Convolutional neural network
Grasp its core idea, that is, reduce the content of the image through convolution operation, and focus the model's attention on the specific and obvious features of the image.
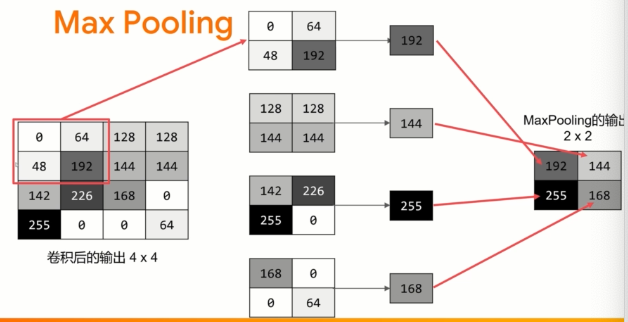
max pooling - enhance features and reduce data
realization
In the following code, the accuracy of the model on the training data may rise to about 93% and on the verification data may rise to 91%.
This is remarkable progress in the right direction!
Try running more epochs -- such as 20 epochs, and then observe the results! Although the results may look very good, in fact, the verification results may decline because of "over fitting", which will be discussed later.
(in short, 'over fitting' occurs in the network model. The results learned from the training set are very good, but it is too narrow. It can only identify the training data, but the effect is not good when we see other data. For example, if we only see red shoes all our life, we may be confused when we see a pair of blue suede shoes... Another example, exam oriented education To make students have a good accuracy rate only for the questions they have done, but a high error rate for the real problems)

import tensorflow as tf print(tf.__version__) mnist = tf.keras.datasets.fashion_mnist (training_images, training_labels), (test_images, test_labels) = mnist.load_data() training_images=training_images.reshape(60000, 28, 28, 1) training_images=training_images / 255.0 test_images = test_images.reshape(10000, 28, 28, 1) test_images=test_images/255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.summary() model.fit(training_images, training_labels, epochs=5) test_loss = model.evaluate(test_images, test_labels)
How is the convolution model established
The first step is to collect data. We will notice that there is a change here and before. The training data needs to change the shape. This is because the first convolution expects a single tensor containing all data, so it is necessary to set the training data to a 4D list of 60000x28x1, and the test image is processed in the same way. If you do not do so, you will get an error during training, because the convolution operation will not recognize the data shape.
The next step is to define the model. First, add a volume layer. Parameter is
- The number of volumes we want to generate (number of filters). This value is arbitrary, but preferably a multiple starting from 32.
- The size of the convolution (the size of the filter), in this case, is a 3x3 grid. This is the most commonly used size.
- Activation function to use -- in this case, we will use relu, which we may remember is equivalent to returning x when x > 0, otherwise 0.
- In the first layer, the shape of the input data is set.
A MaxPooling layer is added after the convolution layer to compress the image while maintaining the feature content emphasized by the convolution. By specifying (2,2) for MaxPooling, the effect is to reduce the size of the image by a quarter. Its idea is to create a 2x2 pixel array, and then select the largest one, so as to change four pixels into one. Repeat this in the whole image. The result is to halve the number of horizontal pixels and the number of vertical pixels, effectively reducing the image by 25%.
Add another convolution layer and MaxPooling2D.
Now flatten the output. After that, you will have the same DNN structure as the non convolution version, that is, fully connected neural network.
The total junction layer containing 128 neurons and the output layer of 10 neurons.
Now compile the model, call the model.fit method for training, and then use the test set to evaluate the loss and accuracy.
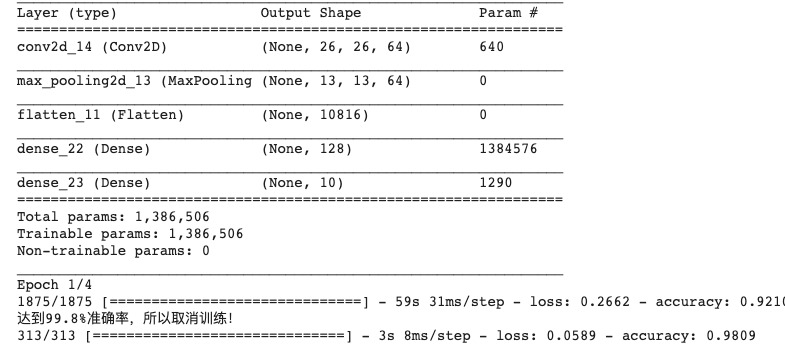
network structure
See if you can improve the MNIST recognition rate to 99.8% or higher using only a single convolution layer and a single MaxPooling 2D. Once the accuracy exceeds this value, the training should be stopped. Epochs should not exceed 20. If the epochs reaches 20 but the accuracy does not meet the requirements, the layer structure needs to be redesigned. When you reach 99.8% accuracy, you should print out the string "reach 99.8% accuracy, so cancel training!".
import tensorflow as tf
from tensorflow import keras
## overwrite callback
class Callbacks(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy')>=0.998):
print("Up to 99.8%Accuracy, so cancel the training!")
self.model.stop_training = True
callbacks = Callbacks()
## Prepare data
mnist = tf.keras.datasets.mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
## normalization
training_images = training_images.reshape(60000, 28, 28, 1)
training_images = training_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images = test_images / 255.0
## Model building
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
# tf.keras.layers.Conv2D(62, (3, 3), activation='relu'),
# tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(), ##delayering
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
## train
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
model.fit(training_images, training_labels, epochs=4, callbacks=[callbacks])
## Forecasting and evaluation
test_loss = model.evaluate(test_images, test_labels)result