We are going to use 17 days to divide the deliberate practice of Python foundation into the following tasks:
Task01: variables, operators and data types (1day)
Task02: condition and cycle (1day)
Task03: list and tuple (2day)
Task04: string and sequence (1day)
Task05: functions and Lambda expressions (2day)
Task06: dictionary and collection (1day)
Task07: file and file system (2day)
Task08: exception handling (1day)
Task09: else and with statements (1day)
Task10: classes and objects (2day)
Task 11: magic method (2day)
Task 12: module (1day)
Abstract:
- This chapter is about some operations of Python string method
- Some built-in methods of list
Python basic syntax
1. string
Definition of string
- Strings in Python are defined as sets of characters between quotation marks.
- Python supports the use of single or double quotes in pairs.
t1 = 'i love Python!' print(t1, type(t1)) # i love Python! <class 'str'> t2 = "I love Python!" print(t2, type(t2)) # I love Python! <class 'str'> print(5 + 8) # 13 print('5' + '8') # 58
- If you need single or double quotation marks in a string, you can use escape symbol \ to escape symbols in the string.
print('let\'s go') # let's go print("let's go") # let's go print('C:\\now') # C:\now print("C:\\Program Files\\Intel\\Wifi\\Help") # C:\Program Files\Intel\Wifi\Help
- Common escape characters in Python
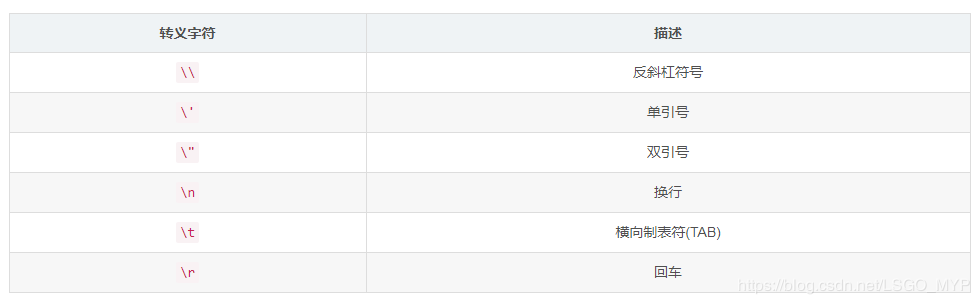
- The original string only needs to be preceded by an English letter r.
print(r'C:\Program Files\Intel\Wifi\Help') # C:\Program Files\Intel\Wifi\Help
python triple quotes allow a string to span multiple lines, which can contain line breaks, tabs, and other special characters.
para_str = 'this is an instance of a multiline string Tabs can be used for multiline strings TAB ( \t ). You can also use the new line character [\ n]. """ print (para_str) ''' This is an example of a multiline string Tabs can be used for multiline strings TAB ( ). You can also use line breaks[ ]. '''
Slicing and splicing of strings
- Similar to tuple, it is immutable
- From 0 (same as C)
- Slices are usually written in the form of start:end, including the elements corresponding to the start index, excluding the elements corresponding to the end index.
- Index value can be positive or negative, positive index starts from 0, left to right; negative index starts from - 1, right to left. When a negative index is used, it counts from the last element. The position number of the last element is - 1.
str1 = 'I Love LsgoGroup' print(str1[:6]) # I Love print(str1[5]) # e print(str1[:6] + " Inserted string " + str1[6:]) # String LsgoGroup inserted by I Love s = 'Python' print(s) # Python print(s[2:4]) # th print(s[-5:-2]) # yth print(s[2]) # t print(s[-1]) # n
Common built-in methods for Strings
- capitalize() converts the first character of the string to uppercase.
str2 = 'xiaoxie' print(str2.capitalize()) # Xiaoxie
- lower() converts all uppercase characters in the string to lowercase.
- upper() converts lowercase letters in the string to uppercase.
- swapcase() converts uppercase to lowercase and lowercase to uppercase in a string.
str2 = "DAXIExiaoxie" print(str2.lower()) # daxiexiaoxie print(str2.upper()) # DAXIEXIAOXIE print(str2.swapcase()) # daxieXIAOXIE
- count(str, beg= 0,end=len(string)) returns the number of times that str appears in the string. If beg or end is specified, it returns the number of times that str appears in the specified range.
str2 = "DAXIExiaoxie" print(str2.count('xi')) # 2
- Endswitch (suffix, beg = 0, end = len (string)) checks whether the string ends with the specified substring suffix. If so, returns True, otherwise False. If beg and end specify values, check within the specified range.
- Startswitch (substr, beg = 0, end = len (string)) checks whether the string begins with the specified substring substr. If yes, returns True, otherwise returns False. If beg and end specify values, check within the specified range.
str2 = "DAXIExiaoxie" print(str2.endswith('ie')) # True print(str2.endswith('xi')) # False print(str2.startswith('Da')) # False print(str2.startswith('DA')) # True
- find(str, beg=0, end=len(string)) detects whether str is included in the string. If the range is specified, it checks whether it is included in the specified range. If it is, it returns the starting index value. Otherwise, it returns - 1.
- rfind(str, beg=0,end=len(string)) is similar to the find() function, but it starts from the right.
str2 = "DAXIExiaoxie" print(str2.find('xi')) # 5 print(str2.find('ix')) # -1 print(str2.rfind('xi')) # 9
- isnumeric() returns True if the string contains only numeric characters, otherwise False.
str3 = '12345' print(str3.isnumeric()) # True str3 += 'a' print(str3.isnumeric()) # False
- ljust(width[, fillchar]) returns the left alignment of the original string and fills the new string with fillchar (the default space) to the length width.
- rjust(width[, fillchar]) returns a right alignment of the original string and fills the new string with fillchar (the default space) to the length width.
str4 = '1101' print(str4.ljust(8, '0')) # 11010000 print(str4.rjust(8, '0')) # 00001101
- lstrip([chars]) truncates the space to the left of the string or the specified character.
- rstrip([chars]) removes spaces or specified characters at the end of a string.
- String ([chars]) executes lstrip() and rstrip() on the string.
str5 = ' I Love LsgoGroup ' print(str5.lstrip()) # 'I Love LsgoGroup ' print(str5.lstrip().strip('I')) # ' Love LsgoGroup ' print(str5.rstrip()) # ' I Love LsgoGroup' print(str5.strip()) # 'I Love LsgoGroup' print(str5.strip().strip('p')) # 'I Love LsgoGrou'
- partition(sub) finds the substring sub, and divides the string into a triple (pre sub, sub, fol sub). If the string does not contain sub, it returns ('original string ',', ').
- rpartition(sub) is similar to the partition() method, but looks from the right.
str5 = ' I Love LsgoGroup ' print(str5.strip().partition('o')) # ('I L', 'o', 've LsgoGroup') print(str5.strip().partition('m')) # ('I Love LsgoGroup', '', '') print(str5.strip().rpartition('o')) # ('I Love LsgoGr', 'o', 'up')
- replace(old, new [, max]) replaces the old in the string with new. If max is specified, the replacement cannot exceed max times.
str5 = ' I Love LsgoGroup ' print(str5.strip().replace('I', 'We')) # We Love LsgoGroup
split(str="", num) is a string sliced without parameters. By default, a space is used as the separator. If the num parameter is set, only num substrings are separated, and the list of substrings stitched after slicing is returned.
str5 = ' I Love LsgoGroup ' print(str5.strip().split()) # ['I', 'Love', 'LsgoGroup'] print(str5.strip().split('o')) # ['I L', 've Lsg', 'Gr', 'up']
Splitlines ([keeps]) is separated by lines ('\ r', '\ r\n', \ n '), and returns a list containing lines as elements. If the parameter keeps is False, it does not contain line breaks. If it is True, it retains line breaks.
str6 = 'I \n Love \n LsgoGroup' print(str6.splitlines()) # ['I ', ' Love ', ' LsgoGroup'] print(str6.splitlines(True)) # ['I \n', ' Love \n', ' LsgoGroup']
Maketrans (intrab, outtab) creates a conversion table for character mapping. The first parameter is string, which represents the characters to be converted. The second parameter is also the target of string.
translate(table, deletechars = "") according to the table given by the parameter table, convert the characters of the string, and put the characters to be filtered into the deletechars parameter.
str = 'this is string example....wow!!!' intab = 'aeiou' outtab = '12345' trantab = str.maketrans(intab, outtab) print(trantab) # {97: 49, 111: 52, 117: 53, 101: 50, 105: 51} print(str.translate(trantab)) # th3s 3s str3ng 2x1mpl2....w4w!!!
String formatting
Python format format function
str = "{0} Love {1}".format('I', 'Lsgogroup') # Position parameter print(str) # I Love Lsgogroup str = "{a} Love {b}".format(a='I', b='Lsgogroup') # Key parameters print(str) # I Love Lsgogroup str = "{0} Love {b}".format('I', b='Lsgogroup') # Position parameter before key parameter print(str) # I Love Lsgogroup str = '{0:.2f}{1}'.format(27.658, 'GB') # Keep two decimal places print(str) # 27.66GB
Python string formatting symbols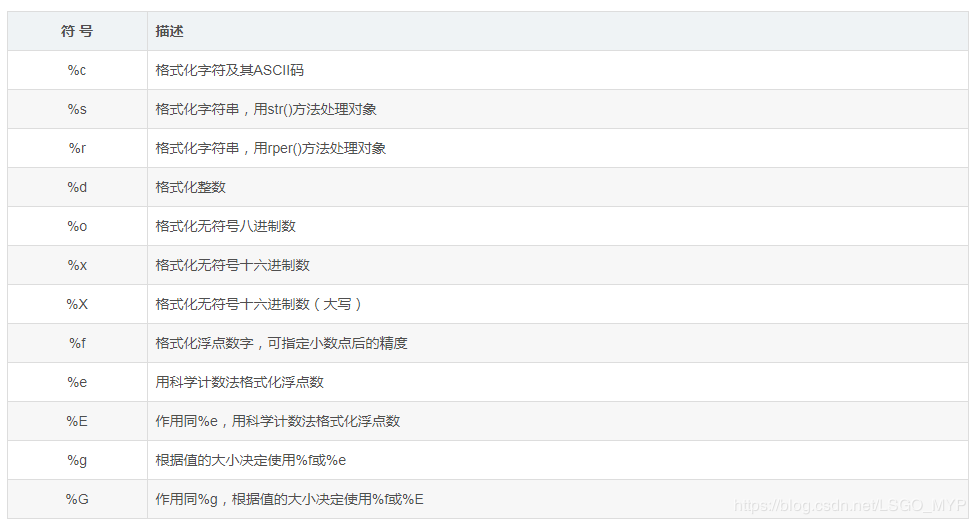
print('%c' % 97) # a print('%c %c %c' % (97, 98, 99)) # a b c print('%d + %d = %d' % (4, 5, 9)) # 4 + 5 = 9 print("My name is %s This year %d year!" % ('Xiao Ming', 10)) # My name is Xiao Ming, 10 years old! print('%o' % 10) # 12 print('%x' % 10) # a print('%X' % 10) # A print('%f' % 27.658) # 27.658000 print('%e' % 27.658) # 2.765800e+01 print('%E' % 27.658) # 2.765800E+01 print('%g' % 27.658) # 27.658 text = "I am %d years old." % 22 print("I said: %s." % text) # I said: I am 22 years old.. print("I said: %r." % text) # I said: 'I am 22 years old.'
- Formatting operator helper

print('%5.1f' % 27.658) # ' 27.7' print('%.2e' % 27.658) # 2.77e+01 print('%10d' % 10) # ' 10' print('%-10d' % 10) # '10 ' print('%+d' % 10) # +10 print('%#o' % 10) # 0o12 print('%#x' % 108) # 0x6c print('%010d' % 5) # 0000000005
2. Built in functions for sequences
- list(sub) converts an iteratable object to a list.
a = list() print(a) # [] b = 'I Love LsgoGroup' b = list(b) print(b) # ['I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p'] c = (1, 1, 2, 3, 5, 8) c = list(c) print(c) # [1, 1, 2, 3, 5, 8]
- tuple(sub) converts an iteratable object into a tuple.
a = tuple() print(a) # () b = 'I Love LsgoGroup' b = tuple(b) print(b) # ('I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p') c = [1, 1, 2, 3, 5, 8] c = tuple(c) print(c) # (1, 1, 2, 3, 5, 8)
str(obj) converts obj objects to strings
a = 123 a = str(a) print(a) # 123
len(sub) returns the number of sub containing elements
a = list() print(len(a)) # 0 b = ('I', ' ', 'L', 'o', 'v', 'e', ' ', 'L', 's', 'g', 'o', 'G', 'r', 'o', 'u', 'p') print(len(b)) # 16 c = 'I Love LsgoGroup' print(len(c)) # 16
max(sub) returns the maximum value in a sequence or parameter set
print(max(1, 2, 3, 4, 5)) # 5 print(max([-8, 99, 3, 7, 83])) # 99 print(max('IloveLsgoGroup')) # v
min(sub) returns the minimum value in a sequence or parameter set
print(min(1, 2, 3, 4, 5)) # 1 print(min([-8, 99, 3, 7, 83])) # -8 print(min('IloveLsgoGroup')) # G
sum(iterable[, start=0]) returns the sum of the sequence iterable and the optional parameter start.
print(sum([1, 3, 5, 7, 9])) # 25 print(sum([1, 3, 5, 7, 9], 10)) # 35 print(sum((1, 3, 5, 7, 9))) # 25 print(sum((1, 3, 5, 7, 9), 20)) # 45
sorted(iterable, key=None, reverse=False) sorts all objects that can be iterated.
numbers = [-8, 99, 3, 7, 83] print(sorted(numbers)) # [-8, 3, 7, 83, 99] print(sorted(numbers, reverse=True)) # [99, 83, 7, 3, -8]
reversed() is used to reverse elements in the list.
numbers = [-8, 99, 3, 7, 83] a = list(reversed(numbers)) print(a) # [83, 7, 3, 99, -8]
enumerate(sequence, [start=0])
It is used to combine a traversable data object (such as list, tuple or string) into an index sequence, and list data and data subscript at the same time. It is generally used in for loop.
seasons = ['Spring', 'Summer', 'Fall', 'Winter'] a = list(enumerate(seasons)) print(a) # [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] b = list(enumerate(seasons, 1)) print(b) # [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
for i, element in a: print('{0},{1}'.format(i, element))
zip([iterable, ...])
It is used to take iteratable objects as parameters, package the corresponding elements in the objects into tuples, and then return the objects composed of these tuples. The advantage of this is that it saves a lot of memory.
We can use the list() transformation to output the list.
If the number of elements of each iterator is different, the length of the returned list is the same as that of the shortest object. Using the * operator, the tuple can be decompressed into a list.
a = [1, 2, 3] b = [4, 5, 6] c = [4, 5, 6, 7, 8]
zipped = zip(a, b) print(zipped) # <zip object at 0x000000C5D89EDD88> print(list(zipped)) # [(1, 4), (2, 5), (3, 6)] zipped = zip(a, c) print(list(zipped)) # [(1, 4), (2, 5), (3, 6)]
a1, a2 = zip(*zip(a, b)) print(list(a1)) # [1, 2, 3] print(list(a2)) # [4, 5, 6]