Optimizer
- tf.train.GradientDescentOptimizer
- tf.train.AdadeltaOptimizer
- tf.train. AdagradOptimizer
- tf.train.AdagradDAOptimizer
- tf.train.MomentumOptimizer
- tf.train.AdamOptimizer
- tf.train.FtrlOptimizer
- tf.train.ProximalGradientDescentOptimizer
- tf.train.ProximalAdagradOptimizer
- tf.train.RMSPropOptimizer
Gradient descent optimizer comparison
- Standard gradient descent method: first calculate the total error of all samples, and then update the weight according to the total error
- Random gradient descent method: take a random sample to calculate the error, and then update the weight, you may learn more noise
- Batch gradient descent method: it is a compromise scheme. Select a batch from the total samples (for example, a batch with 10000 samples, randomly select 100 samples as a batch), then calculate the total error of the batch, and update the weight according to the total error






Optimizer dynamic graph comparison

Momentum and NAG are fast, but they run at random; Adadelta is the fastest, followed by Adagrad and Rmsprop
Saddle point problem
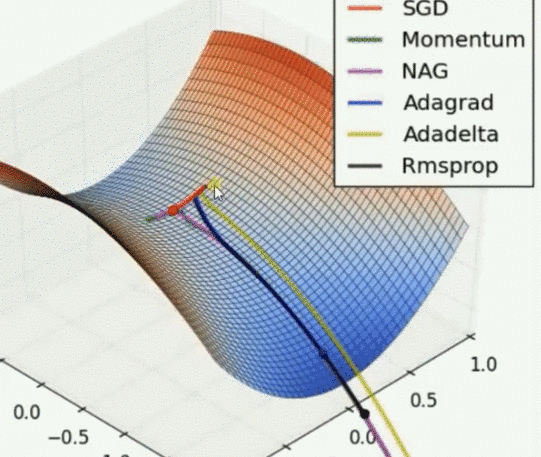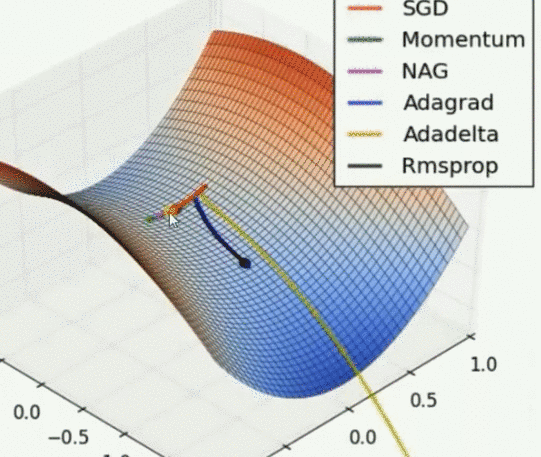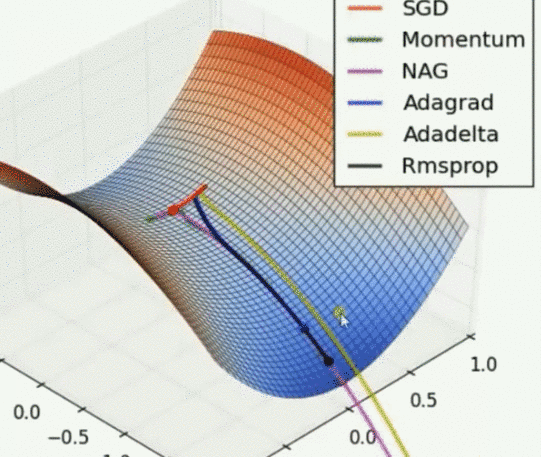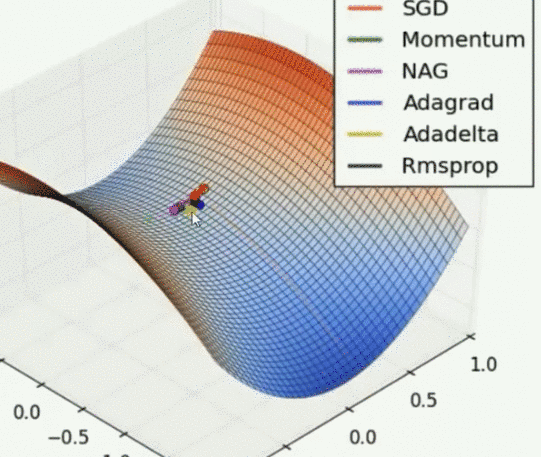
Other optimizers can escape the saddle point, but then the gradient cannot. Adadelta is the fastest, NAG is the fastest, but the reaction of conscious error is slow. Rmsprop is slightly faster than Adagrad
Each kind of optimizer has its scope of application. Many new algorithms are faster than gradient descent, but it is uncertain which optimizer has high accuracy
Use as follows
train_step = tf.train.AdamOptimizer(1e-2).minimize(loss)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# Load data set
mnist = input_data.read_data_sets('MNIST_data',one_hot=True)
# It's not a picture put into a neural network, define a batch, 100 at a time
batch_size = 100
# Calculate how many batches there are and divide them
n_batch = mnist.train.num_examples // batch_size
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
# Set what percentage of neurons work
keep_prob = tf.placeholder(tf.float32)
# Create a simple neural network
# W = tf.Variable(tf.zeros([784, 10]))
# b = tf.Variable(tf.zeros([10]))
# Initialization with truncated positive distribution and standard deviation of 0.1
W1 = tf.Variable(tf.truncated_normal([784, 2000], stddev=0.1))
b1 = tf.Variable(tf.zeros([2000]) + 0.1)
L1 = tf.nn.tanh(tf.matmul(x, W1)+b1)
# L1 is the output of a certain layer of neurons. Keep prob sets the percentage of neurons working
L1_dropout = tf.nn.dropout(L1, keep_prob)
# Add hidden layer
W2 = tf.Variable(tf.truncated_normal([2000, 2000], stddev=0.1))
b2 = tf.Variable(tf.zeros([2000]) + 0.1)
L2 = tf.nn.tanh(tf.matmul(L1_dropout, W2)+b2)
L2_dropout = tf.nn.dropout(L2, keep_prob)
W3 = tf.Variable(tf.truncated_normal([2000, 1000], stddev=0.1))
b3 = tf.Variable(tf.zeros([1000]) + 0.1)
L3 = tf.nn.tanh(tf.matmul(L2_dropout, W3)+b3)
L3_dropout = tf.nn.dropout(L3, keep_prob)
W4 = tf.Variable(tf.truncated_normal([1000, 10], stddev=0.1))
b4 = tf.Variable(tf.zeros([10]) + 0.1)
prediction = tf.nn.softmax(tf.matmul(L3_dropout,W4)+b4)
# Quadratic cost function
# loss = tf.reduce_mean(tf.square(y-prediction))
# Cross entropy cost function
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
# Gradient descent method
# train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
train_step = tf.train.AdamOptimizer(1e-2).minimize(loss)
init = tf.global_variables_initializer()
# Results are stored in a Boolean list
# tf.equal returns True, otherwise False, argmax compares which element in y has a value of 1, and returns the element's subscript
correct_predition = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
# Accuracy rate
# tf.cast converts boolean type to 32-bit floating-point type, true - > 1.0, false - > 0.0, and then calculates the average value. If there are 9 ones, 1 zeros, the average value is 0.9, and the accuracy is 0.9
accuracy = tf.reduce_mean(tf.cast(correct_predition, tf.float32))
with tf.Session() as sess:
sess.run(init)
# Cycle 21 cycles, each cycle batch is 100, each cycle train all pictures once
for epoch in range(20):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x:batch_xs, y:batch_ys, keep_prob: 0.7})
#See the accuracy rate after one cycle of training
test_acc = sess.run(accuracy, feed_dict={x:mnist.test.images,y:mnist.test.labels, keep_prob: 1.0})
train_acc = sess.run(accuracy, feed_dict={x:mnist.train.images,y:mnist.train.labels, keep_prob: 1.0})
print('Iter ' + str(epoch) + ', Testing Accuracy' + str(test_acc) + ', Testing Accuracy'+ str(train_acc))