Posgres Connect User's cache Kernel
Preface
After the pg client connects to the server through libpq, the postmaster process creates a postgres process for the client to process various requests sent by the client. Any request from the client requires the postgres process to scan the system table several times to obtain the data needed for the request. To speed up the processing of requests, a series of caches are created to cache catalog data when each postgres process is initialized. Next, we will analyze the implementation of pg internal cache (code version 10.4).
Section 1 Types of cache
The relevant code of cache is in the src/backend/utils/cache directory
attribute cache code: attoptcache.c
System table cache code: catcache.c
Event trigger cache code: evtcache.c
Message mechanism code: inval.c
Plan cache code: plan cache.c
Common table descriptor cache code: relcache.c
System table oid mapping cache code: relmapper.c
General table oid mapping cache code: relfilenodemap.c
Table space cache code: spccache.c
System table cache code: syscache.c
System Table Retrieval Function: lsyscache.c
Typeecache code: typcache.c
Text retrieval cache code: ts_cache.c
This article mainly explains catcache and relcache.
Section 2 catcache Data Structure
1.syscache identifier enumeration
The enumeration type SysCacheIdentifier is defined in the syscache.h header file, where all elements of syscache are enumerated.
Each element is called a catcache, which will be discussed below.
enum SysCacheIdentifier { AGGFNOID = 0, ... USERMAPPINGUSERSERVER # define SysCacheSize (USERMAPPINGUSERSERVER + 1) };
2.cache Descriptor Structures
struct cachedesc { Oid reloid; Oid indoid; int nkeys; int key[4]; int nbuckets; };
Each enumerated value in 1 corresponds to one of the above structures
3.cacheinfo array
static const struct cachedesc cacheinfo[] = { {AggregateRelationId, AggregateFnoidIndexId, { Anum_pg_aggregate_aggfnoid, 0, 0 }, 16 }, … {UserMappingRelationId, /* USERMAPPINGUSERSERVER */ UserMappingUserServerIndexId, 2, { Anum_pg_user_mapping_umuser, Anum_pg_user_mapping_umserver, 0, 0 }, 2 } };
In 1, each enumeration has its own space in cacheinfo, and the enumeration value is the array subscript.
This array gives a preliminary description of each syscache, through which the cache is initialized when a user connects.
4.catcache structure
typedef struct catcache { int id; slist_node cc_next; const char *cc_relname; Oid cc_reloid; Oid cc_indexoid; bool cc_relisshared; TupleDesc cc_tupdesc; int cc_ntup; int cc_nbuckets; int cc_nkeys; int cc_key[CATCACHE_MAXKEYS]; PGFunction cc_hashfunc[CATCACHE_MAXKEYS]; ScanKeyData cc_skey[CATCACHE_MAXKEYS]; bool cc_isname[CATCACHE_MAXKEYS]; dlist_head cc_lists; dlist_head *cc_bucket; # ifdef CATCACHE_STATS long cc_searches; long cc_hits; long cc_neg_hits; long cc_newloads; long cc_invals; long cc_lsearches; long cc_lhits; # endif } CatCache;
5. CatCTup structure
typedef struct catctup { int ct_magic; # define CT_MAGIC 0x57261502 CatCache *my_cache; dlist_node cache_elem; struct catclist *c_list; int refcount; bool dead; bool negative; uint32 hash_value; HeapTupleData tuple; } CatCTup;
6.CatCList structure
typedef struct catclist { int cl_magic; # define CL_MAGIC 0x52765103 CatCache *my_cache; dlist_node cache_elem; int refcount; bool dead; bool ordered; short nkeys; uint32 hash_value; HeapTupleData tuple; int n_members; CatCTup *members[FLEXIBLE_ARRAY_MEMBER]; } CatCList;
7.CatCacheHeader structure
typedef struct catcacheheader { slist_head ch_caches; int ch_ntup; } CatCacheHeader;
8.catcache-related structure diagram (fig. 1 below)
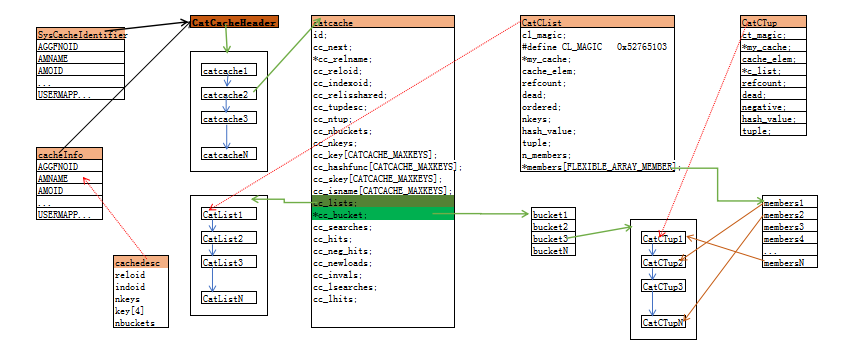
SysCacheIdentifier enumerates all types of catche, while cacheinfo exhausts the structure of each cache. CatCacheHeader is the head of a catcache list. After initializing each catche, the structure of the catche is linked to the list. The information of each cache is described in the catcache structure. The cached system table tuple data is stored in the cc_bucket, which is initialized as a hash bucket array when the catche is initialized. A CatTup list is stored in each hash bucket, and each CatTup structure corresponds to a tuple of the system table.
There is also a cc_lists linked list in the catcache structure, which is used to cache a system table scan with multiple results.
For example, scanning pg_class with a table name as a condition may return multiple records. The returned record is still stored in the cc_bucket hash bucket
In the array, the location in the hash bucket is also stored in the members array of the CatCList structure.
Section 3 Recache cache cache structure
This cache mainly caches the table structure of various tables in the database.
Use static HTAB *RelationIdCache; the structure stores all relcache cache.
Use RelationData to store each relcache.
Section 4 Recache initialization

RelationCacheInitialize() function to create the RelationIdCache structure
The RelationCacheInitializePhase 2 () function loads the necessary relcache through the function formrdesc if relcache data from the cluster shared table failed to load from the globle/pg_internal.init file.
The RelationCacheInitializePhase 3 () function loads the necessary relcache through the function formrdesc if relcache data fails to load non-shared tables (including indexes, views, sequences, etc.) from the dbdir/pg_internal.init file, and calls InitCatalog CachePhase 2 () to iterate through the catcache to add all system tables to the RelationCache.
Section 5 The Behavior of Recache
After the initialization of relcache, the relation ship structure of all system tables has been loaded into relcache.
The relational table structure of a common table loads the relational structure of a common table into relcache when it opens the table for the first time (for example, the following function call procedure).
relation_open()->RelationIdGetRelation()->RelationBuildDesc()->RelationCacheInsert()
Data that has been loaded into relcache is usually accompanied by the user connection until the user connection is closed. But when the structure of a table changes, you need to synchronize this change to all connected user connections. The following is a description of the implementation process of this synchronization:
Assuming that there are currently two users, c1 and c2, who have maintained the connection and c1 has modified the table structure of table t1, the postgres process of c1 registers message message 1 of relcache invalidation of table t1 through the Register Relcache Invalidation (Oid dbId, Oid relId) function. The C2 connection processes message 1 (reference function Local Execute Invalidation Message) before executing the first user query after the c1 change, and finally completes the T1 relcache update of the postgres process of C2 using the Relation ClearRelation function.
Section 6 Initialization of catcache
PostgresMain->InitPostgres->InitCatalogCache->InitCatCache
->RelationCacheInitializePhase3->InitCatalogCachePhase2
In the InitCatalogCache function, InitCatCache (items in cacheinfo are used as initialization parameters) is called iteratively to initialize each catcache.
In InitCatCache, the structure space of CatCache is applied for each catcache, and the structure space is assigned by parameters.
The number of hash buckets for each catcache is fixed, and space will be applied for the hash bucket (cc_bucket). cc_lists, on the other hand, keeps null values.
Section 7 The behavior of catcache (saving and reading cached data)
After catcache initialization, hash buckets for caching scanned data have been initialized for all catcache. Here's how hash buckets access data.
1. The scanning task for a system table with a single return result eventually falls on the SearchCatCache() function:
First, the hash bucket where the cached result of this retrieval condition is located is obtained by the following code.
hashValue = CatalogCacheComputeHashValue(cache, cache->cc_nkeys, cur_skey); hashIndex = HASH_INDEX(hashValue, cache->cc_nbuckets); bucket = &cache->cc_bucket[hashIndex];
The tuples in this hash bucket are retrieved in turn. If the condition is satisfied, the tuple is returned. If the condition is not satisfied, the tuple is executed.
dlist_foreach(iter, bucket) { bool res; ct = dlist_container(CatCTup, cache_elem, iter.cur); if (ct->dead) continue; /* ignore dead entries */ if (ct->hash_value != hashValue) continue; /* quickly skip entry if wrong hash val */ /* * see if the cached tuple matches our key. */ HeapKeyTest(&ct->tuple, cache->cc_tupdesc, cache->cc_nkeys, cur_skey, res); if (!res) continue; dlist_move_head(bucket, &ct->cache_elem); if (!ct->negative) { //The result is retrieved in hash and the tuple is returned ResourceOwnerEnlargeCatCacheRefs(CurrentResourceOwner); ct->refcount++; ResourceOwnerRememberCatCacheRef(CurrentResourceOwner, &ct->tuple); CACHE3_elog(DEBUG2, "SearchCatCache(%s): found in bucket %d", cache->cc_relname, hashIndex); #ifdef CATCACHE_STATS cache->cc_hits++; #endif return &ct->tuple; } else { //At this point, a negative entry is retrieved, which means that there is no result for this retrieval condition. CACHE3_elog(DEBUG2, "SearchCatCache(%s): found neg entry in bucket %d", cache->cc_relname, hashIndex); #ifdef CATCACHE_STATS cache->cc_neg_hits++; #endif return NULL; } }
If you don't find the right result in catcache, scan the table data
relation = heap_open(cache->cc_reloid, AccessShareLock); scandesc = systable_beginscan(relation, cache->cc_indexoid, IndexScanOK(cache, cur_skey), NULL, cache->cc_nkeys, cur_skey); ct = NULL; while (HeapTupleIsValid(ntp = systable_getnext(scandesc))) { //From here, the scanned tuples are inserted into the cache - > cc_bucket [hashIndex] hash bucket ct = CatalogCacheCreateEntry(cache, ntp, hashValue, hashIndex, false); /* immediately set the refcount to 1 */ ResourceOwnerEnlargeCatCacheRefs(CurrentResourceOwner); ct->refcount++; ResourceOwnerRememberCatCacheRef(CurrentResourceOwner, &ct->tuple); break; /* assume only one match */ } systable_endscan(scandesc); heap_close(relation, AccessShareLock); //If no results are scanned, create a negative entry for this retrieval condition if (ct == NULL) { if (IsBootstrapProcessingMode()) return NULL; ntp = build_dummy_tuple(cache, cache->cc_nkeys, cur_skey); ct = CatalogCacheCreateEntry(cache, ntp, hashValue, hashIndex, true); heap_freetuple(ntp); CACHE4_elog(DEBUG2, "SearchCatCache(%s): Contains %d/%d tuples", cache->cc_relname, cache->cc_ntup, CacheHdr->ch_ntup); CACHE3_elog(DEBUG2, "SearchCatCache(%s): put neg entry in bucket %d", cache->cc_relname, hashIndex); /* * We are not returning the negative entry to the caller, so leave its * refcount zero. */ return NULL; } CACHE4_elog(DEBUG2, "SearchCatCache(%s): Contains %d/%d tuples", cache->cc_relname, cache->cc_ntup, CacheHdr->ch_ntup); CACHE3_elog(DEBUG2, "SearchCatCache(%s): put in bucket %d", cache->cc_relname, hashIndex); #ifdef CATCACHE_STATS cache->cc_newloads++; #endif return &ct->tuple;
2. The scanning task for system tables with multiple returns eventually falls on the SearchCatCacheList() function:
The SearchCatCache function puts the retrieved tuples directly into the hash bucket.
The SearchCatCacheList function also places the retrieved tuples in the hash bucket, but each retrieval is organized in a CatCList structure. He places the hash bucket address of the tuple he needs into the members of the CatCList.members [] array.
To achieve the same idea, I will not repeat it here.
Similarly, when a user connection changes the attribute value of a system table, the user connection registers a message through the RegisterCatalog Invalidation () function. Other user connections that maintain the connection process the next time they execute a query, they process the message first and know their process's cache for the catcache.
epilogue
This paper describes the process of initialization and data access of relcache and catcache. In this process, there are still many unknown areas to be studied:
(1) The process of action of other cache s
(2) The mechanism of invalid message passing between postgres processes
Go ahead, move ahead!