The difference between sql join on and where
explain select count(1) from cellinfo_20171124 ci join shandong_lac_ci slc on concat(cast(ci.lac as string),",",cast(ci.ci as string)) =slc.lac_ci;
| == Physical Plan ==
*HashAggregate(keys=[], functions=[count(1)])
+- Exchange SinglePartition
+- *HashAggregate(keys=[], functions=[partial_count(1)])
+- *Project
+- *SortMergeJoin [concat(cast(lac#72382 as string), ,, cast(ci#72383 as string))], [lac_ci#72394], Inner
:- *Sort [concat(cast(lac#72382 as string), ,, cast(ci#72383 as string)) ASC], false, 0
: +- Exchange hashpartitioning(concat(cast(lac#72382 as string), ,, cast(ci#72383 as string)), 200)
: +- HiveTableScan [lac#72382, ci#72383], MetastoreRelation default, cellinfo_20171124, ci
+- *Sort [lac_ci#72394 ASC], false, 0
+- Exchange hashpartitioning(lac_ci#72394, 200)
+- *Filter isnotnull(lac_ci#72394)
+- HiveTableScan [lac_ci#72394], MetastoreRelation default, shandong_lac_ci, slc |
explain select count(*) from cellinfo_20171124 where concat(cast(lac as string),",",cast(ci as string)) in (select lac_ci from shandong_lac_ci);
| == Physical Plan ==
*HashAggregate(keys=[], functions=[count(1)])
+- Exchange SinglePartition
+- *HashAggregate(keys=[], functions=[partial_count(1)])
+- *Project
+- SortMergeJoin [concat(cast(lac#72407 as string), ,, cast(ci#72408 as string))], [lac_ci#72420], LeftSemi
:- *Sort [concat(cast(lac#72407 as string), ,, cast(ci#72408 as string)) ASC], false, 0
: +- Exchange hashpartitioning(concat(cast(lac#72407 as string), ,, cast(ci#72408 as string)), 200)
: +- HiveTableScan [mcc#72405, mnc#72406, lac#72407, ci#72408, lat#72409, lon#72410, acc#72411, date#72412, validity#72413, addr#72414, province#72415, city#72416, district#72417, township#72418], MetastoreRelation default, cellinfo_20171124
+- *Sort [lac_ci#72420 ASC], false, 0
+- Exchange hashpartitioning(lac_ci#72420, 200)
+- HiveTableScan [lac_ci#72420], MetastoreRelation default, shandong_lac_ci |The functions of the above two statements are the same. When querying the coverage of the base station, the number of results is the same, but the speed is different. 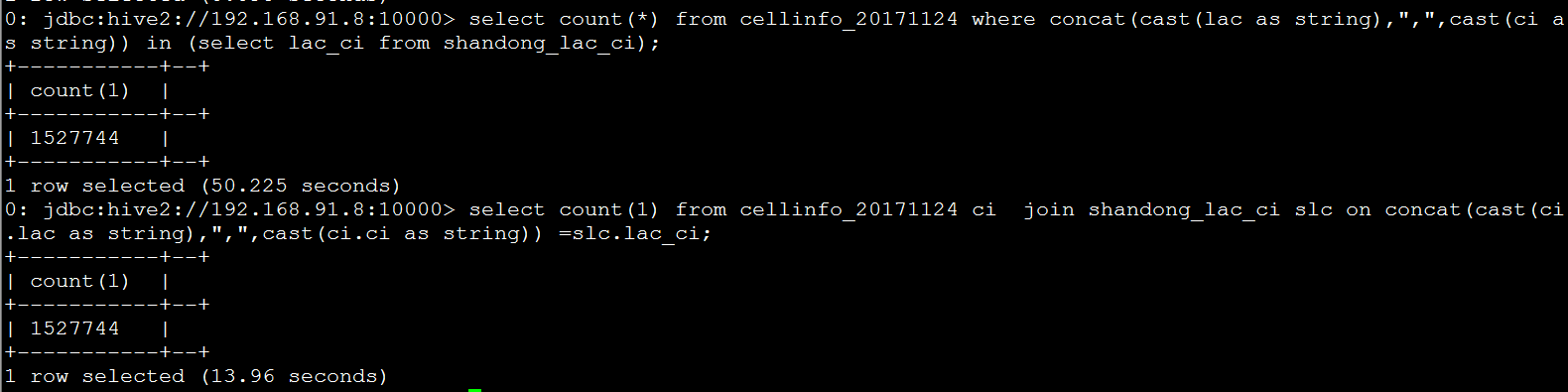
It can be seen from the figure above that the speed difference is several times. Why?
-
View background execution plan


It can be seen from the diagram executed in the background that the main difference between join on and in is Shuffle Write and Shuffle Read @ (these two values are a concept, and the output of the first stage is the input of the second stage)
By querying the difference between join on and where, we know the following situations:
https://www.cnblogs.com/Jessy/p/3525419.html
1. On condition is used when generating temporary table
2. Where condition is to filter the temporary table after it is generated
After understanding these two reasons, when join ing, the content of the temporary table is only lac and CI (972.5M); and where of in is the condition after the temporary table, so the temporary table of in has all fields (11.9G, why not 21.3G, because spark is compressed, the number of items is the same, and the data quantity is smaller), As a result, the output time is long, because the write file is large, and the input time in the next stage is long, because these data reads need to be compared.