First question: use the requests library to visit Baidu homepage 20 times, and return the length of his text and content attributes.
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue May 19 10:12:16 2020 4 5 @author: 49594 6 """ 7 8 import requests 9 url = "https://www.baidu.com/" 10 for i in range(20): 11 try: 12 rest = requests.get (url,timeout=30) 13 rest.raise_for_status() 14 r=rest.content.decode('utf-8') 15 print(r) 16 17 except: 18 print("error") 19 print("text Attribute length",len(rest.text)) 20 print("content Attribute length",len(rest.content))
Because the result is too long, only part of the crawler content is intercepted:1 <!DOCTYPE html> 2 <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>Baidu once, you will know</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=use Baidu Search class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>Journalism</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>Map</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>video</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>Post Bar</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>Sign in</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">Sign in</a>'); 3 </script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">More products</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>About Baidu</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>Read Before Using Baidu</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>Feedback</a> Beijing ICP Zheng 030173 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
The length output is as follows:
Textproperty length 2443
content attribute length 2443
Second question:
This is a simple html page. Please keep it as a string to complete the following calculation requirements.
a. Print the content of the head label and the last two digits of your student number
b get the body label content
c get the label object with id first
d get and print Chinese characters in html page
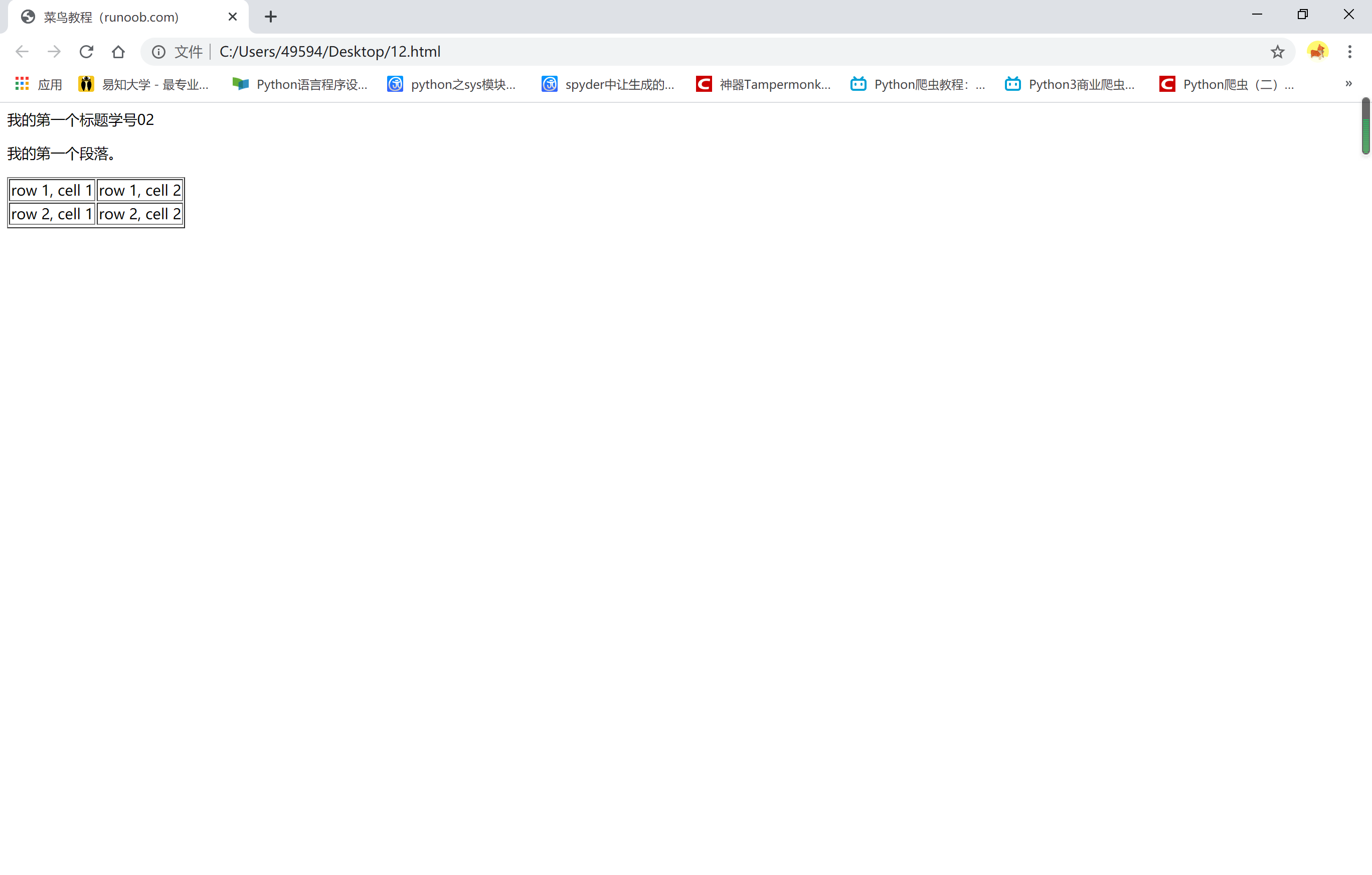
html is:
1 <!DOCTYPE html> 2 3 <html> 4 5 <head> 6 7 <meta charset="utf-8"> 8 9 <title>Rookie tutorial( runoob.com)</title> 10 11 </head> 12 13 <body> 14 15 <hl>My first title student number 25</hl> 16 17 <p id="first">My first paragraph.</p> 18 19 </body> 20 21 <table border="1"> 22 23 <tr> 24 25 <td>row 1, cell 1</td> 26 27 <td>row 1, cell 2</td> 28 29 </tr> 30 31 <tr> 32 33 <td>row 2, cell 1</td> 34 35 <td>row 2, cell 2</td> 36 37 <tr> 38 39 </table> 40 41 </html>