Recently, the spring source code has been re-parsed so that I can better read the spring source code in the future. If you want to discuss it in depth, Please add me QQ:1051980588.
1 ClassPathResource resource = new ClassPathResource("bean.xml"); 2 DefaultListableBeanFactory factory = new DefaultListableBeanFactory(); 3 XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory); 4 reader.loadBeanDefinitions(resource);
spring source code parsing above is the most basic lines of code, I will explore the basic code in depth, of course, some code interpretation is based on other blogs to learn from, if you have the same hope to forgive me.
- ClassPathResource = new ClassPathResource ("bean.xml"); create Resource resource objects based on Xml configuration files. ClassPathResource is a subclass of Resource interface, and the content in the Bean. XML file is the Bean information we defined.
- DefaultListable BeanFactory = new DefaultListable BeanFactory ();: Create a BeanFactory. DefaultListable BeanFactory is a subclass of BeanFactory. As an interface, BeanFactory itself does not have the function of independent use. DefaultListable BeanFactory is a truly independent IoC container. It is the ancestor of Spring IoC. There will be a special article to analyze it later.
- XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);: Create an XmlBeanDefinitionReader reader for loading BeanDefinition.
- Reader. loadBeanDefinitions (resources);: Start the loading and registration process of BeanDefinition, and place the completed BeanDefinition in the IoC container.
1. Resource Location
In order to solve the problem of resource location, Spring provides two interfaces: Resource and Resource Loader, in which:
- Resource interface is an abstract interface of Spring unified resources
- ResourceLoader is a unified abstraction of Spring resource loading.
The location of Resource resources requires the coordination of Resource and Resource Loader interfaces. In the above code, new ClassPathResource (bean. xml) defines resources for us. When did ResourceLoader initialize? Look at the XmlBean Definition Reader construction method:
1 // XmlBeanDefinitionReader.java 2 public XmlBeanDefinitionReader(BeanDefinitionRegistry registry) { 3 super(registry); 4 }
We can see a direct call to the parent AbstractBeanDefinitionReader constructor, code as follows:
1 // AbstractBeanDefinitionReader.java
2
3 protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
4 Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
5 this.registry = registry;
6 // Determine ResourceLoader to use.
7 if (this.registry instanceof ResourceLoader) {
8 this.resourceLoader = (ResourceLoader) this.registry;
9 } else {
10 this.resourceLoader = new PathMatchingResourcePatternResolver();
11 }
12
13 // Inherit Environment if possible
14 if (this.registry instanceof EnvironmentCapable) {
15 this.environment = ((EnvironmentCapable) this.registry).getEnvironment();
16 } else {
17 this.environment = new StandardEnvironment();
18 }
19 }
The core is to set up the resourceLoader section. If you set up ResourceLoader, use the settings. Otherwise, use PathMatching ResourcePatternResolver, which is a resourceLoader of a master class.
2. Loading and parsing of BeanDefinition
Reader.loadBeanDefinitions (resources); code snippet, which opens the BeanDefinition parsing process. As follows:
1 // XmlBeanDefinitionReader.java
2 @Override
3 public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
4 return loadBeanDefinitions(new EncodedResource(resource));
5 }
In this method, the resource resource will be wrapped as a EncodedResource instance object and then called the #loadBeanDefinitions(EncodedResource encodedResource) method. The main purpose of encapsulating Resource into Encoded Resource is to encoding Resource and ensure the correctness of content reading. The code is as follows:
1 // XmlBeanDefinitionReader.java 2 3 public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException { 4 // ... Omit some code 5 try { 6 // Converting resource files to InputStream Of IO flow 7 InputStream inputStream = encodedResource.getResource().getInputStream(); 8 try { 9 // from InputStream Get in XML Analytic source 10 InputSource inputSource = new InputSource(inputStream); 11 if (encodedResource.getEncoding() != null) { 12 inputSource.setEncoding(encodedResource.getEncoding()); 13 } 14 // ... Specific reading process 15 return doLoadBeanDefinitions(inputSource, encodedResource.getResource()); 16 } 17 finally { 18 inputStream.close(); 19 } 20 } 21 // Omit some code 22 }
Get the parsing source of xml from the encodedResource source, then call #doLoadBeanDefinitions(InputSource inputSource, Resource resource) to perform the concrete parsing process.
// XmlBeanDefinitionReader.java protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) throws BeanDefinitionStoreException { try { // Obtain XML Document Example Document doc = doLoadDocument(inputSource, resource); // according to Document Examples, registration Bean information int count = registerBeanDefinitions(doc, resource); return count; } // ... Omit a bunch of configurations }
2.1 Convert to Document Object
Calling the # doLoadDocument(InputSource inputSource, Resource resource) method in the above method converts the resource defined by the Bean into a Document object. The code is as follows:
// XmlBeanDefinitionReader.java protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception { return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler, getValidationModeForResource(resource), isNamespaceAware()); }
The method accepts five parameters:
- inputSource: Load the Document Source source.
- Entity Resolver: A parser that parses files.
- Error Handler: Error handling the process of loading a Document object.
- Validation Mode: Validation mode.
- Namespace Aware: Namespace support. If you want to provide support for XML namespaces, then true
# The loadDocument (InputSource inputSource, EntityResolver entity Resolver, ErrorHandler errorHandler, int validation mode, Boolean namespace Aware) method is implemented in the DefaultDocument Loader class. The code is as follows:
1 // DefaultDocumentLoader.java 2 3 @Override 4 public Document loadDocument(InputSource inputSource, EntityResolver entityResolver, 5 ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception { 6 // Establish DocumentBuilderFactory 7 DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware); 8 // Establish DocumentBuilder 9 DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler); 10 // analysis XML InputSource Return Document object 11 return builder.parse(inputSource); 12 }
2.2 Register BeanDefinition Process
At this point, the defined Bean resource file is loaded and converted into a Document object. The next step, then, is to parse it into a SpringIoC managed BeanDefinition object and register it in the container. This process is implemented by the method # registerBean Definitions (Document doc, Resource resource). The code is as follows
1 // XmlBeanDefinitionReader.java 2 3 public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException { 4 // Establish BeanDefinitionDocumentReader object 5 BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader(); 6 // Get registered BeanDefinition Number 7 int countBefore = getRegistry().getBeanDefinitionCount(); 8 // Establish XmlReaderContext object 9 // register BeanDefinition 10 documentReader.registerBeanDefinitions(doc, createReaderContext(resource)); 11 // Computing new registrations BeanDefinition Number 12 return getRegistry().getBeanDefinitionCount() - countBefore; 13 }
(1) First, create BeanDefinition's parser BeanDefinition Document Reader.
(2) Then, call the # registerBeanDefinitions(Document doc, XmlReaderContext readerContext) method of the BeanDefinition Document Reader to start the parsing process. The delegation mode is used here, and the implementation is accomplished by the subclass DefaultBeanDefinition Document Reader. The code is as follows:
1 // DefaultBeanDefinitionDocumentReader.java 2 3 @Override 4 public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) { 5 this.readerContext = readerContext; 6 // Get XML Document Root Element 7 // Enforcement registration BeanDefinition 8 doRegisterBeanDefinitions(doc.getDocumentElement()); 9 }
2.2.1 parse the Document object, get the root element root from the Document object, and then call the #doRegisterBeanDefinitions(Element root) method to open the real parsing process. The code is as follows:
// DefaultBeanDefinitionDocumentReader.java protected void doRegisterBeanDefinitions(Element root) { // ... Omit part of the code (non-core) this.delegate = createDelegate(getReaderContext(), root, parent); // Analytical Preprocessing preProcessXml(root); // analysis parseBeanDefinitions(root, this.delegate); // Analytical post-processing postProcessXml(root); }
# ParseBean Definitions (Element root, Bean Definition Parser Delegate delegate) is an analytical registration process for root element root. The code is as follows:
// DefaultBeanDefinitionDocumentReader.java protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) { // If the root node uses the default namespace, perform default parsing if (delegate.isDefaultNamespace(root)) { // Traversing subnodes NodeList nl = root.getChildNodes(); for (int i = 0; i < nl.getLength(); i++) { Node node = nl.item(i); if (node instanceof Element) { Element ele = (Element) node; // If the node uses the default namespace, perform default parsing if (delegate.isDefaultNamespace(ele)) { parseDefaultElement(ele, delegate); // If the node is not the default namespace, perform custom parsing } else { delegate.parseCustomElement(ele); } } } // If the root node is not the default namespace, perform custom parsing } else { delegate.parseCustomElement(root); } }
Iterate all the child nodes of root element and judge them:
- If the node is the default namespace, the parseDefaultElement (Element ele, BeanDefinition ParserDelegate delegate) method is called to open the parsing and registration process of the default tag. Detailed analysis
- Otherwise, call the BeanDefinitionParserDelegate#parseCustomElement(Element ele) method to open the parse registration process for the custom tag.
2.2.1.1 Default Label Resolution
If the element node defined uses Spring default namespace, the parseDefaultElement (Element ele, BeanDefinition Parser Delegate delegate) method is called for default tag resolution. The code is as follows:
// DefaultBeanDefinitionDocumentReader.java private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) { if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) { // import importBeanDefinitionResource(ele); } else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) { // alias processAliasRegistration(ele); } else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) { // bean processBeanDefinition(ele, delegate); } else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) { // beans // recurse doRegisterBeanDefinitions(ele); } }
Four labels are analyzed: import, alias, bean and beans.
2.2.1.2 Custom Label Resolution
For default tags, parseCustomElement(Element ele) method is responsible for parsing. The code is as follows:
1 // BeanDefinitionParserDelegate.java 2 3 @Nullable 4 public BeanDefinition parseCustomElement(Element ele) { 5 return parseCustomElement(ele, null); 6 } 7 8 @Nullable 9 public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) { 10 // Obtain namespaceUri 11 String namespaceUri = getNamespaceURI(ele); 12 if (namespaceUri == null) { 13 return null; 14 } 15 // according to namespaceUri Get the corresponding Handler 16 NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri); 17 if (handler == null) { 18 error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele); 19 return null; 20 } 21 // Call custom Handler Handle 22 return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd)); 23 }
The namespaceUri of the node is obtained, and the corresponding NamespaceHandler is obtained according to the namespaceUri. Finally, the #parse(Element element, ParserContext parserContext) method of NamespaceHandler is called to complete the parsing and injection of the custom tag.
2.2.2 Register BeanDefinition
After the above analysis, the Bean tags in the Document object are parsed into Bean Definitions one by one. The next step is to register these Bean Definitions into the IoC container. The action is triggered after parsing the bean tag, and the code is as follows
// DefaultBeanDefinitionDocumentReader.java protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) { // Conduct bean Element resolution. // If the parse succeeds, it returns BeanDefinitionHolder Object. and BeanDefinitionHolder by name and alias Of BeanDefinition object // If parsing fails, return null . BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele); if (bdHolder != null) { // Conduct custom tag processing bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder); try { // Conduct BeanDefinition Registration // Register the final decorated instance. BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry()); } catch (BeanDefinitionStoreException ex) { getReaderContext().error("Failed to register bean definition with name '" + bdHolder.getBeanName() + "'", ele, ex); } // Send a response event to notify the relevant listener that this has been completed Bean Analysis of labels. // Send registration event. getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder)); } }
Call the BeanDefinitionReaderUtils.registerBeanDefinition() method to register. In fact, it also calls BeanDefinition Registry's # registerBeanDefinition(String beanName, BeanDefinition beanDefinition) method to register BeanDefinition. However, the final implementation is implemented in DefaultListable BeanFactory with the following code:
1 // DefaultListableBeanFactory.java 2 @Override 3 public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition) 4 throws BeanDefinitionStoreException { 5 // ...Eliminate the code associated with checking 6 // Get the specified from the cache beanName Of BeanDefinition 7 BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName); 8 // If it already exists 9 if (existingDefinition != null) { 10 // Throw an exception if it exists but is not allowed to override 11 if (!isAllowBeanDefinitionOverriding()) { 12 throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition); 13 } else { 14 // ...ellipsis logger Print Log Related Code 15 } 16 // [Emphasis) Allow coverage, direct coverage of the original BeanDefinition reach beanDefinitionMap Medium. 17 this.beanDefinitionMap.put(beanName, beanDefinition); 18 // If it does not exist 19 } else { 20 // ... Eliminate non-core code 21 // [Focus added BeanDefinition reach beanDefinitionMap Medium. 22 this.beanDefinitionMap.put(beanName, beanDefinition); 23 } 24 // Reset beanName Corresponding cache 25 if (existingDefinition != null || containsSingleton(beanName)) { 26 resetBeanDefinition(beanName); 27 } 28 }
The core part of this code is this. bean DefinitionMap. put (bean Name, bean Definition) snippet. Therefore, the registration process is not so big, that is to use a collection object of Map to store: key is beanName, value is BeanDefinition object.
3. summary
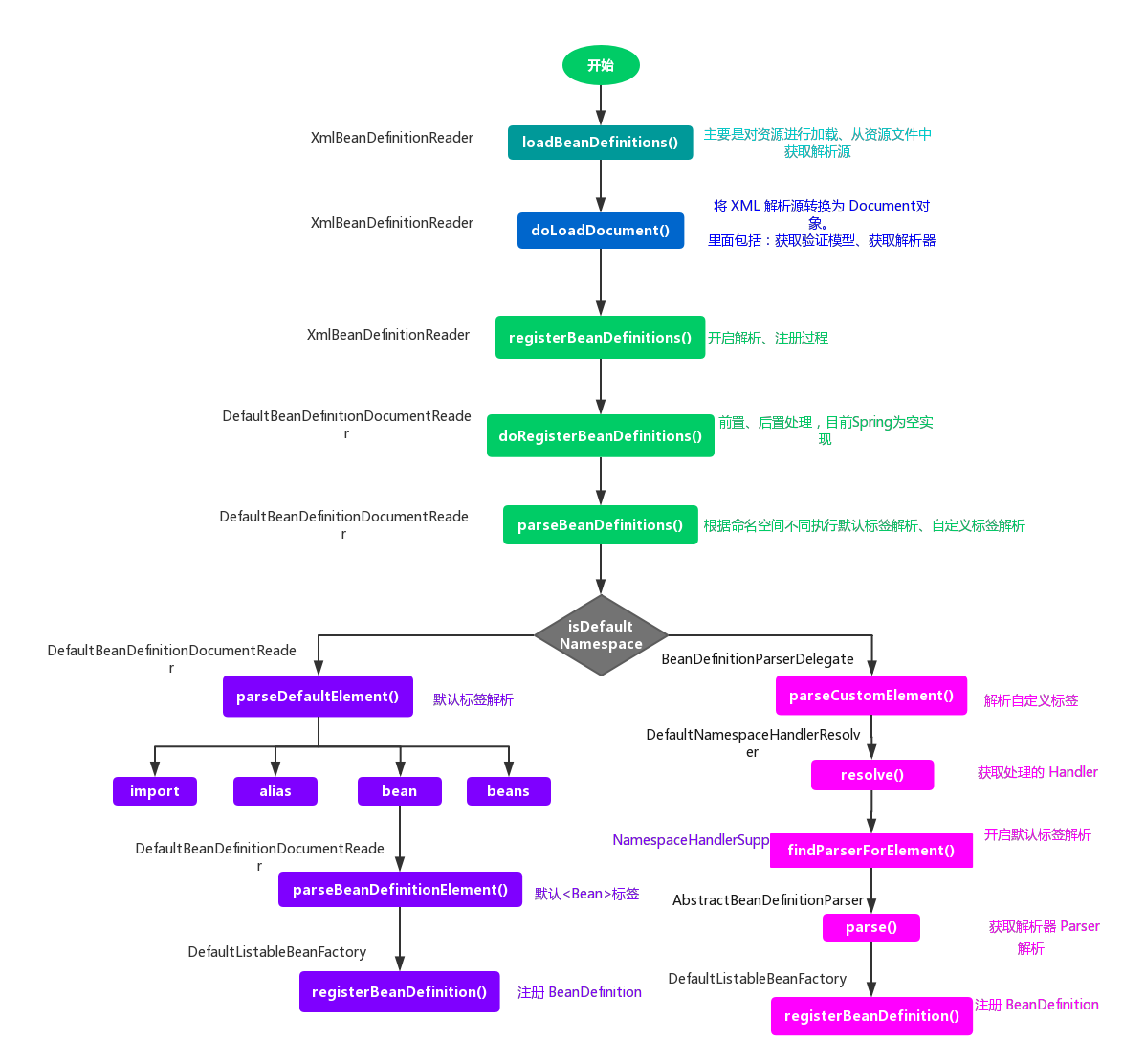
So far, the initialization process of the whole IoC has been completed, from the location of Bean resources to the Document object, then parse it, and finally register it in the IoC container, which has been perfectly completed. Now the configuration information of the whole bean has been established in the IoC container. These beans can be retrieved, used and maintained. They are the basis of control inversion and the dependence of injecting beans later. Finally, a flow chart is used to conclude this summary.