Catalog
- 1. The Essence of web Framework and Custom web Framework
- 2. Simple web Framework
- 3. web Framework for Returning HTML Files
- 4. Advanced web Framework for Returning Static Files
- 5. Functional Advanced web Framework
- 6. Higher Edition (Multithread Edition) web Framework
- 7. More advanced web framework
- 8. web Framework for Returning Different Pages Based on Different Paths
- 9. web Framework for Returning Dynamic Pages
- 10.wsgiref module version web Framework
- 11. Take-off web Framework
1. The Essence of web Framework and Custom web Framework
We can understand that all Web applications are essentially a socket server, and the user's browser is a socket client. Based on the request, the client responds first, the server responds accordingly, sends the request according to the request protocol of http protocol, and the server responds according to the sound of http protocol. In response to requests by protocol, such network communication, we can implement the Web framework ourselves.
Through the study of socket, we know that network communication, we can write by ourselves, because socket is used for network communication. Next, we implement a web framework based on socket, write a web server, let the browser request, and return the page to the browser through its own server. Browsers render what we want.
The contents of the HTML file are as follows, named test.html:.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="test.css">
<link rel="icon" href="wechat.ico">
<! - The css style written directly on the html page can be displayed directly on the browser - >
<!--<style>-->
<!--h1{-->
<!--background-color: green;-->
<!--color: white;-->
<!--}-->
<!--</style>-->
</head>
<body>
<h1> Hello, girl. This is Jaden speaking. May I have an appointment? Hee Hee~~</h1>
<! - The src attribute value of the img tag written directly on the html page can be displayed directly on the browser if the address of another website (network address) is displayed directly on the browser - >
<<<!!! <img src= "https://timgsa.baidu.com/timg? Image quality = 80&size = 80&size = b9999_10000&sec = 15503939546161724&di = c2b971db12eef5d85aba410d85aba410aba410e2e85088e8568 & im gt ype = 0&src = http%3A%2F%2Fy0.ifeifeife.com%2ffpic%2ffffff2012020204082822%Fd2012020202020Fd685151515151515151515151515151515172724&di=c2b971550393939393939size87_w800_h1227.jpg"alt="> - > <! - If they are all network addresses, then As long as your computer has a network, you can see that you don't need to write the corresponding reading file in the back end, and return the code of the image file information, because someone else's website has done this thing - >.
<img src="meinv.png" alt=""width="100" height="100"> <!--If you are a local picture to return to the page, you need to respond to the request for this picture on the page yourself, this SRC is to request this picture locally, you just read out the picture information, return to the page, the page for The data of this picture can be rendered. Is it simple?
<! - js operations written directly on html pages can be displayed directly on browsers
<!--<script>-->
<! - alert ('This is our first web page') -->
<!--</script>-->
<script src="test.js"></script>
</body>
</html>The CSS file is named test.css:
h1{
background-color: green;
color: white;
}The contents of the JS file are as follows, named test.js:
alert('This is our first web page.');Prepare another picture named meinv.jpg, and prepare an ICO file named wechat.ico, which is actually a picture file. After opening the official website of Weixin, you can see it on the top of the browser.
Save it.
When all the files above are ready, you create a new project with pycharm, put all the files in a folder and keep them in reserve, as follows:

2. Simple web Framework
Create a python file with the following name: test.py:
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
conn,addr = sk.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
#Socket is the abstract layer between the application layer and the transport layer. Every time there is a protocol, the protocol is the message format. Then the message format of the transport layer need not be controlled. Because socket helps us to work out the message format, but the protocol of the application layer still needs to be complied with by ourselves, so when sending messages to the browser, if not. Write according to the message format of the application layer, then the information you return to the browser is not recognized by the browser. The application layer protocol is our HTTP protocol, so we can return messages to browsers according to the message format stipulated by HTTP protocol. We will go into details about HTTP. First, we will look at the effect of writing conn.send(b'hello') directly, then run the code, access it through browsers, and then look at this. Effect of a sentence conn.send (b'HTTP/1.1 200 okrn\rnhello')
#The following sentence is written according to http protocol
# conn.send(b'HTTP/1.1 200 ok \r\n\r\nhello')
#The above sentence can also be divided into the following two sentences.
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(b'hello')Let's take a look at the request sent by the browser:
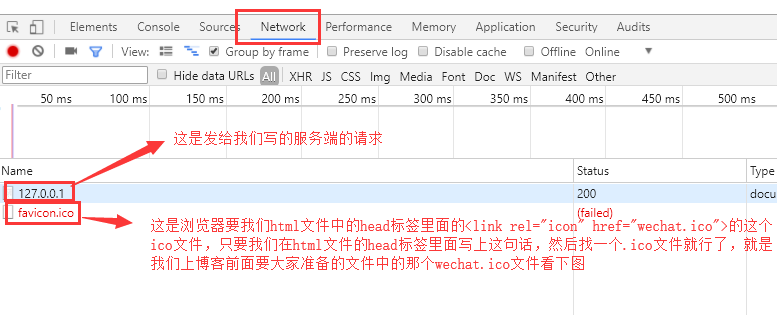
At present, we haven't written how to return an html file to the browser, so we don't care about it here for the time being, so let's click on this 127.0.0.1 to see:
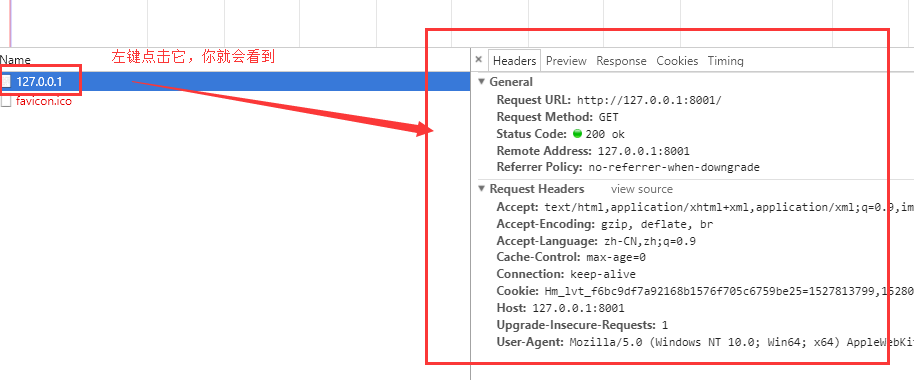
We print the request information sent by the browser in the python file.
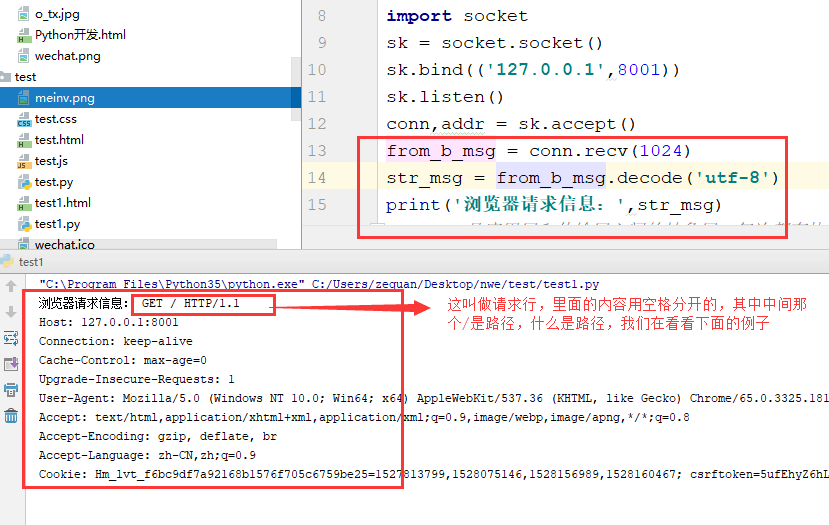
Restart our code and type this in the web address:
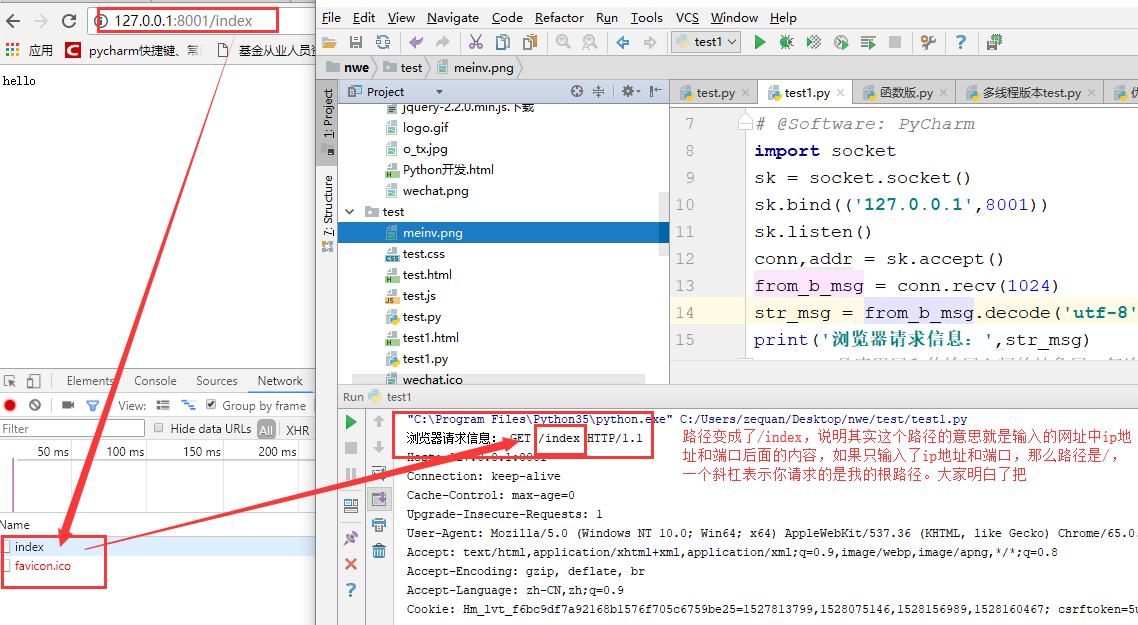
Restart our code and type this in the web address:
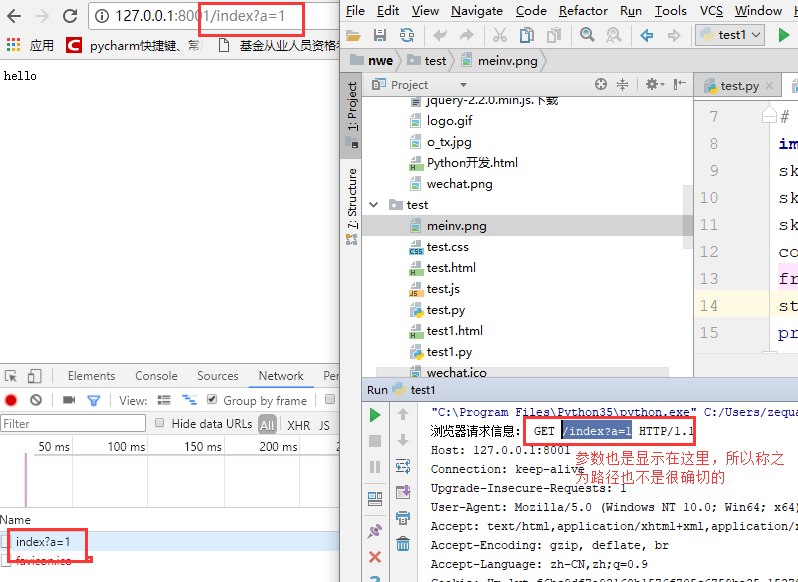
Browsers send a bunch of messages, and when we reply to the browser (response) information, we also need to write in accordance with a message format, which is stipulated by the http protocol, so let's learn the http protocol, and then continue to improve our web framework:
HTTP protocol: https://www.cnblogs.com/clschao/articles/9230431.html
3. web Framework for Returning HTML Files
First, write an HTML file with the following name: test.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title><link rel="stylesheet" href="test.css">
<!--Write directly html Inside the page css Styles can be displayed directly on browsers-->
<style>
h1{
background-color: green;
color: white;
}
</style>
</head>
<body>
<h1>Hello, girl, I am Jaden,Do you have an appointment? Hee hee~~</h1>
<!--Write directly html Inside the page img Labelling src Property values can be displayed directly in browsers if they are addresses of other people's websites (network addresses)-->
<img src="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1550395461724&di=c2b971db12eef5d85aba410d1e2e8568&imgtype=0&src=http%3A%2F%2Fy0.ifengimg.com%2Fifengimcp%2Fpic%2F20140822%2Fd69e0188b714ee789e97_size87_w800_h1227.jpg" alt="">
<!--If they are all network addresses, as long as your computer has a network, you can see that you don't need to write the corresponding reading files in the back end, return the code of picture file information, because someone else's website has done this.-->
<!--Write directly html Inside the page js The operation can be displayed directly on the browser.-->
<script>
alert('This is our first web page')
</script>
</body>
</html>Prepare our python code, server program, file content as follows, file name is test.py:.
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
conn,addr = sk.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
print('Browser requests information:',str_msg)
# conn.send(b'HTTP/1.1 200 ok \r\ncontent-type:text/html;charset=utf-8;\r\n')
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
with open('test1.html','rb') as f:
f_data = f.read()
conn.send(f_data)Enter the website on the page to see the effect. The effect of css and js code is also very good:

But we know that our CSS and JS are basically written in local files, and our pictures are basically our own. What should we do? We will prepare the JS and CSS above and the image file at the end of the. ico. Let's come to an upgraded version of the web. Framework, in fact, css, js, pictures and other files are called static files of the website.
First, let's look at an effect. If we insert the css and js we have written and the. ico and image files directly into our html page, this is the html file below.
The name is test.html, which reads as follows:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="test.css">
<! - Add the following sentence, then we can see that there is no favicon.ico request in the network in the browser debugging window. In fact, this is the page icon on the left of the page title label text, but this file is our own local, so we need to put this file data in the back-end code. Read it out and return it to the front end - >
<link rel="icon" href="wechat.ico">
<! - The css style written directly on the html page can be displayed directly on the browser - >
<!--<style>-->
<!--h1{-->
<!--background-color: green;-->
<!--color: white;-->
<!--}-->
<!--</style>-->
</head>
<body>
<h1> Hello, girl. This is Jaden speaking. May I have an appointment? Hee Hee~~</h1>
<! - The src attribute value of the img tag written directly on the html page can be displayed directly on the browser if the address of another website (network address) is displayed directly on the browser - >
<<<!!! <img src= "https://timgsa.baidu.com/timg? Image quality = 80&size = 80&size = b9999_10000&sec = 15503939546161724&di = c2b971db12eef5d85aba410d85aba410aba410e2e85088e8568 & im gt ype = 0&src = http%3A%2F%2Fy0.ifeifeife.com%2ffpic%2ffffff2012020204082822%Fd2012020202020Fd685151515151515151515151515151515172724&di=c2b971550393939393939size87_w800_h1227.jpg"alt="> - > <! - If they are all network addresses, then As long as your computer has a network, you can see that you don't need to write the corresponding reading file in the back end, and return the code of the image file information, because someone else's website has done this thing - >.
<img src="meinv.png" alt=""width="100" height="100"> <!--If you are a local picture to return to the page, you need to respond to the request for this picture on the page yourself, this SRC is to request this picture locally, you just read out the picture information, return to the page, the page for The data of this picture can be rendered. Is it simple?
<! - js operations written directly on html pages can be displayed directly on browsers
<!--<script>-->
<! - alert ('This is our first web page') -->
<!--</script>-->
<script src="test.js"></script>
</body>
</html>Also use our previous python program to see the effect:
We found that neither js nor css works, and let's take a look at the network in the browser debug window.
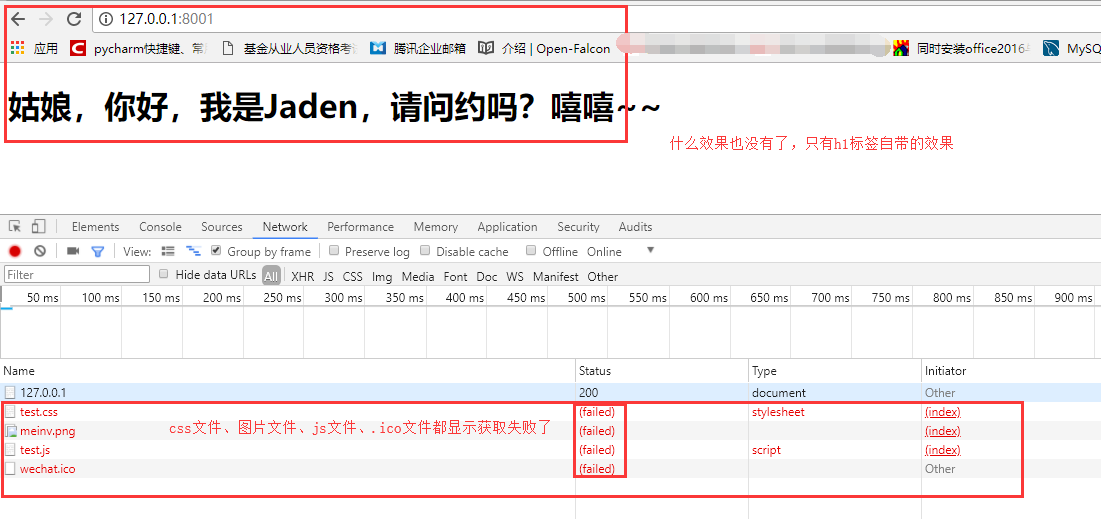
Next, we click on the test.css file in the network to see what the request is:

When we save a page directly on the browser, we click on the right button to save it as a page, and then save it in a local directory. You will find that the html, css, js, pictures and other files of this page are saved with it. I saved the homepage of the blog Garden for a while. The page, look, is a folder and an HTML file:

Let's click on the folder of Blog Garden to see what's in it.
Find that js, CSS and pictures have been saved, explain what, that these files exist in the browser itself, oh, the original html page needs css, js, pictures and other files are sent to the browser, and these static files are browsers alone to request, its The properties of the real tag are related. The CSS file is the href attribute of the link tag, the JS file is the src attribute of the script tag, and the picture file is the src attribute of the img tag. The. ico file is the attribute of the link tag: in fact, when the page is loaded, these attributes will go to their corresponding attribute values alone to request the corresponding file data, and if we write in the value of their own local path, then we will come from their own local path to find, if we write in the value of their own local path. Relative path, we will go to our own address + file name, this path to find the files it needs, so we just need to do some response to these requests, the corresponding file data to the browser on it! And we can see through the previous view, browser url request path we know what, static files are not so requested, okay, we return different files to it for different paths.
The. ico file is the attribute of the link tag: in fact, when the page is loaded, these attributes will go to their corresponding attribute values alone to request the corresponding file data, and if we write in the value of their own local path, then we will come from their own local path to find, if we write in the value of their own local path. Relative path, we will go to our own address + file name, this path to find the files it needs, so we just need to do some response to these requests, the corresponding file data to the browser on it! And we can see through the previous view, browser url request path we know what, static files are not so requested, okay, we return different files to it for different paths.
Very nice! Let's try!
4. Advanced web Framework for Returning Static Files
Or use the html file in the second web framework. We just need to write some of our server-side programs. The same is the test.py file, which reads as follows:
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
#First, the browser sends us several requests, one is to request our html file, and the tag of the imported file in our html file sends us a request for static file to this website, so we need to loop the process of establishing the connection to accept multiple requests, no problem.
while 1:
conn,addr = sk.accept()
# while 1:
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
#Through the http protocol, we know that browser requests, there is a request content path. Through the analysis of the request information, this path can be extracted from all the request information. The following path is the path we extracted.
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>',path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
#Because the whole page needs a series of files, such as html, css, js, pictures, etc., so we all need to send them to people's browsers before they can have these files, in order to render your page well.
#Return the content of the response according to different paths
if path == '/': #Return html file
print(from_b_msg)
with open('test.html','rb') as f:
# with open('Python development. html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
elif path == '/meinv.png': #Return to picture
with open('meinv.png','rb') as f:
pic_data = f.read()
# conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(pic_data)
conn.close()
elif path == '/test.css': #Return css file
with open('test.css','rb') as f:
css_data = f.read()
conn.send(css_data)
conn.close()
elif path == '/wechat.ico':#ico icon for returning page
with open('wechat.ico','rb') as f:
ico_data = f.read()
conn.send(ico_data)
conn.close()
elif path == '/test.js': #Return the js file
with open('test.js','rb') as f:
js_data = f.read()
conn.send(js_data)
conn.close()
#Note: After each of the above requests is processed, there is a conn.close() because the HTTP protocol is short-linked, a request responds to a response, the request is over, so we need to write close, otherwise the browser itself is broken, the server you write yourself is not broken, there will be problems.Run our py file, and then visit our server in the browser to see the effect:

5. Functional Advanced web Framework
html files and other static files we used above
The python code is as follows:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2019/2/17 14:06
# @Author : wuchao
# @Site :
# @File : test.py
# @Software: PyCharm
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
#Functions for processing page requests
def func1(conn):
with open('test.html', 'rb') as f:
# with open('Python development. html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
#Processing page img tag src attribute value is a request for local path
def func2(conn):
with open('meinv.png', 'rb') as f:
pic_data = f.read()
# conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(pic_data)
conn.close()
#Process the request when the page link (< link rel = "stylesheet" href = "test. CSS" >
def func3(conn):
with open('test.css', 'rb') as f:
css_data = f.read()
conn.send(css_data)
conn.close()
#Processing page link (<link rel="icon" href="wechat.ico">) tag href attribute value is a request when the local path
def func4(conn):
with open('wechat.ico', 'rb') as f:
ico_data = f.read()
conn.send(ico_data)
conn.close()
#Processing page script (<script src="test.js"></script>) tag SRC attribute value is a request when the local path
def func5(conn):
with open('test.js', 'rb') as f:
js_data = f.read()
conn.send(js_data)
conn.close()
while 1:
conn,addr = sk.accept()
# while 1:
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>',path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(from_b_msg)
if path == '/':
func1(conn)
elif path == '/meinv.png':
func2(conn)
elif path == '/test.css':
func3(conn)
elif path == '/wechat.ico':
func4(conn)
elif path == '/test.js':
func5(conn)
6. Higher Edition (Multithread Edition) web Framework
In application, we concurrent programming content, anyway, html files and static files are directly to the browser, then everyone will deal with concurrently, html files and static files are still above.
The python code is as follows:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2019/2/17 14:06
# @Author : wuchao
# @Site :
# @File : test.py
# @Software: PyCharm
import socket
from threading import Thread
#Note that you can do without multithreading. Here we just teach you the idea of concurrent programming, so I use multithreading.
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
def func1(conn):
with open('test.html', 'rb') as f:
# with open('Python development. html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
def func2(conn):
with open('meinv.png', 'rb') as f:
pic_data = f.read()
# conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(pic_data)
conn.close()
def func3(conn):
with open('test.css', 'rb') as f:
css_data = f.read()
conn.send(css_data)
conn.close()
def func4(conn):
with open('wechat.ico', 'rb') as f:
ico_data = f.read()
conn.send(ico_data)
conn.close()
def func5(conn):
with open('test.js', 'rb') as f:
js_data = f.read()
conn.send(js_data)
conn.close()
while 1:
conn,addr = sk.accept()
# while 1:
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>',path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(from_b_msg)
if path == '/':
# func1(conn)
t = Thread(target=func1,args=(conn,))
t.start()
elif path == '/meinv.png':
# func2(conn)
t = Thread(target=func2, args=(conn,))
t.start()
elif path == '/test.css':
# func3(conn)
t = Thread(target=func3, args=(conn,))
t.start()
elif path == '/wechat.ico':
# func4(conn)
t = Thread(target=func4, args=(conn,))
t.start()
elif path == '/test.js':
# func5(conn)
t = Thread(target=func5, args=(conn,))
t.start()
7. More advanced web framework
There are too many if judgments, and the way of opening threads is disgusting. If there are too many if judgments, just write as many times to create threads to simplify it.
import socket
from threading import Thread
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
def func1(conn):
conn.send(b'HTTP/1.1 200 ok\r\ncontent-type:text/html\r\ncharset:utf-8\r\n\r\n')
with open('test.html', 'rb') as f:
# with open('Python development. html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
def func2(conn):
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('meinv.png', 'rb') as f:
pic_data = f.read()
# conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(pic_data)
conn.close()
def func3(conn):
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('test.css', 'rb') as f:
css_data = f.read()
conn.send(css_data)
conn.close()
def func4(conn):
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('wechat.ico', 'rb') as f:
ico_data = f.read()
conn.send(ico_data)
conn.close()
def func5(conn):
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('test.js', 'rb') as f:
js_data = f.read()
conn.send(js_data)
conn.close()
#Define the correspondence between a path and an execution function, instead of writing a bunch of if judgments
l1 = [
('/',func1),
('/meinv.png',func2),
('/test.css',func3),
('/wechat.ico',func4),
('/test.js',func5),
]
#Traversing the list of corresponding relationships between paths and functions, and opening multi-threads to execute paths efficiently.
def fun(path,conn):
for i in l1:
if i[0] == path:
t = Thread(target=i[1],args=(conn,))
t.start()
# else:
# conn.send(b'sorry')
while 1:
conn,addr = sk.accept()
#After reading the code, you can think about a problem. Many people want to visit your website at the same time. If you ask if concurrent programming can be started here, multi-process + multi-threading + protocol, compromise support for high concurrency, and with server cluster, this web page will support a lot of high concurrency. Is there any excitement, haha, but we wrote too low, and the function is very poor, fault-tolerant ability is also poor, of course, if you have the ability, you can now write your own web framework, write an nb, if not now, then we will learn the framework written by others well, first of all. The first one is our django framework. In fact, it is to encapsulate these functions, and has strong fault tolerance and compression resistance. In a word: hanging.
# while 1:
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>',path)
# Note: Because the open thread is very fast, it may lead to your file has not been sent in the past, other file requests have come, resulting in your file information is not correctly recognized by the browser, so you need to send the request line and the request header part to each function in front of it, and prevent browsing. It may not be able to identify your html file. You need to add two request header content-types: text/htmlr\ncharset:utf-8rn to the part of the sending request line and the request header in the function that sends the html file.
# Conn. send (b'HTTP/1.1 200 okrnrn') does not write this way
# Conn. send (b'HTTP/1.1 200 ok r ncontent-type: text/html r ncharset: utf-8 r n r n') does not write like this
print(from_b_msg)
#Execute the fun function and pass him both the path and the conn pipe as parameters
fun(path,conn)
8. web Framework for Returning Different Pages Based on Different Paths
Since we know that we can return different content according to different request paths, can we return different pages according to different paths accessed by users? Well, it should be possible.
Create two HTML files, write a few labels in them, named index.html and home.html, and then return to different pages according to different paths. I will write python code for you.
"""
//Return different content according to different paths in the URL
//Return to a separate HTML page
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # Binding IP and Port
sk.listen() # Monitor
# Encapsulate the parts returning different contents into functions
def index(url):
# Read the contents of the index.html page
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
# Returns byte data
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# Define the corresponding relationship between a url and the actual function to be executed
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# Waiting for connection
conn, add = sk.accept()
data = conn.recv(8096) # Receive messages from clients
# From data to path
data = str(data, encoding="utf8") # Converting the received byte-type data into strings
# Segmentation byrn
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url is our access path separated from the message sent from the browser
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # Because the HTTP protocol is to be followed, the message to be replied must also be added a status line.
# Return different contents according to different paths
func = None # Define a variable that holds the name of the function to be executed
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# Returns a specific response message
conn.send(response)
conn.close()
9. web Framework for Returning Dynamic Pages
This page can be displayed, but it's static. The content of the page will not change. What I want is a dynamic website. The dynamic website means that there are dynamic data in it, not dynamic effect in the page. We should pay attention to this.
No problem, I can solve it. I chose to use string substitution to achieve this requirement. (Here we use timestamps to simulate dynamic data, or just give you python code)
"""
//Return different content according to different paths in the URL
//Return to the HTML page
//Make the web dynamic
"""
import socket
import time
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # Binding IP and Port
sk.listen() # Monitor
# Encapsulate the parts returning different contents into functions
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.time())
s = s.replace("@@oo@@", now) # Define special symbols in web pages and replace them with dynamic data
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# Define the corresponding relationship between a url and the actual function to be executed
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# Waiting for connection
conn, add = sk.accept()
data = conn.recv(8096) # Receive messages from clients
# From data to path
data = str(data, encoding="utf8") # Converting the received byte-type data into strings
# Segmentation byrn
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url is our access path separated from the message sent from the browser
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # Because the HTTP protocol is to be followed, the message to be replied must also be added a status line.
# Return different contents according to different paths
func = None # Define a variable that holds the name of the function to be executed
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# Returns a specific response message
conn.send(response)
conn.close()
All of you are satisfied with these eight frameworks. Now you can understand the principle of the whole web framework. Haha, but the frameworks we write are still too low and not strong enough. Others have developed many nb frameworks, such as Django, Flask, Tornado and so on. We can learn how to use them, but pay attention to one. The problem is that when we get the path inside, we divide it according torn and then divide it by space, but if it's not http protocol, you should pay attention to the message format yourself.
Next, let's look at the web framework developed by a module written by an individual called wsgiref
10.wsgiref module version web Framework
The wsgiref module actually encapsulates the whole request information, so you don't need to deal with it by yourself. If it encapsulates all the request information into an object called request, then you can get the path of the user's request directly by request.path, and request.method can get the path of the user's request. Request mode (get or post) and so on. If we use this module, it will be much easier for us to write the web framework.
For python web applications in real development, they are generally divided into two parts: server applications and applications.
The server program is responsible for encapsulating the socket server and collating the various data requested when the request arrives.
The application is responsible for specific logical processing. In order to facilitate the development of applications, there are many Web frameworks, such as Django, Flask, web.py and so on. Different frameworks have different ways of development, but in any case, the developed applications must cooperate with server programs in order to provide services for users.
In this way, server programs need to provide different support for different frameworks. This chaotic situation is not good for servers or frameworks. For servers, different frameworks need to be supported. For frameworks, only servers that support them can be used by applications developed. The simplest Web application is to save HTML with a file, use a ready-made HTTP server software, receive user requests, read HTML from the file, and return. If you want to generate HTML dynamically, you need to implement the above steps by yourself. However, accepting HTTP requests, parsing HTTP requests, and sending HTTP responses are all hard work. If we write these underlying codes ourselves and haven't started writing dynamic HTML yet, we have to spend a month reading the HTTP specification.
The correct approach is that the underlying code is implemented by specialized server software, and we use Python to focus on generating HTML documents. Because we don't want to be exposed to TCP connections, HTTP original request and response formats, we need a unified interface protocol to implement such server software, let's concentrate on Python to write Web services.
At this time, standardization becomes particularly important. We can set up a standard, as long as the server program supports this standard and the framework supports this standard, then they can cooperate. Once the criteria are established, each party will implement them. In this way, servers can support more standards-supporting frameworks, and frameworks can also use more standards-supporting servers.
WSGI (Web Server Gateway Interface) is a specification, which defines the interface format between web application program and web server program written in Python, and realizes the decoupling between web application program and web server program.
The commonly used WSGI servers are uwsgi and Gunicorn. The independent WSGI server provided by Python standard library is called wsgiref, and the Django development environment uses this module as the server.
wsfiref uses
from wsgiref.simple_server import make_server
# wsgiref itself is a web framework, which provides some fixed functions (encapsulation of request and response information, no need for us to write the original socket, no need for us to complete the extraction of request information, it is very convenient to extract).
#Function name is arbitrary
def application(environ, start_response):
'''
:param environ: It's all processed request information, processed into a dictionary, through the way of dictionary value, you can get a lot of information you want to get.
:param start_response: Help you encapsulate the response information (response lines and response headers). Note the following parameters
:return:
'''
start_response('200 OK', [('Content-Type', 'text/html'),('k1','v1')])
print(environ)
print(environ['PATH_INFO']) #Input address 127.0.0.1:8000, this print is'/', input is 127.0.0.1:8000/index, print result is'/index'
return [b'<h1>Hello, web!</h1>']
#It's very similar to the socket server module we learned.
httpd = make_server('127.0.0.1', 8080, application)
print('Serving HTTP on port 8080...')
# Start listening for HTTP requests:
httpd.serve_forever()
Come to a complete web project, user login authentication project, we need to connect to the database, so first to the mysql database to prepare some tables and data
mysql> create database db1;
Query OK, 1 row affected (0.00 sec)
mysql> use db1;
Database changed
mysql> create table userinfo(id int primary key auto_increment,username char(20) not null unique,password char(20) not null);
Query OK, 0 rows affected (0.23 sec)
mysql> insert into userinfo(username,password) values('chao','666'),('sb1','222');
Query OK, 2 rows affected (0.03 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from userinfo;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | chao | 666 |
| 2 | sb1 | 222 |
+----+----------+----------+
2 rows in set (0.00 sec)
Then create these files:
python file name webmodel.py
#Create table, insert data
def createtable():
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='666',
database='db1',
charset='utf8'
)
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = '''
-- Create table
create table userinfo(id int primary key auto_increment,username char(20) not null unique,password char(20) not null);
-- insert data
insert into userinfo(username,password) values('chao','666'),('sb1','222');
'''
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
python's name is webauth file
#Verify username and password
def auth(username,password):
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='db1',
charset='utf8'
)
print('userinfo',username,password)
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = 'select * from userinfo where username=%s and password=%s;'
res = cursor.execute(sql, [username, password])
if res:
return True
else:
return False
A file named web.html where the user enters a username and password
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!--If form Inside the form action No value is given, default is to the current page url Submit your data, so we can specify our own data submission path.-->
<!--<form action="http://127.0.0.1:8080/auth/" method="post">-->
<form action="http://127.0.0.1:8080/auth/" method="get">
User name<input type="text" name="username">
Password <input type="password" name="password">
<input type="submit">
</form>
<script>
</script>
</body>
</html>
The page that jumps after the user's authentication is successful is displayed as websuccess.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
h1{
color:red;
}
</style>
</head>
<body>
<h1>Baby, congratulations on your landing success</h1>
</body>
</html>
Python server-side code (main logic code), named web_python.py
from urllib.parse import parse_qs
from wsgiref.simple_server import make_server
import webauth
def application(environ, start_response):
# start_response('200 OK', [('Content-Type', 'text/html'),('k1','v1')])
# start_response('200 OK', [('Content-Type', 'text/html'),('charset','utf-8')])
start_response('200 OK', [('Content-Type', 'text/html')])
print(environ)
print(environ['PATH_INFO'])
path = environ['PATH_INFO']
#Request path for user to get login page
if path == '/login':
with open('web.html','rb') as f:
data = f.read()
#Logical processing for form form submission auth path
elif path == '/auth/':
#Landing authentication
#1. Get the username and password entered by the user
#2. Check the data in the database to see if the submission is legitimate.
# user_information = environ['']
if environ.get("REQUEST_METHOD") == "POST":
#Get the length of the request volume data, because the submitted data needs to be extracted with it. Note that POST requests and GET requests obtain data differently.
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
#How POST requests get data
request_data = environ['wsgi.input'].read(request_body_size)
print('>>>>>',request_data) # >> b'username = Chao & password = 123', is a bytes type data
print('?????',environ['QUERY_STRING']) #Empty, because post requests can only retrieve data in the same way as above
#parse_qs can help us parse the data
re_data = parse_qs(request_data)
print('Disassembled data',re_data) #Disassembled data {b'password': [b'123'], b'username': [b'chao']} #I won't write the return data of the post request.
if environ.get("REQUEST_METHOD") == "GET":
#The way GET requests data can only be retrieved in this way
print('?????',environ['QUERY_STRING']) #Username = Chao & password = 123, is a string type data
request_data = environ['QUERY_STRING']
# parse_qs can help us parse the data
re_data = parse_qs(request_data)
print('Disassembled data', re_data) #Disassembled data {password': ['123'],'username': ['chao']}
username = re_data['username'][0]
password = re_data['password'][0]
print(username,password)
#Verification:
status = webauth.auth(username,password)
if status:
# 3. Return the corresponding content
with open('websuccess.html','rb') as f:
data = f.read()
else:
data = b'auth error'
# But neither post nor get requests can get the data directly. The data we get need to be decomposed and extracted. So we introduce urllib module to help us decompose.
#Note Ang, if we return to Chinese directly, without specifying the encoding format for the browser, the default is gbk, so we need GBK to encode it, so the browser can recognize it.
# data='successful landing! '. encode('gbk')
else:
data = b'sorry 404!,not found the page'
return [data]
#It's very similar to the socket server module we learned.
httpd = make_server('127.0.0.1', 8080, application)
print('Serving HTTP on port 8080...')
# Start listening for HTTP requests:
httpd.serve_forever()
Create a file and put it in the same directory. Run the code of our_python.py file to see the effect. Note that the first address you enter is 127.0.0.1:8080/login. Also note that your mysql database is not a problem.
11. Take-off web Framework
In our last web framework, we wrote all the code in a py file. We split it into other files and used if judgment when distributing requests according to unused paths. There are many things worth optimizing. OK, let's optimize them according to the advantages of our previous versions. Files and folders
The code is not listed on the blog. I packed it into Baidu cloud. Let's download it: https://pan.baidu.com/s/1Ns5QHFpZGusGHuHz rCto3A.