Introduction to distributed unique ID
The globally unique id of a distributed system is a scenario encountered by all systems. It is often used in search and storage as a unique identification or sorting, such as the globally unique order number and coupon code of a coupon. If two identical order numbers appear, it will undoubtedly be a huge bug for users.
In a single system, there is no challenge to generate a unique ID, because there is only one machine and one application. You can directly use a single instance plus an atomic operation to increase itself. In the distributed system, different applications, different computer rooms and different machines need to work hard to generate unique IDs.
One sentence summary:
Distributed unique ID is used to uniquely identify data.
Characteristics of distributed unique ID s
The core of distributed unique ID is uniqueness, and others are additional attributes. Generally speaking, an excellent global unique ID scheme has the following characteristics for reference only:
- Globally unique: cannot be repeated, core features!
- Roughly ordered or monotonically increasing: the self increasing feature is conducive to search, sorting, or range query
- High performance: fast ID generation response and low latency
- High availability: if you can only use a single machine and hang up, all the services that depend on the globally unique ID of the whole company are unavailable, so the services that generate the ID must be highly available
- Easy to use: it is user-friendly and can be packaged out of the box
- Information security: in some scenarios, if continuous, it is easy to guess, and attacks are also possible, which has to be chosen.
Generation scheme of distributed unique ID
UUID direct generation
Friends who have written Java know that sometimes we use a class UUID to write logs, and a random ID will be generated as the unique identification code of the current user's request record. Just use the following code:
String uuid = UUID.randomUUID();
The usage is simple and crude. The full name of UUID is actually universal unique identifier, or GUID(Globally Unique IDentifier). It is essentially a 128 bit binary integer. Usually, we will express it as a string composed of 32 hexadecimal numbers, which will hardly be repeated. It is an extremely huge number to the 128 power of 2.
The following is the description of Baidu Encyclopedia:
UUID consists of a combination of the following parts:
(1) The first part of UUID is related to time. If you generate a UUID after a few seconds, the first part is different and the rest are the same.
(2) Clock sequence.
(3) The globally unique IEEE machine identification number. If there is a network card, it is obtained from the MAC address of the network card. If there is no network card, it is obtained in other ways.
The only drawback of UUID is that the resulting string will be long. The most commonly used standard for UUID is Microsoft's guid (global unique identifiers). In ColdFusion, you can use the CreateUUID() function to simply generate UUIDs in the format of XXXXXXXX - XXXX - xxxxxxxxxxxxxxxxxx (8-4-4-16), where each x is a hexadecimal number in the range of 0-9 or a-f. The standard UUID format is xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12). You can download CreateGUID() UDF from cflib for conversion. [2]
(4) In hibernate (Java orm framework), the UUID is composed of IP-JVM startup time - current time shifted 32 bits to the right - current time - internal count (8-8-4-8-4)
If you want to repeat, two identical virtual machines have the same startup time, the same random seeds, and generate UUIDs at the same time, there is a very small probability that they will repeat. Therefore, we can think that they will repeat in theory, but they can't repeat in practice!!!
uuid benefits:
- Good performance and high efficiency
- Directly generate locally without network request
- Different machines work one by one and will not repeat
uuid is so good. Is it a silver bullet? Of course, the disadvantages are also prominent:
- There is no way to guarantee the increasing trend, and there is no way to sort
- uuid is too long and takes up a lot of storage space, especially in the database, which is not friendly to indexing
- Without business attributes, this thing is a string of numbers, which is meaningless or regular
Of course, some people want to improve this guy, such as unreadability transformation. Use uuid to int64 to convert it to long type:
byte[] bytes = Guid.NewGuid().ToByteArray(); return BitConverter.ToInt64(bytes, 0);
Another example is to transform the disorder, such as NHibernate's Comb algorithm, which retains the first 20 characters of uuid and the time of generating the last 12 characters with guid. The time is roughly orderly, which is a small improvement.
Comments: UUID does not exist as a database index. As some logs, context recognition is still very popular, but it's really crashing if it is used as an order number
Database autoincrement sequence
Stand alone database
The database primary key itself has a natural feature of self increment. As long as the ID is set as the primary key and self increment, we can insert a record into the database and return the self increment ID, such as the following table creation statement:
CREATE DATABASE `test`;
use test;
CREATE TABLE id_table (
id bigint(20) unsigned NOT NULL auto_increment,
value char(10) NOT NULL default '',
PRIMARY KEY (id),
) ENGINE=MyISAM;Insert statement:
insert into id_table(value) VALUES ('v1');advantage:
- Stand alone, simple and fast
- Natural self increasing, atomicity
- Digital id sorting, search and paging are more favorable
The disadvantages are also obvious:
- Stand alone, hang up and run away with the bucket
- One machine, high concurrency is impossible
Clustered database
Since the high concurrency and high availability of a single machine are uncertain, add machines and build a database in cluster mode. Since there are multiple master s in cluster mode, each machine must not generate its own id, which will lead to duplicate IDs.
At this time, it is particularly important to set the starting value and step size for each machine. For example, three machines V1, V2 and V3:
Uniform step size: 3 V1 Starting value: 1 V2 Starting value: 2 V3 Starting value: 3
Generated ID:
V1: 1, 4, 7, 10... V2: 2, 5, 8, 11... V3: 3, 6, 9, 12...
To set up the command line, you can use:
set @@auto_increment_offset = 1; // Starting value set @@auto_increment_increment = 3; // step
In this way, when there are enough masters, the high performance is guaranteed. Even if some machines are down, slave can be added. It can be based on master-slave replication, which can greatly reduce the pressure on a single machine. However, there are still disadvantages:
- The master-slave replication is delayed and the master is down. After the slave node is switched to the master node, it may issue signals repeatedly.
- After the initial value and step size are set, if the machine needs to be added later (horizontal expansion), it is very troublesome to adjust, and it may be necessary to shut down and update many times
Batch number segment database
The above database access is too frequent. As soon as the concurrency increases, many small probability problems may occur. Why don't we directly take out a section of id at one time? Put it directly in the memory for use. When it is used up, you can apply for another period. Similarly, the advantages of the cluster mode can be retained. Take out a range of IDs from the database each time, such as three machines, and issue:
Take 1000 each time, and each step is 3000 V1: 1-1000,3001-4000, V2: 1001-2000,4001-5000 V3: 2001-3000,5001-6000
Of course, if you don't have multiple machines, you can apply for 10000 numbers at a time, implement it with optimistic lock, and add a version number,
CREATE TABLE id_table ( id int(10) NOT NULL, max_id bigint(20) NOT NULL COMMENT 'Current maximum id', step int(20) NOT NULL COMMENT 'Step size of segment No', version int(20) NOT NULL COMMENT 'Version number', `create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, `update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) )
Only when it is used up, it will re apply to the database. During the competition, optimistic lock can ensure that only one request is successful. Others can wait for others to take it out and put it in the application memory, and then take it. In fact, it is an update operation:
update id_table set max_id = #{max_id+step}, version = version + 1 where version = # {version}a key:
- Batch acquisition to reduce database requests
- Optimistic lock to ensure accurate data
- Acquisition can only be obtained from the database. Batch acquisition can be made into asynchronous scheduled tasks. If it is found that it is less than a certain threshold, it will be supplemented automatically
Redis self increment
redis has an atomic command incr. The atom increases automatically. redis is fast and based on memory:
127.0.0.1:6379> set id 1 OK 127.0.0.1:6379> incr id (integer) 2
Of course, if there is a problem with a single redis, you can also go to the cluster. You can also use the initial value + step size and the INCRBY command. Several machines can basically resist high concurrency.
advantage:
- Memory based, fast
- Natural sorting, self increasing, conducive to sorting search
Disadvantages:
- After the step size is determined, it is difficult to adjust the added machine
We need to pay attention to persistence, availability, etc. to increase the complexity of the system
If the redis persistence is RDB and a snapshot is taken for a period of time, the data may hang up before it can be persisted to the disk, and duplicate IDs may appear when restarting. At the same time, if the master-slave delay, the master node hangs up, and the master-slave switch may also appear duplicate IDS. If AOF is used, if a command is persisted once, it may slow down the speed. If it is persisted once a second, it may lose data for up to one second. At the same time, data recovery will be slow. This is a trade-off process.
Zookeeper generates a unique ID
zookeeper can actually be used to generate unique ID s, but we don't need it because the performance is not high. znode has a data version and can generate a 32-bit or 64 bit serial number. This serial number is unique, but if the competition is large, it also needs to add distributed locks, which is not worth it and inefficient.
Meituan's Leaf
The following are official documents from meituan: https://tech.meituan.com/2019...
Leaf adheres to several requirements at the beginning of design:
- It is globally unique. There will never be duplicate IDS, and the overall trend of IDS is increasing.
- High availability. The service is completely based on the distributed architecture. Even if MySQL goes down, it can tolerate the unavailability of the database for a period of time.
- High concurrency and low latency. On the virtual machine of CentOS 4C8G, the remote call of QPS can reach 5W +, and the TP99 can be within 1ms.
- The access is simple. It can be accessed directly through the company's RPC service or HTTP call.
It is very clear in the document. There are two versions:
- V1: ID is provided by pre distribution, that is, the above-mentioned number segment distribution, and the table design is similar, which means pulling ID in batch
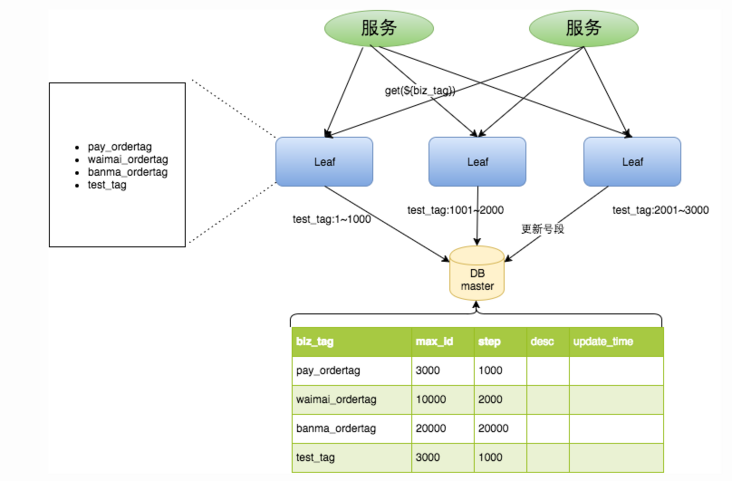
The disadvantage of this is that it takes a lot of time to update the number segment, and it is unavailable if it goes down or master-slave replication.
Optimization:
- 1. First, a double Buffer optimization is made, that is, asynchronous update, which means that two number segments are created. For example, when one number segment is consumed by 10%, the next number segment will be allocated. It means allocation in advance, and asynchronous thread update
- 2. In the above scheme, the number segment may be fixed, and the span may be too large or too small. Then make dynamic changes, determine the size of the next number segment according to the flow, and adjust it dynamically
- V2: leaf snowflake. Leaf provides the implementation of the Java version. At the same time, it makes a weak dependency on the machine number generated by zookeeper. Even if there is a problem with zookeeper, it will not affect the service. After taking the worker ID from zookeeper for the first time, leaf will cache a worker ID file on the local file system. Even if there is a problem with the zookeeper and the machine happens to be restarting, the normal operation of the service can be guaranteed. In this way, the weak dependence on third-party components is achieved, and the SLA is improved to a certain extent.
Snowflake (snowflake algorithm)
snowflake is an ID generation algorithm used in the internal distributed project of twitter. It is widely popular after open source. The ID generated by it is Long type, 8 bytes, 64 bits in total, from left to right:
- 1 bit: not used. The highest bit in binary is 1, which is negative, but the unique ID to be generated is a positive integer, so this 1 bit is fixed to 0.
- 41 bits: record timestamp (MS). This bit can be $(2 ^ {41} - 1) / (1000 * 60 * 60 * 24 * 365) = 69 $years
- 10 digits: record the ID of the working machine, either machine ID or machine room ID + machine ID
- 12 digits: serial number, which is the id serial number generated simultaneously within one millisecond on a machine in a machine room
If each machine generates an ID according to the above logic, the trend will increase, because time is increasing, and there is no need to build a distributed one, which is much simpler.
It can be seen that snowflake is strongly dependent on time. Theoretically, time is moving forward, so the number of digits in this part is also increasing. However, one problem is time callback, that is, time suddenly goes backward, which may be a fault or the time is taken out after restart. How can we solve the problem of time callback?
- The first scheme: judge when obtaining the time. If it is less than the last timestamp, do not allocate it and continue to cycle to obtain the time until it meets the conditions.
- The second scheme: the above scheme is only suitable for those with small clock callback. If the interval is too large, blocking and waiting is certainly not desirable. Therefore, either an error is reported directly and the service is refused for callback exceeding a certain size, or one scheme is to use the extension booth and add 1 to the extension booth after callback, so that the ID can still remain unique.
Java code implementation:
public class SnowFlake {
// Data center (machine room) id
private long datacenterId;
// Machine ID
private long workerId;
// Same time series
private long sequence;
public SnowFlake(long workerId, long datacenterId) {
this(workerId, datacenterId, 0);
}
public SnowFlake(long workerId, long datacenterId, long sequence) {
// Legal judgment
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
// Start timestamp
private long twepoch = 1420041600000L;
// The machine room number, the number of digits occupied by the ID of the machine room, 5 bit s, the maximum: 11111 (binary) - > 31 (decimal)
private long datacenterIdBits = 5L;
// The maximum number of digits occupied by the machine ID is 5 bit s: 11111 (binary) - > 31 (decimal)
private long workerIdBits = 5L;
// 5 bit can only have 31 digits at most, that is, the machine id can only be within 32 at most
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 5 bit can only have 31 digits at most, and the machine room id can only be within 32 at most
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// The number of bits occupied by the sequence at the same time is 12 bits 111111111111 = 4095. At most, 4096 bits are generated in the same millisecond
private long sequenceBits = 12L;
// Offset of workerId
private long workerIdShift = sequenceBits;
// Offset of datacenter ID
private long datacenterIdShift = sequenceBits + workerIdBits;
// Offset of timestampLeft
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
// Serial number mask 4095 (0b111111 = 0xfff = 4095)
// It is used for the sum operation of serial number to ensure that the maximum value of serial number is between 0-4095
private long sequenceMask = -1L ^ (-1L << sequenceBits);
// Last timestamp
private long lastTimestamp = -1L;
// Get machine ID
public long getWorkerId() {
return workerId;
}
// Get machine room ID
public long getDatacenterId() {
return datacenterId;
}
// Get the latest timestamp
public long getLastTimestamp() {
return lastTimestamp;
}
// Get next random ID
public synchronized long nextId() {
// Gets the current timestamp in milliseconds
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
// duplicate removal
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
// Sequence sequence greater than 4095
if (sequence == 0) {
// Method called to the next timestamp
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// If it is the first acquisition of the current time, it is set to 0
sequence = 0;
}
// Record last timestamp
lastTimestamp = timestamp;
// Offset calculation
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
private long tilNextMillis(long lastTimestamp) {
// Get latest timestamp
long timestamp = timeGen();
// If the latest timestamp is found to be less than or equal to the timestamp whose serial number has exceeded 4095
while (timestamp <= lastTimestamp) {
// If not, continue
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake worker = new SnowFlake(1, 1);
long timer = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
worker.nextId();
}
System.out.println(System.currentTimeMillis());
System.out.println(System.currentTimeMillis() - timer);
}
}
Baidu uid generator
It is developed by Baidu. Based on the Snowflake algorithm, you can define the number of bits of each part by yourself. It has also made a lot of optimization and expansion: https://github.com/baidu/uid-...
UidGenerator is implemented in Java and is based on Snowflake Unique ID generator for the algorithm. UidGenerator works as a component in an application project. It supports custom workerId bits and initialization policies, which are applicable to docker Scenarios such as instance automatic restart and drift in virtualization environment. In terms of implementation, UidGenerator solves the natural concurrency limitation of sequence by borrowing the future time; RingBuffer is used to cache the generated UID, parallelize the production and consumption of UID, and supplement the CacheLine to avoid the hardware level "pseudo sharing" problem caused by RingBuffer. Finally, the single machine QPS can reach 6 million.
Qin Huaiyi's viewpoint
No matter what kind of uid generator, ensuring uniqueness is the core. Other performance or high availability issues can be considered on this core. The overall scheme is divided into two types:
Centralization: a third-party center, such as Mysql, Redis and Zookeeper
- Advantages: self increasing trend
- Disadvantages: increase the complexity, generally have to cluster, and agree the step size in advance
Decentralized: generated directly on the local machine, snowflake, uuid
- Advantages: simple, efficient, no performance bottleneck
- Disadvantages: the data is long and the self increasing attribute is weak
No one is perfect. There are only solutions that meet the business and current volume. There is no optimal solution in the technical solution.
[about the author]:
Qin Huai, the official account of Qin Huai grocery store, is not in the right place for a long time. Personal writing direction: Java source code analysis, JDBC, Mybatis, Spring, redis, distributed, sword finger Offer, LeetCode, etc. I carefully write every article. I don't like the title party and fancy. I mostly write a series of articles. I can't guarantee that what I write is completely correct, but I guarantee that what I write has been practiced or searched for information. Please correct any omissions or mistakes.