Author: Hong bin The person in charge and technical service director of akerson South District, MySQL ace, is good at database architecture planning, fault diagnosis, performance optimization analysis, with rich practical experience, helping customers in various industries to solve MySQL technical problems, and providing overall MySQL solutions for customers in finance, operators, Internet and other industries. Source: reproduced from official account - fun MySQL *Aikesheng is produced by the open source community. The original content cannot be used without authorization. Please contact the editor for reprint and indicate the source.
MySQL parallel playback is improved in one way, from 5.6 schema parallel to 5.7 group commit to 8.0 write set.
MTS based on schema
Needless to say, this method involves DML operations of different schemas, which can be played back in parallel according to the schema granularity at the slave end. The weakness is also obvious. If there are fewer schemas in the instance, the effect of parallel playback is not ideal. Its optimization mode is also relatively simple_ parallel_ Workers is less than or equal to the number of schema s of the master.
LOGICAL_CLOCK
MySQL 5.7 adds a group commit based parallel playback strategy, so that slave can be close to the same concurrent playback transaction of the master. The higher the concurrency of the master, the more obvious the parallel playback effect of slave.
There will be two more tags for each transaction in binlog
**sequence_number: * * the incremental ID of each transaction. Each new binlog will start from 1
**last_committed: * * the sequence of the last transaction on which the current transaction depends_ Number, every time a new binlog starts from 0
last_ Transactions with the same value of committed represent those submitted at the same time and can be played back in parallel.
#180105 20:08:33 ... last_committed=7201 sequence_number=7203 #180105 20:08:33 ... last_committed=7203 sequence_number=7204 #180105 20:08:33 ... last_committed=7203 sequence_number=7205 #180105 20:08:33 ... last_committed=7203 sequence_number=7206 #180105 20:08:33 ... last_committed=7205 sequence_number=7207
- 7203 transaction depends on 7201
- 7204, 7205, 7206 transactions rely on 7203 and can be submitted in parallel
- 7207 transaction depends on 7205. Since 7205 depends on 7203, 7207 can be executed in parallel with 7206 after 7205 is executed
The optimization method improves the parallel efficiency by adjusting the master group commit size and the number of parallel work threads of slave.
The master group commit size is related to the concurrent pressure and the following two parameters
binlog_group_commit_sync_delay indicates how many microseconds binlog waits before committing a transaction
binlog_group_commit_sync_no_delay_count indicates the maximum number of transactions allowed in the synchronization queue. When the number of threads waiting for submission reaches, they are not waiting
Under the low concurrent load of the master, the parallel playback effect is not good. If you want to improve the parallelism, you need to add binlog_group_commit_sync_delay, accumulate more packet sizes, and the side effect is to pull down the master throughput.
Write set
MySQL 8.0.1 & 5.7.22 further improves the efficiency of parallel replication based on group commit, and adds a new mechanism to track transaction dependency. Compared with the transaction based commit timestamp, even in the low concurrency scenario of the master, the slave can be replayed in parallel according to the transaction dependency, making full use of the hardware resources, and no need to add binlog like MySQL 5.7_ group_ commit_ sync_ In the way of delay, we can increase the parallel transactions and reduce the replication delay.
The following conditions are met on the master:
- binlog_format=row
- Open transaction_write_set_extraction=XXHASH64
- The update table must have a primary key. If the update transaction contains a foreign key, it will be returned to commit_order mode
- binlog_transaction_dependency_tracking = [COMMIT_ORDER | WRITESET | WRITESET_SESSION]
Turn on slave on slave_parallel_workers
COMMIT_ORDER is based on commit timestamp
Different sessions executed at the same time can be played back in parallel
Write set can change different operations in parallel
- Return commit without primary key_ Order mode
hongbin@MBP ~/w/s/msb_8_0_3> mysqlbinlog data/MBP-bin.000013 |grep last_ |sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/' #180105 21:19:31 [...] last_committed=0 sequence_number=1 [...] create table t1 (id); #180105 21:19:50 [...] last_committed=1 sequence_number=2 [...] insert t1 value(1); #180105 21:19:52 [...] last_committed=2 sequence_number=3 [...] insert t1 value(2); #180105 21:19:54 [...] last_committed=3 sequence_number=4 [...] insert t1 value(3);
- A single session with a primary key can also be parallel
#180105 21:23:58 [...] last_committed=4 sequence_number=5 [...] create table t2 (id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, str VARCHAR(80) NOT NULL UNIQUE); #180105 21:24:19 [...] last_committed=5 sequence_number=6 [...] session1: insert t2(str) value('a'); #180105 21:24:21 [...] last_committed=5 sequence_number=7 [...] session1: insert t2(str) value('b'); #180105 21:24:25 [...] last_committed=5 sequence_number=8 [...] session1: insert t2(str) value('c');
WRITESET_SESSION the same session will not be reordered, different sessions can be in parallel
Execute in the same session
#180106 13:15:26 [...] last_committed=0 sequence_number=1 [...] session1: insert t2(str) value('h'); #180106 13:15:31 [...] last_committed=1 sequence_number=2 [...] session1: insert t2(str) value('l');
Execute in different sessions
#180106 13:17:08 [...] last_committed=1 sequence_number=3 [...] session1: insert t2(str) value('q'); #180106 13:17:09 [...] last_committed=1 sequence_number=4 [...] session2: insert t2(str) value('w');
How to observe parallel playback
How to evaluate slave_ parallel_ How many workers settings are appropriate? If the setting is small, there will be a backlog of tasks. If the setting is large, redundant threads are idle.
There is such a formula in the field of computer to study the fairness of system resource allocation.
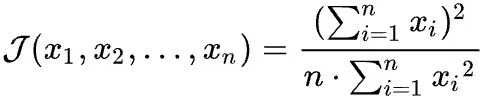
From a quantitative measure of failure and discrimination for resource allocation in shared computer systems+
This formula is called jain's index to calculate the fairness index of a system's shared resource allocation. The index value is between 0 < J < 1. The closer one is, the fairer the resource allocation is.
This formula can be used to calculate the fairness of task allocation of playback thread. If slave_ parallel_ The setting of workers is too large, and the fairness of task allocation is poor. Find the right slave_parallel_workers.
Performance needs to be enabled here_ The transaction level instrument of the schema collects the thread transaction submission information.
call sys.ps_setup_enable_consumer('events_transactions%'); call sys.ps_setup_enable_instrument('transaction');
Convert the formula to SQL statement as follows
select ROUND(POWER(SUM(trx_summary.COUNT_STAR), 2) / (@@GLOBAL.slave_parallel_workers * SUM(POWER(trx_summary.COUNT_STAR, 2))), 2) AS replica_jain_index from performance_schema.events_transactions_summary_by_thread_by_event_name as trx_summary join performance_schema.replication_applier_status_by_worker as applier on trx_summary.THREAD_ID = applier.THREAD_ID
On the slave, if the index value is closer to 0, the idle rate of the current applier thread is higher. If the index value is closer to 1, the idle rate of the current applier thread is lower. Try it!
reference resources: https://www.percona.com/blog/2016/02/10/estimating-potential-for-mysql-5-7-parallel-replication/ https://www.slideshare.net/JeanFranoisGagn/fosdem-2018-premysql-day-mysql-parallel-replication https://jfg-mysql.blogspot.hk/2017/02/metric-for-tuning-parallel-replication-mysql-5-7.html https://jfg-mysql.blogspot.com/2018/01/write-set-in-mysql-5-7-group-replication.html?m=1 http://mysqlhighavailability.com/improving-the-parallel-applier-with-writeset-based-dependency-tracking/