The process of locating user records in MySQL can be described as: opening index - > searching B + tree branch node layer by layer according to index key value - > locating leaf node, locating cursor on rec satisfying condition; if tree height is N, then reading N nodes in index tree and comparing them. If buffer_pool is small, a large number of operations will be done on pread and users will ring. In addition, in MySQL, the interaction between Server layer and engine is based on row. engine returns records to server layer. The server layer calculates the row data of engine and then caches or sends them to client. In order to reduce the time needed for interaction, MySQL has made two optimizations:
-
If MYSQL_FETCH_CACHE_THRESHOLD(4) records are continuously retrieved from the same query statement, the function row_sel_enqueue_cache_row_for_mysql is called to cache MYSQL_FETCH_CACHE_SIZE(8) records into prebuild-> fetch_cache, and in subsequent prebuild-> n_fetch_cached interactions, data is retrieved directly from prebuild-> fetch_cache to server layer. The problem is that even if the user only needs four pieces of data, the Engine layer will put MYSQL_FETCH_CACHE_SIZE data into fetch_cache, resulting in unnecessary cache usage. In addition, 5.7 can adjust the number of cached user records according to user settings.
-
Engine will save cursor's location when it takes out data. When it takes down one data, it will try to restore cursor's location. If it succeeds, it will continue to take down one data. Otherwise, cursor's location will be relocated. Thus, the interaction time between server layer and engine layer can be reduced by saving cursor's location.
The process of interaction between Server layer and engine layer is as follows. Because the row format of Server and engine is different, the cost of engine row format - > Server row format in reading scenario is also relatively large.
while (rc == NESTED_LOOP_OK && join->return_tab >= join_tab)
{
int error;
if (in_first_read)
{
in_first_read= false;
error= (*join_tab->read_first_record)(join_tab);
}
else
error= info->read_record(info); /* load data from engine */
rc= evaluate_join_record(join, join_tab); /* computed by server */
}
Functional role of AHI
From the above analysis, we can see that MySQL once locates cursor is the path from root node to leaf node, and the time complexity is: height(index) + [CPU cost time]. The above two optimization processes can not omit locating cursor intermediate node, so we need to introduce a method that can locate cursor from search info to leaf node to omit root node. The time consumed on the path to the leaf node is adaptive hash index (AHI). Query statements have the following advantages when using AHI:
- It can directly locate the leaf nodes from the query conditions to reduce the time needed for one location.
- In the case of insufficient buffer pool, the cache can be established only for hot data pages, thus avoiding frequent LRU s of data pages.
However, AHI does not always improve performance. In the case of multi-table Join & fuzzy query-query conditions changing frequently, when the resources used by the system to monitor AHI are greater than the above benefits, not only can it not give full play to the advantages of AHI, but also bring additional CPU consumption to the system. At this time, it is necessary to shut down AHI to avoid unnecessary waste of system resources. Adaptation scenarios can be referred to: mysql_adaptive_hash_index_implementation.
AHI Memory Structure
_AHI monitors and analyses the conditions in the query statement (which will be described in detail later). When the conditions for the establishment of AHI cache are satisfied, several prefix index columns of the index are selected to construct hash page s for hot data pages to record the corresponding relationship between hash value - > page blocks. This section mainly introduces the memory structure of AHI-memory source. Shao, its memory structure is as follows:
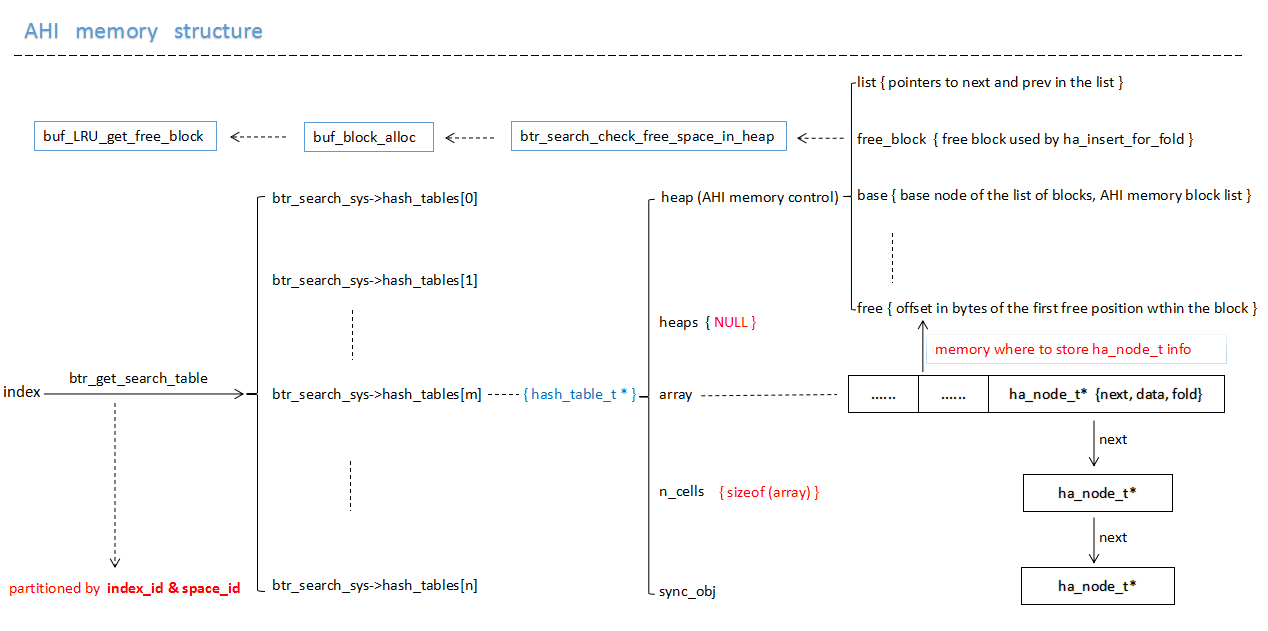
The figure above is a schematic diagram of the memory structure of AHI. AHI mainly uses the following two kinds of memory:
- The memory allocated by system initialization is hash_table, in which the array size of each hash_table is: (buf_pool_get_curr_size()/ sizeof (void*)/ 64). According to the number of machine bits, the array size is different, 32-bit machine is 1/256 of buffer_pool size, 64-bit machine is 1/512 of buffer_pool size, this part of memory is system memory (mem_area_c-> allomalloc), master. To build hash_table structure;
#0 mem_area_alloc (psize=0x7fffffff9888, pool=0x19c27c0) at ../storage/innobase/mem/mem0pool.cc:380
#1 0x0000000000bafb00 in mem_heap_create_block_func (heap=0x0, n=72, file_name=0x10bd7f8 "../storage/innobase/ha/hash0hash.cc", line=303, type=0)
at ../storage/innobase/mem/mem0mem.cc:336
#2 0x0000000000d91c3a in mem_heap_create_func (n=72, file_name=0x10bd7f8 "../storage/innobase/ha/hash0hash.cc", line=303, type=0) at ../storage/innobase/include/mem0mem.ic:449
#3 0x0000000000d91d78 in mem_alloc_func (n=72, file_name=0x10bd7f8 "../storage/innobase/ha/hash0hash.cc", line=303, size=0x0) at ../storage/innobase/include/mem0mem.ic:537
#4 0x0000000000d9358b in hash0_create (n=16352) at ../storage/innobase/ha/hash0hash.cc:303
#5 0x0000000000d8f699 in ha_create_func (n=16352, sync_level=0, n_sync_obj=0, type=3) at ../storage/innobase/ha/ha0ha.cc:67
#6 0x0000000000cfeaff in btr_search_sys_create (hash_size=16352) at ../storage/innobase/btr/btr0sea.cc:179
#7 0x0000000000d099f9 in buf_pool_init (total_size=8388608, n_instances=1) at ../storage/innobase/buf/buf0buf.cc:1498
...
(gdb) n
381 return(malloc(*psize));
- When AHI constructs AHI cache for data pages, it uses the memory in buffer_pool's free link, that is buffer_pool's memory, so it is necessary to maintain the AHI cache when page data changes.
Analytical Implementation of AHI
[The scope of AHI in the query process]
The interaction between Server and Innodb in MySQL is based on the action unit. The process of Innodb's line-by-line data acquisition can be divided into the following six steps:
- 0. If it is found that other threads need to lock btr_search_latch, release btr_search_latch and execute 1; (5.6-5.7 is different in implementation)
- 1. Attempt to retrieve database records from row_prebuilt_t-> fetch_cache and return them directly. If there is no data or fetch cache is not available, execute 2.
- 2. Use AHI to locate cursor position and return data if conditions are satisfied, otherwise execute 3.
- 3. Confirm whether cursor can be restored from row_prebuilt_t according to the value of direction. If direction = 0 or cursor can not be restored from row_prebuilt_t, call btr_pcur_open_at_index_to open the index, call btr_cur_search_to_nth_level, and if AHI is used, locate the leaf node quickly, otherwise traverse the index nodes. Point cursor, then enter 4; if it can be restored from row_prebuilt_t, execute 5;
- 4. Match the values one by one in the leaf nodes, find the records that satisfy the conditions, return the data, and execute 3,5 when the next record is taken.
- 5. Move cursor to the next record and return data.
AHI affects the process of locating leaf nodes in the two steps of [2,3]. It plays the role of hash in the process of locating leaf nodes according to query conditions. The implementation of AHI mainly includes the initialization process, construction conditions, use process, maintenance process, system monitoring and so on. We analyze the above process from the perspective of source code implementation.
[AHI initialization process]
As a part of buffer_pool, AHI is a hash_table that establishes the query condition and the location of REC in memory. When the system starts, it automatically establishes the corresponding memory structure with the initialization of buffer_pool. The initialization process is as follows:
- The system memory (malloc) is used to create the global variable btr_search_sys and its lock structure.
- The hash_table memory structure is established by using system memory (malloc) and its member variables are initialized. The size of the hash_table array depends on the size of the current buffer_pool and the number of machines in the system. The calculation formula is buf_pool_get_curr_size()/ sizeof (void*)/ 64. The structure of hash_table_t is as follows:
(gdb) p table
$37 = (hash_table_t *) 0x1aabfc8
(gdb) p *table
$38 = {
type = HASH_TABLE_SYNC_NONE,
adaptive = 0,
n_cells = 0,
array = 0x0,
n_sync_obj = 0,
sync_obj = {
mutexes = 0x0,
rw_locks = 0x0
},
heaps = 0x0,
heap = 0x0,
magic_n = 0
}
Explain:
- All buffer_pool instances share an AHI instead of an AHI for each buffer_pool instance.
- Before 5.7.8, AHI had only one global lock structure, btr_search_latch. When the pressure was high, performance bottlenecks would occur. 5.7.8 unlocked the AHI. Details can be referred to as functions: btr_get_search_table() & btr_search_sys_create().
- btr_search_latch of AHI( bug#62018 )& Index lock is two of the larger locks in MySQL. Details can be consulted. Index lock and adaptive search – next two biggest InnoDB problems 5.7 By splitting the AHI lock (5.7 commit id: ab17ab91) and introducing different index lock protocols( WL#6326 ) These two problems have been solved.
[Conditions for the Construction of AHI]
AHI is based on the mapping information between search info & REC memory addresses. There is not enough information to establish the mapping information of AHI before the system receives access. Therefore, it is necessary to collect the search_info & block info information during the execution of SQL statements and determine whether the AHI cache can be established for data pages.
_search info corresponds to btr_search_t, which is used to record n_fields (prefix index column number) & n_bytes (last column bytes) information in index, which is used to calculate fold value.
In addition to the fields & bytes required for calculating fold values, the number of potential successes of using AHI on this data page in this case is also recorded.
We briefly describe several aspects of AHI statistical information.
- Conditions for triggering AHI index statistics
When the AHI is opened, btr_cur_search_to_nth_level is invoked before the return of btr_cur_search_to_nth_level to update the corresponding statistical information. If the current index serch_info-> hash_analysis < BTR_SEARCH_HAYSIS(17), then the search info & search info_to_nth_level is invoked to update the corresponding statistical information. Otherwise, the information of search info & block info will be updated by calling btr_search_info_update_slow.
void btr_search_info_update(
/*===================*/
dict_index_t* index, /*!< in: index of the cursor */
btr_cur_t* cursor) /*!< in: cursor which was just positioned */
{
...
info->hash_analysis++;
if (info->hash_analysis < BTR_SEARCH_HASH_ANALYSIS) {
/* Do nothing */
return;
}
btr_search_info_update_slow(info, cursor);
}
- Updating and Adaptation of Index Query Information (index->search_info) in AHI
Background: In the process of locating cursor in btr_cur_search_to_nth_level, page_cur_search_with_match is called at each level of the tree to determine the next branch node or leaf node. The page_cur_search_with_match function records the number of prefix index columns that are compared during the query process {cursor-> up_match, cursor-> up_bytes, cursor_up_match -> Low_bytes, cursor-> low_match}, the purpose is to save the minimum comparing unit in the comparing process with search tuple. Detailed calculation process can refer to the page_cur_search_with_match implementation code.
_
Secondly, if the current index info-> n_hash_potential = 0, the prefix index columns {cursor-> up_match, cursor-> up_bytes, cursor-> low_bytes, cursor-> low_match} will be recommended from the recommended algorithm {cursor-> up_bytes, cursor-> low_match} to calculate the value of the key {ha_node_t-> fold} stored in AHI.
When info-> n_hash_potential!= 0, it will judge whether the matching mode saved in the current query matching mode, index-> search_info, has changed or not, and if there is no change, it will increase the number of potential AHI success in this mode (info-> n_hash_potential). Otherwise, it is necessary to re-recommend prefix index columns and other relevant information, and empty info-> n_hash_poten_potential. The value of TiAl (info - > n_hash_potential = 0), AHI uses this method to achieve self-adaptive, so it is not recommended to change the query condition frequently in the system of opening AHI. The calculation process of prefix index and other information is as follows:
btr_search_info_update_hash
{
...
/* We have to set a new recommendation; skip the hash analysis
for a while to avoid unnecessary CPU time usage when there is no
chance for success */
info->hash_analysis = 0;
cmp = ut_pair_cmp(cursor->up_match, cursor->up_bytes,
cursor->low_match, cursor->low_bytes);
if (cmp == 0) {
info->n_hash_potential = 0;
/* For extra safety, we set some sensible values here */
info->n_fields = 1;
info->n_bytes = 0;
info->left_side = TRUE;
} else if (cmp > 0) {
info->n_hash_potential = 1;
if (cursor->up_match >= n_unique) {
info->n_fields = n_unique;
info->n_bytes = 0;
} else if (cursor->low_match < cursor->up_match) {
info->n_fields = cursor->low_match + 1;
info->n_bytes = 0;
} else {
info->n_fields = cursor->low_match;
info->n_bytes = cursor->low_bytes + 1;
}
info->left_side = TRUE;
} else {
info->n_hash_potential = 1;
if (cursor->low_match >= n_unique) {
info->n_fields = n_unique;
info->n_bytes = 0;
} else if (cursor->low_match > cursor->up_match) {
info->n_fields = cursor->up_match + 1;
info->n_bytes = 0;
} else {
info->n_fields = cursor->up_match;
info->n_bytes = cursor->up_bytes + 1;
}
info->left_side = FALSE;
}
}
From the above algorithm, we can see that the selection of {info-> n_fields, info-> n_bytes, info-> left_side} is based on the minimum calculation cost without exceeding the number of unique index columns, while the value of index-> info-> left_side determines whether the leftmost record or the rightmost record of the same prefix index is stored on the same data page.
- Update of block Information on Data Pages
The update of block info of data page mainly includes index matching mode on data page, the number of times of success in existing index matching mode and the judgment of whether to build AHI cache information for the data page. The main process is as follows:
1) Set index - > Info - > last_hash_succ to FALSE, at which time other threads can not use the AHI function on the index;
2) If the matching format of index - > search_info is the same as the matching mode saved on the data page, the block - > n_hash_help will be increased. If the AHI cache has been established for the data page, the index - > Info - > last_hash_succ = TRUE will be set.
3) If the matching format of index - > search_info is different, set block - > n_hash_help=1 and reset the index matching information on the block using index - > search_info. The detailed process can refer to btr_search_update_block_hash_info.
4) Determine whether it is necessary to create an AHI cache for a data page. When the number of successful AHI usage on a data page block is greater than 1/16 of the user records on the data page and the number of successful AHI usage on the current prefix index is greater than 100, if the number of potential successful AHI usage on the data page is more than twice the number of user records on the data page or the currently recommended prefix index letter. When information changes, you need to construct AHI cache information for data pages. For details, you can refer to the following code.
if ((block->n_hash_helps > page_get_n_recs(block->frame)
/ BTR_SEARCH_PAGE_BUILD_LIMIT)
&& (info->n_hash_potential >= BTR_SEARCH_BUILD_LIMIT)) {
if ((!block->index)
|| (block->n_hash_helps > 2 * page_get_n_recs(block->frame))
|| (block->n_fields != block->curr_n_fields)
|| (block->n_bytes != block->curr_n_bytes)
|| (block->left_side != block->curr_left_side)) {
/* Build a new hash index on the page */
return(TRUE);
}
}
[AHI Construction Process (Collection & Judgment & Establishment)]
The construction process of_AHI refers to the hash relation of query condition-data page based on index-> search_info. The main process is as follows:
1) Collecting hash information. Traveling through all user records on the data page, an array {folds, recs} is established by mapping between prefix index information and physical records, where index - > Info - > left_side is used to determine how to save physical page records under the same prefix index column. It can be seen from the code that when left_side is TRUE, the records with the same prefix index column are only the leftmost records. When left_side is FALSE, records with the same prefix index column only keep the rightmost records. The code is implemented as follows:
for (;;) {
next_rec = page_rec_get_next(rec);
if (page_rec_is_supremum(next_rec)) {
if (!left_side) {
folds[n_cached] = fold;
recs[n_cached] = rec;
n_cached++;
}
break;
}
offsets = rec_get_offsets(next_rec, index, offsets,
n_fields + (n_bytes > 0), &heap);
next_fold = rec_fold(next_rec, offsets, n_fields,
n_bytes, index->id);
if (fold != next_fold) {
/* Insert an entry into the hash index */
if (left_side) {
folds[n_cached] = next_fold;
recs[n_cached] = next_rec;
n_cached++;
} else {
folds[n_cached] = fold;
recs[n_cached] = rec;
n_cached++;
}
}
rec = next_rec;
fold = next_fold;
}
2) If the previous data page already has AHI cache information but the prefix index information is inconsistent with the current information, the previously cached AHI information will be released. If the release exceeds a page size, the released data page will be returned to buffer_pool-> free list.
3) Call btr_search_check_free_space_in_heap to ensure t ha t AHI has enough memory to generate mapping information ha_node_t{fold, data, next}, which is obtained from buffer_pool-> free list. Details are as follows: buf_block_alloc(), rec_fold(), a reference function for calculating the value of fold;
4) Since btr_search_latch is released in the process of operation, it is necessary to check again whether the AHI information on the block has changed and exit the function if it has changed.
5) Call the ha_insert_for_fold method to generate the previously collected information into ha_node_t and store it in an array of btr_search_sys-> hash_table, in which the stored structure can refer to the AHI memory structure.
for (i = 0; i < n_cached; i++) {
ha_insert_for_fold(table, folds[i], block, recs[i]);
}
[Conditions for the Use of AHI and the Process of Locating Leaf Nodes]
In the section "The scope of the role of AHI in the query process", we introduce in detail the interaction mode of Server-Engine layer in MySQL and the position and role of AHI in the whole process. Next, we will look at how AHI works in step 2 and 3.
Step 2 is a short cut query method using AHI. It can only use the short cut query method of AHI after satisfying very harsh conditions. These harsh conditions include:
1) The current index is cluster index.
2) The current query is unique search;
3) The current query does not contain large fields of blob type;
4) Record length should not be greater than page_size/8;
5) Queries that do not use memcache interface protocols;
6) Things are open and the isolation level is higher than READ UNCOMMITTED;
7) Simple select query instead of function & procedure;
The short cut query of AHI can be used to locate leaf nodes only after satisfying the above conditions. The operation after satisfying the conditions in 5.7 can be simply described as:
rw_lock_s_lock(btr_get_search_latch(index));
...
row_sel_try_search_shortcut_for_mysql()
...
rw_lock_s_lock(btr_get_search_latch(index));
Step 3: Using AHI to locate leaf nodes quickly also needs to meet some conditions. Specific reference code: btr_cur_search_to_nth_level(), which is not mentioned here, we focus on the process of locating leaf nodes using AHI.
1) To lock the hash_table where index is located, the key fold is calculated by using the tuple information in the query condition.
rw_lock_s_lock(btr_search_get_latch(index)); fold = dtuple_fold(tuple, cursor->n_fields, cursor->n_bytes, index_id);
2) Find ha_node_t of key = fold on hash_table;
const rec_t*
ha_search_and_get_data(
/*===================*/
hash_table_t* table, /*!< in: hash table */
ulint fold) /*!< in: folded value of the searched data */
{
ha_node_t* node;
hash_assert_can_search(table, fold);
ut_ad(btr_search_enabled);
node = ha_chain_get_first(table, fold);
while (node) {
if (node->fold == fold) {
return(node->data);
}
node = ha_chain_get_next(node);
}
return(NULL);
}
rec = (rec_t*) ha_search_and_get_data(btr_search_get_hash_table(index), fold);
3) Release lock resources and locate leaf nodes according to the returned records;
block = buf_block_align(rec);
rw_lock_s_unlock(btr_search_get_latch(index));
btr_cur_position(index, (rec_t*) rec, block, cursor);
4) The process of locating leaf nodes is similar to that of not using AHI, and returns to record cursor location directly.
AHI Maintenance & Monitoring
In MySQL 5.7, there are two AHI-related parameters: innodb_adaptive_hash_index, innodb_adaptive_hash_index_parts, in which innodb_adaptive_hash_index is a dynamically adjusted parameter to control whether the AHI function is turned on or not; innodb_adaptive_hash_index_parts are read-only parameters, which can not be modified during the running of the example and used to adjust the AHI partition. Number (5.7.8 introduced) to reduce lock conflicts. Detailed description can be referred to official instructions: innodb_adaptive_hash_index, innodb_adaptive_hash_index This section mainly introduces the commands related to the operation of AHI and the internal implementation process of the commands.
1) Open AHI Operations - Internal Implementation
set global innodb_adaptive_hash_index=ON. This command only sets global variables. The code is as follows:
Enable the adaptive hash search system. */
UNIV_INTERN
void
btr_search_enable(void)
/*====================*/
{
btr_search_x_lock_all();
btr_search_enabled = TRUE; /* global variables which indicate whether AHI can be used */
btr_search_x_unlock_all();
}
2) Turn off AHI operations - internal implementation
set global innodb_adaptive_hash_index= OFF, this command is used to turn off the AHI function, specific implementation can refer to btr_search_disable(), close the process description:
- Set btr_search_enabled = FALSE and turn off the AHI function.
- Set ref_count of all cached table objects in the data dictionary to 0. Only when btr_search_info_get_ref_count(info, index) = 0 can the cached objects in the data dictionary be cleared. For more details, see dict_table_can_be_evicted().
- The statistical information in all data pages is blanked, and the specific implementation can refer to buf_pool_clear_hash_index().
- To release buffer_pool memory used by AHI, btr_search_disable is implemented as follows:
Disable the adaptive hash search system and empty the index. */
UNIV_INTERN
void
btr_search_disable(void)
/*====================*/
{
dict_table_t* table;
ulint i;
mutex_enter(&dict_sys->mutex);
btr_search_x_lock_all();
btr_search_enabled = FALSE;
/* Clear the index->search_info->ref_count of every index in
the data dictionary cache. */
for (table = UT_LIST_GET_FIRST(dict_sys->table_LRU); table;
table = UT_LIST_GET_NEXT(table_LRU, table)) {
btr_search_disable_ref_count(table);
}
for (table = UT_LIST_GET_FIRST(dict_sys->table_non_LRU); table;
table = UT_LIST_GET_NEXT(table_LRU, table)) {
btr_search_disable_ref_count(table);
}
mutex_exit(&dict_sys->mutex);
/* Set all block->index = NULL. */
buf_pool_clear_hash_index();
/* Clear the adaptive hash index. */
for (i = 0; i < btr_search_index_num; i++) {
hash_table_clear(btr_search_sys->hash_tables[i]);
mem_heap_empty(btr_search_sys->hash_tables[i]->heap);
}
btr_search_x_unlock_all();
}
3) Maintenance of AHI Cache Information
AHI maintains the hash relationship of search info & REC in physical memory address. When the location of physical record or the address of block changes, AHI also needs to maintain it accordingly, such as inserting new records, deleting table records, splitting data pages, drop table & alter table, LRU page change, etc. The details can be referred to the implementation of the function btr_search_update_hash_ref() & btr_search_drop_page_hash_index() & buf_LRU_drop_page_hash_for_tablespace().
4) Monitoring of AHI Information
By default, AHI only monitors adaptive_hash_searches (number of queries using AHI) & adaptive_hash_searches_btree (number of queries using bree d, need to traverse the branch node). More detailed monitoring needs additional settings. Detailed setting methods can be referred to. innodb_monitor_enable &module_adaptive_hash Open the monitoring method of AHI, use monitoring and reset monitoring methods as follows:
MySQL [information_schema]> set global innodb_monitor_enable = module_adaptive_hash;
Query OK, 0 rows affected (0.00 sec)
MySQL [information_schema]> select status, name, subsystem,count, max_count, min_count, avg_count, time_enabled, time_disabled from INNODB_METRICS where subsystem like '%adaptive_hash%';
+---------+------------------------------------------+---------------------+--------+-----------+-----------+--------------------+---------------------+---------------+
| status | name | subsystem | count | max_count | min_count | avg_count | time_enabled | time_disabled |
+---------+------------------------------------------+---------------------+--------+-----------+-----------+--------------------+---------------------+---------------+
| enabled | adaptive_hash_searches | adaptive_hash_index | 259530 | 259530 | NULL | 1663.6538461538462 | 2016-12-16 14:03:07 | NULL |
| enabled | adaptive_hash_searches_btree | adaptive_hash_index | 143318 | 143318 | NULL | 918.7051282051282 | 2016-12-16 14:03:07 | NULL |
| enabled | adaptive_hash_pages_added | adaptive_hash_index | 14494 | 14494 | NULL | 127.14035087719299 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_pages_removed | adaptive_hash_index | 0 | NULL | NULL | 0 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_rows_added | adaptive_hash_index | 537933 | 537933 | NULL | 4718.710526315789 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_rows_removed | adaptive_hash_index | 0 | NULL | NULL | 0 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_rows_deleted_no_hash_entry | adaptive_hash_index | 0 | NULL | NULL | 0 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_rows_updated | adaptive_hash_index | 0 | NULL | NULL | 0 | 2016-12-16 14:03:49 | NULL |
+---------+------------------------------------------+---------------------+--------+-----------+-----------+--------------------+---------------------+---------------+
8 rows in set (0.00 sec)
MySQL [information_schema]> set global innodb_monitor_reset_all='adaptive_hash_%';
Query OK, 0 rows affected (0.00 sec)
MySQL [information_schema]> set global innodb_monitor_disable='adaptive_hash%';
Query OK, 0 rows affected (0.00 sec)
MySQL [information_schema]> select status, name, subsystem,count, max_count, min_count, avg_count, time_enabled, time_disabled from INNODB_METRICS where subsystem like '%adaptive_hash%';
+----------+------------------------------------------+---------------------+-------+-----------+-----------+-----------+--------------+---------------+
| status | name | subsystem | count | max_count | min_count | avg_count | time_enabled | time_disabled |
+----------+------------------------------------------+---------------------+-------+-----------+-----------+-----------+--------------+---------------+
| disabled | adaptive_hash_searches | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_searches_btree | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_pages_added | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_pages_removed | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_rows_added | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_rows_removed | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_rows_deleted_no_hash_entry | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_rows_updated | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
+----------+------------------------------------------+---------------------+-------+-----------+-----------+-----------+--------------+---------------+
8 rows in set (0.00 sec)
It is worth mentioning that the state is reset only by executing set global innodb_monitor_reset_all='adaptive hash%'& set global innodb_monitor_disable='adaptive_hash%'. If adaptive_hash_searches << adaptive_hash_searches_btree is found, the AHI should be closed to reduce unnecessary system consumption.
Related recommendations
High Availability Analysis of MySQL Database
Documents related to Tencent Cloud Database CDB for MySQL
MySQL Development Practice 8: How many can you hold?
This article has been authorized by the author to be published by Tencent Cloud Technology Community. Please indicate if it is reproduced. Article provenance For more dry goods of cloud computing technology, please go to Tencent Cloud Technology Community
Wechat Public Signal: Qcloud Community