catalogue
1.2 what can you do by learning XML
2.2.1 In an XML document, there must be and only one root tag is allowed
2.2.2 Tags can be nested, but no crossing is allowed
2.2.4 Duplicate tag names are allowed
2.2.5 in addition to the start and end, the tag also has attributes
3: Syntax advanced CDATA (understand)
four point four DOM4J parsing (key)
5: DOM4J parsing XML (detailed)
5.2 Document object interpretation
5.2 Element object interpretation
5.3 analyzing local file cases
5.3.2 start parsing local files
five point four Analyzing network file cases
6.2.1 Method 1 XPATH parsing single output code interpretation
6.2.2 method 2 XPATH parsing multiple output code interpretation
8: Use of XStream generated XML (understand)
1: Introduction to XML
XML is an eXtensible Markup Language
features:
· xml is a platform independent markup language
· xml is self descriptive
1.1 history of XML
- 1969 GML (General Markup Language), the data specification whose main purpose is to communicate between different machines
- 1985 SGML (standard universal markup language)
- 1993 HTML (hypertext markup language, www)
- 1998 XML (Extensible Markup Language)
1.2 what can you do by learning XML
1 . Network data transmission
2 . data storage
3 . configuration file
1.3 understanding XML files
one . XML file is a way to save XML data
two XML data can also exist in other ways (such as building XML data in memory)
three Don't narrowly interpret XML language as an XML file (or an attribute in a Java object)
2: Syntax format of XML
2.1 XML document declaration
<?xml version="1.0" encoding="UTF-8"?>
2.2 rules for using XML tags
An xml document consists of tags
Syntax:
Start tag (open tag): < tag name >
End tag (closed tag): < / tag name >
Tag name:
Custom names must follow the following naming rules:
one Names can contain letters, numbers, and other characters
two The name cannot start with a number or punctuation mark
three The name cannot start with the character "XML" (or XML, XML)
four The name cannot contain spaces or colons (:)
five Names are case sensitive
Tag content: between the start tag and the end tag, it is the content of the tag
For example, we use tags to describe a person's name < Name > happy < / name >
2.2.1 In an XML document, there must be and only one root tag is allowed
Positive example:
<names>
<name>Zhang San</name>
<name>Li Si</name>
</names>
Counterexample:
<name>Li Si</name> <name>Pockmarks</name>
2.2.2 Tags can be nested, but no crossing is allowed
Positive example:
<person>
<name>Li Si</name>
<age>18</age>
</person>Counterexample:
<person>
<name>Li Si<age></name>
18</age>
</person>
2.2.3 Hierarchical address of markers (child marker, parent marker, brother marker, descendant marker, ancestor marker)
For example:
<persons>
<person>
<name>Li Si</name>
<length>180cm</length>
</person>
<person>
<name>Li Si</name>
<length>200cm</length>
</person>
</persons>name is a child marker of person. It is also a descendant marker of person
name is the descendant tag of persons
name is the sibling token of length
person is the parent tag of name
People is the ancestral marker of name
2.2.4 Duplicate tag names are allowed
2.2.5 in addition to the start and end, the tag also has attributes
The attribute in the tag, which is described at the beginning of the tag, consists of attribute name and attribute value
Format:
In the start tag, describe the attribute
It can contain 0-n attributes, and each attribute is a key value pair!
Attribute names are not allowed to be repeated, keys and values are connected by equal signs, and multiple attributes are separated by spaces
Attribute values must be enclosed in quotation marks
Case:
<persons>
<person id="10001" groupid="1">
<name>Li Si</name>
<age>18</age>
</person>
<person id="10002" groupid="1">
<name>Li Si</name>
<age>20</age>
</person>
</persons>
2.2.6 XML annotation rules
Comments in XML are similar to those in HTML:
<!--This is a comment-->
be careful!
· Don't put comments in the middle of tags
· Note content should not appear--
· Comments cannot be nested
· You can place comments anywhere except for tags
· Comments cannot be written before the document declaration
3: Syntax advanced CDATA (understand)
CDATA
CDATA is text data that should not be parsed by an XML parser.
Characters like "<" and "&" are illegal in XML elements.
"<" generates an error because the parser interprets the character as the beginning of a new element.
"&" generates an error because the parser interprets the character as the beginning of the character entity
Some text, such as JavaScript code, contains a large number of "<" or "&" characters. To avoid errors, you can define the script code as CDATA.
Everything in the CDATA section is ignored by the parser.
The CDATA section starts with "<! [CDATA [" and ends with "]] >":
Case:
<![CDATA[<<<>>>]]>
4: Parsing XML with Java
Interview question: how many XML parsing methods are there in Java? What are they? What are the advantages and disadvantages?
A: there are four XML parsing methods in java: SAX parsing, DOM parsing, JDOM parsing and DOM4J parsing (key points)
The advantages and disadvantages are as follows.
4.1 SAX analysis
Introduction:
- The parsing method is an event driven mechanism!
- SAX parser, The XML file is read line by line and parsed. An event is triggered whenever the start / end / content / attribute of a tag is parsed
- We can write programs to deal with these events when they occur
advantage:
- Analysis can start immediately, rather than waiting for all data to be processed
- Load line by line to save memory. It is helpful to parse documents larger than system memory
- Sometimes, instead of parsing the entire document, it can stop parsing when a condition is met
Disadvantages:
- For one-way parsing, the document hierarchy cannot be located and different parts of the data of the same document cannot be accessed at the same time (because line by line parsing, when parsing line n, line n-1 has been released and cannot be operated)
- You cannot know the hierarchy of the element when the event occurs. You can only maintain the parent / child relationship of the node yourself
- Read only parsing mode, unable to modify the content of XML document
four point two DOM parsing
Introduction:
- It is the official W3C standard that represents XML documents in a platform and language independent manner. Analyzing this structure usually needs to load the whole document and establish a document tree model in memory. Programmers can complete data acquisition, modification and deletion by operating the document tree
advantage:
- The document is loaded in memory, allowing changes to data and structure
- The access is bidirectional, and the data can be parsed Bi directionally in the tree at any time
Disadvantages:
- All documents are loaded in memory, which consumes a lot of resources. (documents are generally small and can be ignored, so most of them are parsed in DOM)
four point three JDOM parsing
Introduction:
- The goal is to become a Java specific document model that simplifies interaction with XML and is faster than using DOM. Since it is the first Java specific model, JDOM has been vigorously promoted and promoted
- The JDOM document states that its purpose is to "solve 80% (or more) Java/XML problems with 20% (or less) (assuming 20% according to the learning curve)
advantage:
- Using concrete classes instead of interfaces simplifies the DOM API
- A large number of Java collection classes are used to facilitate Java developers
Disadvantages:
- No good flexibility
- The performance is not so excellent
four point four DOM4J parsing (key)
Introduction:
- It is an intelligent branch of JDOM
- It incorporates many capabilities beyond the basic XML document representation, including integrated XPath (DOM tree is similar to the inclusion relationship of file directory), XML Schema support, and event based processing for large documents or streaming documents. It also provides options for building document representations
- DOM4J is a very excellent Java XML API. It has the characteristics of excellent performance, powerful function and extremely easy to use. At the same time, it is also an open source software. Now you can see that more and more Java software is using DOM4J to read and write XML
- At present, DOM4J is widely used in many open source projects, such as Hibernate
5: DOM4J parsing XML (detailed)
5.1 steps:
package com.java.demo1;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo1 {
public static void main(String[] args) throws IOException, DocumentException {
//1. Import the jar file dom4j.jar
//2. Create an input stream that points to an XML file
FileInputStream fis = new FileInputStream("xml Address of the file");
//3. Create an XML reader object
SAXReader sr = new SAXReader();
//4. Use the reading tool object to read the input stream of the XML document and get the document object
Document doc = sr.read(fis);
//5. Get the root element object in the XML document through the document object
Element root = doc.getRootElement();
}
}
5.2 Document object interpretation
Refers to the entire XML document loaded into memory
Common methods:
// Get the root element object in the XML document through the document object
Element root = doc.getRootElement();
// Add root node
Element root = doc.addElement("Root node name");5.2 Element object interpretation
Refers to a single node in an XML document
Common methods:
1. Get node name
String getName();
2. Get node content
String getText();
3. Set node content
String setText();
4. Obtain the first child node object matching the name according to the name of the child node
Element element(String child node name);
5. Get all child node objects
List<Element> elements();
6. Get the attribute value of the node
String attributeValue(String attribute name);
7. Get the content of child nodes
String elementText(String child node name);
8. Add child nodes
Element addElement(String child node name);
9. Add attribute void addAttribute(String attribute name, String attribute value);
5.3 analyzing local file cases
5.3.1 importing jar files
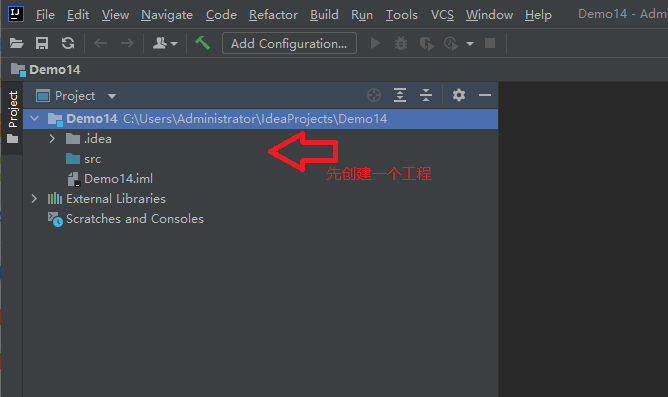
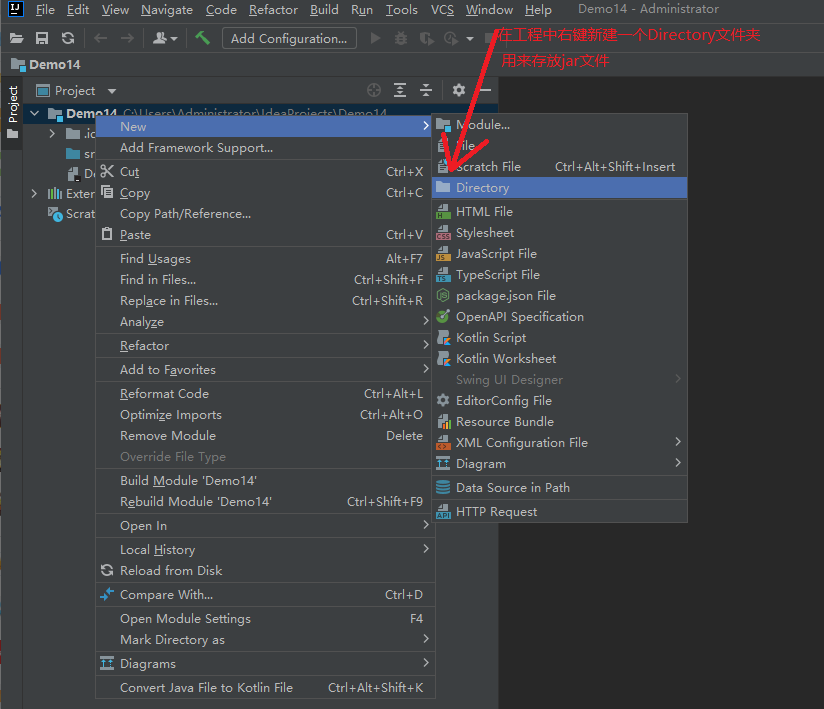
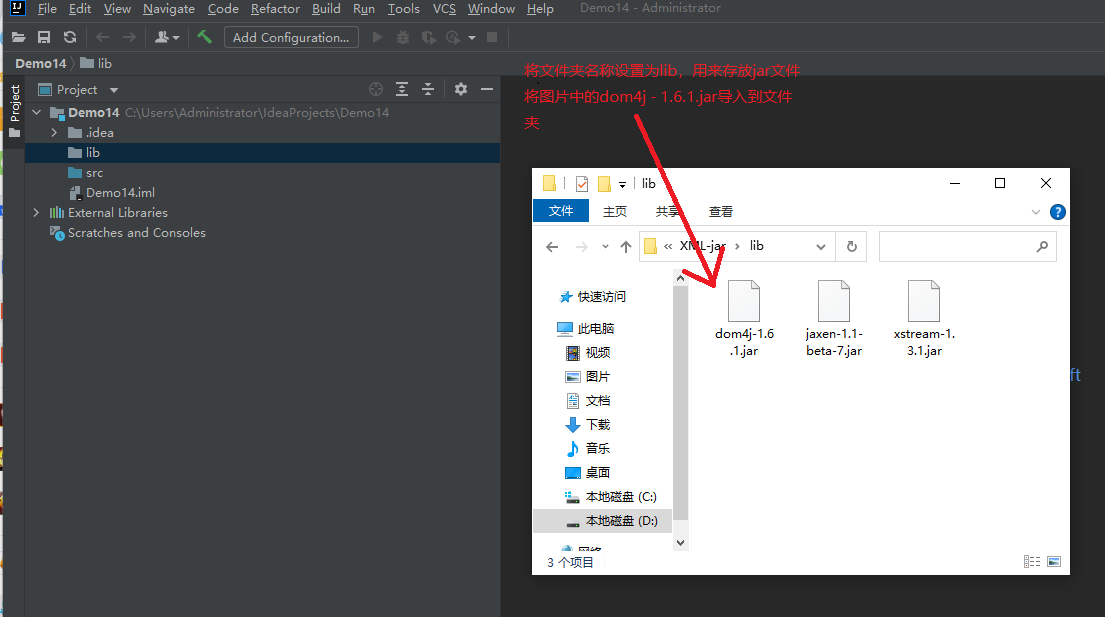
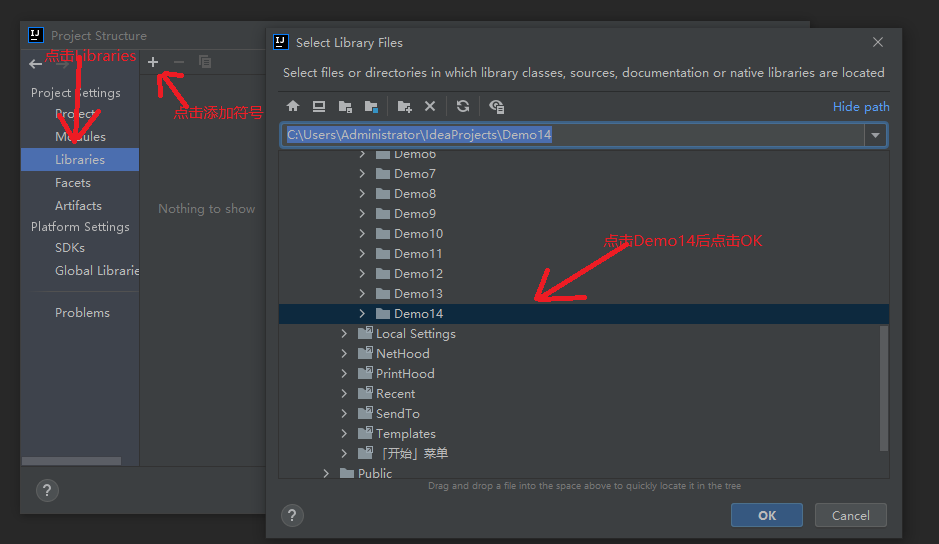
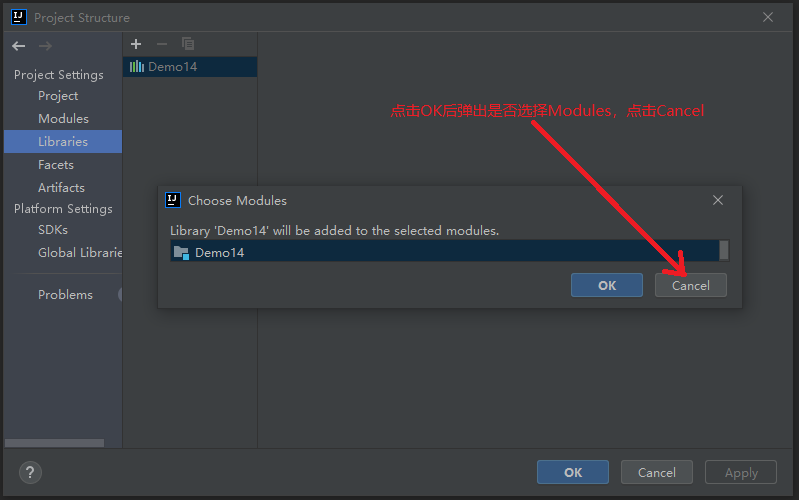
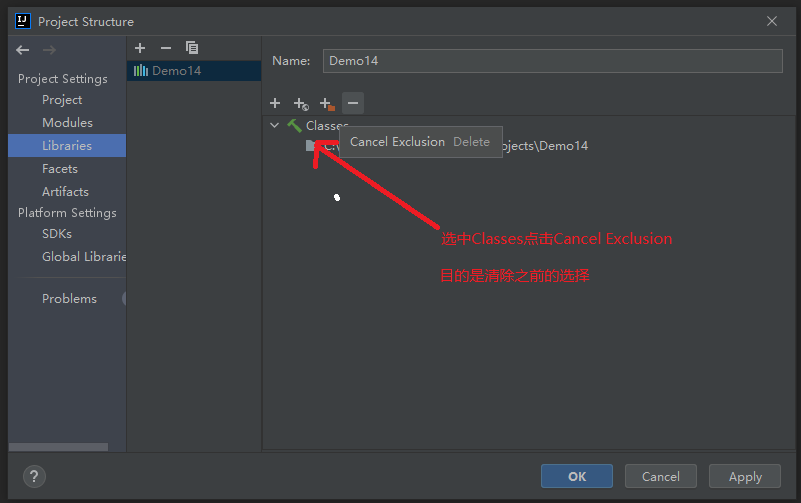
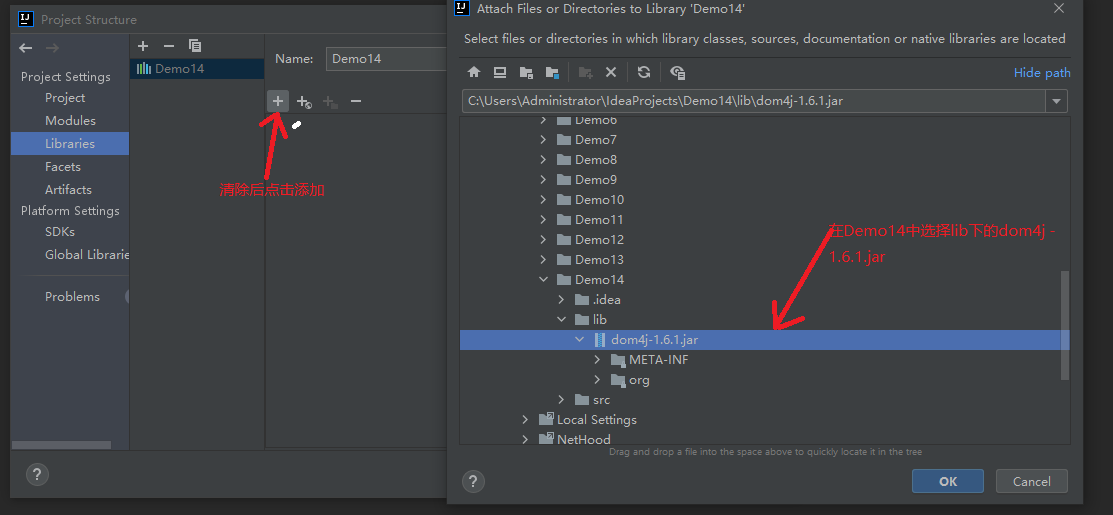
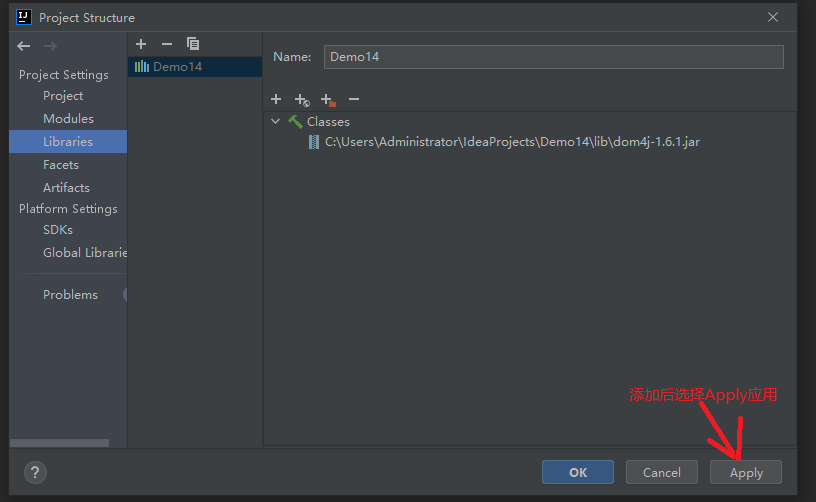
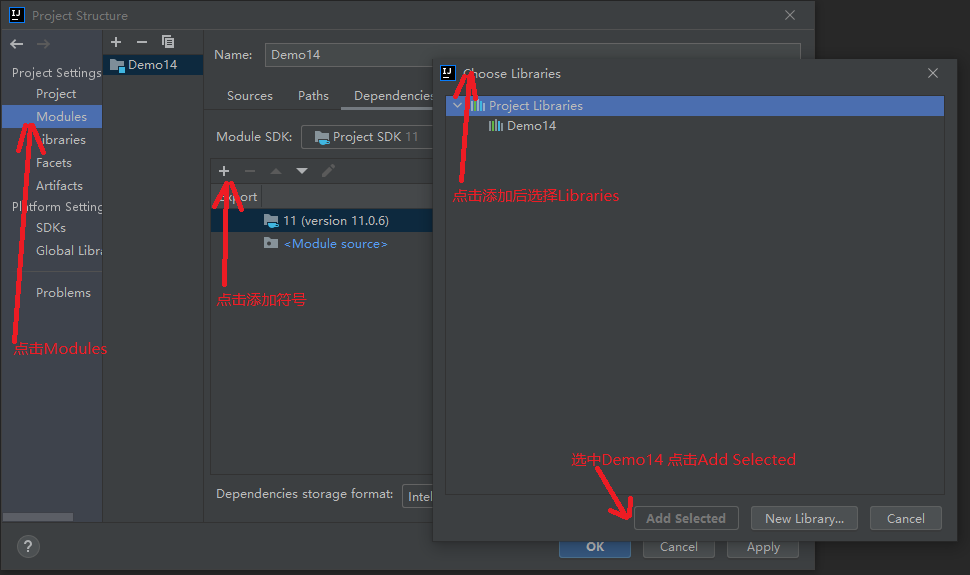
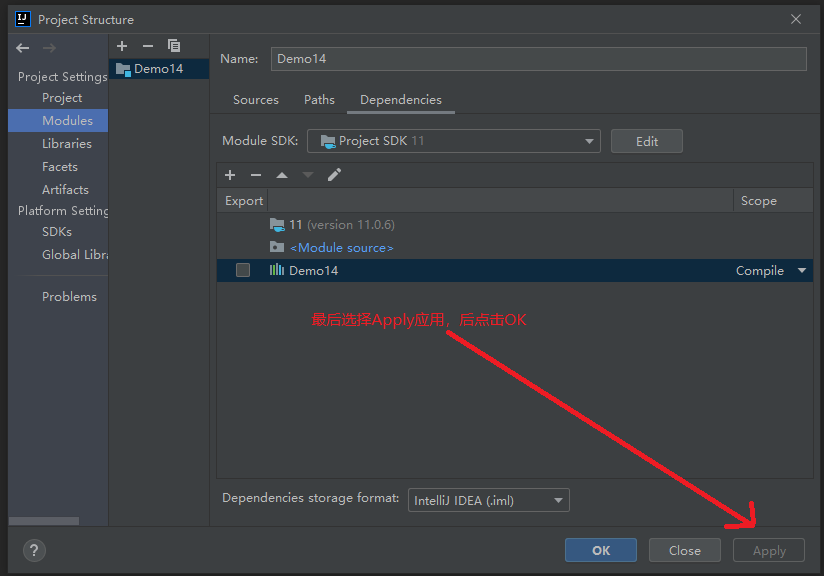
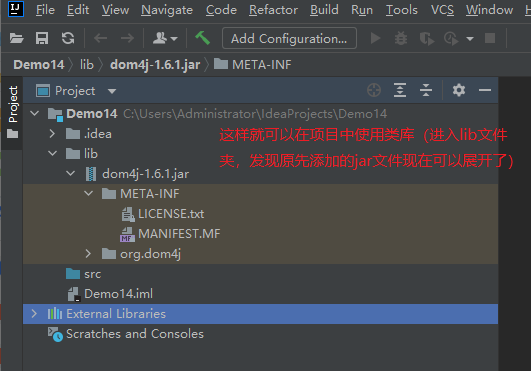
5.3.2 start parsing local files
Case:
First, create a Demo.xml file under Disk c and edit the contents
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="1001">
<name>Golden Apple</name>
<info>La La La</info>
</book>
<book id="1002">
<name>Silver Apple</name>
<info>Rululu</info>
</book>
</books>Then we begin to parse the contents of this xml file
package com.java.demo1;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.List;
public class Demo1 {
public static void main(String[] args) throws IOException, DocumentException {
//1. Gets the input stream of the file
FileInputStream fis = new FileInputStream("c://Demo.xml");
//2. Create an XML reader object
SAXReader sr = new SAXReader();
//3. Through the reading tool, read the input stream of XML document and get the document object
Document doc = sr.read(fis);
//4. Get the root node object of the document through the document object
Element root = doc.getRootElement();
//5. Get all child nodes through the root node
List<Element> es = root.elements();
//6. Loop through two book s
for(int i=0;i<es.size();i++){
Element book = es.get(i);
System.out.println(book.attributeValue("id"));
//Parse the content of name under the current book
System.out.println(book.elementText("name"));
//Parse the content of info under the current book
System.out.println(book.elementText("info"));
System.out.println("---------------");
}
fis.close();
}
}
It can be found that the content in the xml file has been parsed And the output result may contain a warning. The reason for the warning is that our jdk version is too high, but it does not affect the operation.
five point four Analyzing network file cases
The network file is from the website:
http://apis.juhe.cn/mobile/get?%20phone = phone number & dtype = XML & key = 9f3923e8f87f1ea50ed4ec8c39cc9253
The website opened after filling in the mobile phone number is as follows:

Start parsing the contents of this web address:
package com.java.demo1;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
public class Demo2 {
public static void main(String[] args) throws IOException, DocumentException {
String phone = "18731371698";
//1. Get the input stream of XML resources
URL url = new URL("http://apis.juhe.cn/mobile/get?%20phone="+phone+"&dtype=xml&key=9f3923e8f87f1ea50ed4ec8c39cc9253");
URLConnection conn = url.openConnection();
InputStream is = conn.getInputStream();
//2. Create an XML reading object
SAXReader sr = new SAXReader();
//3. Read the object, read the XML data, and return a document object
Document doc = sr.read(is);
//4. Get root node
Element root = doc.getRootElement();
//5. Analysis content
String code = root.elementText("resultcode");
if("200".equals(code)){
Element result = root.element("result");
String province = result.elementText("province");
String city = result.elementText("city");
if(province.equals(city)){
System.out.println("The mobile phone number belongs to:"+city);
}else {
System.out.println("The mobile phone number belongs to:"+province+" "+city);
}
}else {
System.out.println("Please enter the correct mobile phone number");
}
}
}
6: DOM4J - XPATH parsing XML
The jar used is jaxen-1.1-beta-7.jar The import method is the same as above
6.1 path expression:
Quickly find an element or group of elements through a path
Path expression:
one / : Find from root node
two // : Find descendant nodes from the location of the node initiating the lookup***
three . : Find current node
four .. : Find parent node
five @ : Select an attribute*
6.1.1 Attribute usage:
[@ property name = 'value']
[@ attribute name > 'value']
[@ property name < 'value']
[@ attribute name! = 'value']
6.1.2 examples
books: Path: / / book[@id='1']//name
books
book id=1
name
info
book id=2
name
info6.2 use steps
Two methods of Node class are used to complete the search:
(Node is the parent interface of Document and Element)
Method 1
//Find a matching single node according to the path expression
Element e = selectSingleNode("Path expression");
Method 2
//Find all matching nodes according to the path expression
List<Element> es = selectNodes("Path expression");
6.2.1 Method 1 XPATH parsing single output code interpretation
The xml file used is the xml file under the above c disk, which remains unchanged
package com.java.demo1;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo1 {
public static void main(String[] args) throws IOException, DocumentException {
//1. Get input stream
FileInputStream fis = new FileInputStream("c://Demo.xml");
//2. Create XML read object
SAXReader sr = new SAXReader();
//3. Read and get document object
Document doc = sr.read(fis);
//4. Find the name node through the document object + xpath
Node node = doc.selectSingleNode("//book[@id='1001']//name");
System.out.println(node.getName()+":"+node.getText());
fis.close();
}
}
6.2.2 method 2 XPATH parsing multiple output code interpretation
package com.java.demo1;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.List;
public class Demo1 {
public static void main(String[] args) throws IOException, DocumentException {
//1. Get input stream
FileInputStream fis = new FileInputStream("c://Demo.xml");
//2. Create XML read object
SAXReader sr = new SAXReader();
//3. Read and get document object
Document doc = sr.read(fis);
//4. Find all the name nodes through the document object + xpath
List<Node> names = doc.selectNodes("//name");
for (int i=0;i< names.size();i++){
System.out.println(names.get(i).getName());
System.out.println(names.get(i).getText());
}
fis.close();
}
}
7: Generate XML using Java
Steps:
1. Create an empty document object through the document helper
Document doc = DocumentHelper.createDocument();
2. Add a root node to the document object
Element root = doc.addElement("Root node name");
3. Enrich our child nodes through the root node object root
Element e = root.addElement("Element name");
4. Create a file output stream for storing XML files
FileOutputStream fos = new FileOutputStream("Location to store");
5. Convert the file output stream to XML document output stream
XMLWriter xw = new XMLWriter(fos);
6. Write the document
xw.write(doc);
7. Release resources
xw.close();
Case:
package com.java.demo1;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.XMLWriter;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo3 {
public static void main(String[] args) throws IOException {
//1. Create a document object through the document helper
Document doc = DocumentHelper.createDocument();
//2. Add a node to the document
Element books = doc.addElement("books");
//3. Enrich child nodes through root nodes
for (int i = 0; i < 100; i++) {
Element book = books.addElement("book");
Element name = book.addElement("name");
name.setText("Golden Apple");
Element info = book.addElement("info");
info.setText("Ha ha ha");
Element id = book.addAttribute("id", 100 + i + "");
}
//4. Create a file output stream and set the generation path
FileOutputStream fos = new FileOutputStream("c://books.xml");
//5. Convert the output stream to XML output stream
XMLWriter xw = new XMLWriter(fos);
//6. Write the document
xw.write(doc);
//7. Release resources
xw.close();
System.out.println("completion of enforcement");
}
}
After executing the program, you will find that a books.xml file is generated under disk c
8: Use of XStream generated XML (understand)
Use jar as xstream - 1.3.1.jar The import method is the same as above
Generally, an XML file will not be generated directly from a blank document in the above way. Instead, an object is converted into an XML file for transmission. It is more complicated to use the above methods, so XStream is introduced.
8.1 use steps
Quickly convert objects in Java into XML strings
Use steps:
1. Create an XStream object;
XStream x = new XStream();
2. Modify the node name generated by the class (the default node name is package name. Class name);
x.alias("Node name",Class name.class);
3. Pass in an object and generate an XML string
String xml character string = x.toXML(object);
8.1.1 cases
package com.java.demo1;
import com.thoughtworks.xstream.XStream;
import java.util.Objects;
public class Demo4 {
public static void main(String[] args) {
Person p = new Person();
p.setName("Zhang San");
p.setAge("18");
//XStream usage
//1. Create XStream object
XStream x = new XStream();
//2. Modify the generated root node (optional, the default is package name. Class name)
x.alias("person",Person.class);
//3. The incoming object starts to be generated
String xml = x.toXML(p);
System.out.println(xml);
}
// Create an inner class and convert the inner class into XML form through XStream
static class Person{
private String name;
private String age;
public Person() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name) && Objects.equals(age, person.age);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age='" + age + '\'' +
'}';
}
}
}
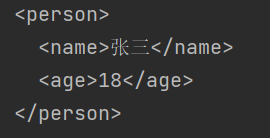
As can be seen from the output result, the internal class has been converted to xml for output
9: JSON
9.1 what is JSON?
- JSON, the full name is JavaScript Object Notation, that is, JavaScript Object Notation.
- JSON is a lightweight, text-based, human readable format
- Although JavaScript is included in the name of JSON, this means that its syntax rules refer to JavaScript objects, not only for JavaScript language
- JSON is very easy to read and write for both people and machines, and compared with XML (another common data exchange format), the file is smaller, so it has quickly become a very popular exchange format on the network.
- In recent years, JavaScript has become the de facto standard language of browsers. The popularity of JavaScript is also closely related to the popularity of JSON.
- Because JSON itself is defined by referring to the rules of JavaScript objects, its syntax is almost the same as that of JavaScript objects.
- The founder of JSON format claims that this format will never be upgraded, which means that this format has long-term stability. Files written 10 years ago can also be used 10 years later without any compatibility problems.
9.2 syntax rules of JSON
- Array s are represented by square brackets ("[]").
- The object (0bject) is represented by braces ("{}").
- name/value pairs are combined into arrays and objects.
- The name is enclosed in double quotation marks, and the value includes string, numeric value, Boolean value, null, object and array.
- Parallel data are separated by commas (",")
{
"name":"Beaming with Joy",
"age":4,
"pengyou":["Zhang San","Li Si","WangTwo ","Pockmarks",{
"name":"Mustang teacher",
"info":"Run like a wild horse on the road of technical research"
}],
"heihei":{
"name":"glaive ",
"length":"40m"
}
}nine point three JSON and XML
JSON is often compared with XML, because the birth of JSON has more or less the meaning of replacing XNL. Compared with XML, JSON has the following advantages :
- No end tag, shorter length, faster reading and writing
- Can be parsed directly by the JavaScript interpreter
- You can use arrays
XML
<book>
<name>Golden Apple</name>
<info>plant apples</info>
</book>
JSON
{
"name":"Golden Apple",
"info":"plant apples"
}
9.4 JSON parsing
Method 1: through Gson analysis
Method 2: through fastjason analysis
9.4.1 Gson analysis
The jar used is gson-2.8.6.jar import method is the same as above
(1) Convert object to JSON
Set object Book class
package com.java.demo2;
import java.util.Objects;
public class Book {
private String id;
private String name;
private String info;
public Book() {
}
public Book(String id, String name, String info) {
this.id = id;
this.name = name;
this.info = info;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getInfo() {
return info;
}
public void setInfo(String info) {
this.info = info;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Book book = (Book) o;
return Objects.equals(id, book.id) && Objects.equals(name, book.name) && Objects.equals(info, book.info);
}
@Override
public int hashCode() {
return Objects.hash(id, name, info);
}
@Override
public String toString() {
return "Book{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", info='" + info + '\'' +
'}';
}
}
transformation:
package com.java.demo2;
import com.google.gson.Gson;
public class Demo1 {
public static void main(String[] args) {
//1. Create a Gson object
Gson g = new Gson();
//2. Conversion
Book book = new Book("100","Golden Apple","Ha ha ha");
String s = g.toJson(book);
System.out.println(s);
}
}

(2) Convert JSON to object
package com.java.demo2;
import com.google.gson.Gson;
public class Demo2 {
public static void main(String[] args) {
//1. Create a Gson object
Gson g = new Gson();
//2. Conversion
Book book = g.fromJson("{\"id\":\"100\",\"name\":\"Golden Apple\",\"info\":\"Ha ha ha\"}", Book.class);
System.out.println(book.getId());
}
}

(3) Convert JSON to a collection
package com.java.demo2;
import com.google.gson.Gson;
import java.util.HashMap;
import java.util.List;
public class Demo3 {
public static void main(String[] args) {
//1. Create a Gson object
Gson g = new Gson();
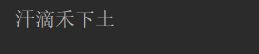
//2. Convert {"id":"100","name": "Golden Apple", "info": "hahaha", "page": ["weeding day at noon", "sweat dripping into the soil", "hahaha"]}
HashMap data = g.fromJson("{\"id\":\"100\",\"name\":\"Golden Apple\",\"info\":\"Ha ha ha\",\"page\":[\"Hoe standing grain gradually pawning a midday\",\"Sweat drops under the grass\",\"Ha ha ha\"]}", HashMap.class);
//The array will be converted to ArrayList type here, so converting to List type requires strong conversion
List page = (List) data.get("page");
System.out.println(page.get(1));
}
}
9.4.2 Fastjason parsing
Use the jar fastjson-1.2.70.jar
(1) Convert object to JSON
package com.java.demo2;
import com.alibaba.fastjson.JSON;
public class Demo4 {
public static void main(String[] args) {
Book book = new Book("100","Li Ge","Ha ha ha");
//1. Conversion
String json = JSON.toJSONString(book);
System.out.println(json);
}
}

(2) Convert JSON to object
package com.java.demo2;
import com.alibaba.fastjson.JSON;
public class Demo5 {
public static void main(String[] args) {
//Conversion {"id":"100","info": "hahaha", "name": "brother Li"}
Book book = JSON.parseObject("{\"id\":\"100\",\"info\":\"Ha ha ha\",\"name\":\"Li Ge\"}", Book.class);
System.out.println(book.getId());
}
}

(3) Convert JSON to a collection
package com.java.demo2;
import com.alibaba.fastjson.JSON;
import java.util.List;
public class Demo6 {
public static void main(String[] args) {
//Conversion ["one two three", "two three four", "three four five"]
List<String> strings = JSON.parseArray("[\"one two three\",\"two three four\",\"three four five\"]", String.class);
System.out.println(strings.get(1));
}
}

I hope the friends here can make your understanding of multithreading to a higher level. If this article is helpful to you, please don't be stingy with your hard-working hands , Give the blogger a compliment and pay attention. The blogger will publish other articles in the future. Thank you Thanks for watching!!!