Original: Guan Changlong
We have introduced six common segmentation algorithms of DBLE and MyCat through the previous six articles, so let's make a summary!
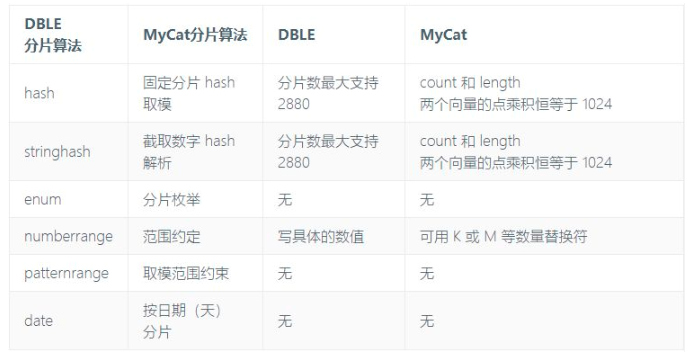
DBLE and MyCat corresponding algorithm name and similarities and differences
The seventh DBLE fragmentation algorithm jumpStringHash
In addition to the above six common sharding algorithms, DBLE also has a unique sharding algorithm: jump string algorithm.
The specific configuration is as follows:
#rule.xml <function name="jumphash" class="jumpStringHash"> <property name="partitionCount">2</property> <property name="hashSlice">0:2</property> </function>
partitionCont: number of segments
hashSlice: fragment cut length
This algorithm comes from a Google article "a fast, minimum memory, consistent hash algorithm". Its core idea is to change the probability of a hash value distribution in each node into 1/n by probability distribution method, and it can be calculated by a simpler method, and the distribution is more uniform.
Note: when the fragment field value is NULL, the data will always fall on node 0. When the field value that actually exists in mysql is not null, the error "Sharding column can't be null when the table in MySQL column is not null" will be reported.
At this point, we have finished the introduction of the seven fragmentation algorithms supported in DBLE. I believe that readers and friends are gradually familiar with the use of DBLE.
At the end of the series:
Full partition instance
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE dble:rule SYSTEM "rule.dtd"> <dble:rule xmlns:dble="http://dble.cloud/" version="9.9.9.9"> <tableRule name="sharding-by-enum"> <rule> <columns>id</columns> <algorithm>enum</algorithm> </rule> </tableRule> <tableRule name="sharding-by-range"> <rule> <columns>id</columns> <algorithm>rangeLong</algorithm> </rule> </tableRule> <tableRule name="sharding-by-hash"> <rule> <columns>id</columns> <algorithm>hashLong</algorithm> </rule> </tableRule> <tableRule name="sharding-by-hash2"> <rule> <columns>id</columns> <algorithm>hashLong2</algorithm> </rule> </tableRule> <tableRule name="sharding-by-hash3"> <rule> <columns>id</columns> <algorithm>hashLong3</algorithm> </rule> </tableRule> <tableRule name="sharding-by-mod"> <rule> <columns>id</columns> <algorithm>hashmod</algorithm> </rule> </tableRule> <tableRule name="sharding-by-hash-str"> <rule> <columns>id</columns> <algorithm>hashString</algorithm> </rule> </tableRule> <tableRule name="sharding-by-date"> <rule> <columns>calldate</columns> <algorithm>partbydate</algorithm> </rule> </tableRule> <tableRule name="sharding-by-pattern"> <rule> <columns>id</columns> <algorithm>pattern</algorithm> </rule> </tableRule> <!-- enum partition --> <function name="enum" class="Enum"> <property name="mapFile">partition-hash-int.txt</property> <property name="defaultNode">0</property><!--the default is -1,means unexpected value will report error--> <property name="type">0</property><!--0 means key is a number, 1 means key is a string--> </function> <!-- number range partition --> <function name="rangeLong" class="NumberRange"> <property name="mapFile">autopartition-long.txt</property> <property name="defaultNode">0</property><!--he default is -1,means unexpected value will report error--> </function> <!-- Hash partition,when partitionLength=1, it is a mod partition--> <!--MAX(sum(count*length[i]) must not more then 2880--> <function name="hashLong" class="Hash"> <property name="partitionCount">8</property> <property name="partitionLength">12