Hello, I'm a senior programmer~
Today, let's share a Tencent two-sided algorithm problem, basin friend circle problem~
If you like, remember to pay attention~
Circle of friends problem
There are now 105 users numbered 1 - 105. It is known that there are m pairs of relationships. Each pair of relationships gives you two numbers x and y, representing that the user with number x and the user with number y are in the same circle. For example, A and B are in the same circle, B and C are in the same circle, then A, B and C are in the same circle. Now I want to know how many users there are in the most circle.
Data range: 1 < = m < = 2 * 10 6.
Advanced: space complexity O (n), time complexity O (nlogn).
Enter Description:
In the first line, enter an integer T, followed by T sets of test data. For each set of test data: enter an integer n in the first line, representing an n-pair relationship. Next, enter two numbers x and Y in each line, representing that the user numbered X and y are in the same circle.
1 ≤ T ≤ 10
1 ≤ n ≤ 2 * 106
1 ≤ x, y ≤ 105
Output Description:
For each group of data, output an answer representing the maximum number of people in a circle.
Example:
Input:
2 4 1 2 3 4 5 6 1 6 4 1 2 3 4 5 6 7 8
Output:
4 2
Analyze problems
By analyzing the problem, we can know that this problem is the problem of element grouping, that is, all users are assigned to disjoint circles, and then find the circle with the largest number of people in all circles.
Obviously, we can use union search set to solve it.
First, let's take a look at what a join set is.
Join query set is used to group a series of elements into disjoint sets, and supports merge and query operations.
- Union: merge two disjoint sets into one set.
- Find: query whether two elements are in the same collection.
The important idea of joint search set is to use an element in the set to represent the set.
Theory is always too abstract. Let's illustrate how search sets work through an example.
Here, we compare the collection to a gang, and the representative in the collection is the guild leader.
At the beginning, there were disputes in the Jianghu. All heroes fought their own battles. Each of them was their own guild leader (for a collection with only one element, the representative element is naturally the only element).
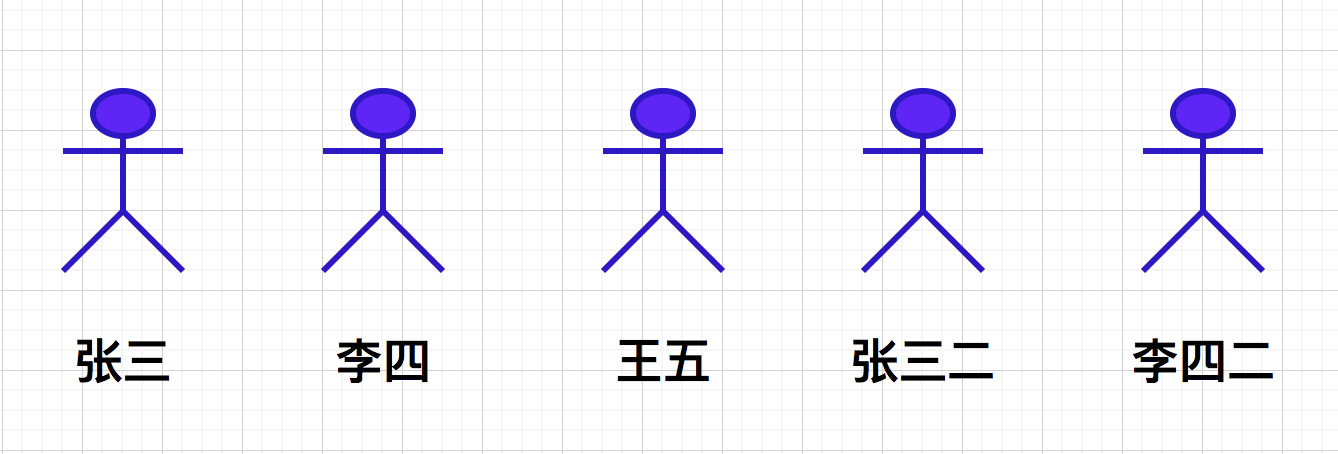
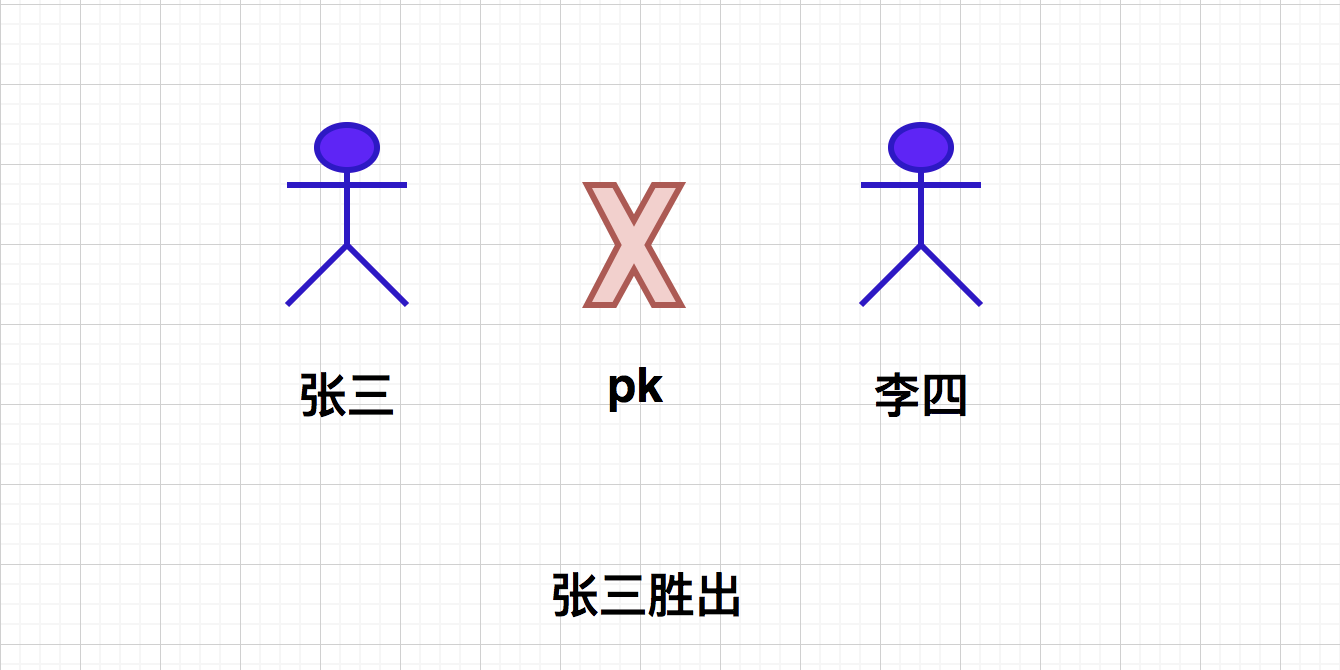
One day, Jianghu people Zhang San and Li Si met accidentally and wanted to recruit each other under their command, so they had a martial arts competition. As a result, Zhang San won, so they recruited Li Si under their command, and Li Si's guild leader became Zhang San (merge the two sets, and the guild leader is the representative element of this set).
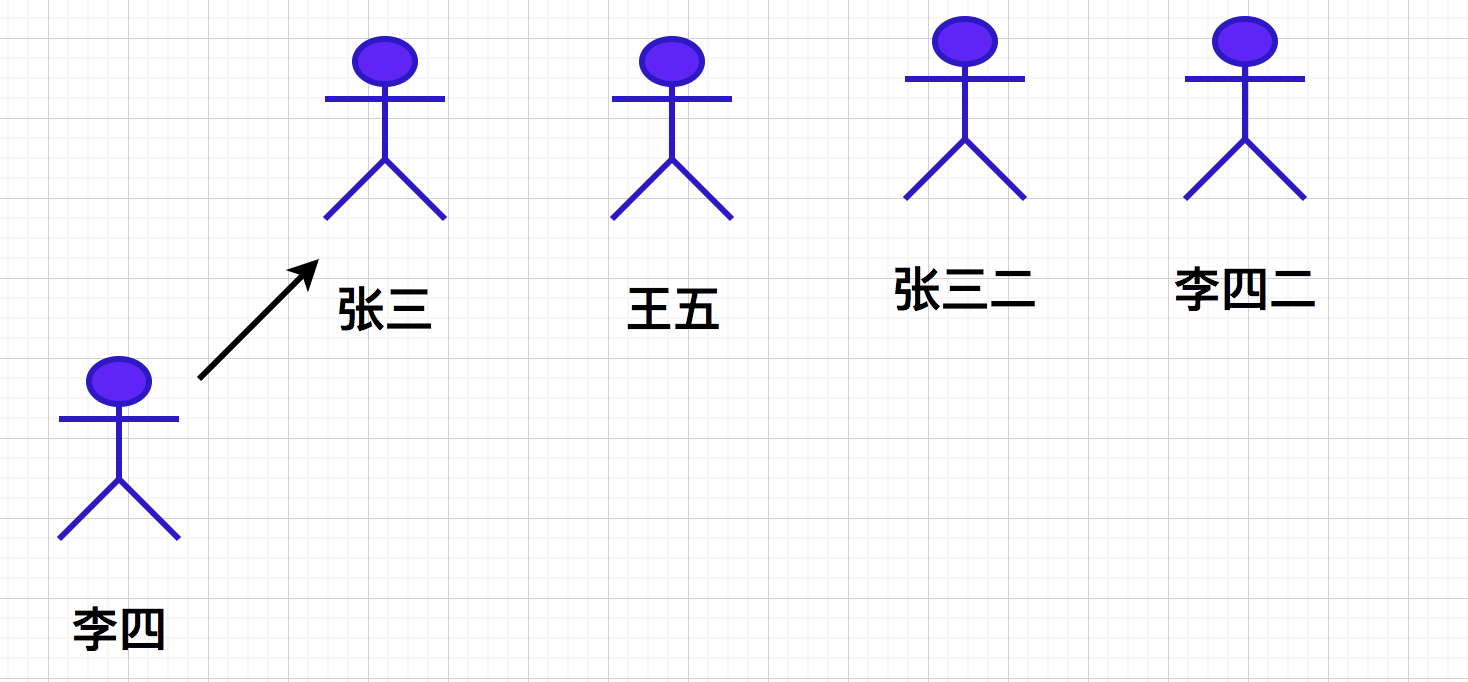
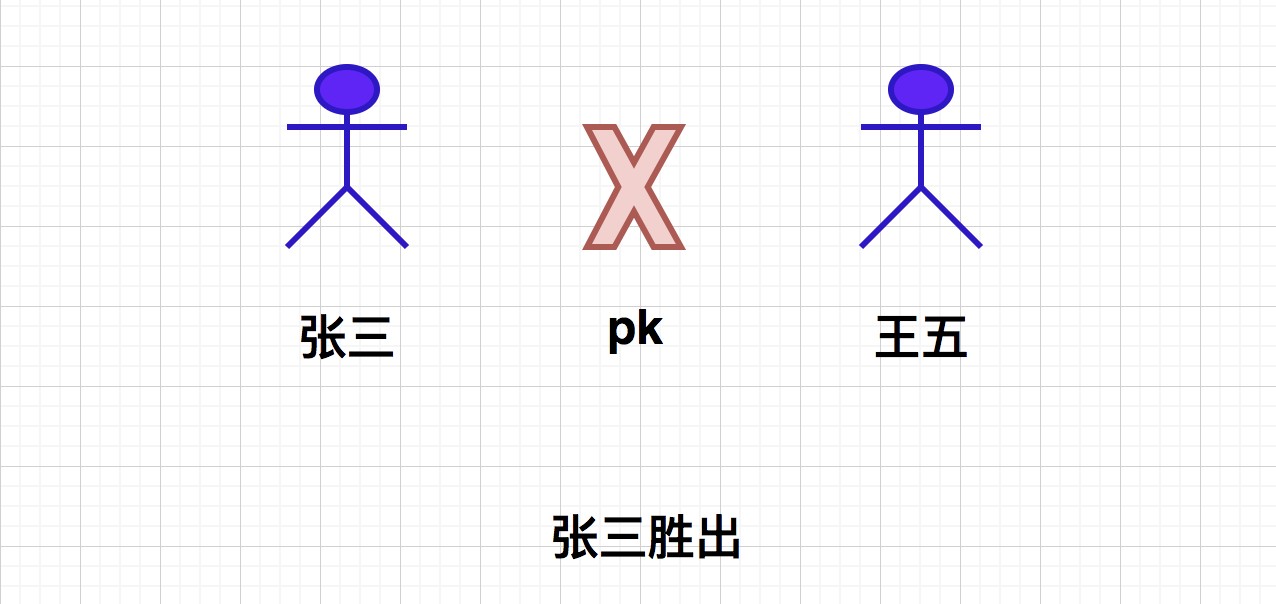
Then, Li Si and Wang Wu met by chance. They disagreed with each other, so they had a martial arts contest. As a result, Li Si lost again (how can Li Si cook so well). At this time, can Li Si accept advice and join Wang Wu's gang? Of course not!! At this time, Li Si is no longer fighting alone, so he calls his boss Zhang San. Zhang San hears that his little brother has been bullied, so he must deal with him!! So he had a competition with Wang Wu. As a result, Zhang San won, and then brought Wang Wu under his command (in fact, Li Si didn't have to compete with Wang Wu, because Li Si was more counselled, so he could directly find his eldest brother to clean up Wang Wu). At this time, Wang Wu's guild leader is also Zhang San.
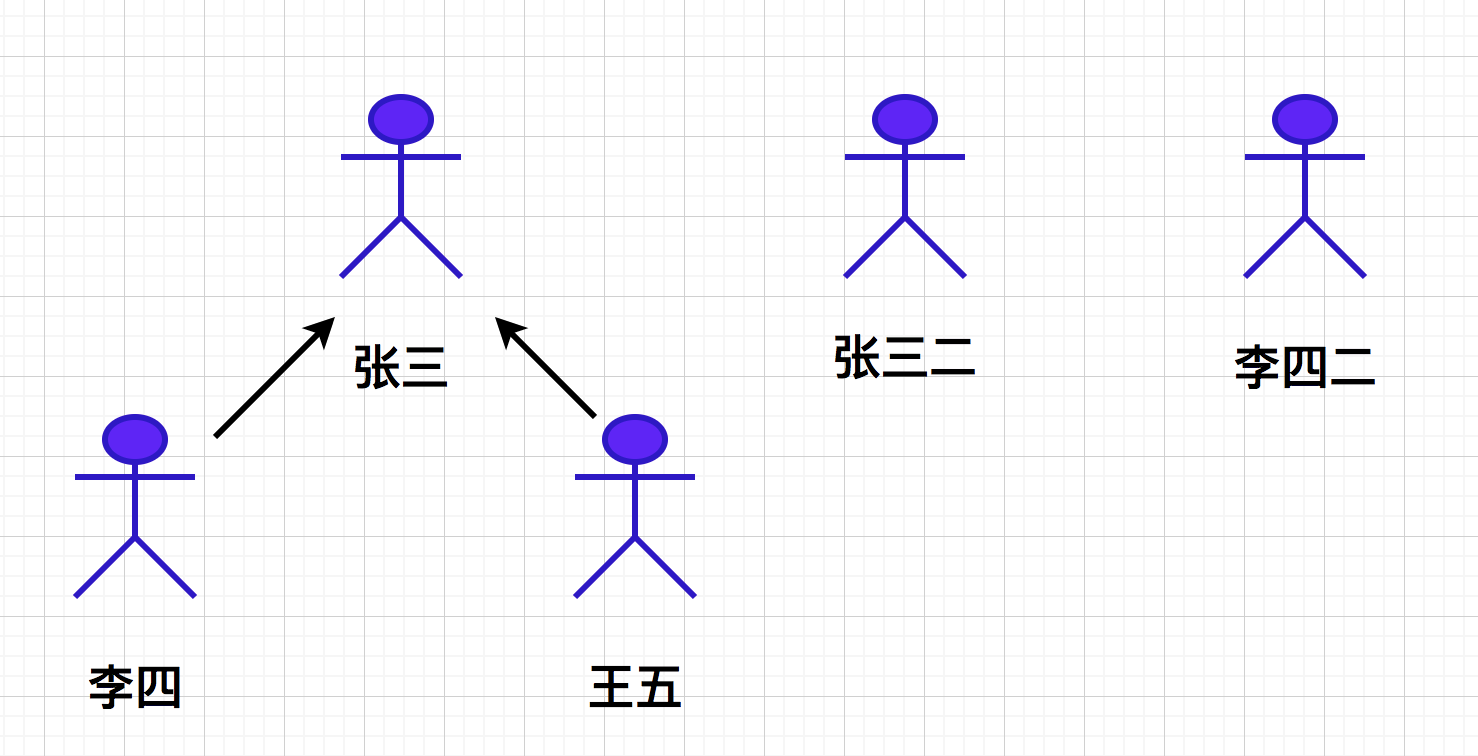
Let's assume that Zhang san'er and Li Si'er also merged gangs, and the Jianghu situation became as follows, forming two major gangs.
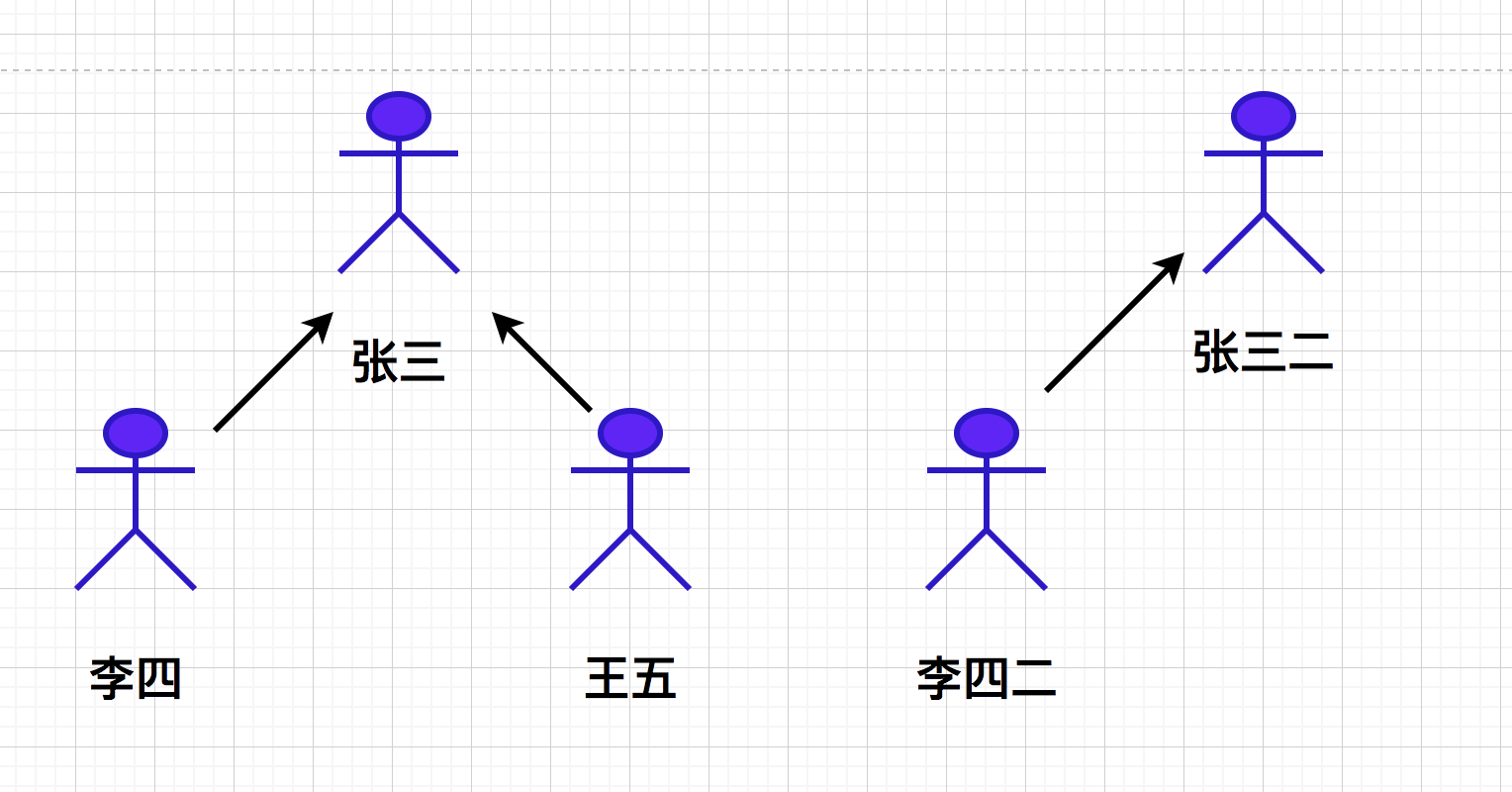
From the above figure, we can know that each gang (a collection) is a tree structure.
To find the representative element (guild leader) of the collection, you only need to access the parent node layer by layer up to the root node of the tree. The parent node of the root node is itself.
Using this method, we can write the simplest version of the search set code.
-
initialization
We use the array fa to store the parent node of each element (where each element has and has only one parent node). At the beginning, they fought their own battles. We set their parent node as ourselves (assuming that there are n elements numbered 1~n).
def __init__(self,n): self.fa=[0]*(n+1) for i in range(1,n+1): self.fa[i]=i -
query
Here, we use a recursive method to find the representative element of an element, that is, access the parent node layer by layer to the root node (the root node refers to the node whose parent node is itself).
def find(self,x): if self.fa[x]==x: return x else: return self.find(self.fa[x]) -
merge
We first find the root node of two elements, and then set the parent node of the former as the latter. Of course, you can also set the parent node of the latter to the former, which is not important for the time being. A more reasonable comparison method will be given later.
def merge(self,x,y): x_root=self.find(x) y_root=self.find(y) self.fa[x_root]=y_root
The overall code is as follows.
class Solution(object):
def __init__(self,n):
self.fa=[0]*(n+1)
for i in range(1,n+1):
self.fa[i]=i
def find(self,x):
if self.fa[x]==x:
return x
else:
return self.find(self.fa[x])
def merge(self,x,y):
x_root=self.find(x)
y_root=self.find(y)
self.fa[x_root]=y_root
optimization
The efficiency of the simplest parallel query code is relatively low. Assume that the current set is as follows.
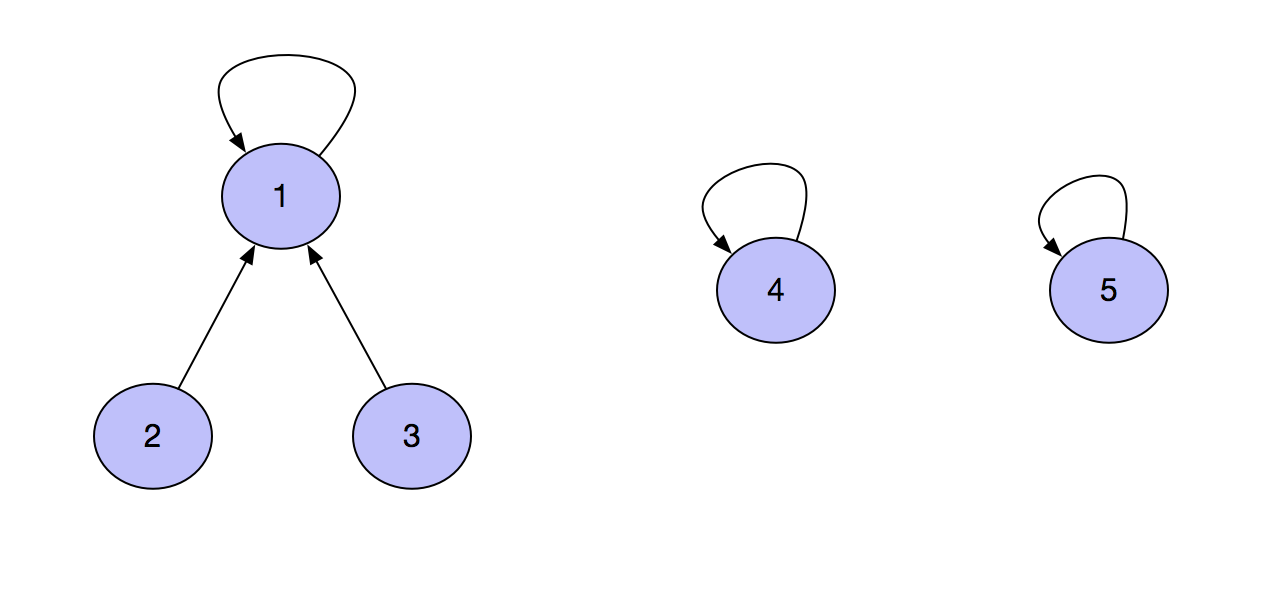
At this time, you need to call the merge(2,4) function, so find 1 from 2, and then execute f[1]=4, that is, the collection situation at this time becomes the following form.
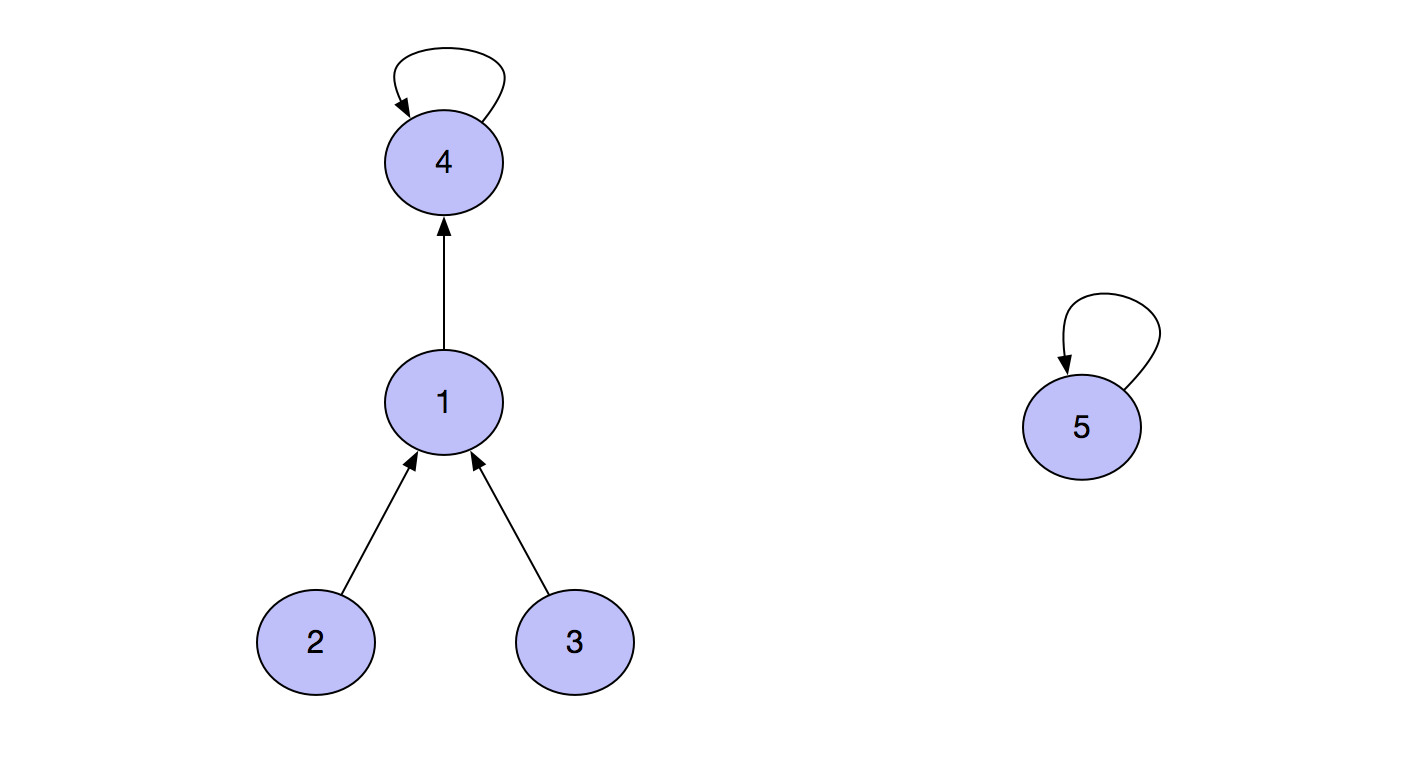
Then we execute the merge(2,5) function, then find 1 from 2, then find 4, and finally execute f[4]=5, that is, the set situation at this time becomes the following form.
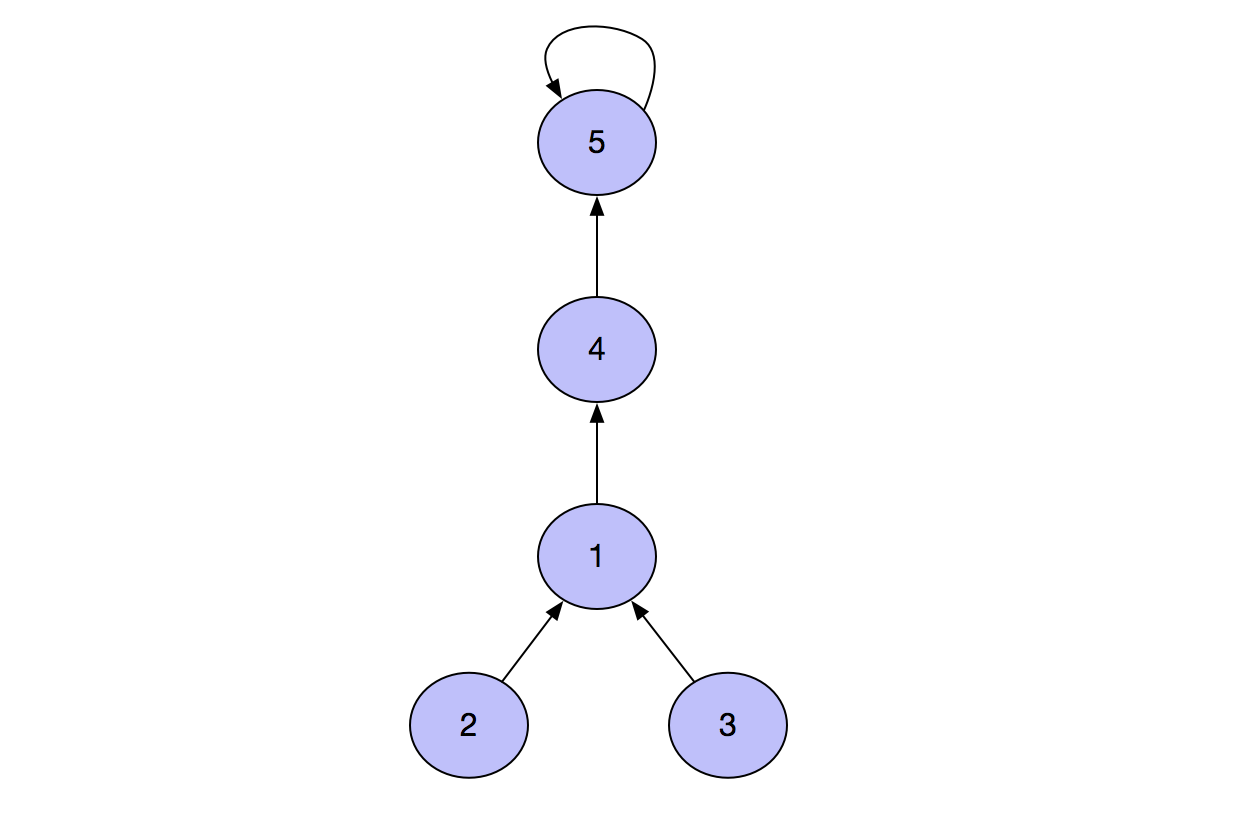
If we continue to execute, we will find that the algorithm may form a long chain. As the chain becomes longer and longer, it will become more and more difficult for us to find the root node from the bottom.
Therefore, we need to optimize. Here, we can use the path compression method, even if the path from each element to the root node is as short as possible.
Specifically, in the process of query, we can set the parent node of each node along the way as the root node. Then the next time you query, you can easily get the root node of the element. The code is as follows:
def find(self,x):
if x==self.fa[x]:
return x
else:
self.fa[x] = self.find(self.fa[x])
return self.fa[x]
After path compression, the time complexity of query set code is very low.
Next, let's further optimize --- merge by rank.
Here we need to explain a point first, because path compression optimization is only performed during query, and only one path can be compressed. Therefore, after path optimization, the final structure of query set may still be complex. Suppose that we now have a complex tree and an element to merge.
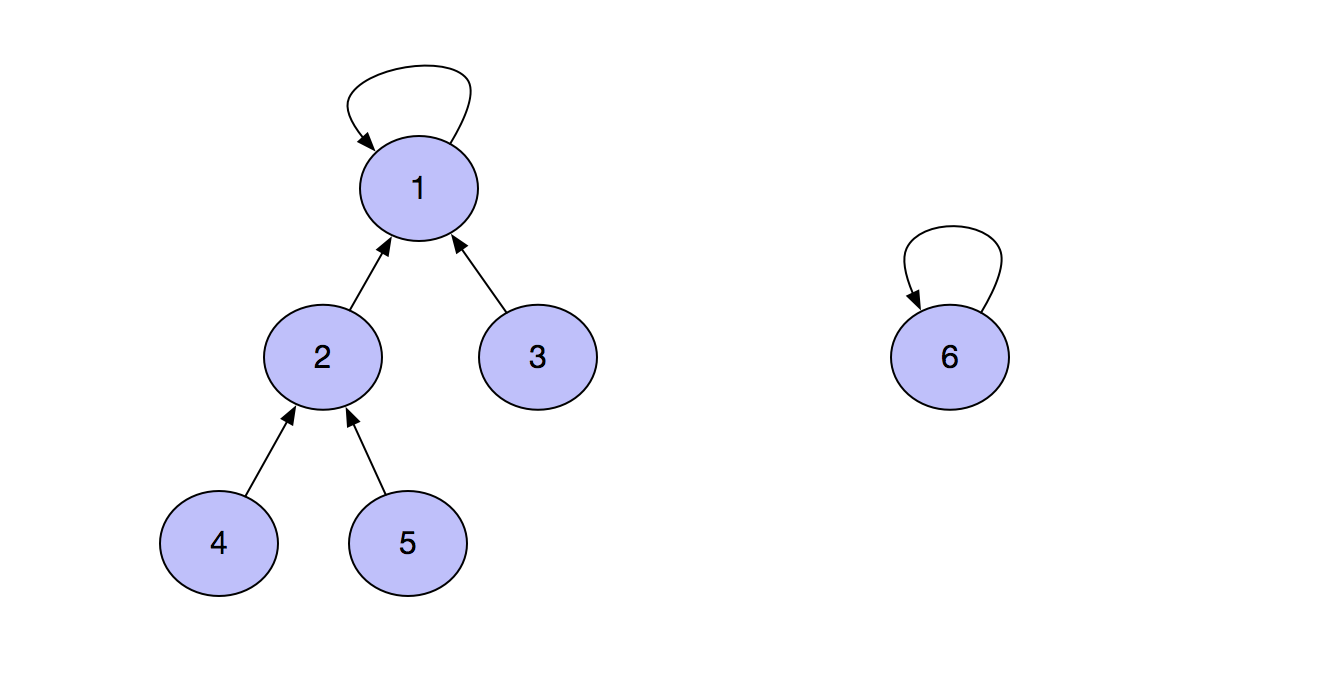
If we want to merge(1, 6) at this time, we should set the parent node of 6 to 1. If the parent node of 1 is set to 6, the depth of the tree will be deepened, which will make the distance from each element in the tree to the root node longer, so that the path for us to find the root node will be longer accordingly. If the parent node of 6 is set to 1, this problem will not occur.
This inspires us to merge simple trees into complex trees, because after merging, the number of nodes with longer distance to the root node is relatively small.
Specifically, we use an array rank to record the depth of the tree corresponding to each root node (if the corresponding element is not the root node of the tree, its rank value is equivalent to the depth of the subtree with it as the root node).
Initially, set the rank of all elements to 1. When merging, compare the two root nodes and merge the smaller rank to the larger one.
Let's take a look at the implementation of the code.
def merge(self,x,y):
#Find a root node corresponding to two elements
x_root=self.find(x)
y_root=self.find(y)
if self.rank[x_root] <= self.rank[y_root]:
self.fa[x_root]=y_root
else:
self.fa[y_root] = x_root
#If the depth is the same and the root node is different, the depth of the new root node
if self.rank[x_root] == self.rank[y_root] \
and x_root != y_root:
self.rank[y_root]=self.rank[y_root]+1
Therefore, our final version of the merge set code is as follows.
class Solution(object):
def __init__(self,n):
self.fa=[0]*(n+1)
self.rank=[0]*(n+1)
for i in range(1,n+1):
self.fa[i]=i
self.rank[i]=i
def find(self,x):
if x==self.fa[x]:
return x
else:
self.fa[x] = self.find(self.fa[x])
return self.fa[x]
def merge(self,x,y):
#Find a root node corresponding to two elements
x_root=self.find(x)
y_root=self.find(y)
if self.rank[x_root] <= self.rank[y_root]:
self.fa[x_root]=y_root
else:
self.fa[y_root] = x_root
#If the depth is the same and the root node is different, the depth of the new root node
if self.rank[x_root] == self.rank[y_root] \
and x_root != y_root:
self.rank[y_root]=self.rank[y_root]+1
With the idea of merging and searching collections, the problem of our circle of friends will be solved. Below we give the code that can AC.
class Solution(object):
def __init__(self,n):
self.fa=[0]*(n+1)
self.rank=[0]*(n+1)
self.node_num=[0]*(n+1)
for i in range(1,n+1):
self.fa[i]=i
self.rank[i]=1
self.node_num[i]=1
def find(self,x):
if x==self.fa[x]:
return x
else:
self.fa[x] = self.find(self.fa[x])
return self.fa[x]
def merge(self,x,y):
#Find a root node corresponding to two elements
x_root=self.find(x)
y_root=self.find(y)
if self.rank[x_root] <= self.rank[y_root]:
#Will x_ Merge root collection into y_ On root
self.fa[x_root]=y_root
self.node_num[y_root] = self.node_num[y_root] + self.node_num[x_root]
else:
#Will y_ Merge root collection into x_ On root
self.fa[y_root] = x_root
self.node_num[x_root] = self.node_num[x_root] + self.node_num[y_root]
#If the depth is the same and the root node is different, the depth of the new root node
if self.rank[x_root] == self.rank[y_root] \
and x_root != y_root:
self.rank[y_root]=self.rank[y_root]+1
if __name__ == '__main__':
#Up to N users
N=100000
result=[]
T = int(input("Please enter how many groups of test data?"))
while T>0:
n = int(input("Enter how many pairs of user relationships"))
print("input{}Group user relationship".format(n))
s1=Solution(N)
for i in range(n):
cur=input()
cur_users=cur.split(" ")
s1.merge(int(cur_users[0]), int(cur_users[1]))
max_people=1
for i in range(len(s1.node_num)):
max_people=max(max_people, s1.node_num[i])
result.append(max_people)
T=T-1
for x in result:
print(x)
That's it. We'll finish our search.
Long winded
Now give a question to think about. You can write your thoughts in the message area.
Now give a kinship diagram to judge whether any given two people have kinship.
Original is not easy! If you think the article is good, you might as well like it (reading), leave a message and forward it!
The more you know, the more open your mind is. I'll see you next time.