Chinese speech synthesis scheme based on PaddleSpeech
- Chinese speech synthesis scheme: https://aistudio.baidu.com/aistudio/projectdetail/2791125?contributionType=1
- Paddlespeech source code: https://github.com/PaddlePaddle/PaddleSpeech
Chinese standard female voice library (10000 sentences)
brief introduction
Speech synthesis is a technology that produces artificial speech through mechanical and electronic methods. TTS Technology (also known as text to speech conversion technology) belongs to speech synthesis. It is a technology that transforms the text information generated by the computer itself or input externally into understandable and fluent oral output.
TTS speech synthesis technology is one of the key technologies to realize man-machine speech communication. Making computers have the same speech ability as people is an important competitive market in the information industry in today's era. Compared with speech recognition ASR, speech synthesis technology is relatively mature and has a wide range of applications.
With the rapid development of artificial intelligence industry, speech synthesis system has also been more widely used. In addition to the clarity and intelligibility in the early stage of speech synthesis, people have higher and higher requirements for the naturalness, rhythm and sound quality of speech synthesis. The quality of speech database is also the key factor to determine the effect of speech synthesis.
[Chinese standard female voice library] The timbre style of the collected object is intellectual, sunny, friendly and natural. The professional standard Mandarin female voice has an optimistic and positive listening feeling. The recording environment is a professional recording studio and recording software. The recording environment and equipment remain unchanged from beginning to end, and the signal-to-noise ratio of the recording environment is not less than 35dB; mono recording is recorded with 48KHz 16 bit sampling frequency and pcm wav format. The recording corpus covers all kinds of news and novels In the fields of, science and technology, entertainment, dialogue and so on, the corpus is designed to integrate the corpus sample size, and strive to cover the syllable phonons, types, tones, links and rhythms as fully as possible within the limited corpus data volume. According to the synthetic speech annotation standard, the corpus is subject to text phonetic proofreading, prosodic level annotation and voice file boundary segmentation annotation.
technical parameter
- Data content: Chinese standard female voice database data
- Recording corpus: comprehensive corpus sample size; covering the number, type, tone, sound connection and rhythm of syllable phonons.
- Effective duration: about 12 hours
- Average number of words: 16 words
- Language type: Standard Mandarin
- Speaker: female; 20-30 years old; positive voice; intellectual
- Recording environment: the sound acquisition environment is a professional recording studio environment: 1) the recording studio meets the recording standard of professional sound library; 2) The recording environment and equipment remain unchanged from beginning to end; 3) The signal-to-noise ratio of the recording environment shall not be lower than 35dB.
- Recording tools: professional recording equipment and recording software
- Sampling format: uncompressed pcm wav format with sampling rate of 48KHz and 16bit
- Annotation contents: phonetic proofreading, prosodic annotation, boundary segmentation of Chinese vowels and vowels
- Annotation format: text annotation is a. txt format document; The syllable phoneme boundary segmentation file is in. interval format
- Quality standard: 1. The voice file is in 48k 16bit wav format, with the same voice color, volume and speed, no drift and no section; 2. The accuracy rate of marked documents shall not be less than 99.8%; 3. The proportion of phoneme boundary error greater than 10ms is less than 1%; The accuracy of syllable boundary is more than 98%
- Storage method: FTP storage
- File format: audio file: wav text annotation file: TXT boundary annotation file: INTERVAL
- Copyright owner: Biao Bei (Beijing) Technology Co., Ltd
Speech synthesis model combing
Researchers of Microsoft Asia Research Institute have investigated more than 450 literatures in the field of speech synthesis and published the most detailed review paper "A Survey on Neural Speech Synthesis" in the field of speech synthesis so far. In this paper, the researchers also collected relevant resources in the field of speech synthesis, such as data sets, open source implementation, lecture tutorials, etc. at the same time, they also discussed and prospected the future research direction in the field of speech synthesis. I hope this paper can provide a valuable reference for researchers in related work.
Paper link: https://arxiv.org/pdf/2106.15561.pdf
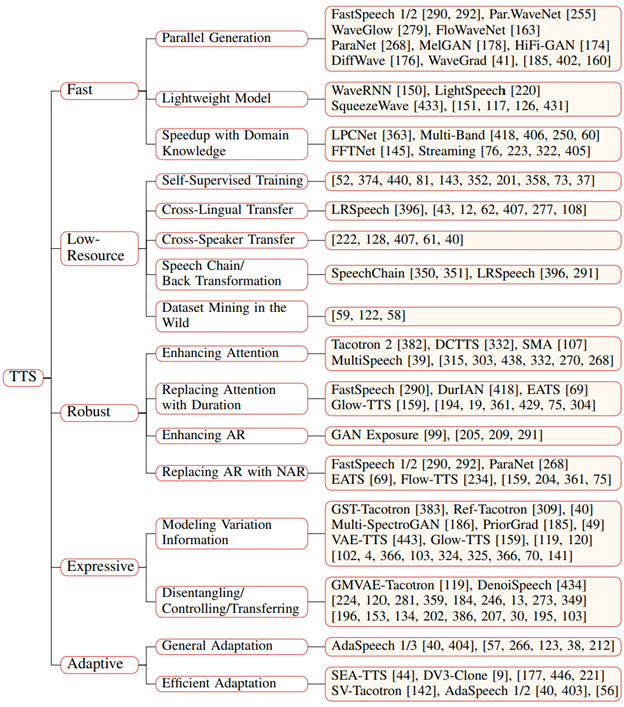
This paper summarizes the development status of neural speech synthesis from two aspects (the logical framework is shown in Figure 1):
Core modules: text analysis, acoustic model, vocoder, fully end-to-end model, etc.
Advanced topics: introduce fast TTS, low resource TTS, robust TTS, expressive TTS, adaptive TTS, etc

TTS core module
Researchers proposed a classification system according to the core module of neural speech synthesis system. Each module corresponds to a specific data conversion process:
1) The text analysis module converts text characters into phonemes or linguistic features;
2) Acoustic model converts linguistic features, phonemes or character sequences into acoustic features;
3) The vocoder converts linguistic features or acoustic features into speech waveforms;
4) The complete end-to-end model converts character or phoneme sequences into speech waveforms.
Picture: (a) TTS core framework, (b) data conversion process
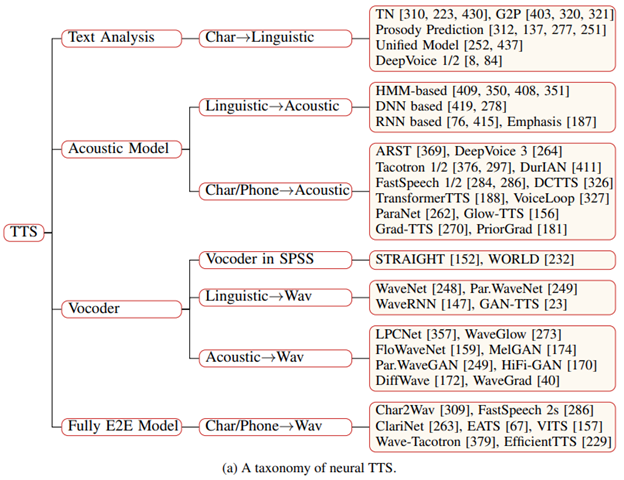
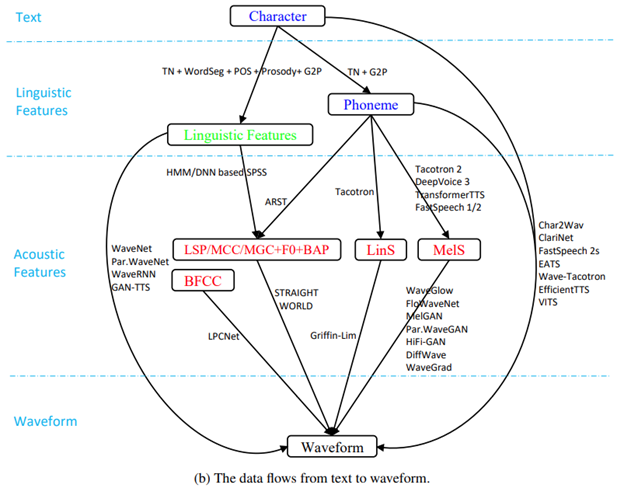
Text analysis
This paper summarizes several common tasks of the text analysis module, including text normalization, word segmentation, part of speech tagging, prosody prediction, font to phonetic transformation and polyphonic word disambiguation.
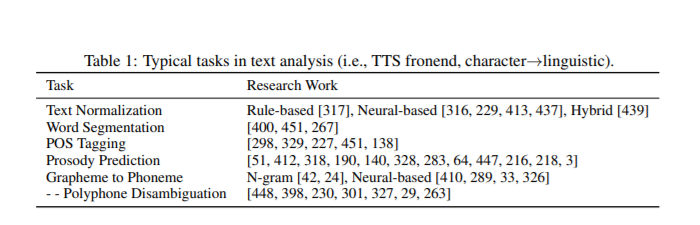
Acoustic mode
In the part of acoustic model, this paper first briefly introduces the acoustic model based on neural network used in statistical parameter synthesis, and then focuses on the neuroacoustic model of end-to-end model, including the acoustic model based on RNN, CNN and Transformer and other acoustic models based on Flow, GAN, VAE and Diffusion.
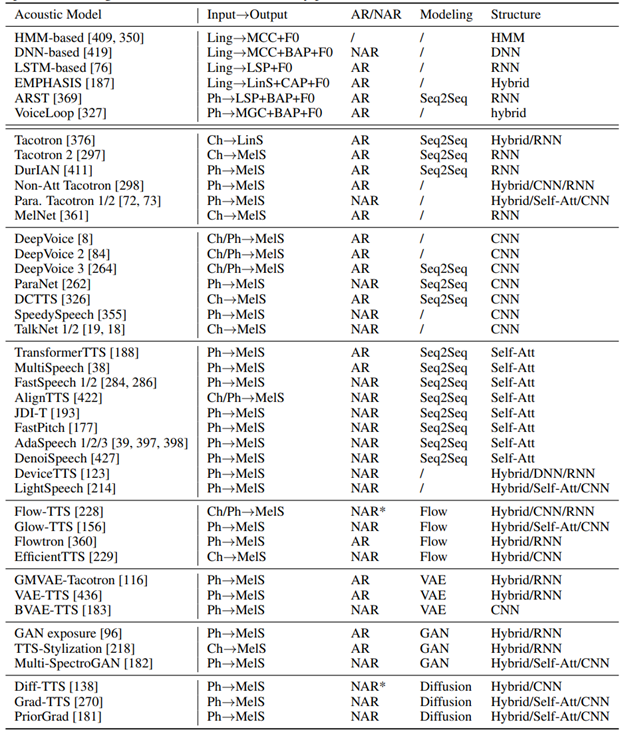
Vocoder
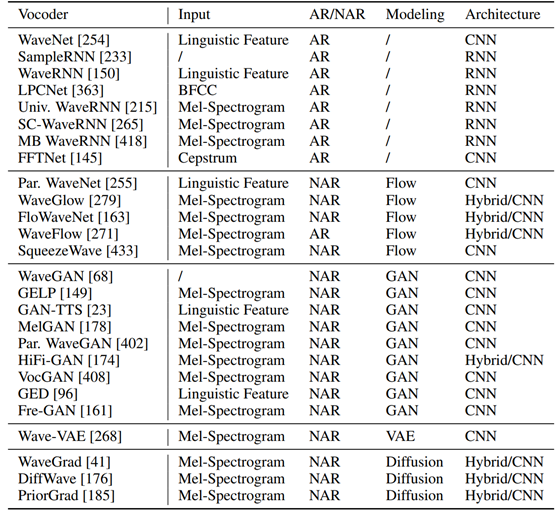
The development of vocoder is divided into two stages, including vocoders in traditional parameter synthesis, such as strong and WORLD, and vocoders based on neural network. This paper focuses on the vocoder based on neural network, and divides the related work into the following categories, including:
1) Autoregressive vocoder (WaveNet, SampleRNN, WaveRNN, LPCNet, etc.);
2) Flow based vocoder (WaveGlow, WaveNet, WaveFlow, Par. WaveNet, etc.);
3) GAN based vocoders (WaveGAN, GAN-TTS, MelGAN, Par. WaveGAN, hifi GAN, VocGAN, GED, fregan, etc.);
4) VAE based vocoder (WaveVAE, etc.);
5) A Diffusion based vocoder (DiffWave, WaveGrad, PriorGrad, etc.).
Complete end-to-end model
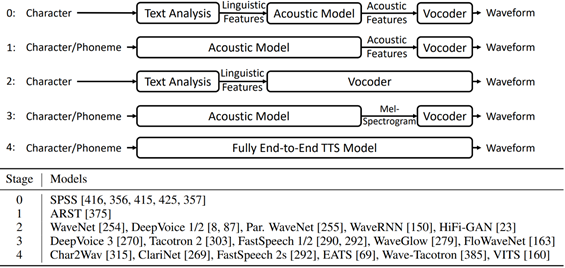
The development of the end-to-end model has gone through the following stages:
Stage 0: in the statistical parameter synthesis method, three modules of text analysis, acoustic model and vocoder are cascaded;
Stage 1: in the statistical parameter synthesis method, the first two modules are combined to form an acoustic model;
Stage 2: generate the final waveform directly from linguistic features, such as WaveNet;
Stage 3: the acoustic model directly generates the acoustic model from the characters or phonemes, and then uses the neural vocoder to generate the waveform;
Stage 4: complete end-to-end neural network model.
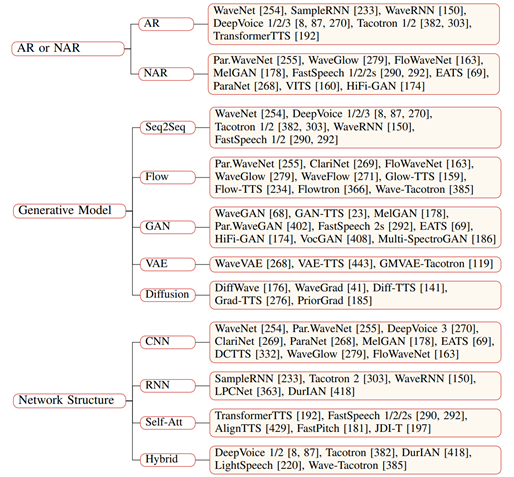
TTS model classification
1) Autoregressive vs non autoregressive; 2) Type of generated model; 3) Type of network structure.
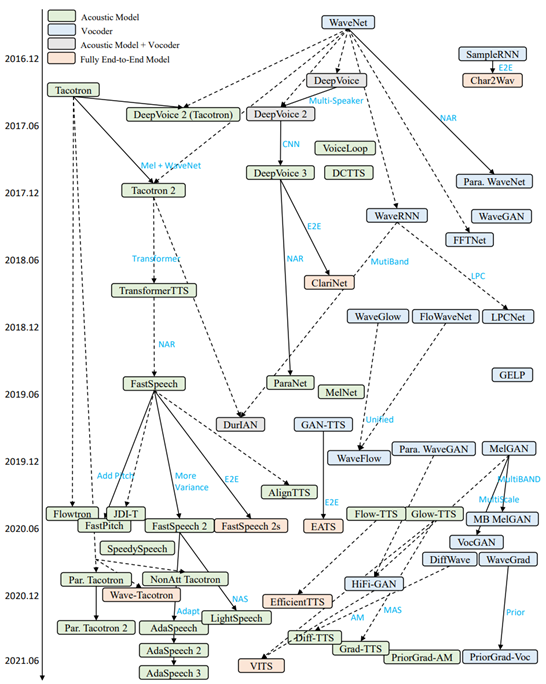
Model evolution
At the same time, this paper also draws the relationship diagram of relevant TTS work over time, which is convenient for readers to more intuitively understand each TTS model and its position in the development of TTS.
TTS advanced topics
The researchers also introduced related advanced topics for various challenges faced by TTS, including fast TTS, low resource TTS, robust TTS, expressive TTS, adaptive TTS, etc.
Loading model
import tensorflow as tf import yaml import numpy as np import matplotlib.pyplot as plt import IPython.display as ipd from tensorflow_tts.inference import AutoConfig from tensorflow_tts.inference import TFAutoModel from tensorflow_tts.inference import AutoProcessor import soundfile as sf from tqdm import tqdm
Tacotron2
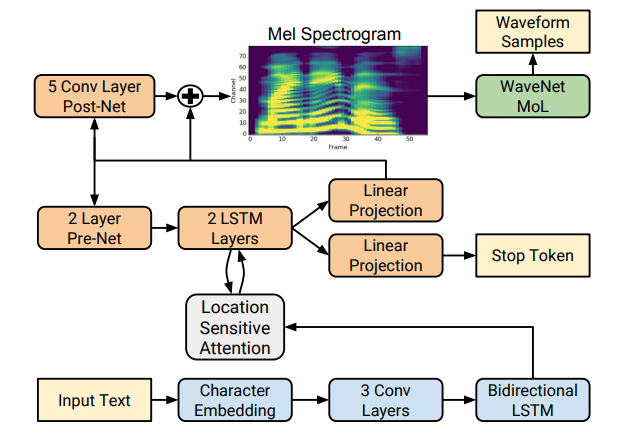
Tacotron2 is a speech synthesis framework proposed by Google brain in 2017.
Tacotron2: a complete neural network speech synthesis method. The model is mainly composed of three parts:
- Sound spectrum prediction network: a cyclic Seq2seq based feature prediction network with attention mechanism is used to predict the frame sequence of Mel spectrum from the input character sequence.
- vocoder: a revised version of WaveNet, which uses the predicted Mel spectrum frame sequence to generate time-domain waveform samples.
- Intermediate connection layer: the two parts of the system are connected by using a low-level acoustic representation - Mel frequency spectrogram.
tacotron2 = TFAutoModel.from_pretrained("tensorspeech/tts-tacotron2-baker-ch", name="tacotron2")
FastSpeech2
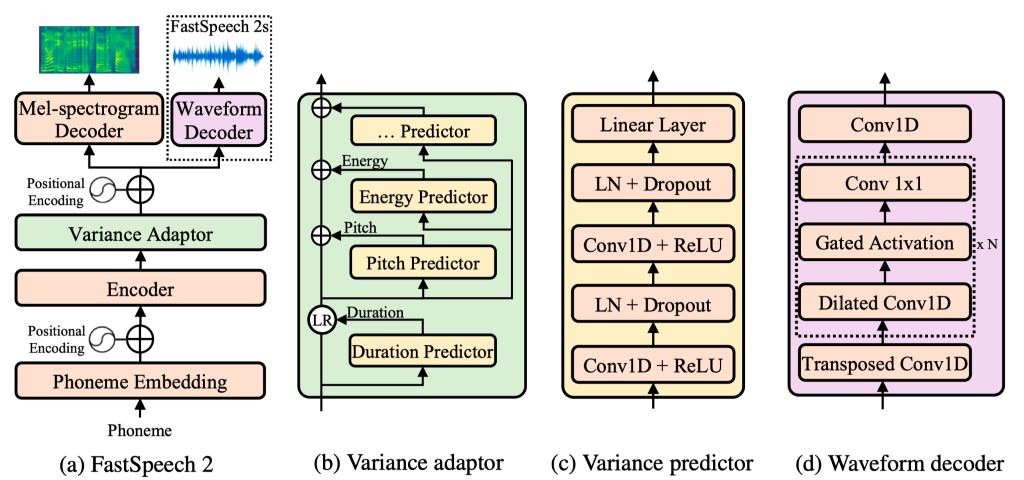
In recent years, compared with the traditional autoregressive model (such as Tacotron 2), the text to speech (TTS) model represented by FastSpeech can greatly improve the synthesis speed, improve the speech robustness (reduce the problems of repeated spitting and missing words) and controllability (control rate and rhythm), and achieve the matching speech synthesis quality at the same time. However, FastSpeech also faces the following problems:
FastSpeech relies on teacher student's knowledge distillation framework, and the training process is complex;
Due to knowledge distillation, the training target of FastSpeech has information loss compared with real speech, and the Duration information obtained from Teacher model is not accurate enough, both of which will affect the quality of synthetic speech.
In order to solve the above problems, Microsoft Asia Research Institute and Microsoft Azure voice team, together with Zhejiang University, proposed an improved version of FastSpeech 2, which abandoned the teacher student knowledge distillation framework, reduced the training complexity, and directly used real voice data as the training target to avoid information loss, At the same time, more accurate time length information and other variable information in speech (including Pitch and Energy) are introduced to improve the quality of synthesized speech. Based on FastSpeech 2, we also propose an enhanced version of FastSpeech 2s to support complete end-to-end synthesis from text to speech waveform, and omit the generation process of Mel spectrum. The experimental results show that FastSpeech 2 and 2S are better than FastSpeech in speech quality. At the same time, it greatly simplifies the training process, reduces the training time, and speeds up the synthesis speed.
The sample audio websites of FastSpeech 2 and 2s have been published at:
https://speechresearch.github.io/fastspeech2/
The paper is published in: https://arxiv.org/pdf/2006.04558.pdf
fastspeech2 = TFAutoModel.from_pretrained("tensorspeech/tts-fastspeech2-baker-ch", name="fastspeech2")
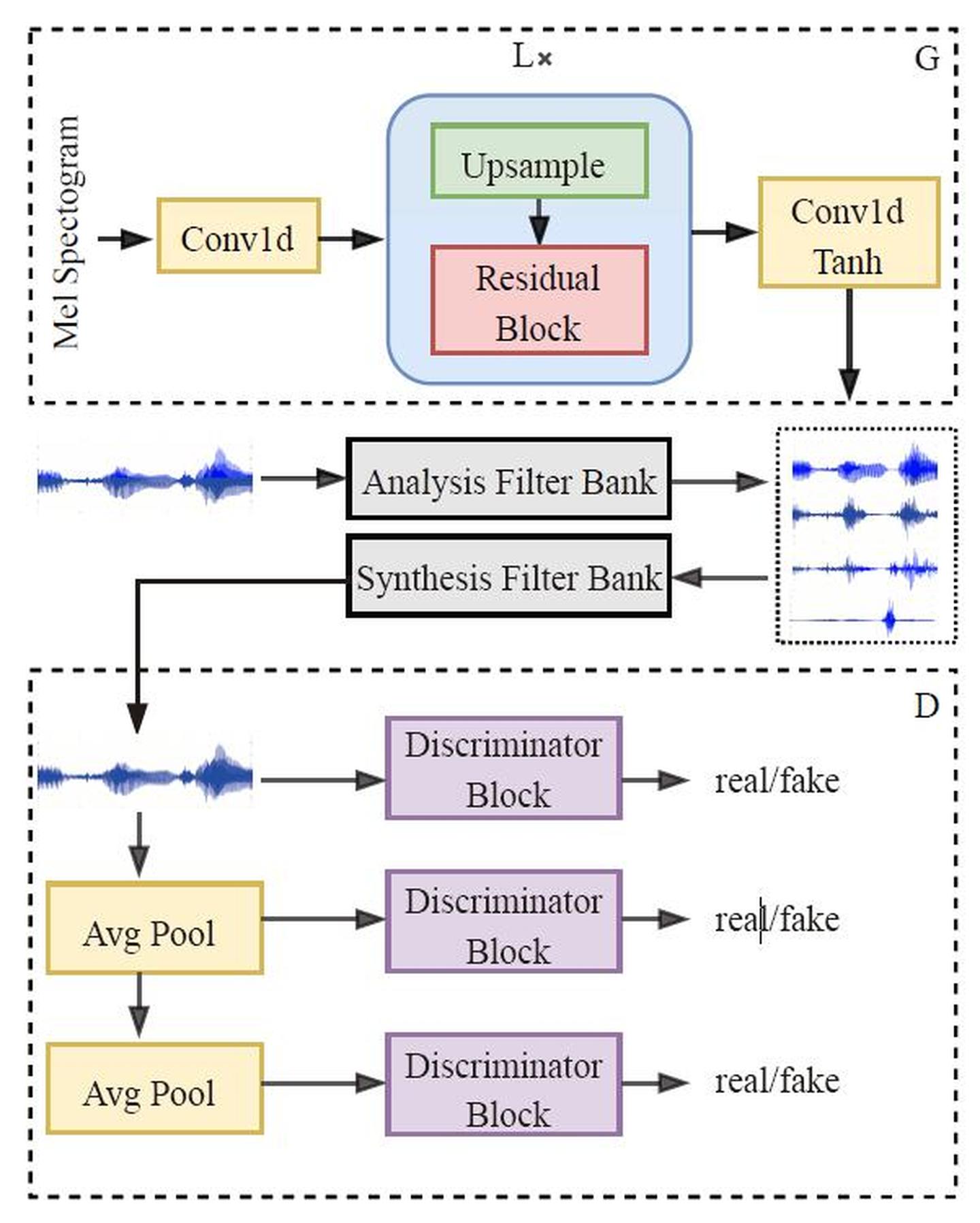
MB-MelGAN
Multi band MelGAN introduces the multi-resolution STFT loss in Parallel WaveGAN into MelGAN, and measures the loss on multiple subbands of audio respectively.
Code address:
kan-bayashi/ParallelWaveGAN
rishikksh20/melgan
Step 1: install Parakeet
!git clone https://github.com/PaddlePaddle/Parakeet %cd Parakeet !pip install -e .
!unzip Parakeet.zip
%cd Parakeet/ !pip install -e .
Step 2 install dependency
First, check the instructions in the official documents
Install libsndfile1
Make sure the library libsndfile1 is installed, e.g., on Ubuntu.
sudo apt-get install libsndfile1
Taking the Ubuntu operating system as an example, libsndfile1, an open source sound file format processing library, must be installed. At present, AI Studio has built-in the processing library without additional installation.
Install PaddlePaddle
Install PaddlePaddle See install for more details. This repo requires PaddlePaddle 1.8.2 or above.
At present, the Notebook environment supports PaddlePaddle1.8.0, but it has been verified that WaveFlow can be trained normally in the PaddlePaddle1.8.0 environment of AI Studio.
Install Parakeet
git clone https://github.com/PaddlePaddle/Parakeet cd Parakeet pip install -e .
Install CMUdict for nltk
CMUdict from nltk is used to transform text into phonemes.
import nltk
nltk.download("punkt")
nltk.download("cmudict")
The Notebook environment is relatively simple. Just do it. Although nltk.download() will report an error of network failure, refer to nltk.download() for error resolution. This article has downloaded and unzipped the relevant files, which can be used directly.
In [ ] %cd Parakeet !pip install -e .
/home/aistudio/Parakeet
import nltk
nltk.download("punkt")
nltk.download("cmudict")
[nltk_data] Downloading package punkt to /home/aistudio/nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package cmudict to /home/aistudio/nltk_data...
[nltk_data] Package cmudict is already up-to-date!
True
Script task environment
In the script task, the installation of Parakeet and NLTK will be troublesome
Install libsndfile1
Without installation, download the output weight file to the local forecast.
Install PaddlePaddle
The script task supports the paddepadde1.8.2 environment without installation.
!nvidia-smi
# import nltk
# nltk.download("punkt")
# nltk.download("cmudict")
!unzip nltk_data.zip
Step 3: data preparation and preprocessing
The standard data path is as follows:
# %cd ../ !ls data/data117129/ # data/data117129/BZNSYP.zip
Decompress the dataset to avoid excessive output
!unzip data/data117129/BZNSYP.zip > /dev/null 2>&1
Tone data: https://paddlespeech.bj.bcebos.com/MFA/BZNSYP/with_tone/baker_alignment_tone.tar.gz
!tar -zxf baker_alignment_tone.tar.gz
This step takes a long time, almost an hour
!sed -i 's/\r$//' ./preprocess.sh !chmod +x ./preprocess.sh !./preprocess.sh
The preprocessed data sets generated are as follows:
dump
├── dev
│ ├── norm
│ └── raw
├── phone_id_map.txt
├── speaker_id_map.txt
├── test
│ ├── norm
│ └── raw
└── train
├── energy_stats.npy
├── norm
├── pitch_stats.npy
├── raw
└── speech_stats.npy
Step 4 model training
Use. / run.sh to complete the training task
usage: train.py [-h] [--config CONFIG] [--train-metadata TRAIN_METADATA]
[--dev-metadata DEV_METADATA] [--output-dir OUTPUT_DIR]
[--device DEVICE] [--nprocs NPROCS] [--verbose VERBOSE]
[--phones-dict PHONES_DICT] [--speaker-dict SPEAKER_DICT]
Train a FastSpeech2 model.
optional arguments:
-h, --help show this help message and exit
--config CONFIG fastspeech2 config file.
--train-metadata TRAIN_METADATA
training data.
--dev-metadata DEV_METADATA
dev data.
--output-dir OUTPUT_DIR
output dir.
--device DEVICE device type to use.
--nprocs NPROCS number of processes.
--verbose VERBOSE verbose.
--phones-dict PHONES_DICT
phone vocabulary file.
--speaker-dict SPEAKER_DICT
speaker id map file for multiple speaker model.
# !sed -i 's/\r$//' ./run.sh # !chmod +x ./run.sh # !./run.sh
Step 5 model prediction: "speech synthesis"
Predict the test set
usage: synthesize.py [-h] [--fastspeech2-config FASTSPEECH2_CONFIG]
[--fastspeech2-checkpoint FASTSPEECH2_CHECKPOINT]
[--fastspeech2-stat FASTSPEECH2_STAT]
[--pwg-config PWG_CONFIG]
[--pwg-checkpoint PWG_CHECKPOINT] [--pwg-stat PWG_STAT]
[--phones-dict PHONES_DICT] [--speaker-dict SPEAKER_DICT]
[--test-metadata TEST_METADATA] [--output-dir OUTPUT_DIR]
[--device DEVICE] [--verbose VERBOSE]
Synthesize with fastspeech2 & parallel wavegan.
optional arguments:
-h, --help show this help message and exit
--fastspeech2-config FASTSPEECH2_CONFIG
fastspeech2 config file.
--fastspeech2-checkpoint FASTSPEECH2_CHECKPOINT
fastspeech2 checkpoint to load.
--fastspeech2-stat FASTSPEECH2_STAT
mean and standard deviation used to normalize
spectrogram when training fastspeech2.
--pwg-config PWG_CONFIG
parallel wavegan config file.
--pwg-checkpoint PWG_CHECKPOINT
parallel wavegan generator parameters to load.
--pwg-stat PWG_STAT mean and standard deviation used to normalize
spectrogram when training parallel wavegan.
--phones-dict PHONES_DICT
phone vocabulary file.
--speaker-dict SPEAKER_DICT
speaker id map file for multiple speaker model.
--test-metadata TEST_METADATA
test metadata.
--output-dir OUTPUT_DIR
output dir.
--device DEVICE device type to use.
--verbose VERBOSE verbose.
Prediction of new tennis cup data set
- Use the training model in exp directory to predict the results
- Directly use the official pre training model to predict
For the prediction part, please refer to [Paddle playing competition] speech synthesis: https://aistudio.baidu.com/aistudio/projectdetail/2793102? channelType=0&channel=0
Directly use the official pre training model to predict
FLAGS_allocator_strategy=naive_best_fit
FLAGS_fraction_of_gpu_memory_to_use=0.01
python3 synthesize_e2e.py
–fastspeech2-config=fastspeech2_nosil_baker_ckpt_0.4/default.yaml
–fastspeech2-checkpoint=fastspeech2_nosil_baker_ckpt_0.4/snapshot_iter_76000.pdz
–fastspeech2-stat=fastspeech2_nosil_baker_ckpt_0.4/speech_stats.npy
–pwg-config=pwg_baker_ckpt_0.4/pwg_default.yaml
–pwg-checkpoint=pwg_baker_ckpt_0.4/pwg_snapshot_iter_400000.pdz
–pwg-stat=pwg_baker_ckpt_0.4/pwg_stats.npy
–text=.../sentences.txt
–output-dir=exp/default/test_e2e
–device="gpu"
–phones-dict=fastspeech2_nosil_baker_ckpt_0.4/phone_id_map.txt
%cd ~
/home/aistudio
!sed -i 's/\r$//' ./synthesize_e2e.sh !chmod +x ./synthesize_e2e.sh !./synthesize_e2e.sh
The results are stored in exp/default/test_e2e
We can see the effect
001 Chewing the taste of food, I feel happy. 002 At present, there are two ways to apply for a good loan: Taking the original ID card in real time or uploading album photos, but copies and temporary ID cards are not allowed. 003 The Hun leader Shan Yu can only ride a horse, not a bicycle. 004 On the bright moon,It's raining and worrying. 005 A bronze medal is inserted in front of the tree to explain the reason. In this case, if you don't look at the description of the bronze medal, you can't imagine that there is a magnificent modern building under the root of the huge tree. 006 Dunhuang Mogao Grottoes is a miracle in the history of world culture. On the basis of inheriting the artistic tradition of Han and Jin Dynasties, it has formed its own inclusive and magnificent bearing, showing its exquisite artistic form and broad and profound cultural connotation. 007 Perhaps by contrast, it is no longer difficult to occupy a place;You will easily gain the power to free your soul from unhappiness and make it not gray. 008 If a person wants to change the current situation full of misfortune or unsatisfactory, he can only answer a simple question: "what do I want the situation to become?" and then devote himself to taking action to move towards his ideal goal. 009 Psychologists have found that when most people buy things, if they encounter many different brands, he means that they will buy products that have seen advertisements. 010 Due to the busy business, I'm sorry. If you can't receive it in three days, please check it again. Please don't check the goods from 7:00 to 10:00 in the evening. Thank you for your support and cooperation in our store. The waiter will be very grateful! 011 Soon after sunset, an orange sunset glow was burning in the western sky. 012 The shopkeeper is out to deliver goods. I'm very sorry that I can't reply to your information in time. You can choose slowly in the shop. You must wait for the shopkeeper! The shopkeeper will reply as soon as he comes back! 013 Hello, I have seen your payment succeeded. We will deliver the goods for you in time. Thank you for purchasing our goods. Please feel free to call me if necessary, 014 Through life and death, life understands the impermanence of things; Fate, after gathering and dispersing, precipitates the true feelings; After years of love, we realize that love is deep and shallow. 015 I'm sorry for the overdue due to your own reason. The resulting penalty interest needs to be borne by yourself and cannot be reduced or exempted. 016 In the past, some were our relatives and friends, while others were our enemies and enemies. When we meet again in this life, this brand will revive and drive us to continue the past love and hatred.
import IPython
%cd /home/aistudio
IPython.display.Audio('exp/default/test_e2e/001.wav')
Your browser does not support the audio element./home/aistudio
import IPython
%cd /home/aistudio
IPython.display.Audio('exp/default/test_e2e/002.wav')
/home/aistudio