Synchronization lock for concurrent programming
1 thread security
The problem is that when multiple threads operate on the same data, we often can't get the expected results. What's the reason for this problem? In fact, the data is not visible to multiple threads. These threads cannot operate the public data in an orderly manner. The operation of the data is not atomic, so the expected results are inconsistent. Therefore, we can summarize three embodiments of thread safety:
- Atomicity: provides mutually exclusive access. Only one thread can operate on data at a time (Synchronized, AtomicXXX, Lock).
- Visibility: when a thread modifies the main memory, it can be observed by other threads in time (Synchronized and volatile).
- Orderliness: if two threads cannot be observed from the happens before principle, their orderliness cannot be observed. The virtual machine can reorder them at will, resulting in disordered and Synchronized observations.
1.1 atomicity
In the following code, it is demonstrated that two threads call the demo.incr() method to stack the variable i. the expected result should be 20000, but the actual result is a value less than or equal to 20000.
public class Demo {
int i = 0;
public void incr(){
i++;
}
public static void main(String[] args) {
Demo demo = new Demo();
Thread[] threads=new Thread[2];
for (int j = 0;j<2;j++) {
// Create two threads
threads[j]=new Thread(() -> {
// 10000 runs per thread
for (int k=0;k<10000;k++) {
demo.incr();
}
});
threads[j].start();
}
try {
threads[0].join();
threads[1].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(demo.i);
}
}
1.1.1 causes of problems
This is the embodiment of atomicity in typical thread safety problems.
In the above code, i + + is a programming instruction in the Java high-level language, and these instructions may eventually be composed of multiple CPU instructions. i + + will eventually generate three instructions. View the bytecode instructions through javap -v xxx.class. The instructions are as follows:
public incr()V
L0
LINENUMBER 13 L0
ALOAD 0
DUP
GETFIELD com/gupaoedu/pb/Demo.i : I // Access variable i
ICONST_1 // Put the integer constant 1 on the operand stack
IADD // The constant 1 in the operand stack is taken out of the stack and added, and the added result is put into the operand stack
PUTFIELD com/gupaoedu/pb/Demo.i : I // Access the class field (class variable) and copy it to Demo.i
If these three operations want to meet atomicity, it is necessary to ensure that the thread does not allow other threads to interfere when executing this instruction.
1.1.2 graphical problem essence
A CPU core can only execute one thread at a time. If the number of threads is much larger than the number of CPU cores, thread switching will occur. This switching action can occur before any CPU instruction is executed.
For the three CPU instructions of i + +, if thread A switches to thread B after executing instruction 1, thread B also executes the instructions of the three CPUs of i + +, and the execution sequence is shown in the figure below, the result will be 1 instead of 2.
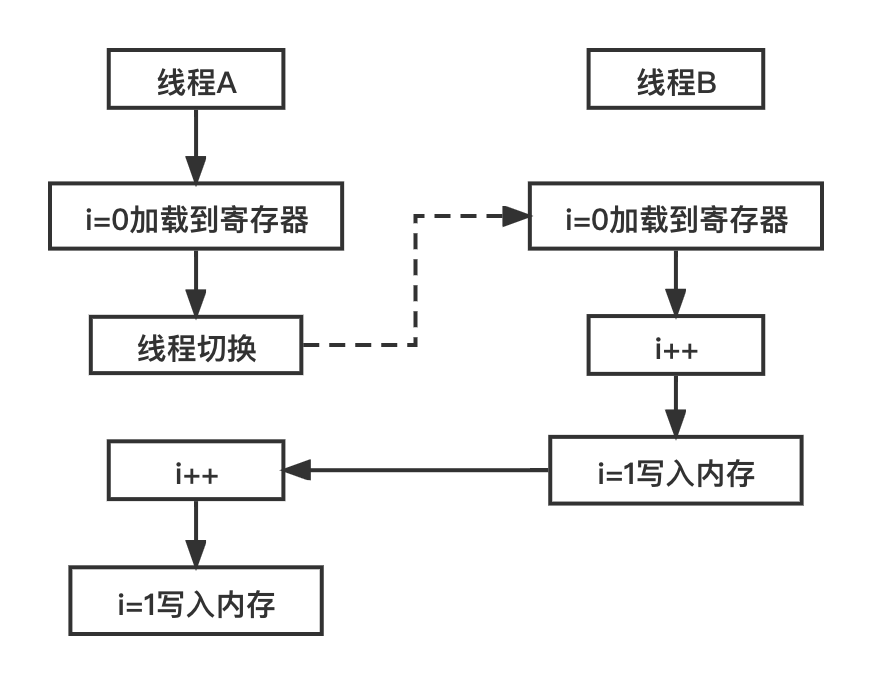
This is the atomicity problem in a multithreaded environment. How should we solve this problem?
As can be seen from the above figure, on the surface, it is the operation of multiple threads on the same variable. In fact, it is the line of i + + code, which is not atomic, which leads to such a problem in a multithreaded environment.
In other words, we only need to ensure that only one thread can access the i + + instruction at the same time. Therefore, we need to use the Synchronized lock to solve the problem.
2 basic application of synchronized
Synchronized has three locking methods. Different modification types represent the control granularity of locks:
- Modify the instance method to lock the current instance. You need to obtain the lock of the current instance before entering the synchronization code.
- Static method, which is used to lock the current class object. You need to obtain the lock of the current class object before entering the synchronization code.
- Modify the code block, specify the locked object, lock the given object, and obtain the lock of the given object before entering the synchronization code.
2.1 understanding of lock implementation model
What can Synchronized do for us? Why can we solve the atomic problem?
Before locking, when multiple threads call the incr() method, there is no limit. They can get the value of i for i+1 operation at the same time. However, when the Synchronized lock is added, thread A and thread B change from parallel execution to serial execution.
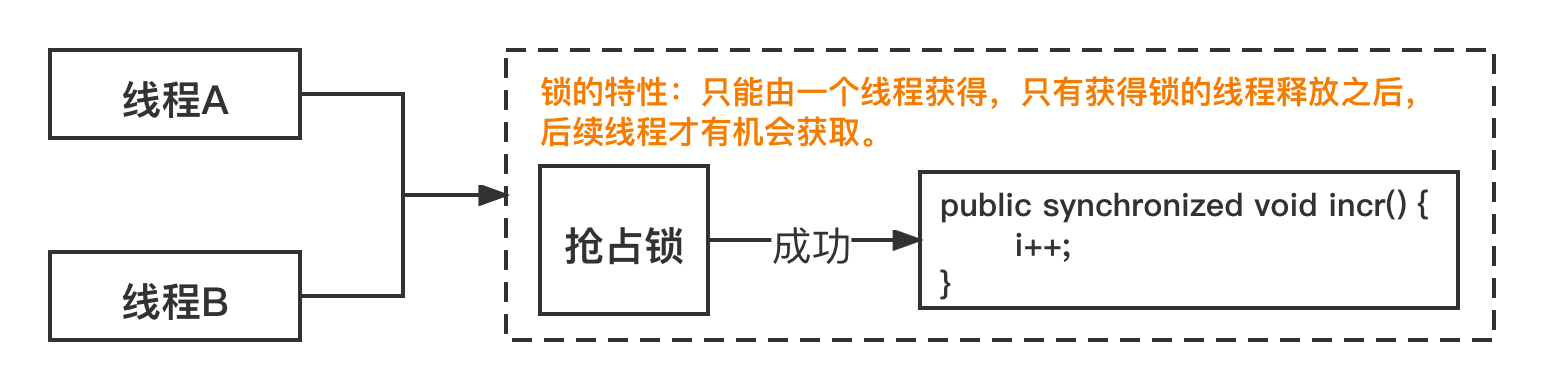
2.2 principle of synchronized
How does Synchronized implement locks? Where is the lock information stored? Take the above figure for example. Thread A grabs the lock. How does thread B know that the current lock has been preempted? There must be A tag to implement it, and the tag must be stored somewhere.
2.2.1 Markword object header
Markword is the meaning of object header, which is simply understood as the storage form of an object in JVM memory.
In the Hotspot virtual machine, the storage layout of objects in memory can be divided into three areas: object Header, Instance Data and Padding.
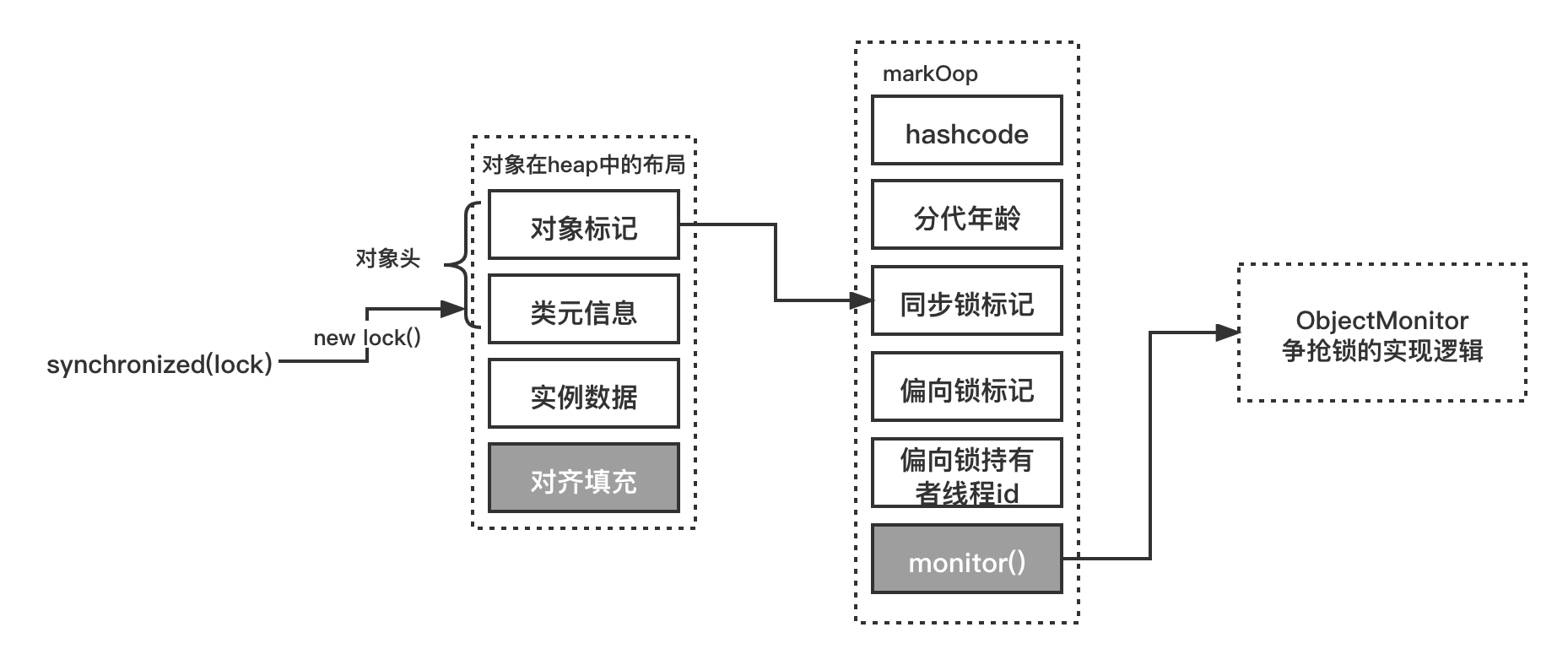
- Mark word: the object tag field occupies 4 bytes and is used to store the tag bits of some columns, such as hash value, tag bit of lightweight lock, tag bit biased to lock, generation age, etc.
- Klass Pointer: the type pointer of Class object. By default, Jdk1.8 turns on pointer compression to 4 bytes, and turns off compressed pointer (- xx:-UseCompressedOops) to 8 bytes. The location it points to is the memory address of the Class object corresponding to the object (its corresponding metadata object).
- Object actual data: including all member variables of the object. The size is determined by each member variable. For example, byte accounts for 1 byte and int accounts for 4 bytes.
- Alignment: the last space completion is not necessary, just to serve as a placeholder. Since the memory management system of the Hotspot virtual machine needs to start the object, the address must be an integer multiple of 8 bytes, so the object header is exactly a multiple of 8 bytes. Therefore, if the object instance data part is not aligned, it needs to be filled in by alignment.
2.2.2 print object headers through ClassLayout
In order to more intuitively see the storage and implementation of objects, we use JOL to view the memory layout of objects.
-
Add jol dependency
<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.9</version> </dependency> -
Write test code to print object header information without locking
public class Demo {
Object o=new Object();
public static void main(String[] args) {
Demo demo=new Demo(); //o how this object is stored and laid out in memory.
System.out.println(ClassLayout.parseInstance(demo).toPrintable());
}
}
- Output content
com.test.Demo object internals:
OFFSET SIZE TYPE DESCRIPTION
VALUE
0 4 (object header)
01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header)
00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header)
05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 java.lang.Object Demo.o
(object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
2.3 upgrading of synchronized locks
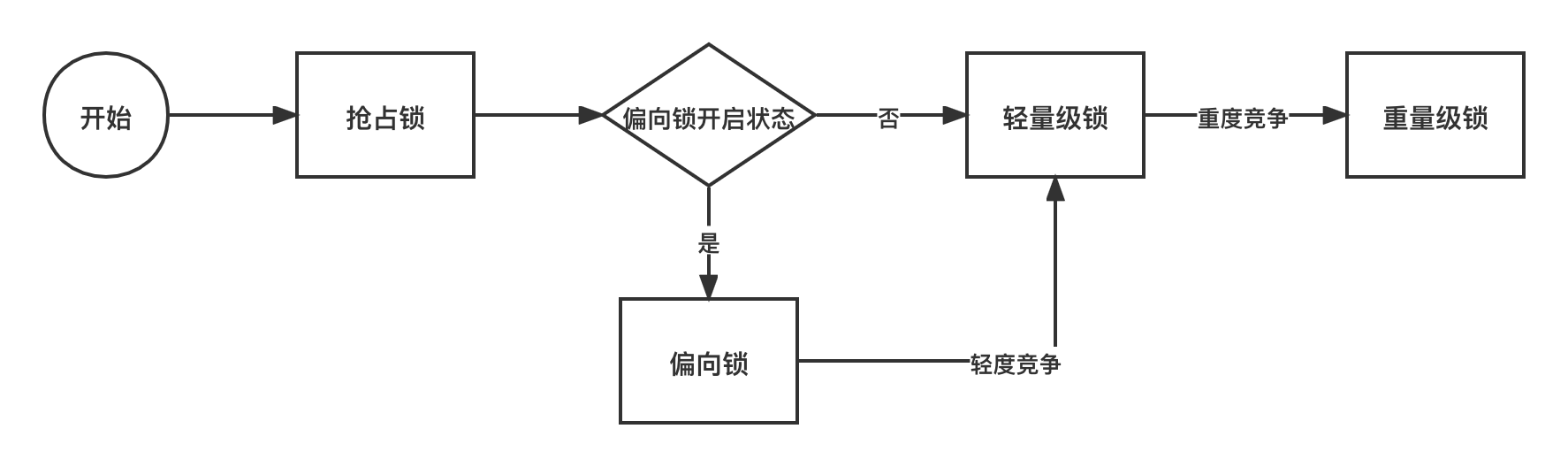
jdk1.6 introduces a lot of optimizations to the implementation of lock, such as spin lock, adaptive spin lock, lock elimination, lock coarsening, bias lock, lightweight lock and so on.
Locks mainly exist in four states: no lock state, biased lock state, lightweight lock state and heavyweight lock state. They will gradually upgrade with the fierce competition.
The purpose of this design is to solve the problem of thread concurrency in the lock free state as much as possible. The underlying implementation of bias lock and lightweight lock is based on spin lock, which is a lock free implementation compared with heavyweight lock.
-
By default, the biased lock is on, the biased thread ID is 0, and the biased thread ID is an Anonymous BiasedLock.
-
If a thread preempts the lock, the thread will preempt the biased lock first, that is, change the thread ID of markword to the thread ID of the current preempted lock.
-
If there is thread competition, the bias lock will be revoked and upgraded to a lightweight lock. The thread will create a LockRecord in its own stack frame, and set the markword to the pointer to the LR of its own thread with CAS operation. After setting successfully, it indicates that the lock has been preempted.
-
If the competition intensifies, for example, a thread spins more than 10 times (- XX:PreBlockSpin parameter setting), or the number of spin threads exceeds twice the number of CPU cores, after 1.6, the JVM will automatically control the spin time according to the last competition.
-
Upgrade to the heavyweight lock, request resources from the operating system, and then the thread is suspended and enters the waiting queue.
2.3.1 acquisition of lightweight lock
Let's use an example to show how to pay attention to the changes in the object header by printing the object layout information after locking.
public class Demo {
Object o=new Object();
public static void main(String[] args) {
Demo demo=new Demo(); //o how this object is stored and laid out in memory.
System.out.println(ClassLayout.parseInstance(demo).toPrintable());
synchronized (demo){
System.out.println(ClassLayout.parseInstance(demo).toPrintable());
}
}
}
The obtained object layout information is as follows
// Before locking, the last three bits of the first byte in the object header are [001], of which the last two bits [01] represent no lock, and the first bit [0] also represents no lock
com.test.Demo object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00
00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00
00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1
00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 java.lang.Object Demo.o
(object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
// The following part is the object layout changes after locking
// Among the first four bytes, the last three bits of the first byte are [000], the last two bits 00 represent a lightweight lock, and the first bit is [0], indicating that it is not biased to the lock state at present.
com.gupaoedu.pb.Demo object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) d8 f0
d5 02 (11011[000] 11110000 11010101 00000010) (47575256)
4 4 (object header) 00 00
00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1
00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 java.lang.Object Demo.o
(object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
Process finished with exit code 0
There will be doubts here. Doesn't it mean that the upgrade of locks is based on thread competition, from biased locks to lightweight locks and then to heavyweight locks? Why is there no thread competition here, and his lock tag is a lightweight lock? The answer needs to be found in the acquisition and principle of bias lock.
2.3.2 acquisition of deflection lock
By default, there is a delay in opening the bias lock. The default is 4s. Why do you design this?
Because the JVM virtual machine has some threads started by default, and there are many Synchronized codes in these threads. These Synchronized codes will trigger competition when starting. If biased locks are used, it will cause biased locks to continuously upgrade and revoke locks, which is inefficient.
The delay can be set to 0 through the JVM parameter - XX:BiasedLockingStartupDelay=0.
Run the code again
public class Demo {
Object o=new Object();
public static void main(String[] args) {
Demo demo=new Demo(); //o how this object is stored and laid out in memory.
System.out.println(ClassLayout.parseInstance(demo).toPrintable());
synchronized (demo){
System.out.println(ClassLayout.parseInstance(demo).toPrintable());
}
}
}
The following object layout is obtained. It can be seen that the last three digits of the first byte in the high order of the object header are [101], indicating that it is currently in a biased lock state.
com.test.Demo object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00
00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00
00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1
00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 java.lang.Object Demo.o
(object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
com.gupaoedu.pb.Demo object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 30
4a 03 (00000101 00110000 01001010 00000011) (55193605)
4 4 (object header) 00 00
00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1
00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 java.lang.Object Demo.o
(object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
The lock status of the first object and the second object here is 101, because when the bias lock is open, anonymous objects will be configured to obtain the bias lock by default.
2.3.3 heavyweight lock acquisition
In the case of fierce competition, when the thread has been unable to obtain the lock, it will be upgraded to heavyweight lock.
The following example simulates the competition scenario through two threads.
public static void main(String[] args) {
Demo testDemo = new Demo();
Thread t1 = new Thread(() -> {
synchronized (testDemo){
System.out.println("t1 lock ing");
System.out.println(ClassLayout.parseInstance(testDemo).toPrintable());
}
});
t1.start();
synchronized (testDemo){
System.out.println("main lock ing");
System.out.println(ClassLayout.parseInstance(testDemo).toPrintable());
}
}
It can be seen from the results that in the case of competition, the mark of the lock is [010], where the mark [10] represents a heavyweight lock.
com.test.Demo object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 8a 20 5e 26
(10001010 00100000 01011110 00100110) (643702922)
4 4 (object header) 00 00 00 00
(00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 f8
(00000101 11000001 00000000 11111000) (-134168315)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
t1 lock ing
com.gupaoedu.pb.Demo object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 8a 20 5e 26
(10001010 00100000 01011110 00100110) (643702922)
4 4 (object header) 00 00 00 00
(00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 f8
(00000101 11000001 00000000 11111000) (-134168315)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
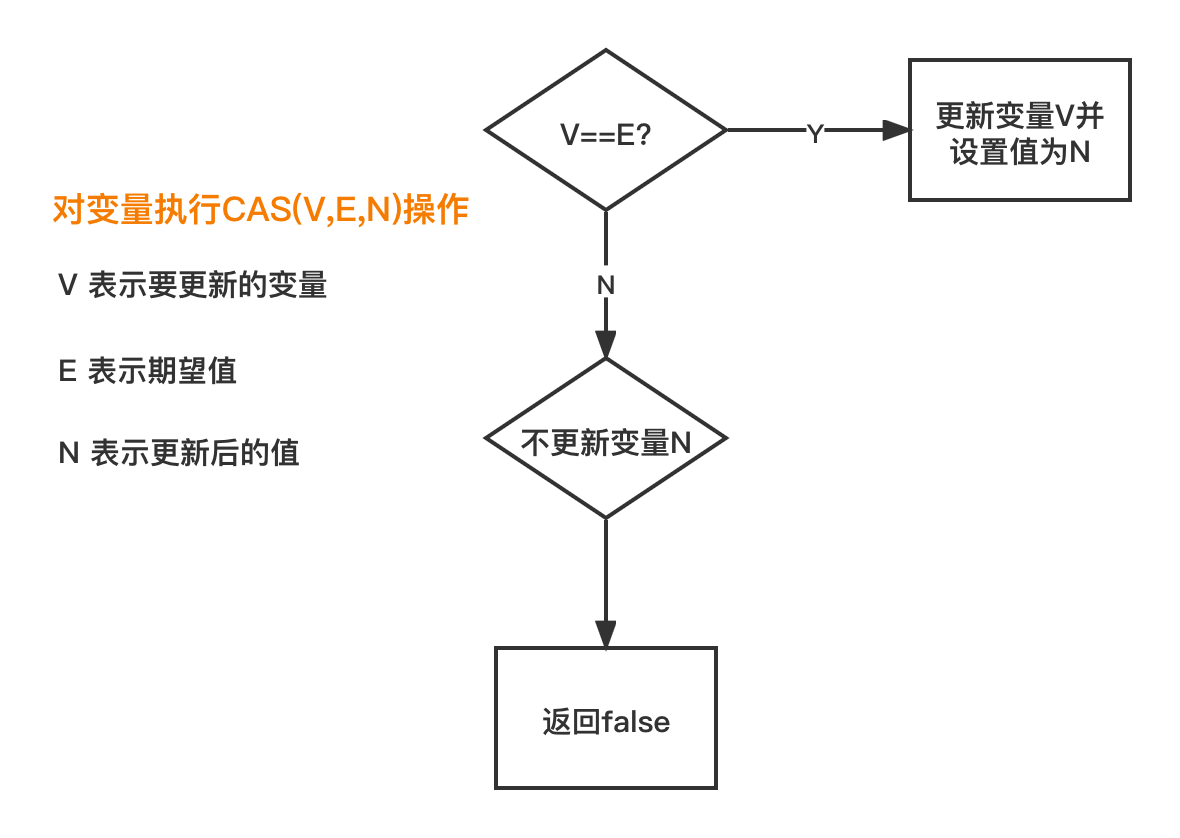
3 CAS
CAS is often used at the bottom of Synchronized. There are two types of CAS in the whole process:
- Compare and swap
- Compare and exchange
It can ensure the atomicity of modifying a variable in a multithreaded environment.
CAS principle is very simple, including three values: current memory value (V), expected original value (E) and expected updated value (N).