Tiktok: This article introduces how to use Python crawler to pick up all the videos of your favorite patten (including two kinds of watermark and no watermark). Love is the best way to get your favorite video. Tiktok has been uploaded to the official account. Reply: you can get it by shaking.

1, Get your favorite video url
Tiktok user's home page url, I will take Luo Yonghao's home page as an example (my first tiktok is Luo Yonghao.
Go, so I only pay attention to him.)
1. Get home page link
Tiktok, click on the user's main page, click the three points in the upper right corner:
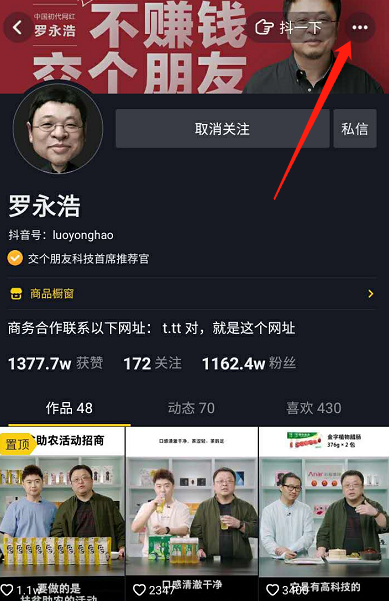
Choose to share:
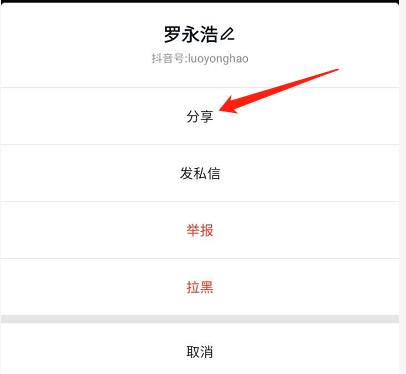
Click the copy link to get the following url:
https://v.douyin.com/JJ8b6Hq/
2. Get the redirect link
We just need to paste the above link into the chrome browser to get the redirect link
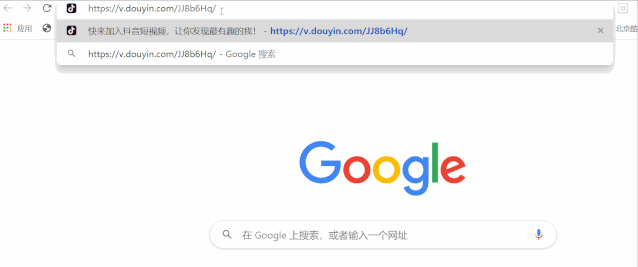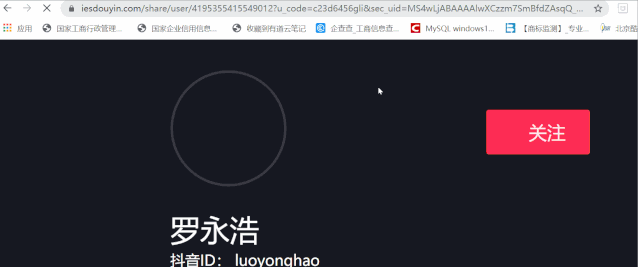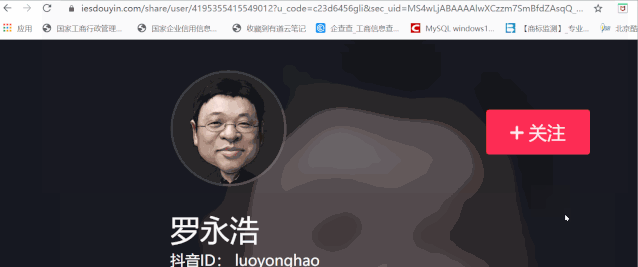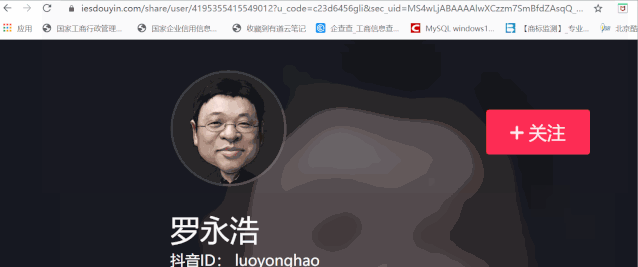
To reset a backward link:
https://www.iesdouyin.com/share/user/4195355415549012?u_code=c23d6456gli&sec_uid=MS4wLjABAAAAlwXCzzm7SmBfdZAsqQ_wVVUbpTvUSX1WC_x8HAjMa3gLb88-MwKL7s4OqlYntX4r×tamp=1590603009&utm_source=copy&utm_campaign=client_share&utm_medium=android&share_app_name=douyin
Now we need to remember the number after / user in the url, which is 41953554155449012. This is our user ID. In the future, as long as you have such a user ID, you can directly replace it with the url (the timestamp needs to be modified as well)
2, Get all v id eo IDS below the user
We just got the link of the video home page, now we want to get all the videos under the current page through the home page link. To facilitate our viewing and debugging, we will turn Chrome into iPhone mode.
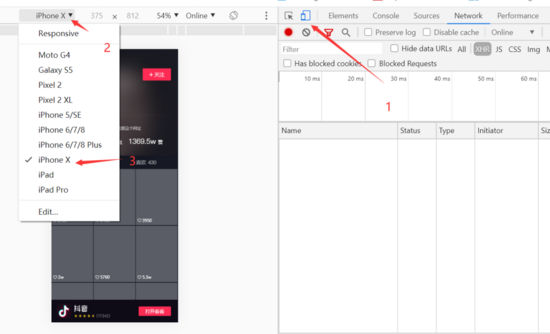
1. Get request link
Set the Network to XHR, refresh the following page to obtain the requested content:
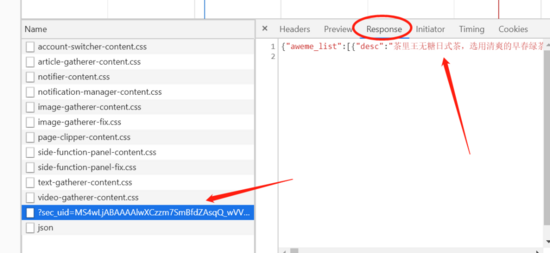
We can see that the request selected above returns a string of json. Let's copy the content and have a look. We can see that there is a url in the video through the following figure_ There are two different URLs in list. In fact, these two URLs are video related addresses, but there are still some problems. If you click these two URLs, you can't directly see the video.
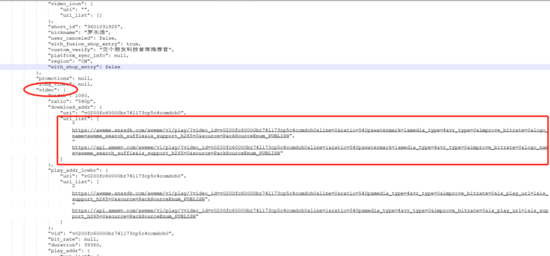
2. Get video link
Here we need to change the url a little bit. We can change / play to / playmw. At this time, we find that these two video addresses are redirected to normal video addresses. (next, why add mw? What does this represent)
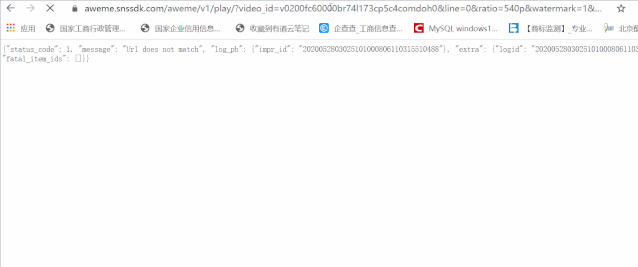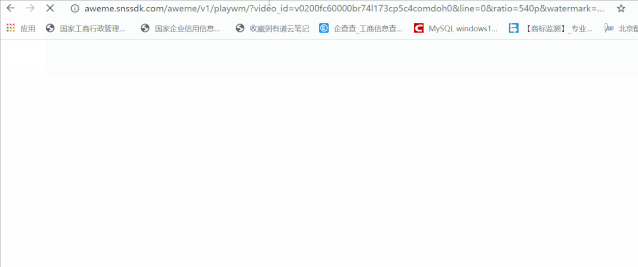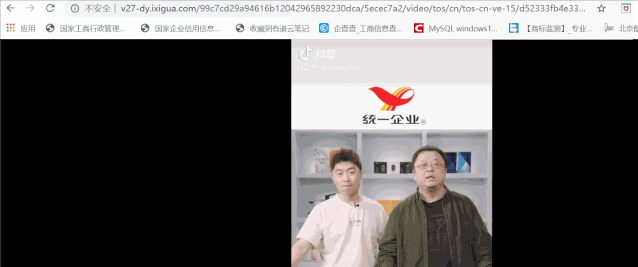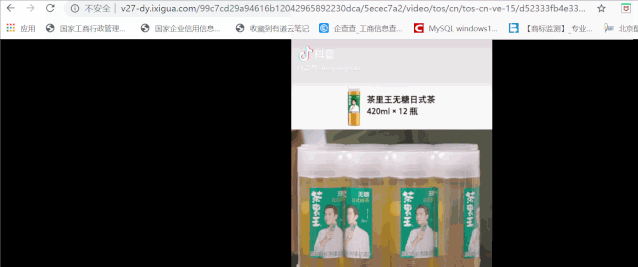
In this way, we can get the video address successfully. We can go to json to get all video url links:
pattern = re.compile('"(https://aweme.snssdk.com/aweme/v1/play/.*?)"')
result = pattern.findall(data)
result = [i.replace("/play/", "/playwm/") for i in result]
for i in result:
print(i)
//Add python learning qq group: 775690737 send python zero basic learning materials + 99 source codes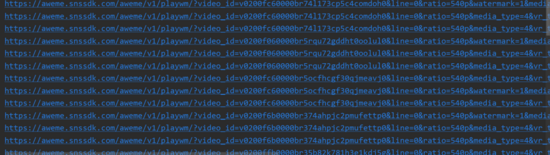
3. Watermark problem
On the issue of watermarks, I read an article in Jianshu that introduces the difference between watermarks and no watermarks. I will not give a detailed introduction here. In fact, the url we got at the beginning is watermark free, but the link itself is not redirected to watermark free video. After adding wm, the url will be redirected to watermark free video.
Short book reference link:
https://www.jianshu.com/p/af02f00729c5
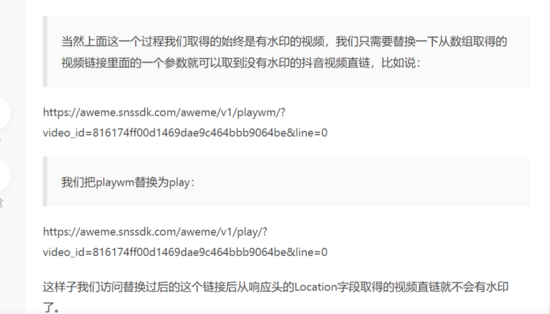
Watermark link:
https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200fc60000br74l173cp5c4comdoh0&line=0
Waterless link:
https://aweme.snssdk.com/aweme/v1/play/?video_id=v0200fc60000br74l173cp5c4comdoh0&line=0
(redundant parameters are ignored, regardless of others)

3, Download Video
With the method of video link and watermark, we can download the video directly.
import json
import re
import requests
import os
data = json.dumps(data)
pattern = re.compile('"(https://aweme.snssdk.com/aweme/v1/play/.*?)"')
result = pattern.findall(data)
result = [i.split("&ratio")[0] for i in result]
result2 = [i.replace("/play/", "/playwm/") for i in result]
for i in result:
print(i)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
}
if not os.path.exists("No watermark"):
os.mkdir("No watermark")
if not os.path.exists("watermark"):
os.mkdir("watermark")
count = 0
for res1 in result:
count += 1
videoBin = requests.get(res1, timeout=5, headers=headers)
with open(f'No watermark/{count}.mp4', 'wb') as fb:
fb.write(videoBin.content)
count = 0
for res2 in result2:
count += 1
videoBin = requests.get(res2, timeout=5, headers=headers)
with open(f'watermark/{count}.mp4', 'wb') as fb:
fb.write(videoBin.content)
//Add python learning qq group: 775690737 send python zero basic learning materials + 99 source codes
For a single video download, if you want to download a single watermark free video, you can download it directly through the sharing link:
url = "https://v.douyin.com/JJ8kVTc/ "Share links
session = requests.Session()
req = session.get(url, timeout=5, headers=HEADERS)
print(req.text)
video = re.findall(r'playAddr: "([\S]*?)"', req.text)[0]
vid = re.findall(r'vid=([\S]*?)&', video)[0]
addr = video.replace("/playwm/", "/play/") # Remove watermark
print(addr)
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
}
videoBin = session.get(addr, timeout=5, headers=headers)
with open('test.mp4', 'wb') as fb:
fb.write(videoBin.content)
//Add python learning qq group: 775690737 send python zero basic learning materials + 99 source codes4, Conclusion
This paper first obtains the interface data by sharing the link, then finds the video data in the interface data, finds the video content, and then completes the video download. The crawling process is very simple, mainly because it will be difficult to find the ID. A novice for reptiles.