
List of reference resources
- Official document: https://docs.spring.io/spring-data/jpa/docs/2.1.5.RELEASE/reference/html/
- Spring Data JPA introduction to mastery
Preface
JPA is the abbreviation of Java Persistence API. It is the second encapsulation framework of Spring based on Hibernate. In order to better and more convenient integrate into Spring family, JPA also provides some features that hibernate does not have. Together with other ORM frameworks, JPA forms SpringData, encapsulates ORM layer in a unified way, making developers more convenient and quick to use.
Note: all code in this article is based on spring boot version 2.1.5
The use of JPA
Use of basic single table operations
For single table operation, jpa provides a very convenient package. We just need to write the Repository interface according to the specification and inherit jpa Repository to enjoy the basic functions of jpa. The code is as follows:
User entities:
package com.yizhu.entity;
import lombok.Builder;
import lombok.Data;
import lombok.ToString;
import javax.persistence.*;
import java.io.Serializable;
import java.util.List;
import java.util.Set;
@Entity
@Table(name = "t_user")
@Data
@Builder
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String password;
private Integer age;
private Integer sex;
}
repository interface:
package com.yizhu.repository;
import com.yizhu.entity.User;
public interface UserRepository extends JpaRepository<User, Long>{
}Let's take a look at the default methods jpa provides for us to manipulate single table data.
package org.springframework.data.jpa.repository;
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll(); // Query full table data
List<T> findAll(Sort var1); // Query full table data, support sorting
List<T> findAllById(Iterable<ID> var1); // Query all matching data according to id field
<S extends T> List<S> saveAll(Iterable<S> var1); // Batch save or update data
void flush(); // Refresh local cache to database
<S extends T> S saveAndFlush(S var1); // Save or update singleton data and refresh local cache to database
void deleteInBatch(Iterable<T> var1); // Bulk delete data
void deleteAllInBatch(); // Batch delete full table data
T getOne(ID var1); // Query a piece of matching data according to id
<S extends T> List<S> findAll(Example<S> ar1); // Query specified entity by Example
<S extends T> List<S> findAll(Example<S> var1, Sort var2); // Example query specifies entities and sorts them
}package org.springframework.data.repository;
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort var1); // Query the whole table according to sorting, and the return type is any set
Page<T> findAll(Pageable var1); // Paging query according to paging parameters
}package org.springframework.data.repository;
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1); // Save or update single data
<S extends T> Iterable<S> saveAll(Iterable<S> var1); // Batch save or update
Optional<T> findById(ID var1); // According to the id query data, the return type is Optional
boolean existsById(ID var1); // Judge whether data exists according to id
Iterable<T> findAll(); // Query full table data, return type is set
Iterable<T> findAllById(Iterable<ID> var1); // Query data according to id set
long count(); // Statistics of data volume of the whole table
void deleteById(ID var1); // Delete data by id
void delete(T var1); // Delete single data
void deleteAll(Iterable<? extends T> var1); // Delete specified collection data
void deleteAll(); // Delete full table data
}package org.springframework.data.repository.query;
public interface QueryByExampleExecutor<T> {
<S extends T> Optional<S> findOne(Example<S> var1); // Query one according to Example
<S extends T> Iterable<S> findAll(Example<S> var1); // Query all data according to Example
<S extends T> Iterable<S> findAll(Example<S> var1, Sort var2); // Query all data according to Example and sort
<S extends T> Page<S> findAll(Example<S> var1, Pageable var2); // Paging query according to Example
<S extends T> long count(Example<S> var1); // According to Example statistics
<S extends T> boolean exists(Example<S> var1); // Judge whether data exists according to Example
}In addition, jpa provides a new mechanism for generating sql, which is very convenient and easy to use. jpa automatically generates sql according to the keywords, entity fields and access parameters in the Repository interface method. When starting the container in this way, it can check whether the syntax is correct. A simple example is as follows:
package com.yizhu.repository;
import com.yizhu .entity.User;
import org.springframework.data.jpa.repository.EntityGraph;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface UserRepository extends JpaRepository<User, Long>{
/**
* Query user information based on age
* @param age
* @return
*/
List<User> findAllByAge(Integer age);
/**
* Query user information according to user gender and organization name
* @param userSex
* @param orgName
* @return
*/
List<User> findBySexAndOrg(@Param("sex") Integer sex, @Param("name") String name);
/**
* Fuzzy query based on user name
* @return
*/
List<User> findAllByNameLike(@Param("name") String name);
}In addition to find, By, And, there are also some keywords, all of which are defined in the PartTree And Part classes. When they are assembled, they can generate a variety of sql. Next, Part of the code is intercepted. Interested students can open the source code to read.
package org.springframework.data.repository.query.parser;
public class PartTree implements Streamable<PartTree.OrPart> {
private static final String KEYWORD_TEMPLATE = "(%s)(?=(\\p{Lu}|\\P{InBASIC_LATIN}))";
private static final String QUERY_PATTERN = "find|read|get|query|stream";
private static final String COUNT_PATTERN = "count";
private static final String EXISTS_PATTERN = "exists";
private static final String DELETE_PATTERN = "delete|remove";
private static final Pattern PREFIX_TEMPLATE = Pattern.compile("^(find|read|get|query|stream|count|exists|delete|remove)((\\p{Lu}.*?))??By");
private final PartTree.Subject subject;
private final PartTree.Predicate predicate;
...
private static String[] split(String text, String keyword) {
Pattern pattern = Pattern.compile(String.format("(%s)(?=(\\p{Lu}|\\P{InBASIC_LATIN}))", keyword));
return pattern.split(text);
}
private static class Predicate implements Streamable<PartTree.OrPart> {
private static final Pattern ALL_IGNORE_CASE = Pattern.compile("AllIgnor(ing|e)Case");
private static final String ORDER_BY = "OrderBy";
private final List<PartTree.OrPart> nodes;
private final OrderBySource orderBySource;
private boolean alwaysIgnoreCase;
public Predicate(String predicate, Class<?> domainClass) {
String[] parts = PartTree.split(this.detectAndSetAllIgnoreCase(predicate), "OrderBy");
if (parts.length > 2) {
throw new IllegalArgumentException("OrderBy must not be used more than once in a method name!");
} else {
this.nodes = (List)Arrays.stream(PartTree.split(parts[0], "Or")).filter(StringUtils::hasText).map((part) -> {
return new PartTree.OrPart(part, domainClass, this.alwaysIgnoreCase);
}).collect(Collectors.toList());
this.orderBySource = parts.length == 2 ? new OrderBySource(parts[1], Optional.of(domainClass)) : OrderBySource.EMPTY;
}
}
...
}
private static class Subject {
private static final String DISTINCT = "Distinct";
private static final Pattern COUNT_BY_TEMPLATE = Pattern.compile("^count(\\p{Lu}.*?)??By");
private static final Pattern EXISTS_BY_TEMPLATE = Pattern.compile("^(exists)(\\p{Lu}.*?)??By");
private static final Pattern DELETE_BY_TEMPLATE = Pattern.compile("^(delete|remove)(\\p{Lu}.*?)??By");
private static final String LIMITING_QUERY_PATTERN = "(First|Top)(\\d*)?";
private static final Pattern LIMITED_QUERY_TEMPLATE = Pattern.compile("^(find|read|get|query|stream)(Distinct)?(First|Top)(\\d*)?(\\p{Lu}.*?)??By");
private final boolean distinct;
private final boolean count;
private final boolean exists;
private final boolean delete;
private final Optional<Integer> maxResults;
public Subject(Optional<String> subject) {
this.distinct = (Boolean)subject.map((it) -> {
return it.contains("Distinct");
}).orElse(false);
this.count = this.matches(subject, COUNT_BY_TEMPLATE);
this.exists = this.matches(subject, EXISTS_BY_TEMPLATE);
this.delete = this.matches(subject, DELETE_BY_TEMPLATE);
this.maxResults = this.returnMaxResultsIfFirstKSubjectOrNull(subject);
}
private Optional<Integer> returnMaxResultsIfFirstKSubjectOrNull(Optional<String> subject) {
return subject.map((it) -> {
Matcher grp = LIMITED_QUERY_TEMPLATE.matcher(it);
return !grp.find() ? null : StringUtils.hasText(grp.group(4)) ? Integer.valueOf(grp.group(4)) : 1;
});
}
...
private boolean matches(Optional<String> subject, Pattern pattern) {
return (Boolean)subject.map((it) -> {
return pattern.matcher(it).find();
}).orElse(false);
}
}
}package org.springframework.data.repository.query.parser;
public class Part {
private static final Pattern IGNORE_CASE = Pattern.compile("Ignor(ing|e)Case");
private final PropertyPath propertyPath;
private final Part.Type type;
private Part.IgnoreCaseType ignoreCase;
...
public static enum Type {
BETWEEN(2, new String[]{"IsBetween", "Between"}),
IS_NOT_NULL(0, new String[]{"IsNotNull", "NotNull"}),
IS_NULL(0, new String[]{"IsNull", "Null"}),
LESS_THAN(new String[]{"IsLessThan", "LessThan"}),
LESS_THAN_EQUAL(new String[]{"IsLessThanEqual", "LessThanEqual"}),
GREATER_THAN(new String[]{"IsGreaterThan", "GreaterThan"}),
GREATER_THAN_EQUAL(new String[]{"IsGreaterThanEqual", "GreaterThanEqual"}),
BEFORE(new String[]{"IsBefore", "Before"}),
AFTER(new String[]{"IsAfter", "After"}),
NOT_LIKE(new String[]{"IsNotLike", "NotLike"}),
LIKE(new String[]{"IsLike", "Like"}),
STARTING_WITH(new String[]{"IsStartingWith", "StartingWith", "StartsWith"}),
ENDING_WITH(new String[]{"IsEndingWith", "EndingWith", "EndsWith"}),
IS_NOT_EMPTY(0, new String[]{"IsNotEmpty", "NotEmpty"}),
IS_EMPTY(0, new String[]{"IsEmpty", "Empty"}),
NOT_CONTAINING(new String[]{"IsNotContaining", "NotContaining", "NotContains"}),
CONTAINING(new String[]{"IsContaining", "Containing", "Contains"}),
NOT_IN(new String[]{"IsNotIn", "NotIn"}),
IN(new String[]{"IsIn", "In"}),
NEAR(new String[]{"IsNear", "Near"}),
WITHIN(new String[]{"IsWithin", "Within"}),
REGEX(new String[]{"MatchesRegex", "Matches", "Regex"}),
EXISTS(0, new String[]{"Exists"}),
TRUE(0, new String[]{"IsTrue", "True"}),
FALSE(0, new String[]{"IsFalse", "False"}),
NEGATING_SIMPLE_PROPERTY(new String[]{"IsNot", "Not"}),
SIMPLE_PROPERTY(new String[]{"Is", "Equals"});
private static final List<Part.Type> ALL = Arrays.asList(IS_NOT_NULL, IS_NULL, BETWEEN, LESS_THAN, LESS_THAN_EQUAL, GREATER_THAN, GREATER_THAN_EQUAL, BEFORE, AFTER, NOT_LIKE, LIKE, STARTING_WITH, ENDING_WITH, IS_NOT_EMPTY, IS_EMPTY, NOT_CONTAINING, CONTAINING, NOT_IN, IN, NEAR, WITHIN, REGEX, EXISTS, TRUE, FALSE, NEGATING_SIMPLE_PROPERTY, SIMPLE_PROPERTY);
public static final Collection<String> ALL_KEYWORDS;
private final List<String> keywords;
private final int numberOfArguments;
...
static {
List<String> allKeywords = new ArrayList();
Iterator var1 = ALL.iterator();
while(var1.hasNext()) {
Part.Type type = (Part.Type)var1.next();
allKeywords.addAll(type.keywords);
}
ALL_KEYWORDS = Collections.unmodifiableList(allKeywords);
}
}
}It can be seen that jpa provides us with a ready-made implementation for most of the requirements of single table operation, but it also supports us to use @ Query annotation to customize Query sql, which is convenient for students with sql foundation and has strong controllability.
package com.yizhu.repository;
import com.yizhu .entity.User;
import org.springframework.data.jpa.repository.EntityGraph;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface UserRepository extends JpaRepository<User, Long>{
/**
* Query all user information
* @return
*/
@Query(value = "from User u")
List<User> findAll();
/**
* Query user information based on age
* @param age
* @return
*/
@Query(value = "select * from t_user u where u.user_age = ?1", nativeQuery = true)
List<User> findAllByAge(Integer age);
/**
* Query user information according to user gender and organization name
* @param userSex
* @param orgName
* @return
*/
@Query(value = "select u from User u left join u.org o where u.userSex = :userSex and o.orgName = :orgName")
List<User> findUsersBySexAndOrg(@Param("userSex") Integer userSex, @Param("orgName") String orgName);
}Multi table correlation
@OneToOne,@OneToMany,@ManyToOne,@ManyToMany
@Entity
@Table(name = "t_user")
@NamedEntityGraph(name = "User.findUsers", attributeNodes = {@NamedAttributeNode("jobs"), @NamedAttributeNode("roles")})
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@ApiModelProperty(hidden = true)
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ApiModelProperty(value = "User name")
@Column(name = "user_name")
private String name;
@ApiModelProperty(value = "User password")
@Column(name = "user_password")
private String password;
@ApiModelProperty(value = "User age")
@Column(name = "user_age")
private Integer age;
@ApiModelProperty(value = "User gender")
@Column(name = "user_sex")
private Integer sex;
@ApiModelProperty(value = "Affiliated organization id")
@Column(name = "org_id")
private Long orgId;
@ApiModelProperty(value = "User information")
@OneToOne
@JoinColumn(name = "id", updatable = false, insertable = false)
private UserInfo userInfo;
@ApiModelProperty(value = "User organization")
@ManyToOne
@JoinColumn(name = "org_id", updatable = false, insertable = false)
private Organization org;
@ApiModelProperty(value = "User roles")
@OneToMany
@JoinColumn(name = "user_id", referencedColumnName = "id", insertable = false, updatable = false)
@NotFound(action = NotFoundAction.IGNORE)
private Set<Role> roles;
@ApiModelProperty(value = "User work")
@ManyToMany
@JoinTable(
name = "t_user_job",
joinColumns = @JoinColumn(name = "user_id", referencedColumnName = "id"),
inverseJoinColumns = @JoinColumn(name = "job_id", referencedColumnName = "id")
)
@NotFound(action = NotFoundAction.IGNORE)
private Set<Job> jobs;private Set<Role> roles;and private Set<Job> jobs;Cannot be used at the same time List Set substitution, error will be reported org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [com.yizhu.entity.User.jobs, com.yizhu.entity.User.roles]
Dynamic query
package com.yizhu.repository;
import com.yizhu.dto.UserQueryDto;
import com.yizhu.entity.Organization;
import com.yizhu.entity.User;
import org.springframework.data.jpa.domain.Specification;
import javax.persistence.criteria.Join;
import javax.persistence.criteria.JoinType;
import javax.persistence.criteria.Predicate;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
public class UserSpecs {
public static Specification<User> listQuerySpec(UserQueryDto userQueryDto){
return (root, query, builder) -> {
List<Predicate> predicates = new ArrayList<>();
Optional.ofNullable(userQueryDto.getId()).ifPresent(i -> predicates.add(builder.equal(root.get("id"), i)));
Optional.ofNullable(userQueryDto.getName()).ifPresent(n -> predicates.add(builder.equal(root.get("name"), n)));
Optional.ofNullable(userQueryDto.getAge()).ifPresent(a -> predicates.add(builder.equal(root.get("age"), a)));
Optional.ofNullable(userQueryDto.getOrgId()).ifPresent(oi -> predicates.add(builder.equal(root.get("orgId"), oi)));
Optional.ofNullable(userQueryDto.getOrgName()).ifPresent(on -> {
Join<User, Organization> userJoin = root.join(root.getModel().getSingularAttribute("org", Organization.class), JoinType.LEFT);
predicates.add(builder.equal(userJoin.get("orgName"), on));
});
return builder.and(predicates.toArray(new Predicate[predicates.size()]));
};
}
}package com.yizhu.service;
import com.yizhu.dto.UserQueryDto;
import com.yizhu.entity.User;
import com.yizhu.repository.UserRepository;
import com.yizhu.repository.UserSpecs;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public List<User> findUsersDynamic(UserQueryDto userQueryDto){
return userRepository.findAll(UserSpecs.listQuerySpec(userQueryDto));
}
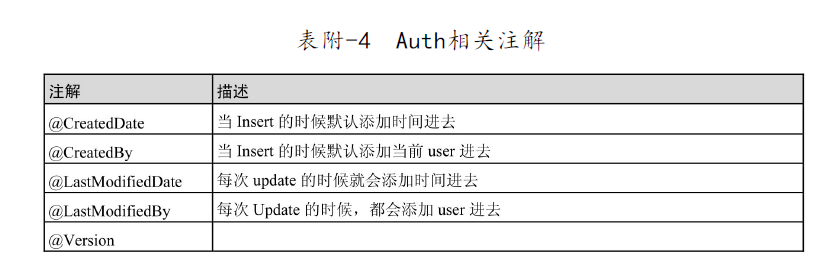
}Use of audit function
Add @ EnableJpaAuditing annotation to the startup class to enable jpa auditing.
package com.yizhu;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.jpa.repository.config.EnableJpaAuditing;
@EnableJpaAuditing
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}Add @ EntityListeners(AuditingEntityListener.class) annotation to entity class requiring audit function
package com.yizhu.entity;
import lombok.Builder;
import lombok.Data;
import org.springframework.data.jpa.domain.support.AuditingEntityListener;
import javax.persistence.*;
import java.io.Serializable;
import java.util.Date;
@Entity
@Table(name = "t_role")
@Data
@Builder
@EntityListeners(AuditingEntityListener.class)
public class Role implements Serializable {
private static final long serialVersionUID=1L;
@ApiModelProperty(hidden = true)
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String roleName;
@CreatedDate
private Date createTime;
@CreatedBy
private Long createId;
@LastModifiedDate
private Date updateTime;
@LastModifiedBy
private Long updateId;
}Implement the AuditorAware interface to tell the container the current login id
package com.yizhu.configuration;
import org.springframework.data.domain.AuditorAware;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import java.util.Optional;
public class UserAuditorAwareImpl implements AuditorAware<Long> {
@Override
public Optional<Long> getCurrentAuditor() {
// Get login id from session
ServletRequestAttributes servletRequestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
Long userId = (Long)servletRequestAttributes.getRequest().getSession().getAttribute("userId");
return Optional.of(userId);
}
}ok, then JPA will judge whether the current operation is to update or add data according to the ID and Version. When adding, it will inject the current login ID into the field marked with @ CreateBy annotation, and the current time into the field marked with @ CreateTime annotation; when updating, it will inject into the field corresponding to @ LastModifiedBy and @ LastModifiedDate. For more information, see the source code of org.springframework.data.jpa.domain.support.AuditingEntityListener.
Common pits
- N+1 problem, when using @ ManyToMany, @ ManyToOne, @ OneToMany, @ OneToOne Association
How to configure LAZY or eagle for FetchType in relation. When SQL actually executes
Waiting is composed of a main table query and N sub table queries. This kind of query efficiency is generally compared
For example, if there are n sub objects, N+1 SQL will be executed. This problem can be solved by using @ EntityGraph and @ NamedEntityGraph pushed by JPA 2.1. As follows.
@ApiModel
@Entity
@Table(name = "t_user")
@NamedEntityGraph(name = "User.findUsers", attributeNodes = {@NamedAttributeNode("jobs"), @NamedAttributeNode("roles")})
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@ApiModelProperty(hidden = true)
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// Omit other attributes
}package com.yizhu.repository;
import com.yizhu.entity.User;
import org.springframework.data.jpa.repository.EntityGraph;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface UserRepository extends JpaRepository<User, Long>, JpaSpecificationExecutor<User> {
/**
* Query user information according to id
* @param id
* @return
*/
@EntityGraph(value = "User.findUsers", type = EntityGraph.EntityGraphType.FETCH)
User findAllById(Long id);
/**
* Query user information according to name
* @param name
* @return
*/
@EntityGraph(value = "User.findUsers", type = EntityGraph.EntityGraphType.FETCH)
@Query(value = "select * from t_user where user_name = :name", nativeQuery = true)
List<User> findAllByUserName(@Param("name") String name);
}- All annotations are either fully configured on fields or get methods. If they are not mixed, they will fail to start, but there is no problem with syntax configuration.
- All associations support one-way Association and two-way Association, depending on the specific business scenario. When using two-way annotations in JSON serialization, there will be a life and death cycle. You need to manually convert it once, or use @ JsonIgnore.
- In all associated queries, tables generally do not need to be indexed by foreign keys. @The use of mappedBy needs attention.
- Cascade deletion is dangerous. It is recommended to consider it clearly or master it completely.
- The names and referencedcolumnnames in @ joincolumn are different for different configurations of association relationships. They are easy to confuse and can be adjusted according to the printed SQL.
- When configuring these relationships, it is recommended that you build the foreign key directly on the table, and then generate it directly through the development tools introduced later, which can reduce the time of debugging.
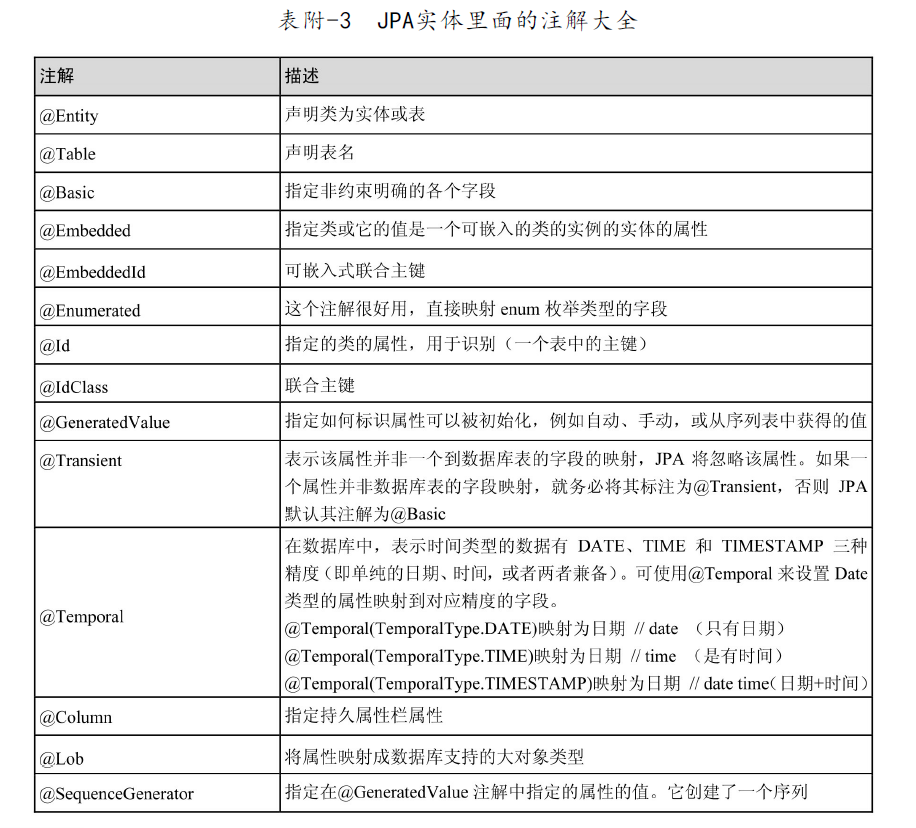
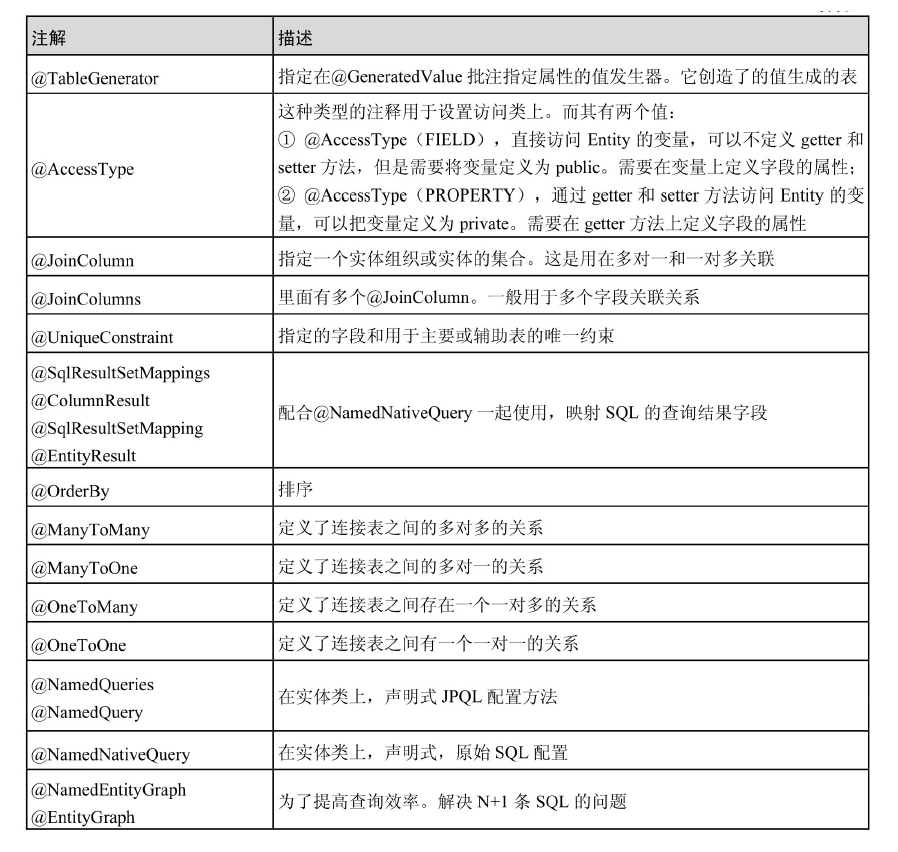
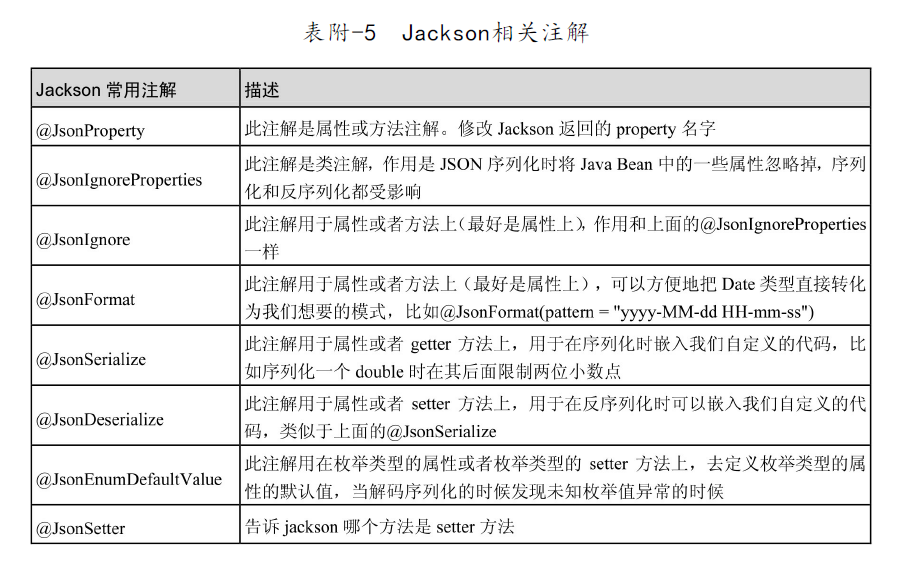
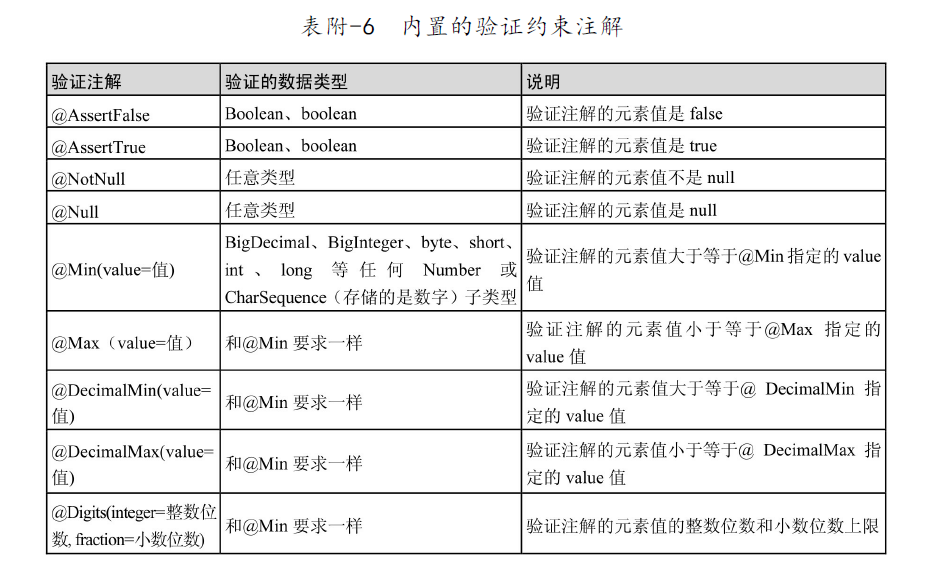
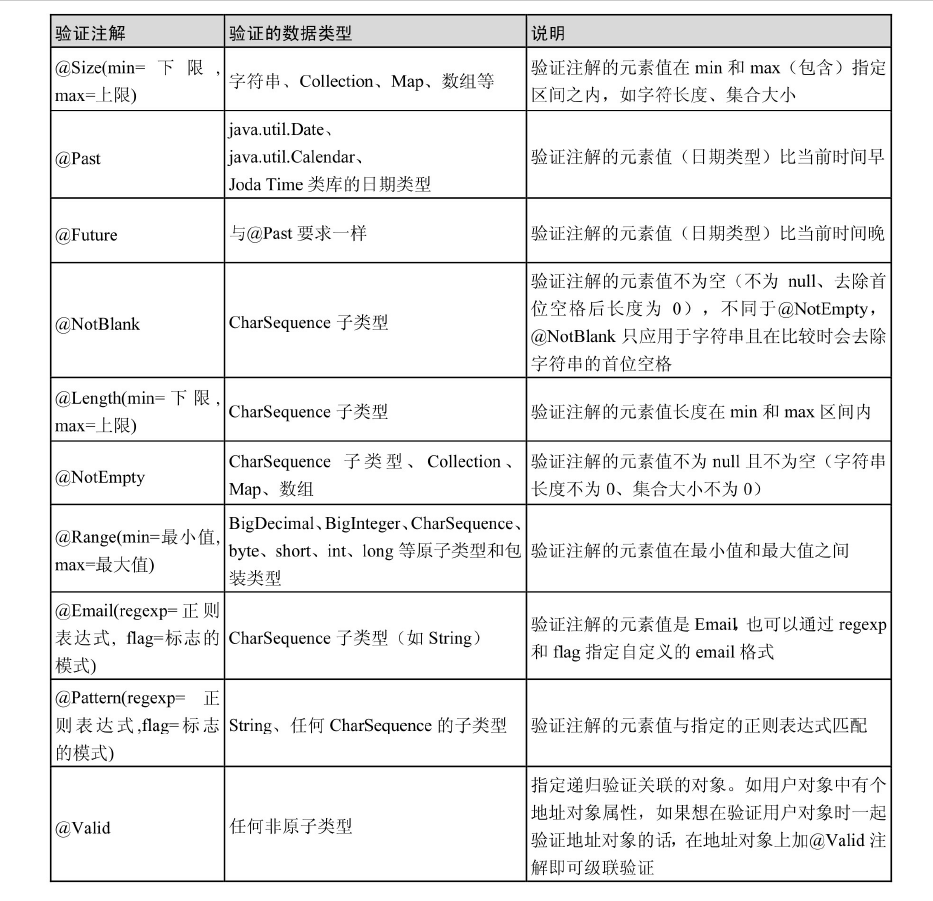
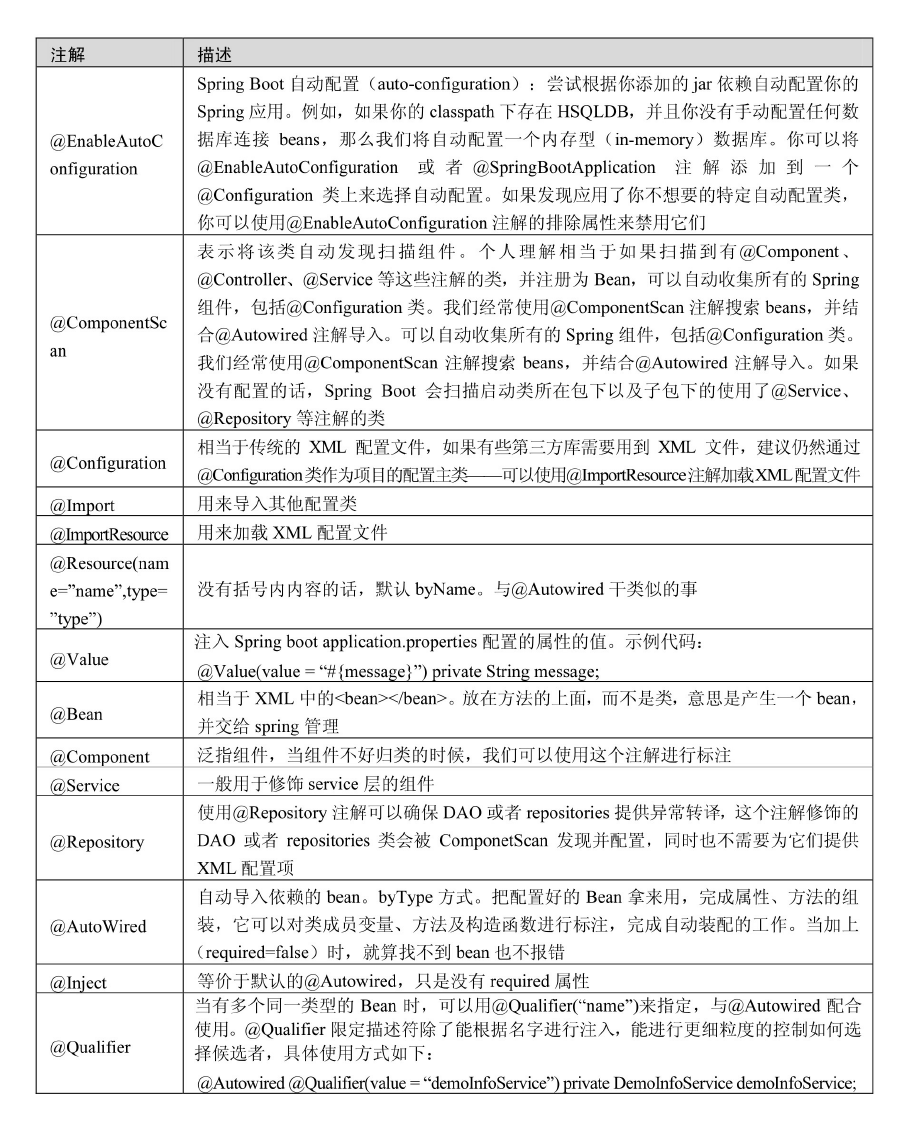
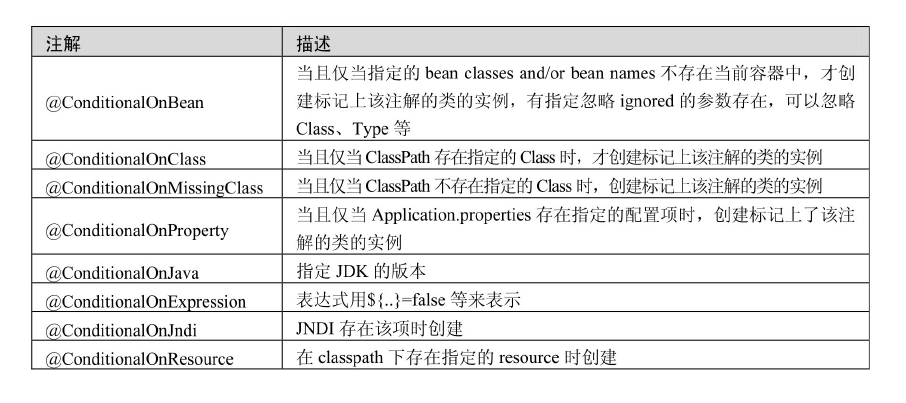
JPA common annotations
Excerpt from Spring Data JPA from introduction to mastery

For more information, follow my personal blog: Yi bamboo station or Yi bamboo station