MySQL advanced - Notes - 01
Video of this article: Dark horse MySQL advanced
1, MySQL architecture
1-1 overview of MySQL architecture
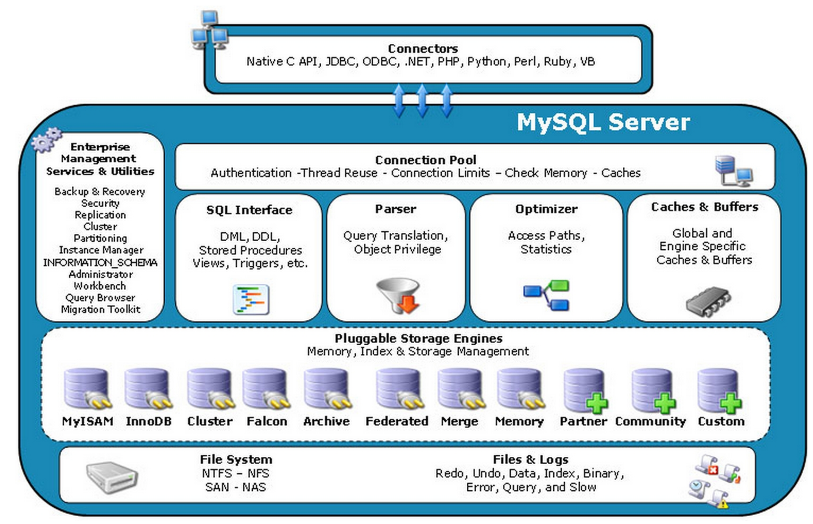
The entire MySQL Server consists of the following components:
- Connection Pool: Connection Pool component
- Management services & Utilities: management services and tools components
- SQL interface: SQL interface component
- Parser: query analyzer component
- Optimizer: optimizer component
- Caches & buffers: buffer pool component
- Pluggable Storage Engines:
- File System: File System
Compared with other databases, MySQL is a little different. Its architecture can be applied in many different scenarios and play a good role. It is mainly reflected in the storage engine. The plug-in storage engine architecture separates query processing from other system tasks and data storage and extraction. This architecture can select the appropriate storage engine according to the business needs and actual needs.
1-2 connection layer
The top layer is some client and link services, including local sock communication and TCP/IP communication based on most client / server tools. It mainly completes some security schemes similar to connection processing, authorization and authentication, and related security schemes. On this layer, the concept of thread pool is introduced to provide threads for clients who access safely through authentication. SSL based secure links can also be implemented on this layer. The server will also verify its operation permissions for each client with secure access.
1-3 service layer
The second layer architecture mainly completes most core service functions, such as SQL interface, cache query, SQL analysis and optimization, and the execution of some built-in functions. All functions across storage engines are also implemented in this layer, such as procedures, functions, etc. In this layer, the server will parse the query, create the corresponding internal parse tree, and optimize it, such as determining the query order of the table, whether to use the index, and finally generate the corresponding execution operations. If it is a select statement, the server will also query the internal cache. If the cache space is large enough, it can improve the performance of the system in the environment of solving a large number of read operations.
1-4 engine layer
In the storage engine layer, the storage engine is really responsible for the storage and extraction of data in MySQL, and the server communicates with the storage engine through API. Different storage engines have different functions, so we can select the appropriate storage engine according to our own needs.
1-5 storage tiers
The data storage layer mainly stores the data on the file system and completes the interaction with the storage engine.
2, Storage engine
2-1 storage engine overview
Storage engine is the implementation of technologies such as storing data, establishing index, updating query data and so on. The storage engine is table based, not library based. Therefore, the storage engine can also be called a table type.
The storage engines supported by MySQL 5.0 include InnoDB, MyISAM, BDB, MEMORY, MERGE, EXAMPLE, NDB Cluster, ARCHIVE, CSV, BLACKHOLE, FEDERATED, etc. InnoDB and BDB provide transaction security tables, while other storage engines are non transaction security tables.
Query the storage engines supported by the current database. The instructions are as follows:
show engines;
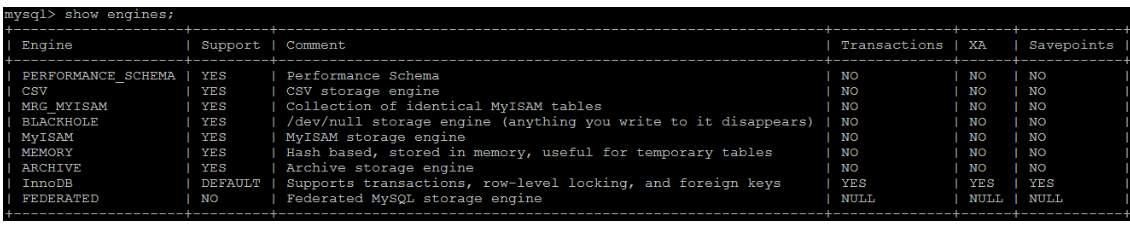
If no storage engine is specified when creating a new table, the system will use the default storage engine. The default storage engine before MySQL 5.5 is MyISAM, and it will be changed to InnoDB after 5.5.
View the default storage engine of Mysql database. The instructions are as follows:
show variables like '%storage_engine%' ;

2-2 MylSAM and InnoDB
(1)InnoDB
InnoDB storage engine is the default storage engine for Mysql. InnoDB storage engine provides transaction security with the capabilities of commit, rollback and crash recovery. However, compared with MyISAM's storage engine, InnoDB's write processing efficiency is lower, and it will occupy more disk space to retain data and indexes
Characteristics of InnoDB storage engine different from other storage engines:
-
Transaction control: InnoDB supports transactions
-
Foreign key constraint: only InnoDB is the storage engine that MySQL supports foreign keys. When creating a foreign key, the parent table must have a corresponding index, and the child table will automatically create a corresponding index when creating a foreign key
(2)MylSAM
MyISAM does not support transactions or foreign keys. Its advantage is that it has fast access speed and has no requirements for transaction integrity. Or applications based on SELECT and INSERT can basically use this engine to create tables.
Comparison between the two:
| Comparison item | MylSAM | InnoDB |
|---|---|---|
| Main foreign key | I won't support it | support |
| affair | I won't support it | support |
| Row table lock | Table lock (not suitable for high concurrency) | Row lock (suitable for high concurrency operation) |
| cache | Only cache indexes, not real data | Cache not only indexes, but also real data. High memory requirements |
| Tablespace | Small | large |
| Focus | performance | affair |
| Default installation | yes | yes |
2-3 selection of storage engine
When selecting the storage engine, the appropriate storage engine should be selected according to the characteristics of the application system. For complex application systems, you can also select a variety of storage engines to combine according to the actual situation. The following are the usage environments of several common storage engines.
- InnoDB: it is the default storage engine of Mysql. It is used for transaction processing applications and supports foreign keys. If the application has high requirements for transaction integrity and data consistency under concurrent conditions, and data operations include many update and delete operations in addition to insertion and query, InnoDB storage engine is a more appropriate choice. In addition to effectively reducing the locking caused by deletion and update, the InnoDB storage engine can also ensure the complete submission and rollback of transactions. For systems with high data accuracy requirements such as billing system or financial system, InnoDB is the most appropriate choice.
- MyISAM: if the application is mainly read and insert operations, there are few update and delete operations, and the requirements for transaction integrity and concurrency are not very high, it is very appropriate to choose this storage engine.
3, Index
3-1 what is an index
- MySQL's official definition of index is: index is a data structure (orderly) that helps MySQL efficiently obtain data.
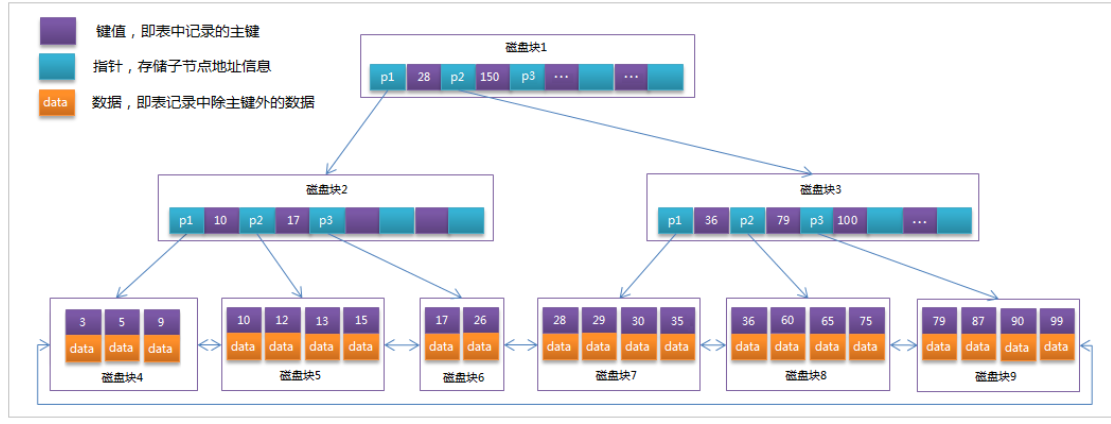
- In addition to the data, the database system also maintains the data structure that meets the specific search algorithm. These data structures refer to (point to) the data in some way, so that the advanced search algorithm can be implemented on these data structures. This data structure is the index. As shown in the following diagram:
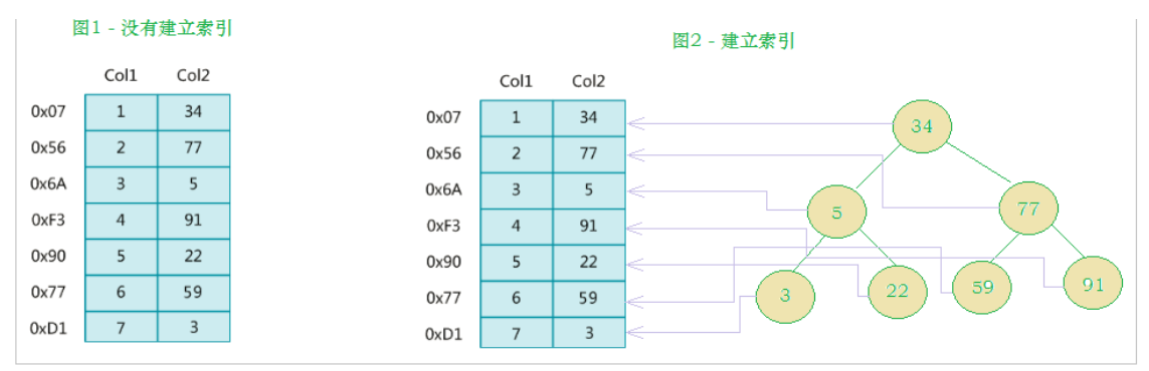
- On the left is the data table, with two columns and seven records. On the left is the physical address of the data record (note that logically adjacent records are not necessarily physically adjacent on the disk). In order to speed up the search of Col2, a binary search tree shown on the right can be maintained. Each node contains an index key value and a pointer to the physical address of the corresponding data record, so that the binary search can be used to quickly obtain the corresponding data.
- Generally speaking, the index itself is too large to be stored in memory, so the index is often stored on disk in the form of index file. Index is the most commonly used tool in database to improve performance.
3-2 index strengths and weaknesses
Advantages:
- Improve the efficiency of data retrieval and reduce the IO cost of database.
- Sort the data through the index column to reduce the cost of data sorting and CPU consumption.
inferiority:
- In fact, the index is also a table, which saves the primary key and index fields and points to the records of entity classes, so the index column also takes up space.
- Although the index greatly improves the query efficiency, it also reduces the speed of updating the table, such as INSERT, UPDATE and DELETE. When updating a table, MySQL should not only save the data, but also save the index file. Every time the field with index column is updated, the index information after the key value changes caused by the UPDATE will be adjusted.
3-3 index structure
Indexing is implemented in the storage engine layer of MySQL, not in the server layer. Therefore, the indexes of each storage engine are not necessarily the same, and not all storage engines support all index types. MySQL currently provides the following four indexes:
- BTREE index: the most common index type. Most indexes support B-tree index.
- HASH index: it is only supported by the Memory engine, and the usage scenario is simple.
- R-tree index (spatial index): spatial index is a special index type of MyISAM engine. It is mainly used for geospatial data types. It is usually less used and will not be introduced in particular.
- Full text index: full text index is also a special index type of MyISAM, which is mainly used for Full-text index. InnoDB supports Full-text index since Mysql5.6.
InnoDB, MyISAM and Memory support various index types:
| Indexes | InnoDB engine | MyISAM engine | Memory engine |
|---|---|---|---|
| BTREE index | support | support | support |
| HASH index | I won't support it | I won't support it | support |
| R-tree index | I won't support it | support | I won't support it |
| Full-text | Supported after version 5.6 | support | I won't support it |
The index we usually refer to, if not specified, refers to the index organized by B+tree (multi-channel search tree, not necessarily binary) structure. The clustered index, composite index, prefix index and unique index are all B+tree indexes by default, which are collectively referred to as indexes.
(1) BTREE structure
BTree is also called multi-channel balanced search tree. The BTree characteristics of an m-fork are as follows:
- Each node in the tree contains up to m children.
- Except for the root node and leaf node, each node has at least [ceil(m/2)] (ceil rounded up) children.
- If the root node is not a leaf node, there are at least two children.
- All leaf nodes are on the same layer.
- Each non leaf node consists of N key s and n+1 pointers, where [ceil (M / 2) - 1] < = n < = M-1
Here we take 5-fork BTree as an example, the number of key s: formula derivation [ceil (M / 2) - 1] < = n < = M-1. SO 2 < = n < = 4. When n > 4, the intermediate node splits to the parent node and the two nodes split.
Insert C N G A H E K Q M F W L T Z D P R X Y S data as an example.
Specific process:
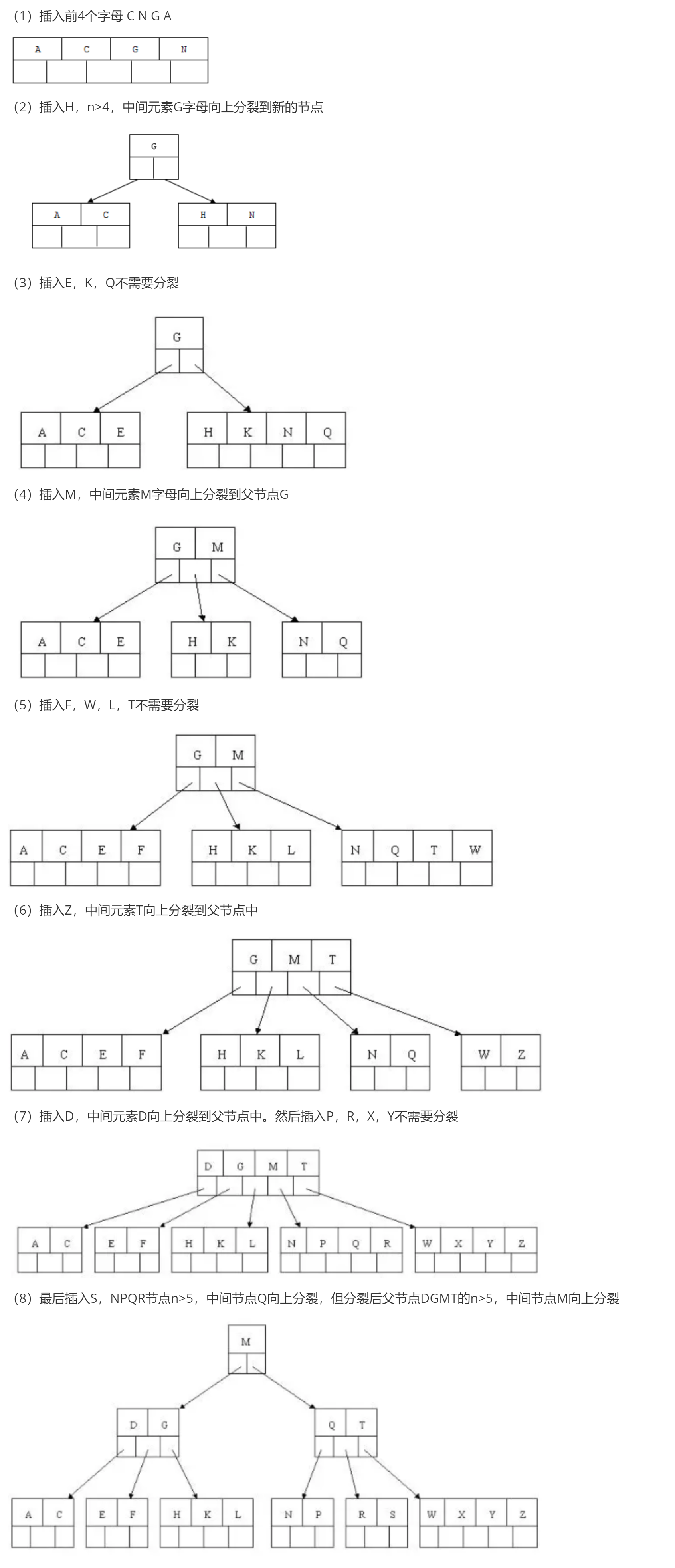
At this point, the BTREE tree has been built. Compared with the binary tree, the BTREE tree is more efficient in querying data, because for the same amount of data, the hierarchical structure of BTREE is smaller than the binary tree, so the search speed is fast.
(2) B+TREE structure
B+Tree is a variant of BTree. The difference between B+Tree and BTree is:
- N-fork B+Tree contains at most N keys, while BTree contains at most n-1 keys.
- The leaf node of B+Tree stores all key information, which is arranged in order of key size.
- All non leaf nodes can be regarded as the index part of the key.
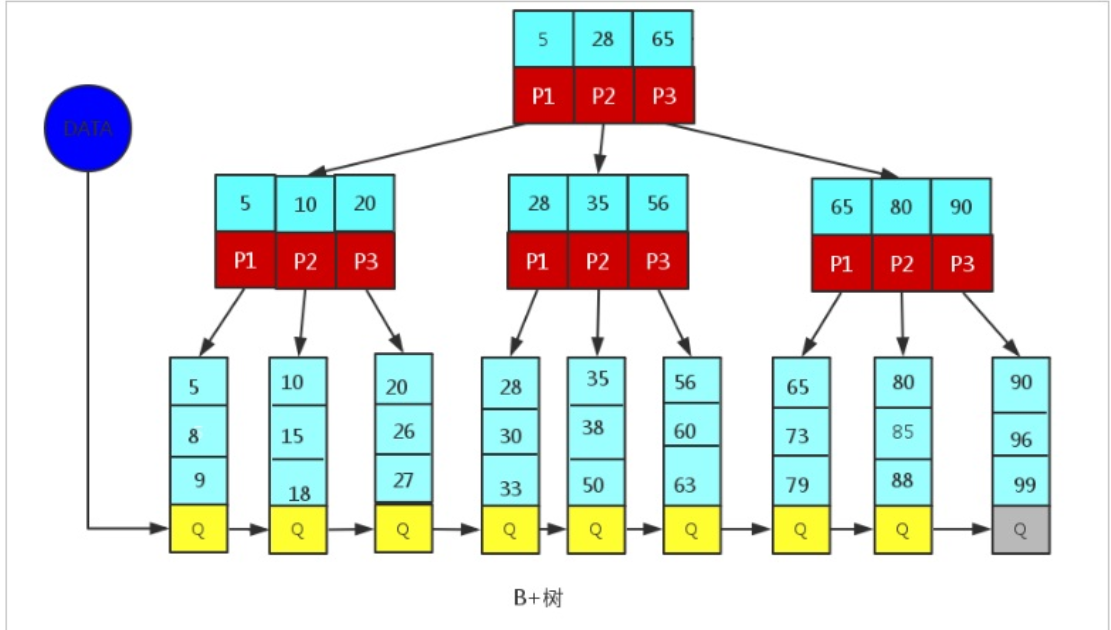
Since only the leaf node of B+Tree stores key information, any key query must go from root to leaf. Therefore, the query efficiency of B+Tree is more stable.
(3) B+Tree in MySQL
MySql index data structure optimizes the classic B+Tree. On the basis of the original B+Tree, a linked list pointer to adjacent leaf nodes is added, that is, the pointers between leaf nodes are bidirectional, forming a B+Tree with sequential pointers to improve the performance of interval access.
Schematic diagram of B+Tree index structure in MySQL:
3-4 index classification
- Single value index: that is, an index contains only a single column, and a table can have multiple single column indexes
- Unique index: the value of the index column must be unique, but null values are allowed
- Composite index: that is, an index contains multiple columns
3-5 index syntax
Indexes can be created at the same time when creating tables, or new indexes can be added at any time.
Here we prepare cases for practical operation:
Prepare database tables and insert data:
create database demo_01 default charset=utf8mb4; use demo_01; CREATE TABLE `city` ( `city_id` int(11) NOT NULL AUTO_INCREMENT, `city_name` varchar(50) NOT NULL, `country_id` int(11) NOT NULL, PRIMARY KEY (`city_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `country` ( `country_id` int(11) NOT NULL AUTO_INCREMENT, `country_name` varchar(100) NOT NULL, PRIMARY KEY (`country_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'Xi'an',1); insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2); insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'Beijing',1); insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'Shanghai',1); insert into `country` (`country_id`, `country_name`) values(1,'China'); insert into `country` (`country_id`, `country_name`) values(2,'America'); insert into `country` (`country_id`, `country_name`) values(3,'Japan'); insert into `country` (`country_id`, `country_name`) values(4,'UK');
(1) Create index
Syntax:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name(index_col_name,...) index_col_name : column_name[(length)][ASC | DESC]
Example: City in the city table_ Create index for name field
CREATE INDEX idx_city_name ON city(city_name);
(2) View index
Syntax:
show index from table_name;
Example: viewing index information in the city table
SHOW INDEX FROM city;
(3) Delete index
Syntax:
DROP INDEX index_name ON tbl_name;
Example: you want to delete the index idx on the city table_ city_ Name, you can operate as follows
DROP INDEX idx_city_name ON city;
(4) ALTER command
1). alter table tb_name add primary key(column_list); #This statement adds a primary key, which means that the index value must be unique and cannot be NULL 2). alter table tb_name add unique index_name(column_list); #The value of the index created by this statement must be unique (NULL may occur multiple times except NULL) 3). alter table tb_name add index index_name(column_list); #Add a normal index, and the index value can appear multiple times. 4). alter table tb_name add fulltext index_name(column_list); #This statement specifies that the index is FULLTEXT, which is used for full-text indexing
3-6 index design principles
The design of the index can follow some existing principles. Please try to comply with these principles when creating the index, so as to improve the efficiency of the index and use the index more efficiently.
-
Index tables with high query frequency and large amount of data.
-
For the selection of index fields, the best candidate columns should be extracted from the conditions of the where clause. If there are many combinations in the where clause, the combination of the most commonly used columns with the best filtering effect should be selected.
-
Using a unique index, the higher the discrimination, the higher the efficiency of using the index.
-
Index can effectively improve the efficiency of query data, but the number of indexes is not the more the better. The more indexes, the higher the cost of maintaining the index. For tables with frequent DML operations such as insert, update and delete, too many indexes will introduce a high maintenance cost, reduce the efficiency of DML operations and increase the time consumption of corresponding operations. In addition, if there are too many indexes, MySQL will also suffer from selection difficulties. Although an available index will still be found in the end, it undoubtedly increases the cost of selection.
-
Using a short index, the index is also stored on a hard disk after it is created. Therefore, improving the I/O efficiency of index access can also improve the overall access efficiency. If the total length of the fields constituting the index is relatively short, more index values can be stored in the storage block of a given size, which can effectively improve the I/O efficiency of MySQL accessing the index.
-
Using the leftmost prefix and a combined index composed of N columns is equivalent to creating n indexes. If the first few fields constituting the index are used in the where clause during the query, the SQL query can use the combined index to improve the query efficiency.
Create composite index: CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS); It's equivalent to yes name Create index ; yes name , email Index created ; yes name , email, status Index created ;
4, Optimize SQL steps
4-1 viewing SQL execution frequency
After the MySQL client is successfully connected, the server status information can be provided through the show [session|global] status command. Show [session|global] status you can add the parameter "session" or "global" as needed to display the session level (current connection) and global level (since the last startup of the database). If you do not write, the default parameter is "session".
The following command displays the values of all statistical parameters in the current session:
show status like 'Com_______';
show status like 'Innodb_rows_%';
Com_xxx indicates the number of times each xxx statement is executed. We usually care about the following statistical parameters.
| number | meaning |
|---|---|
| Com_select | The number of times the select operation is performed. A query only accumulates 1. |
| Com_insert | The number of times the INSERT operation is executed. For the INSERT operation of batch insertion, it is only accumulated once. |
| Com_update | The number of times the UPDATE operation was performed. |
| Com_delete | The number of times the DELETE operation was performed. |
| Innodb_rows_read | select the number of rows returned by the query. |
| Innodb_rows_inserted | The number of rows inserted by the INSERT operation. |
| Innodb_rows_updated | The number of rows updated by the UPDATE operation. |
| Innodb_rows_deleted | The number of rows deleted by the DELETE operation. |
| Connections | The number of attempts to connect to the MySQL server. |
| Uptime | Server working hours. |
| Slow_queries | Number of slow queries. |
Com_*** : These parameters are accumulated for table operations of all storage engines.
Innodb_*** : These parameters are only for the InnoDB storage engine, and the accumulation algorithm is slightly different.
4-2 positioning inefficient SQL execution
You can locate SQL statements with low execution efficiency in the following two ways.
-
Slow query log: locate the SQL statements with low execution efficiency through the slow query log. When started with the – log slow queries [= file_name] option, mysqld writes a long containing all the execution time_ query_ Log file of SQL statement with time seconds.
-
Show processlist: the slow query log is recorded only after the query is completed. Therefore, querying the slow query log can not locate the problem when the application reflects that there is a problem with the execution efficiency. You can use the show processlist command to view the current MySQL thread, including the thread status and whether to lock the table. You can view the SQL execution in real time, At the same time, some table locking operations are optimized.

1) id Column, user login mysql System assigned"connection_id",Functions can be used connection_id()see 2) user Column to display the current user. If not root,This command only displays the user's permission range sql sentence 3) host Column, showing from which ip Which port of the can be used to track the user of the problem statement 4) db Column, showing which database this process is currently connected to 5) command Column, which displays the commands executed by the current connection. Generally, the value is sleep( sleep),Inquiry( query),Connect( connect)etc. 6) time Column to display the duration of this state, in seconds 7) state Column that displays the current connection sql Statement, a very important column. state Describes a state in the execution of a statement sql Statement, taking a query as an example, may need to go through copying to tmp table,sorting result,sending data Wait for the status to complete 8) info Column, show this sql Statement is an important basis for judging problem statements
4-3 explain analysis execution plan
Execution plan of query SQL statement:
explain select * from tb_item where id = 1;

Meaning of each field:
| field | meaning |
|---|---|
| id | The sequence number of a select query is a group of numbers, which indicates the order in which the select clause or operation table is executed in the query. |
| select_type | Indicates the type of SELECT. Common values include SIMPLE (SIMPLE table, i.e. no table connection or sub query), PRIMARY (PRIMARY query, i.e. outer query), UNION (the second or subsequent query statement in UNION), SUBQUERY (the first SELECT in sub query), etc |
| table | Table of output result set |
| type | Indicates the connection type of the table. The connection type with good performance to poor performance is (system - > const ------ > eq_ref ------ -- > ref ------ > ref_or_null ------ > index_merge - > index_subquery ------ > range ------ > index ------ -- > all) |
| possible_keys | Represents the index that may be used when querying |
| key | Represents the index actually used |
| key_len | Length of index field |
| rows | Number of scan lines |
| extra | Description and description of implementation |
(1) Environmental preparation
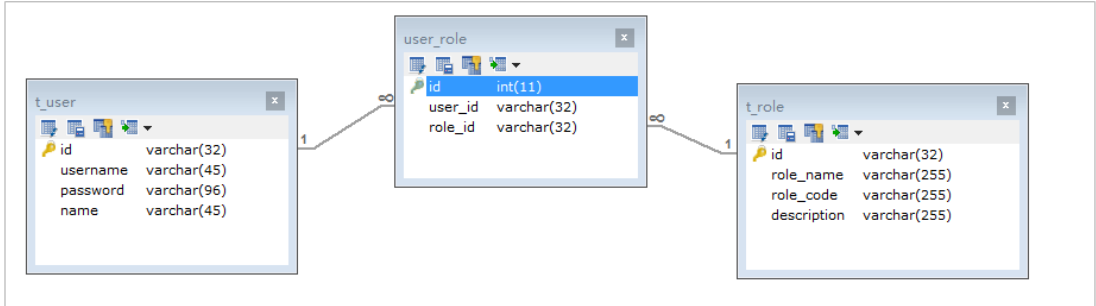
CREATE TABLE `t_role` (
`id` varchar(32) NOT NULL,
`role_name` varchar(255) DEFAULT NULL,
`role_code` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_role_name` (`role_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_user` (
`id` varchar(32) NOT NULL,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_user_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_role` (
`id` int(11) NOT NULL auto_increment ,
`user_id` varchar(32) DEFAULT NULL,
`role_id` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_ur_user_id` (`user_id`),
KEY `fk_ur_role_id` (`role_id`),
CONSTRAINT `fk_ur_role_id` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `fk_ur_user_id` FOREIGN KEY (`user_id`) REFERENCES `t_user` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `t_user` (`id`, `username`, `password`, `name`) values('1','super','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','Super administrator');
insert into `t_user` (`id`, `username`, `password`, `name`) values('2','admin','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','system administrator');
insert into `t_user` (`id`, `username`, `password`, `name`) values('3','itcast','$2a$10$8qmaHgUFUAmPR5pOuWhYWOr291WJYjHelUlYn07k5ELF8ZCrW0Cui','test02');
insert into `t_user` (`id`, `username`, `password`, `name`) values('4','stu1','$2a$10$pLtt2KDAFpwTWLjNsmTEi.oU1yOZyIn9XkziK/y/spH5rftCpUMZa','Student 1');
insert into `t_user` (`id`, `username`, `password`, `name`) values('5','stu2','$2a$10$nxPKkYSez7uz2YQYUnwhR.z57km3yqKn3Hr/p1FR6ZKgc18u.Tvqm','Student 2');
insert into `t_user` (`id`, `username`, `password`, `name`) values('6','t1','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','Teacher 1');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('5','student','student','student');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('7','teacher','teacher','teacher');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('8','Teaching administrator','teachmanager','Teaching administrator');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('9','administrators','admin','administrators');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('10','Super administrator','super','Super administrator');
INSERT INTO user_role(id,user_id,role_id) VALUES(NULL, '1', '5'),(NULL, '1', '7'),(NULL, '2', '8'),(NULL, '3', '9'),(NULL, '4', '8'),(NULL, '5', '10') ;
(2) explain id
The id field is the serial number of the select query and a group of numbers, indicating the order in which the select clause or the operation table is executed in the query. There are three types of id:
-
The same id indicates that the order of loading the table is from top to bottom:
explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and u.id = ur.user_id ;

-
Different IDs. The larger the id value, the higher the priority, and the earlier it is executed:
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'))

-
IDs are the same and different, and exist at the same time. Those with the same id can be considered as a group, which is executed from top to bottom. In all groups, the higher the id value, the higher the priority, and the earlier:
EXPLAIN SELECT * FROM t_role r , (SELECT * FROM user_role ur WHERE ur.`user_id` = '2') a WHERE r.id = a.role_id ;

(4) select_type of explain
select_type represents the type of query. It is mainly used to distinguish complex queries such as ordinary queries, joint queries and sub queries
| select_type | meaning |
|---|---|
| SIMPLE | A simple select query that does not contain subqueries or unions |
| PRIMARY | If any complex subquery is included in the query, the outermost query is marked with this ID |
| SUBQUERY | Subqueries are included in the SELECT or WHERE list |
| DERIVED | The sub queries contained in the FROM list are marked as DERIVED. MYSQL will recursively execute these sub queries and put the results in the temporary table |
| UNION | If the second SELECT appears after the UNION, it will be marked as UNION; if the UNION is included in the subquery of the FROM clause, the outer SELECT will be marked as: DERIVED |
| UNION RESULT | Get the SELECT of the result from the UNION table |
(5) explain table
Show which table the data in this row is about
(6) explain type
Type displays the access type, which is an important indicator. The values are:
| type | meaning |
|---|---|
| NULL | MySQL does not access any tables or indexes and returns results directly |
| system | The table has only one row of records (equal to the system table), which is a special case of const type and generally does not appear |
| const | It means that it can be found once through the index. const is used to compare the primary key or unique index. Because only one row of data is matched, it is very fast. If the primary key is placed in the where list, MySQL can convert the query into a constant light. const is used to compare all parts of a primary key or unique index with a constant value |
| eq_ref | Similar to ref, the difference is that the unique index is used. For the association query using the primary key, there is only one record found in the association query. Common in primary key or unique index scanning |
| ref | Non unique index scan that returns all rows that match a single value. In essence, it is also an index access that returns all rows (multiple) that match a single value |
| range | Retrieve only the rows returned for a given, using an index to select rows. After where, operations such as between, <, >, in appear. |
| index | The difference between index and ALL is that index only traverses the index tree, which is usually faster than ALL. ALL traverses the data file. |
| all | The entire table will be traversed to find matching rows |
The result value efficiency from best to worst is:
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL system > const > eq_ref > ref > range > index > ALL
Generally speaking, we need to ensure that the query reaches at least range level, preferably ref.
(7) explain key
- possible_keys: displays one or more indexes that may be applied to this table.
- key: the index actually used. If it is NULL, no index is used.
- key_len: indicates the number of bytes used in the index. This value is the maximum possible length of the index field, not the actual length. The shorter the length, the better without losing accuracy.
(8) explain rows
Number of scan lines
(9) explain extra
Other additional execution plan information is displayed in this column:
| extra | meaning |
|---|---|
| using filesort | This shows that mysql uses an external index to sort the data instead of reading according to the index order in the table. It is called "file sorting", which is inefficient. |
| using temporary | Temporary tables are used to save intermediate results. MySQL uses temporary tables when sorting query results. Common in order by and group by; Low efficiency |
| using index | It indicates that the corresponding select operation uses the overlay index to avoid accessing the data rows of the table, which is efficient. |
5, SQL optimization
5-1 index optimization
Preparation environment:
create table `tb_seller` (
`sellerid` varchar (100),
`name` varchar (100),
`nickname` varchar (50),
`password` varchar (60),
`status` varchar (1),
`address` varchar (100),
`createtime` datetime,
primary key(`sellerid`)
)engine=innodb default charset=utf8mb4;
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('alibaba','Alibaba','Ali store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('baidu','Baidu Technology Co., Ltd','Baidu store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('huawei','Huawei Technology Co., Ltd','Huawei store','e10adc3949ba59abbe56e057f20f883e','0','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itcast','Chuanzhi podcast Education Technology Co., Ltd','Intelligence Podcast','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('itheima','Dark horse programmer','Dark horse programmer','e10adc3949ba59abbe56e057f20f883e','0','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('luoji','Logitech Technology Co., Ltd','Logitech store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('oppo','OPPO Technology Co., Ltd','OPPO Official flagship store','e10adc3949ba59abbe56e057f20f883e','0','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('ourpalm','Zhangqu Technology Co., Ltd','Palm fun store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('qiandu','QIANDU Technology','QianDu store','e10adc3949ba59abbe56e057f20f883e','2','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('sina','Sina Technology Co., Ltd','Sina official flagship store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('xiaomi','Xiaomi Tech ','Millet official flagship store','e10adc3949ba59abbe56e057f20f883e','1','Xi'an City','2088-01-01 12:00:00');
insert into `tb_seller` (`sellerid`, `name`, `nickname`, `password`, `status`, `address`, `createtime`) values('yijia','IKEA home','IKEA flagship store','e10adc3949ba59abbe56e057f20f883e','1','Beijing','2088-01-01 12:00:00');
create index idx_seller_name_sta_addr on tb_seller(name,status,address);
Avoid index invalidation:
-
Full value matching, specifying specific values for all columns in the index
In this case, the index becomes effective and the execution efficiency is high:
explain select * from tb_seller where name='Xiaomi Tech ' and status='1' and address='Beijing';
-
Leftmost prefix rule: if multiple columns are indexed, follow the leftmost prefix rule. This means that the query starts at the top left of the index and does not skip the columns in the index:
- Match the leftmost prefix rule and take the index
- Illegal leftmost prefix rule, index invalid
- If the leftmost rule is met, but a column jumps, only the leftmost column index takes effect
-
The column on the right of range query cannot use index
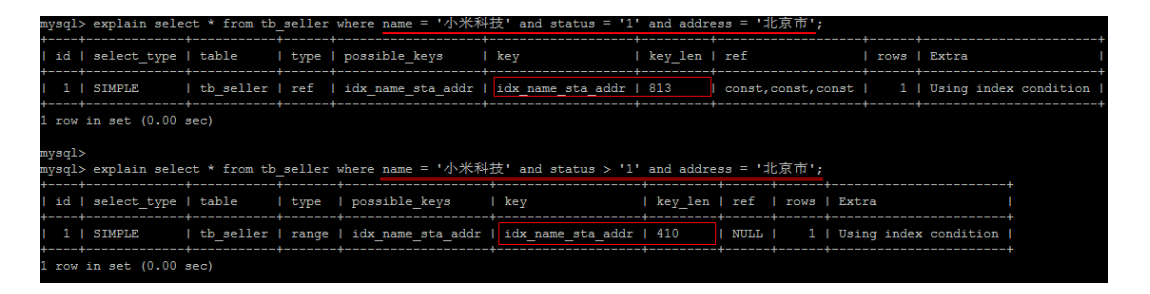
According to the first two fields name and status, the query is indexed, but the last condition address does not use the index
-
Do not operate on the index column, otherwise the index will become invalid
-
The string does not contain single quotation marks, resulting in index invalidation
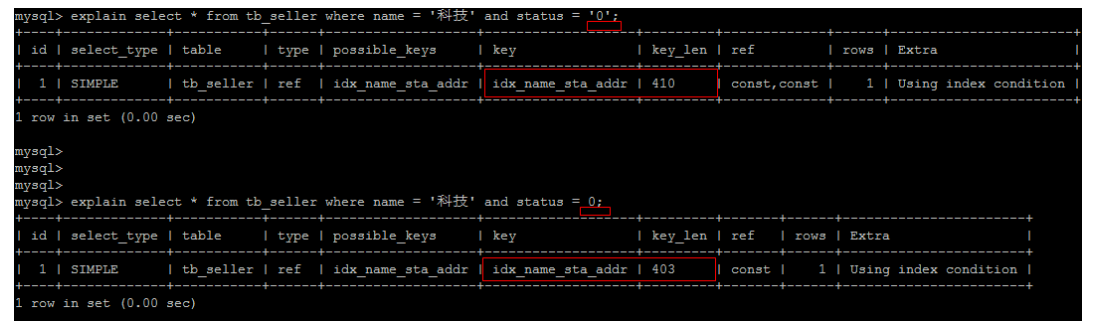
Since no single quotation mark is added to the string during query, the MySQL query optimizer will automatically perform type conversion, resulting in index invalidation
-
Try to use overlay indexes (queries that only access indexes (index columns completely contain query columns)) and reduce select *. If the query column exceeds the index column, performance will also be reduced
-
For the condition separated by or, if the column in the condition before or has an index and the column after or has no index, the indexes involved will not be used
For example, the name field is an index column, while createtime is not an index column. or is connected in the middle, and the index is not used:
explain select * from tb_seller where name='Dark horse programmer' or createtime = '2088-01-01 12:00:00';
-
Like fuzzy query starting with%, index invalid.
If it is only tail fuzzy matching, the index will not fail. If it is a header fuzzy match, the index is invalid
-
If MySQL evaluation uses indexes more slowly than full tables, indexes are not used
-
is NULL, is NOT NULL sometimes the index fails
-
Try to use composite indexes instead of single column indexes
TIP :
using index: appears when using an overlay index
using where: when searching and using an index, you need to go back to the table to query the required data
using index condition: the search uses an index, but the data needs to be queried back to the table
using index ; using where: the index is used for searching, but the required data can be found in the index column, so there is no need to query the data back to the table
To view index usage:
show status like 'Handler_read%'; show global status like 'Handler_read%';
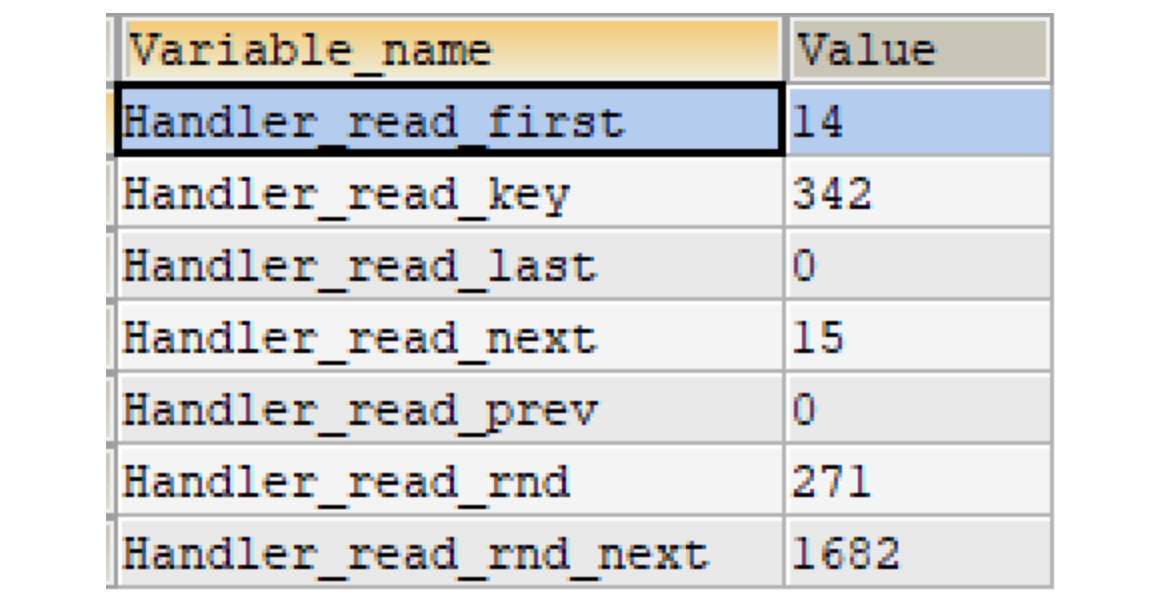
- Handler_read_first: the number of times the first entry in the index is read. A high value indicates that the server is performing a large number of full index scans (the lower the value, the better).
- Handler_read_key: if the index is working, this value represents the number of times a row is read by the index value. If the value is lower, it means that the performance improvement of the index is not high, because the index is not often used (the higher the value, the better).
- Handler_read_next: the number of requests to read the next line in key order. This value increases if you query index columns with range constraints or if you perform an index scan.
- Handler_read_prev: the number of requests to read the previous line in key order. This method is mainly used to optimize ORDER BY... DESC.
- Handler_read_rnd: the number of requests to read a row according to a fixed position. If you are executing a large number of queries and need to sort the results, this value is higher. You may have used a lot of queries that require MySQL to scan the entire table, or your connection does not use keys correctly. This value is high, which means that the operation efficiency is low, and an index should be established to remedy it.
- Handler_read_rnd_next: the number of requests to read the next line in the data file. This value is higher if you are doing a large number of table scans. It usually indicates that your table index is incorrect or the written query does not use the index.
5-2 optimizing insert statements
When insert ing data, the following optimization schemes can be considered:
-
If you need to insert many rows of data into a table at the same time, you should try to use the insert statement of multiple value tables. This method will greatly reduce the consumption of connection and closing between the client and the database. This makes it faster than a single insert statement executed separately.
Example, the original method is:
insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry');
The optimized scheme is:
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
-
Data insertion after manually starting a transaction
start transaction; insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); commit;
-
Orderly data insertion
insert into tb_test values(4,'Tim'); insert into tb_test values(1,'Tom'); insert into tb_test values(3,'Jerry'); insert into tb_test values(5,'Rose'); insert into tb_test values(2,'Cat');
After optimization:
insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); insert into tb_test values(4,'Tim'); insert into tb_test values(5,'Rose');
5-3 optimizing the order by statement
(1) Environmental preparation
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(3) NOT NULL,
`salary` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800');
insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200');
insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700');
insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400');
insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100');
insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900');
insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500');
create index idx_emp_age_salary on emp(age,salary);#Create composite index
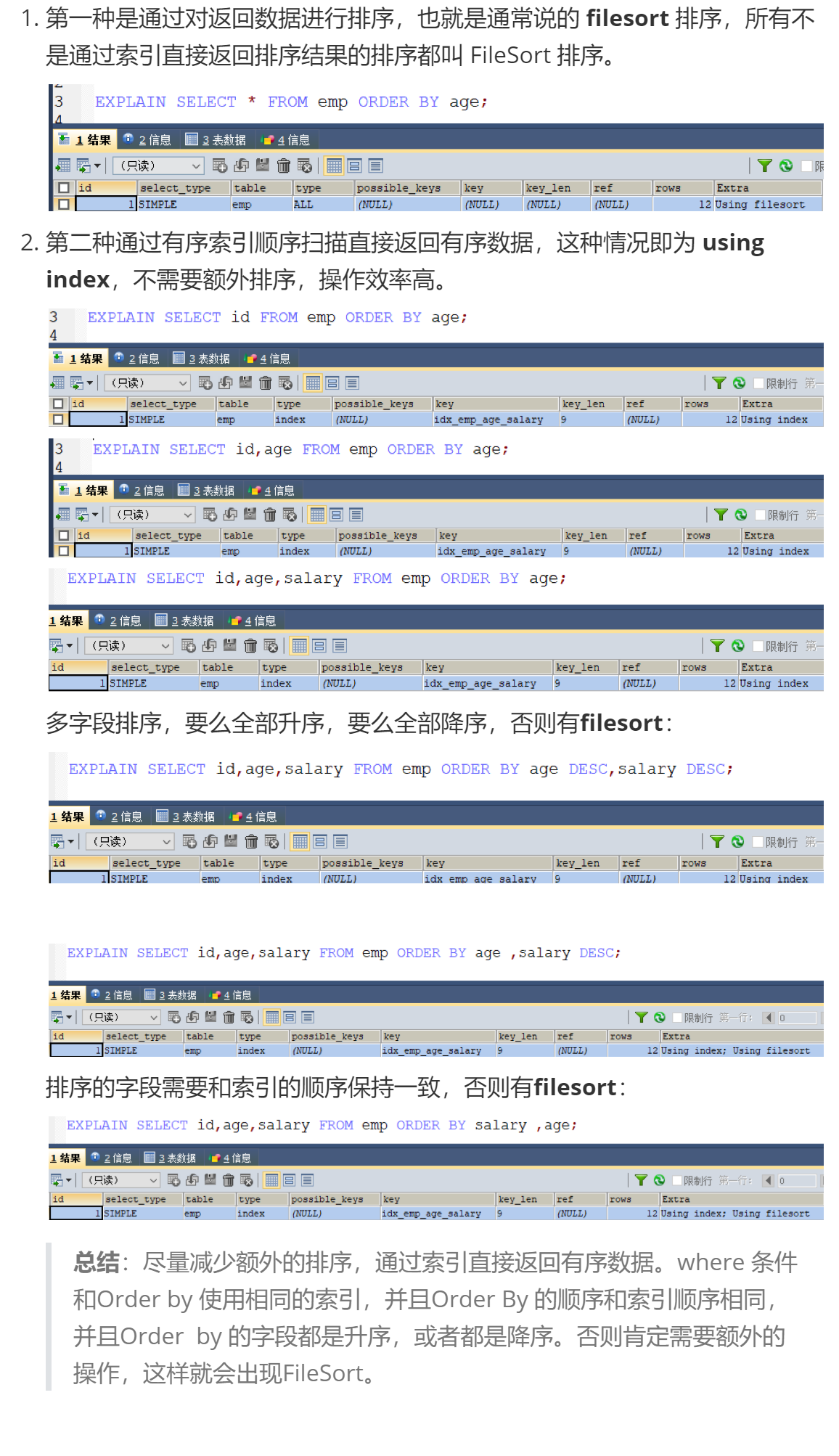
(2) Two sorting methods
(3) Optimization of Filesort
Creating an appropriate index can reduce the occurrence of Filesort, but in some cases, conditional restrictions can not make Filesort disappear, so it is necessary to speed up the sorting operation of Filesort. For Filesort, MySQL has two sorting algorithms:
- Two scan algorithm: first, get the sorting field and row pointer information according to the conditions, and then sort in the sort buffer in the sorting area. If the sort buffer is not enough, the sorting results will be stored in the temporary table. After sorting, read the records back to the table according to the row pointer. This operation may lead to a large number of random I/O operations. (before MySQL 4.1, use this method to sort)
- One scan algorithm: take out all the fields that meet the conditions at one time, and then sort them in the sort buffer of the sorting area, and then directly output the result set. The memory cost of sorting is large, but the sorting efficiency is higher than the two scan algorithm.
MySQL compares the system variable max_ length_ for_ sort_ The size of the data and the total size of the fields taken out by the Query statement to determine whether the sorting algorithm is, if max_ length_ for_ sort_ If the data is larger, use the second optimized algorithm; Otherwise, use the first one.
Sort can be improved appropriately_ buffer_ Size and max_length_for_sort_data system variable to increase the size of the sorting area and improve the efficiency of sorting.
View instructions:
SHOW VARIABLES LIKE 'max_length_for_sort_data'; SHOW VARIABLES LIKE 'sort_buffer_size';
5-4 optimizing group by statements
In fact, GROUP BY also performs sorting operations, and compared with ORDER BY, GROUP BY mainly only has more grouping operations after sorting. Of course, if other aggregate functions are used in grouping, some aggregate function calculations are required. Therefore, in the implementation of GROUP BY, the index can also be used like ORDER BY.
Delete the previous composite index first:
drop index idx_emp_age_salary on emp;
If the query contains group by but the user wants to avoid the consumption of sorting results, order by null can be executed to prohibit sorting. As follows:
Before optimization:

After optimization:

You can also create indexes:
CREATE INDEX idx_emp_age_salary ON emp(age,salary);

5-5 optimizing nested queries
You can replace subqueries with multi table JOIN queries as much as possible:
Before optimization:

After optimization:

Join queries are more efficient because MySQL does not need to create temporary tables in memory to complete this logically two-step query.
5-6 optimizing OR conditions
For query clauses containing OR, if you want to use indexes, indexes must be used for each condition column between ors, and composite indexes cannot be used; If there is no index, you should consider increasing the index.
example:
explain select * from emp where id = 1 or age = 30;

It is recommended to replace or with union:
EXPLAIN SELECT * FROM emp WHERE id=1 UNION SELECT * FROM emp WHERE age=20;
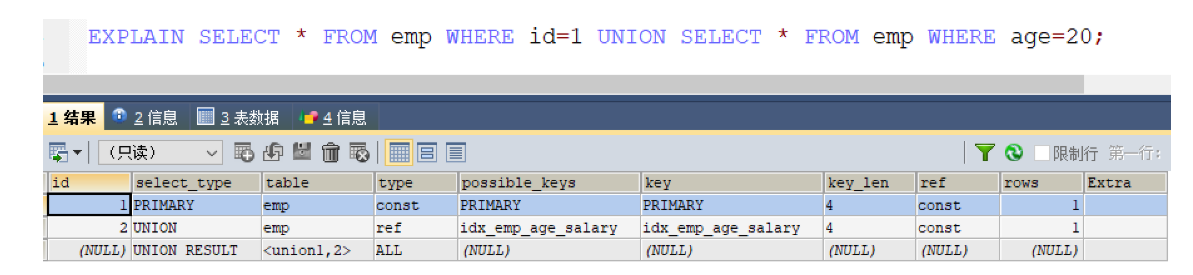
Let's compare the important indicators and find that the main differences are type and ref
Type shows the access type, which is an important indicator. The result values are as follows from good to bad:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
The type value of the UNION statement is ref and the type value of the OR statement is range. You can see that this is an obvious gap
The ref value of the UNION statement is const, and the ref value of the OR statement is null. Const indicates that it is a constant value reference, which is very fast
The difference between the two shows that UNION is better than OR.
5-7 optimize paging query
In general paging queries, the performance can be improved by creating an overlay index. A common and troublesome problem is the limit 2000000,10. At this time, MySQL needs to sort the top 2000010 records, only return 2000000 - 2000010 records, discard other records, and the cost of querying and sorting is very high.

Optimization idea 1:
Complete sorting and paging operations on the index, and finally associate other column contents required by the original table query according to the primary key.

Optimization idea 2:
This scheme is applicable to tables with self incremented primary keys (no fault is allowed), and the Limit query can be transformed into a query at a certain location.

5-8 tips for using SQL
SQL prompt is an important means to optimize the database. In short, it is to add some artificial prompts to the SQL statement to achieve the purpose of optimizing the operation.
USE INDEX:
After the table name in the query statement, add use index to provide the index list you want Mysql to refer to, so that MySQL can no longer consider other available indexes.
EXPLAIN SELECT * FROM tb_seller USE INDEX(idx_seller_name_sta_addr) WHERE NAME='Xiaomi Tech ';
IGNORE INDEX:
If users simply want MySQL to ignore one or more indexes, they can use ignore index as hint.
EXPLAIN SELECT * FROM tb_seller IGNORE INDEX(idx_seller_name_sta_addr) WHERE NAME='Xiaomi Tech ';
FORCE INDEX:
To force MySQL to use a specific index, use force index as hint in the query
EXPLAIN SELECT * FROM tb_seller FORCE INDEX(idx_seller_address) WHERE address='Beijing';
5-9 mass insert data
When using the load command to import data, appropriate settings can improve the import efficiency:
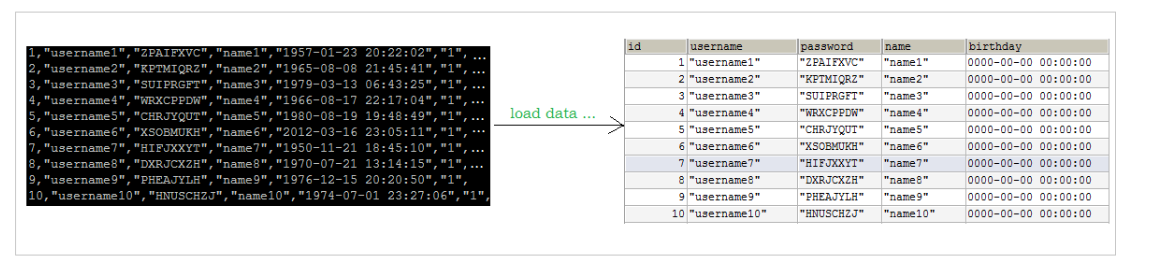
For InnoDB type tables, there are several ways to improve the import efficiency:
- Primary key sequential insertion: because InnoDB tables are saved in the order of primary keys, arranging the imported data in the order of primary keys can effectively improve the efficiency of importing data. If the InnoDB table does not have a primary key, the system will automatically create an internal column as the primary key by default. Therefore, if you can create a primary key for the table, you can use this to improve the efficiency of importing data.
- Turn off uniqueness check: execute set unique before importing data_ Checks = 0, turn off uniqueness verification, and execute set unique after import_ Checks = 1, restore uniqueness verification, which can improve the efficiency of import.
- Manual transaction submission: if the application uses automatic submission, it is recommended to execute SET AUTOCOMMIT=0 before import, turn off automatic submission, and then execute SET AUTOCOMMIT=1 after import to turn on automatic submission, which can also improve the efficiency of import.
LAIN SELECT * FROM tb_seller USE INDEX(idx_seller_name_sta_addr) WHERE NAME = 'Xiaomi technology';
Finally, don't forget to click three times 🎈🎈🎈
