background
In traditional bank IT architecture, online trading and statistical analysis systems often use different technologies and physical devices to migrate online trading data to the analysis system through ETL which is executed regularly. As a data service resource pool, the same data may be accessed by different types of microservices. When some on-line transactions and auditing services run simultaneously for the same data, they must ensure that requests are executed in a completely isolated physical environment, so that the transaction analysis business is free of interference.
HBase is a high reliability, high performance, column-oriented, scalable distributed storage system, good at handling large data scenarios, with the following characteristics:
- The scale of tables is large, with hundreds of millions of rows and millions of columns.
- Column-Oriented Storage, Column Independent Retrieval
But there are also some problems in the use of HBase:
- HBase can only do simple key-value queries and cannot implement complex statistical SQL
- HBase does not support multiple indexing
- Operations and maintenance are complex. Hadoop, as a complete framework of large data analysis system, is complex in operation and difficult to locate problems.
In order to solve the above problems, users need to choose a flexible and extensible distributed relational database to meet the following requirements in typical data desk and service platform business:
- Standard SQL support
- Supporting high concurrency
- Support in multi-index
- Easy maintenance and other requirements
SequoiaDB Jushan database is a computing storage separation architecture. This distributed architecture can provide infinite horizontal expansion for data tables on the one hand. On the other hand, it is 100% compatible with MySQL, PostgreSQL and SparkSQL protocols and syntax by providing different database instances at the computing level. In addition to structured data, SequoiaDB Jushan database can support unstructured data in the same cluster, including JSON and S3 object storage, as well as Posix file system, so that the whole database can provide a complete data service resource pool for the application of the upper-level micro-service architecture.
SequoiaDB supports complex SQL queries, supports multiple indexes, supports high concurrency, and is easy to operate as an open source distributed database. So far, a large number of users have migrated from HBase to SequoiaDB. This article will share with you the operation of migrating data from HBase to SequoiaDB.
1 Export HBase data
First, we use Hive to export HBase data to csv file. The data structure of Hbase is as follows:

Figure 1 Hbase data structure integrates HBase and hive, creating external tables of hive for Association
hive Creates External Table Associated Hbase Reference Statement
CREATE EXTERNAL TABLE hbase_user( id string, name string, phone string, birthday string, id_number string, gender string, email string, address string ) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:name,info:phone,info:birthday,info:id_number,info:gender,info:email,i nfo:address") # Specify a mapping relationship, with: key as rowkey TBLPROPERTIES ("hbase.table.name" = "user"); # Specify the name of the hbase table to be mapped
The integration effect is shown below.
hive (default)> select * from hbase_user limit 1; OK hbase_user.id hbase_user.name hbase_user.phone hbase_user.birthday hbase_user.id_number hbase_user.gender hbase_user.email hbase_user.address 0004928c7287408085403c6ec4cd3c12 Liu Ying 15073203583 2013-07-15 211324199408301340 M maojuan@yahoo.com Liupanshui Street, Xuhui, Jingshi City, Heilongjiang Province J Seat 222331
Export data from his table to csv
# hive table export csv reference statement insert overwrite local directory '/tmp/data/hbase_hive_export_user' row format delimited # Specifies row splitters fields terminated by ',' # Executed column splitter select * from hbase_user;
The exported data is in csv format as shown in the following figure
[hadoop@node hbase_hive_export_user.csv]$ tail -2f 000000_0 ffdca61d22b74462aefdcb948d819542,Zhi Qiang Bian,18598897076,1958-08-25,52062819960928857X,M,ming52@gmail.com,Xunyang Shijie, Taiyuan County, Inner Mongolia Autonomous Region P Seat 547199 ffdf82a4e2f84c3a9c99e726153d9496,Fu Yu Hua,14509458979,1977-08-13,451022198005119836,M,yanhe@hotmail.com,Shanting Shenzhen Road, Bingxian County, Liaoning Province h Seat 706208
2 Import into SequoiaDB through CSV file
sdbimprt is a data import tool for SequoiaDB, which can import data in JSON or csv format into SequoiaDB database.
Import the csv file exported by HBase into SequoiaDB with the following commands:
sdbimprt --hosts=localhost:11810 --type=csv --file=user.csv -c users -l employee --fields='id string,name string,phone string,birthday string,id_number string,gender string,email string,address string'
Where the collection space name is users and the collection name is employee, the execution results are as follows:
$ sdbimprt --hosts=localhost:11810 --type=csv --file=user.csv -c users -l employee --fields='id string,name string,phone string,birthday string,id_number string,gender string,email string,address string' parsed records: 24282 parse failure: 0 sharding records: 0 sharding failure: 0 imported records: 24282 import failure: 0
3 Create HBase mapping table in MySQL layer of SequoiaDB
CREATE TABLE `employee` ( `id` int(11) DEFAULT NULL, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `phone` int(20) DEFAULT NULL, `birthday` datetime DEFAULT NULL, `id_number` int(20) DEFAULT NULL, `gender` varchar(11) COLLATE utf8mb4_bin DEFAULT NULL, `email` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `address` int(50) DEFAULT NULL ) ENGINE=SEQUOIADB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
4 View data import at SAC graphical interface of SequoiaDB
SAC graphical interface is a graphical tool developed by SequoiaDB Jushan database. It has the functions of automatically deploying cluster, configuring host and cluster information, monitoring host and cluster status, viewing cluster data, etc. It can greatly improve the efficiency of database management.

Figure 2. Functional display of SAC graphical interface
Log in to the SequoiaDB storage engine layer and view the amount of data is 24282. The data import is completed successfully.
#sdb > db = new Sdb("localhost", 11810) > db.users.employee.count() 24282 Takes 0.002236s.
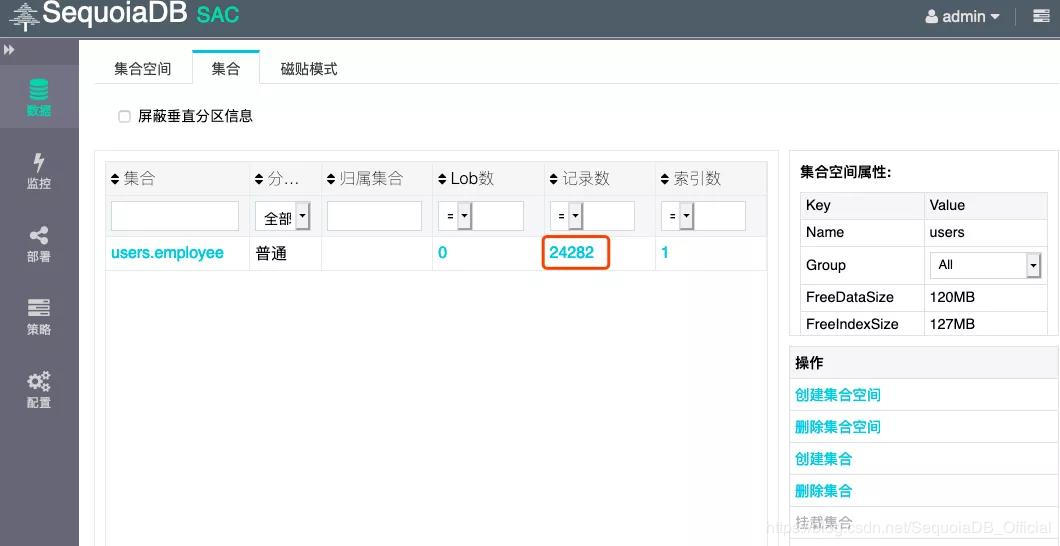
Figure 3. SAC graphical interface SequoiaDB storage engine layer view data schematics
At the same time, at the MySQL instance layer corresponding to SequoiaDB, you can see that the corresponding data is 24282.
$ /opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root ... mysql> use users; Database changed mysql> show tables; +-----------------+ | Tables_in_users | +-----------------+ | employee | +-----------------+ 1 row in set (0.00 sec) mysql> select count(*) from employee; +----------+ | count(*) | +----------+ | 24282 | +----------+ 1 row in set (0.00 sec)
In the SAC graphical interface of SequoiaDB, look at MySQL instance layer and get the number of data bars is 24282.
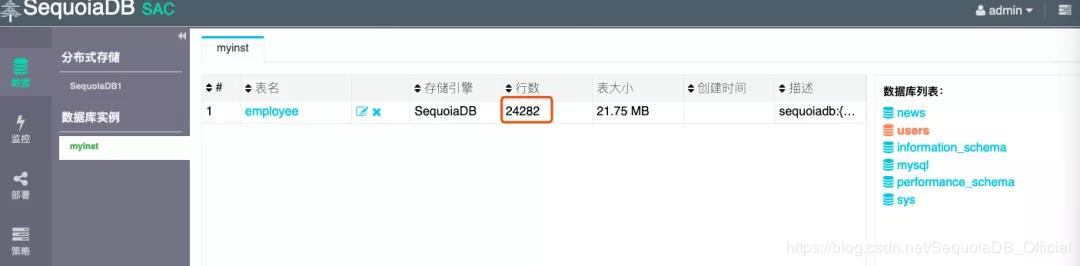
Figure 4 MySQL instance layer query data schematic diagram of SAC interface
5 Perform multi-index query validation in SequoiaDB
Create multiple indexes in mysql instance layer of SequoiaDB
mysql> ALTER TABLE `employee` ADD INDEX index_id (`id`); mysql> ALTER TABLE `employee` ADD INDEX index_email (`name`);
At the mysql instance layer of SequoiaDB, multiple index queries are executed:
mysql> select count(*) from employee where name="xiuyingxia"; +----------+ | count(*) | +----------+ | 2 | +----------+ 1 row in set (0.00 sec)
Migrating data from HBase to SequoiaDB, and in the SAC interface of SequoiaDB, the corresponding imported data can be viewed from the underlying storage engine layer and MySQL instance layer, respectively, and support multiple index queries.
summary
SequoiaDB supports complex SQL queries, supports multiple indexes, and supports high concurrency. As an open source distributed database, SequoiaDB is easy to operate and maintain. Hbase migrates to SequoiaDB, which can first export data file csv format through his, and then import it into SequoiaDB through the import tool sdbimprt of SequoiaDB.