Summary of common HIVE functions
There are many hive functions. In the past, it was always used and checked. Today, I will summarize the commonly used functions for easy reference in the future.
This paper mainly involves the following aspects:
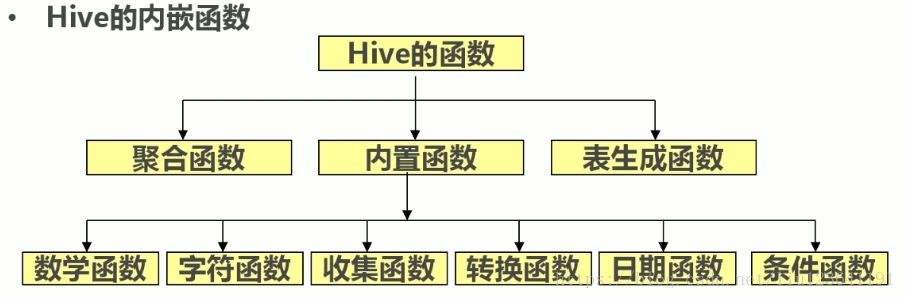
1. Hive function introduction and built-in function view
See Hive official documents for more information
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
1) View the functions provided by the system
hive> show functions;
2) Displays the usage of the built-in function
hive> desc function upper;
3) Displays the usage of the built-in function in detail
hive> desc function extended upper;
2. Introduction to common functions
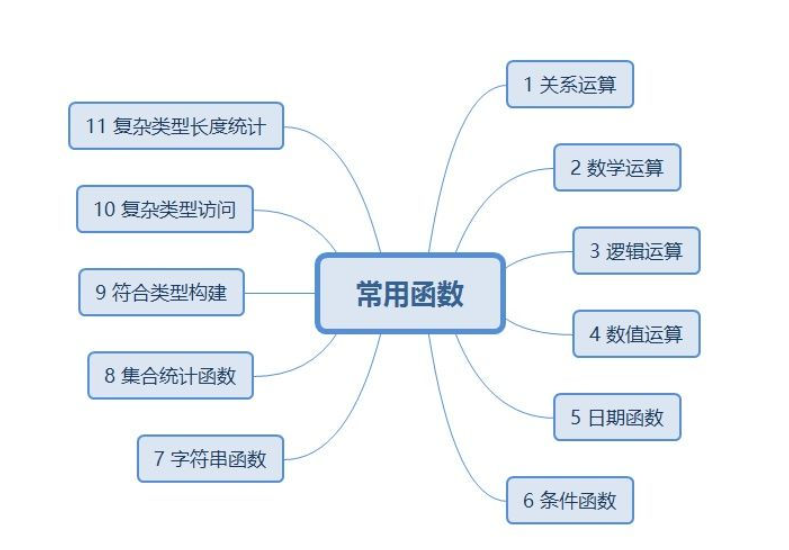
Relational operation
1. Equivalence comparison:=
Syntax: A=B
Operation type: all basic types
Description: TRUE if expression A is equal to expression B; Otherwise, FALSE
hive> select 1 from tableName where 1=1;
2. Unequal comparison: < >
Syntax: a < > b
Operation type: all basic types
Description: if expression A is NULL or expression B is NULL, NULL is returned; TRUE if expression A is not equal to expression B; Otherwise, FALSE
hive> select 1 from tableName where 1 <> 2;
3. Less than comparison:<
Syntax: a < B
Operation type: all basic types
Description: if expression A is NULL or expression B is NULL, NULL is returned; TRUE if expression A is less than expression B; Otherwise, FALSE
hive> select 1 from tableName where 1 < 2;
4. Less than or equal to comparison:<=
Syntax: a < = b
Operation type: all basic types
Description: if expression A is NULL or expression B is NULL, NULL is returned; TRUE if expression A is less than or equal to expression B; Otherwise, FALSE
hive> select 1 from tableName where 1 < = 1;
5. Greater than comparison: >
Syntax: a > b
Operation type: all basic types
Description: if expression A is NULL or expression B is NULL, NULL is returned; TRUE if expression A is greater than expression B; Otherwise, FALSE
hive> select 1 from tableName where 2 > 1;
6. Greater than or equal to comparison: >=
Syntax: a > = b
Operation type: all basic types
Description: if expression A is NULL or expression B is NULL, NULL is returned; TRUE if expression A is greater than or equal to expression B; Otherwise, FALSE
hive> select 1 from tableName where 1 >= 1; 1
Note: pay attention to the comparison of strings (common time comparisons can be made after to_date)
hive> select * from tableName; O 2011111209 00:00:00 2011111209 hive> select a, b, a<b, a>b, a=b from tableName; 2011111209 00:00:00 2011111209 false true false
7. Null value judgment: IS NULL
Syntax: A IS NULL
Operation type: all types
Description: TRUE if the value of expression A is NULL; Otherwise, FALSE
hive> select 1 from tableName where null is null;
8. Non null judgment: IS NOT NULL
Syntax: A IS NOT NULL
Operation type: all types
Description: FALSE if the value of expression A is NULL; Otherwise, TRUE
hive> select 1 from tableName where 1 is not null;
9. LIKE comparison: LIKE
Syntax: A LIKE B
Operation type: strings
Description: if string A or string B is NULL, NULL is returned; TRUE if string A conforms to the regular syntax of expression B; Otherwise, it is FALSE. Character "" in B Represents any single character, while the character '%' represents any number of characters.
hive> select 1 from tableName where 'football' like 'foot____'; <strong>Note: negative comparison is used NOT A LIKE B</strong> hive> select 1 from tableName where NOT 'football' like 'fff%';
10. LIKE operation in JAVA: RLIKE
Syntax: A RLIKE B
Operation type: strings
Description: if string A or string B is NULL, NULL is returned; TRUE if string A conforms to the regular syntax of JAVA regular expression B; Otherwise, it is FALSE.
hive> select 1 from tableName where 'footbar' rlike '^f.*r$'; 1
Note: judge whether a string is all numbers:
hive>select 1 from tableName where '123456' rlike '^\\d+$'; 1 hive> select 1 from tableName where '123456aa' rlike '^\\d+$';
11. REGEXP operation: REGEXP
Syntax: A REGEXP B
Operation type: strings
Description: the function is the same as RLIKE
hive> select 1 from tableName where 'footbar' REGEXP '^f.*r$'; 1
Mathematical operation:
1. Addition operation:+
Syntax: A + B
Operation type: all numeric types
Description: returns the result of adding a and B. The value type of the result is equal to the minimum parent type of type A and type B (see the inheritance relationship of data types for details). For example, the general result of int + int is of type int, while the general result of int + double is of type double
hive> select 1 + 9 from tableName; 10 hive> create table tableName as select 1 + 1.2 from tableName; hive> describe tableName; _c0 double
2. Subtraction operation:-
Syntax: A – B
Operation type: all numeric types
Description: returns the result of subtracting a from B. The value type of the result is equal to the minimum parent type of type A and type B (see the inheritance relationship of data types for details). For example, the general result of int – int is of type int, while the general result of int – double is of type double
hive> select 10 – 5 from tableName; 5 hive> create table tableName as select 5.6 – 4 from tableName; hive> describe tableName; _c0 double
3. Multiplication operation:*
Syntax: A * B
Operation type: all numeric types
Description: returns the result of multiplying a and B. The value type of the result is equal to the minimum parent type of type A and type B (see the inheritance relationship of data types for details). Note that if the result of a multiplied by B exceeds the value range of the default result type, you need to convert the result to a larger value type through cast
hive> select 40 * 5 from tableName; 200
4. Division operation:/
Syntax: A / B
Operation type: all numeric types
Description: returns the result of A divided by B. The numeric type of the result is double
hive> select 40 / 5 from tableName; 8.0
Note: the highest precision data type in hive is double, which is only accurate to 16 digits after the decimal point. Pay special attention to division
hive>select ceil(28.0/6.999999999999999999999) from tableName limit 1; 4 hive>select ceil(28.0/6.99999999999999) from tableName limit 1; 5
5. Remainder fetching operation:%
Syntax: a% B
Operation type: all numeric types
Description: returns the remainder of a divided by B. The value type of the result is equal to the minimum parent type of type A and type B (see the inheritance relationship of data types for details).
hive> select 41 % 5 from tableName; 1 hive> select 8.4 % 4 from tableName; 0.40000000000000036
Note: precision is a big problem in hive. For operations like this, it is best to specify the precision through round
hive> select round(8.4 % 4 , 2) from tableName; 0.4
6. Bit and operation:&
Syntax: A & B
Operation type: all numeric types
Description: returns the result of bitwise and operation of a and B. The value type of the result is equal to the minimum parent type of type A and type B (see the inheritance relationship of data types for details).
hive> select 4 & 8 from tableName; 0 hive> select 6 & 4 from tableName; 4
7. Bit or operation:|
Grammar: A | B
Operation type: all numeric types
Description: returns the result of a and B bitwise or operations. The value type of the result is equal to the minimum parent type of type A and type B (see the inheritance relationship of data types for details).
hive> select 4 | 8 from tableName; 12 hive> select 6 | 8 from tableName; 14
8. Bitwise exclusive or operation:^
Syntax: A ^ B
Operation type: all numeric types
Description: returns the result of bit-by-bit XOR operation of a and B. The value type of the result is equal to the minimum parent type of type A and type B (see the inheritance relationship of data types for details).
hive> select 4 ^ 8 from tableName; 12 hive> select 6 ^ 4 from tableName; 2
9. Bit reversal operation:~
Syntax: ~ A
Operation type: all numeric types
Description: returns the result of a bitwise inversion operation. The numeric type of the result is equal to the type of A.
hive> select ~6 from tableName; -7 hive> select ~4 from tableName; -5
Logical operation:
1. Logic AND operation: AND
Syntax: A AND B
Operation type: boolean
Note: TRUE if both A and B are TRUE; Otherwise, it is FALSE. NULL if A is NULL or B is NULL
hive> select 1 from tableName where 1=1 and 2=2; 1
2. Logical OR operation: OR
Syntax: A OR B
Operation type: boSsolean
Note: TRUE if A is TRUE, B is TRUE, or both A and B are TRUE; Otherwise, FALSE
hive> select 1 from tableName where 1=2 or 2=2; 1
3. Logical non operation: NOT
Syntax: NOT A
Operation type: boolean
Note: TRUE if A is FALSE or A is NULL; Otherwise, FALSE
hive> select 1 from tableName where not 1=2; 1
numerical calculation
1. Rounding function: round***
Syntax: round(double a)
Return value: BIGINT
Description: returns the integer value part of double type (follow rounding)
hive> select round(3.1415926) from tableName; 3 hive> select round(3.5) from tableName; 4 hive> create table tableName as select round(9542.158) from tableName; hive> describe tableName; _c0 bigint
2. Specify precision rounding function: round***
Syntax: round(double a, int d)
Return value: DOUBLE
Description: returns the double type of the specified precision d
hive> select round(3.1415926,4) from tableName; 3.1416
3. Rounding down function: floor***
Syntax: floor(double a)
Return value: BIGINT
Description: returns the maximum integer equal to or less than the double variable
hive> select floor(3.1415926) from tableName; 3 hive> select floor(25) from tableName; 25
4. Rounding up function: ceil***
Syntax: ceil(double a)
Return value: BIGINT
Description: returns the smallest integer equal to or greater than the double variable
hive> select ceil(3.1415926) from tableName; 4 hive> select ceil(46) from tableName; 46
5. Rounding up function: ceiling***
Syntax: ceiling(double a)
Return value: BIGINT
Note: it has the same function as ceil
hive> select ceiling(3.1415926) from tableName; 4 hive> select ceiling(46) from tableName; 46
6. Random number function: rand***
Syntax: rand(),rand(int seed)
Return value: double
Description: returns a random number in the range of 0 to 1. If seed is specified, it will wait for a stable sequence of random numbers
hive> select rand() from tableName; 0.5577432776034763 hive> select rand() from tableName; 0.6638336467363424 hive> select rand(100) from tableName; 0.7220096548596434 hive> select rand(100) from tableName; 0.7220096548596434
7. Natural exponential function: exp
Syntax: exp(double a)
Return value: double
Description: returns the natural logarithm e to the power of a
hive> select exp(2) from tableName; 7.38905609893065
Natural logarithm function: ln
Syntax: ln(double a)
Return value: double
Description: returns the natural logarithm of a
1
hive> select ln(7.38905609893065) from tableName; 2.0
8. Base 10 logarithm function: log10
Syntax: log10(double a)
Return value: double
Description: returns the logarithm of a based on 10
hive> select log10(100) from tableName; 2.0
9. Base 2 logarithmic function: log2
Syntax: log2(double a)
Return value: double
Description: returns the logarithm of a based on 2
hive> select log2(8) from tableName; 3.0
10. Log function: log
Syntax: log(double base, double a)
Return value: double
Description: returns the logarithm of a based on base
hive> select log(4,256) from tableName; 4.0
11. Power operation function: pow
Syntax: pow(double a, double p)
Return value: double
Description: returns the p-power of a
hive> select pow(2,4) from tableName; 16.0
12. power operation function: power
Syntax: power(double a, double p)
Return value: double
Description: returns the p-power of a, the same function as pow
hive> select power(2,4) from tableName; 16.0
13. Square function: sqrt
Syntax: sqrt(double a)
Return value: double
Description: returns the square root of a
hive> select sqrt(16) from tableName; 4.0
14. Binary function: bin
Syntax: bin(BIGINT a)
Return value: string
Description: returns the binary code representation of a
hive> select bin(7) from tableName; 111
15. Hex function: hex
Syntax: hex(BIGINT a)
Return value: string
Note: if the variable is of type int, the hexadecimal representation of a is returned; If the variable is of type string, the hexadecimal representation of the string is returned
hive> select hex(17) from tableName;
11
hive> select hex('abc') from tableName;
616263
16. Reverse hex function: unhex
Syntax: unhex(string a)
Return value: string
Description: returns the string of the hexadecimal string code
hive> select unhex('616263') from tableName;
abc
hive> select unhex('11') from tableName;
\-
hive> select unhex(616263) from tableName;
abc
17. Binary conversion function: conv
Syntax: conv(BIGINT num, int from_base, int to_base)
Return value: string
Note: change the value num from from_base to_base system
hive> select conv(17,10,16) from tableName; 11 hive> select conv(17,10,2) from tableName; 10001
18. Absolute value function: abs
Syntax: abs(double a) abs(int a)
Return value: double int
Description: returns the absolute value of the value a
hive> select abs(-3.9) from tableName; 3.9 hive> select abs(10.9) from tableName; 10.9
19. Positive remainder function: pmod
Syntax: pmod(int a, int b),pmod(double a, double b)
Return value: int double
Description: returns the remainder of positive a divided by b
hive> select pmod(9,4) from tableName; 1 hive> select pmod(-9,4) from tableName; 3
20. Sine function: sin
Syntax: sin(double a)
Return value: double
Description: returns the sine of a
hive> select sin(0.8) from tableName; 0.7173560908995228
21. Inverse sine function: asin
Syntax: asin(double a)
Return value: double
Description: returns the arcsine value of a
hive> select asin(0.7173560908995228) from tableName; 0.8
22. Cosine function: cos
Syntax: cos(double a)
Return value: double
Description: returns the cosine value of a
hive> select cos(0.9) from tableName; 0.6216099682706644
23. Inverse cosine function: acos
Syntax: acos(double a)
Return value: double
Description: returns the inverse cosine of a
hive> select acos(0.6216099682706644) from tableName; 0.9
24. Positive function: positive
Syntax: positive(int a), positive(double a)
Return value: int double
Description: returns a
hive> select positive(-10) from tableName; -10 hive> select positive(12) from tableName; 12
25. Negative function: negative
Syntax: negative(int a), negative(double a)
Return value: int double
Description: Return - a
hive> select negative(-5) from tableName; 5 hive> select negative(8) from tableName; -8
Date function
1. UNIX timestamp to date function: from_unixtime ***
Syntax: from_unixtime(bigint unixtime[, string format])
Return value: string
Note: convert the UNIX timestamp (from 1970-01-01 00:00:00 UTC to the number of seconds of the specified time) to the time format of the current time zone
hive> select from_unixtime(1323308943,'yyyyMMdd') from tableName; 20111208
2. Get current UNIX timestamp function: unix_timestamp ***
Syntax: unix_timestamp()
Return value: bigint
Description: get the UNIX timestamp of the current time zone
hive> select unix_timestamp() from tableName; 1323309615
3. Date to UNIX timestamp function: unix_timestamp ***
Syntax: unix_timestamp(string date)
Return value: bigint
Description: convert the date in the format "yyyy MM DD HH: mm: SS" to UNIX timestamp. If the conversion fails, 0 is returned.
hive> select unix_timestamp('2011-12-07 13:01:03') from tableName;
1323234063
4. Specified format date to UNIX timestamp function: unix_timestamp ***
Syntax: unix_timestamp(string date, string pattern)
Return value: bigint
Description: convert the date in pattern format to UNIX timestamp. If the conversion fails, 0 is returned.
hive> select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss') from tableName;
1323234063
5. Date time to date function: to_date ***
Syntax: to_date(string timestamp)
Return value: string
Description: returns the date part of the date time field.
hive> select to_date('2011-12-08 10:03:01') from tableName;
2011-12-08
6. Date to year function: year***
Syntax: year(string date)
Return value: int
Description: returns the year in the date.
hive> select year('2011-12-08 10:03:01') from tableName;
2011
hive> select year('2012-12-08') from tableName;
2012
7. Date to month function: month***
Syntax: month (string date)
Return value: int
Description: returns the month in the date.
hive> select month('2011-12-08 10:03:01') from tableName;
12
hive> select month('2011-08-08') from tableName;
8
8. Date conversion function: day****
Syntax: day (string date)
Return value: int
Description: returns the days in the date.
hive> select day('2011-12-08 10:03:01') from tableName;
8
hive> select day('2011-12-24') from tableName;
24
9. Date to hour function: hour***
Syntax: hour (string date)
Return value: int
Description: returns the hour in the date.
hive> select hour('2011-12-08 10:03:01') from tableName;
10
10. Date to minute function: minute
Syntax: minute (string date)
Return value: int
Description: returns the minute in the date.
hive> select minute('2011-12-08 10:03:01') from tableName;
3
11. Date to second function: Second
Syntax: second (string date)
Return value: int
Description: returns the second in the date.
hive> select second('2011-12-08 10:03:01') from tableName;
1
12. Date to week function: weekofyear
Syntax: weekofyear (string date)
Return value: int
Description: returns the number of weeks the date is in the current.
hive> select weekofyear('2011-12-08 10:03:01') from tableName;
49
13. Date comparison function: datediff***
Syntax: datediff(string enddate, string startdate)
Return value: int
Description: returns the number of days from the end date minus the start date.
hive> select datediff('2012-12-08','2012-05-09') from tableName;
213
14. Date addition function: date_add ***
Syntax: date_add(string startdate, int days)
Return value: string
Description: returns the start date. startdate is the date after days is added.
hive> select date_add('2012-12-08',10) from tableName;
2012-12-18
15. Date reduction function: date_sub ***
Syntax: date_sub (string startdate, int days)
Return value: string
Description: returns the date after the start date is reduced by days.
hive> select date_sub('2012-12-08',10) from tableName;
2012-11-28
Conditional function
1. If function: if***
Syntax: if (Boolean TestCondition, t ValueTrue, t valuefalse or null)
Return value: T
Description: when the condition testCondition is TRUE, valueTrue is returned; Otherwise, valuefalse ornull is returned
hive> select if(1=2,100,200) from tableName; 200 hive> select if(1=1,100,200) from tableName; 100
2. Non empty lookup function: COALESCE
Syntax: COALESCE(T v1, T v2,...)
Return value: T
Description: returns the first non null value in the parameter; Returns NULL if all values are null
hive> select COALESCE(null,'100','50') from tableName; 100
3. Conditional judgment function: CASE***
Syntax: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
Return value: T
Note: if a equals b, c is returned; If a equals d, then e is returned; Otherwise, return f
hive> Select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end from tableName; mary hive> Select case 200 when 50 then 'tom' when 100 then 'mary' else 'tim' end from tableName; tim
4. Conditional judgment function: CASE****
Syntax: CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
Return value: T
Note: if a is TRUE, b is returned; If c is TRUE, d is returned; Otherwise, return e
hive> select case when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end from tableName; mary hive> select case when 1=1 then 'tom' when 2=2 then 'mary' else 'tim' end from tableName; tom
String function
1. String length function: length
Syntax: length(string A)
Return value: int
Description: returns the length of string A
hive> select length('abcedfg') from tableName;
7
2. String inversion function: reverse
Syntax: reverse(string A)
Return value: string
Description: returns the inversion result of string A
hive> select reverse('abcedfg') from tableName;
gfdecba
3. String concatenation function: concat***
Syntax: concat(string A, string B...)
Return value: string
Description: returns the result of input string connection. Any input string is supported
hive> select concat('abc','def','gh') from tableName;
abcdefgh
4. Delimited string concatenation function: concat_ws ***
Syntax: concat_ws(string SEP, string A, string B…)
Return value: string
Description: returns the result of the input string connection. SEP represents the separator between each string
hive> select concat_ws(',','abc','def','gh')from tableName;
abc,def,gh
5. String interception function: substr,substring****
Syntax: substr(string A, int start),substring(string A, int start)
Return value: string
Description: returns the string from the start position to the end of string A
hive> select substr('abcde',3) from tableName;
cde
hive> select substring('abcde',3) from tableName;
cde
hive> select substr('abcde',-1) from tableName; (and ORACLE Same)
e
6. String interception function: substr,substring****
Syntax: substr(string A, int start, int len),substring(string A, int start, int len)
Return value: string
Description: returns the string A with the length of len starting from the start position
hive> select substr('abcde',3,2) from tableName;
cd
hive> select substring('abcde',3,2) from tableName;
cd
hive>select substring('abcde',-2,2) from tableName;
de
7. String to uppercase function: upper,ucase****
Syntax: upper(string A) ucase(string A)
Return value: string
Description: returns the uppercase format of string A
hive> select upper('abSEd') from tableName;
ABSED
hive> select ucase('abSEd') from tableName;
ABSED
8. String to lowercase function: lower,lcase***
Syntax: lower(string A) lcase(string A)
Return value: string
Description: returns the lowercase format of string A
hive> select lower('abSEd') from tableName;
absed
hive> select lcase('abSEd') from tableName;
absed
9. De whitespace function: trim***
Syntax: trim(string A)
Return value: string
Description: remove the spaces on both sides of the string
hive> select trim(' abc ') from tableName;
abc
10. Left space function: ltrim
Syntax: ltrim(string A)
Return value: string
Description: remove the space to the left of the string
hive> select ltrim(' abc ') from tableName;
abc
11. Function to remove space on the right: rtrim
Syntax: rtrim(string A)
Return value: string
Description: remove the space on the right of the string
hive> select rtrim(' abc ') from tableName;
abc
12. Regular expression replacement function: regexp_replace
Syntax: regexp_replace(string A, string B, string C)
Return value: string
Description: replace the part of string A that conforms to java regular expression B with C. Note that in some cases, escape characters are used, similar to regexp in oracle_ Replace function.
hive> select regexp_replace('foobar', 'oo|ar', '') from tableName;
fb
13. Regular expression parsing function: regexp_extract
Syntax: regexp_extract(string subject, string pattern, int index)
Return value: string
Description: split the string subject according to the rules of pattern regular expression and return the characters specified by index.
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 1) from tableName;
the
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 2) from tableName;
bar
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 0) from tableName;
foothebar
strong>Note that in some cases, the escape character should be used, and the following equal sign should be escaped with a double vertical line, which is java Rules for regular expressions.
select data_field,
regexp_extract(data_field,'.*?bgStart\\=([^&]+)',1) as aaa,
regexp_extract(data_field,'.*?contentLoaded_headStart\\=([^&]+)',1) as bbb,
regexp_extract(data_field,'.*?AppLoad2Req\\=([^&]+)',1) as ccc
from pt_nginx_loginlog_st
where pt = '2012-03-26' limit 2;
14. URL parsing function: parse_url ****
Syntax: parse_url(string urlString, string partToExtract [, string keyToExtract])
Return value: string
Description: returns the part specified in the URL. Valid values of partToExtract are: HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO
hive> select parse_url
('[https://www.tableName.com/path1/p.php?k1=v1&k2=v2](https://link.zhihu.com/?target=https%3A//www.iteblog.com/path1/p.php%3Fk1%3Dv1%26k2%3Dv2)#Ref1', 'HOST')
from tableName;
[http://www.tableName.com](https://link.zhihu.com/?target=http%3A//www.tableName.com)
hive> select parse_url
('[https://www.tableName.com/path1/p.php?k1=v1&k2=v2](https://link.zhihu.com/?target=https%3A//www.iteblog.com/path1/p.php%3Fk1%3Dv1%26k2%3Dv2)#Ref1', 'QUERY', 'k1')
from tableName;
v1
15. JSON parsing function: get_json_object ****
Syntax: get_json_object(string json_string, string path)
Return value: string
Description: parse json string_ String to return the content specified by path. NULL is returned if the json string entered is invalid.
hive> select get_json_object('{"store":{"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} },"email":"amy@only_for_json_udf_test.net","owner":"amy"}','$.owner') from tableName;
16. space string function: space
Syntax: space(int n)
Return value: string
Description: returns a string of length n
hive> select space(10) from tableName; hive> select length(space(10)) from tableName; 10
17. Repeat string function: repeat***
Syntax: repeat(string str, int n)
Return value: string
Description: returns the str string after n repetitions
hive> select repeat('abc',5) from tableName;
abcabcabcabcabc
18. First character function: ascii
Syntax: ascii(string str)
Return value: int
Description: returns the ascii code of the first character of string str
hive> select ascii('abcde') from tableName;
97
19. Left complement function: lpad
Syntax: lpad(string str, int len, string pad)
Return value: string
Note: the str is left complemented to the len bit with pad
hive> select lpad('abc',10,'td') from tableName;
tdtdtdtabc
Note: and GP,ORACLE Different, pad Cannot default
20. Right complement function: rpad
Syntax: rpad(string str, int len, string pad)
Return value: string
Note: right complement str to len bit with pad
hive> select rpad('abc',10,'td') from tableName;
abctdtdtdt
21. Split string function: split****
Syntax: split(string str, string pat)
Return value: array
Note: if str is split according to pat string, the split string array will be returned
hive> select split('abtcdtef','t') from tableName;
["ab","cd","ef"]
22. Set lookup function: find_in_set
Syntax: find_in_set(string str, string strList)
Return value: int
Description: returns the first occurrence of STR in strlist. Strlist is a comma separated string. If the str character is not found, 0 is returned
hive> select find_in_set('ab','ef,ab,de') from tableName;
2
hive> select find_in_set('at','ef,ab,de') from tableName;
0
Set statistical function
1. Number statistics function: count***
Syntax: count(), count(expr), count(DISTINCT expr[, expr_.])
Return value: int
Note: count() counts the number of retrieved rows, including NULL rows; count(expr) returns the number of non NULL values of the specified field; count(DISTINCT expr[, expr_.]) returns the number of different non NULL values of the specified field
hive> select count(*) from tableName; 20 hive> select count(distinct t) from tableName; 10
2. sum statistics function: sum***
Syntax: sum(col), sum(DISTINCT col)
Return value: double
Note: sum(col) is the result of adding col in the statistical result set; sum(DISTINCT col) is the result of the addition of different col values in the statistical results
hive> select sum(t) from tableName; 100 hive> select sum(distinct t) from tableName; 70
3. Average statistical function: avg***
Syntax: avg(col), avg(DISTINCT col)
Return value: double
Note: avg(col) is the average value of col in the statistical result set; avg(DISTINCT col) is the average value of the addition of different col values in the statistical results
hive> select avg(t) from tableName; 50 hive> select avg (distinct t) from tableName; 30
4. Minimum statistical function: min***
Syntax: min(col)
Return value: double
Description: the minimum value of col field in the statistics result set
hive> select min(t) from tableName; 20
5. Maximum statistical function: max***
Syntax: maxcol)
Return value: double
Description: the maximum value of col field in the statistics result set
hive> select max(t) from tableName; 120
6. Non empty set population variable function: var_pop
Syntax: var_pop(col)
Return value: double
Description: the total variable of col non empty collection in the statistics result set (null is ignored)
7. Non empty set sample variable function: var_samp
Syntax: var_samp (col)
Return value: double
Note: the sample variable of col non empty set in the statistical result set (null is ignored)
8. Overall standard deviation function: stddev_pop
Syntax: stddev_pop(col)
Return value: double
Note: this function calculates the population standard deviation and returns the square root of the population variable, and its return value is the same as var_ The square root of pop function is the same
9. Sample standard deviation function: stddev_samp
Syntax: stddev_samp (col)
Return value: double
Note: this function calculates the sample standard deviation
10. Median function: percentile
Syntax: percentile(BIGINT col, p)
Return value: double
Note: for the accurate pth percentile, p must be between 0 and 1, but the col field currently only supports integers and does not support floating-point numbers
11. Median function: percentile
Syntax: percentile(BIGINT col, array(p1 [, p2]...))
Return value: array
Note: the function is similar to the above. After that, you can enter multiple percentiles. The return type is also array, where is the corresponding percentile.
select percentile(score,<0.2,0.4>) from tableName; Take 0.2,0.4 Location data
12. Approximate median function: percentile_approx
Syntax: percentile_approx(DOUBLE col, p [, B])
Return value: double
Note: for the pth percentile of approximation, p must be between 0 and 1. The return type is double, but the col field supports floating-point type. Parameter B controls the approximate accuracy of memory consumption. The larger B, the higher the accuracy of the result. The default is 10000. When the number of distinct values in col field is less than B, the result is the exact percentile
13. Approximate median function: percentile_approx
Syntax: percentile_approx(DOUBLE col, array(p1 [, p2]…) [, B])
Return value: array
Note: the function is similar to the above. After that, you can enter multiple percentiles. The return type is also array, where is the corresponding percentile.
14. Histogram: histogram_numeric
Syntax: histogram_numeric(col, b)
Return value: array < struct {'x', 'y'} >
Note: calculate the histogram information of col based on b.
hive> select histogram_numeric(100,5) from tableName;
[{"x":100.0,"y":1.0}
Composite type build operation
1. map type build: map****
Syntax: map (key1, value1, key2, value2,...)
Description: build the map type according to the entered key and value pairs
hive> Create table mapTable as select map('100','tom','200','mary') as t from tableName;
hive> describe mapTable;
t map<string ,string>
hive> select t from tableName;
{"100":"tom","200":"mary"}
2. Struct type construction: struct
Syntax: struct(val1, val2, val3,...)
Description: construct the struct type of the structure according to the input parameters
hive> create table struct_table as select struct('tom','mary','tim') as t from tableName;
hive> describe struct_table;
t struct<col1:string ,col2:string,col3:string>
hive> select t from tableName;
{"col1":"tom","col2":"mary","col3":"tim"}
3. Array type build: array
Syntax: array(val1, val2,...)
Description: build the array type according to the input parameters
hive> create table arr_table as select array("tom","mary","tim") as t from tableName;
hive> describe tableName;
t array<string>
hive> select t from tableName;
["tom","mary","tim"]
Complex type access operation****
1. array type access: A[n]
Syntax: A[n]
Operation type: A is array type and n is int type
Description: returns the nth variable value in array A. The starting index of the array is 0. For example, if A is an array type with values of ['foo', 'bar], then A[0] will return' foo 'and A[1] will return' bar '
hive> create table arr_table2 as select array("tom","mary","tim") as t
from tableName;
hive> select t[0],t[1] from arr_table2;
tom mary tim
2. map type access: M[key]
Syntax: M[key]
Operation type: M is the map type, and key is the key value in the map
Description: returns the value of the specified value in the map type M. For example, if M is a map type with values of {'f' - > 'foo', 'b' - > 'bar', 'all' - > 'foobar'}, then m ['all'] will return 'foobar'
hive> Create table map_table2 as select map('100','tom','200','mary') as t from tableName;
hive> select t['200'],t['100'] from map_table2;
mary tom
3. struct type access: S.x
Syntax: S.x
Operation type: S is struct type
Description: returns the x field in structure S. For example, for struct foobar {int foo, int bar}, foobar.foo returns the foo field in the struct
hive> create table str_table2 as select struct('tom','mary','tim') as t from tableName;
hive> describe tableName;
t struct<col1:string ,col2:string,col3:string>
hive> select t.col1,t.col3 from str_table2;
tom tim
Complex type length statistical function****
1.Map type length function: size (map < K. V >)
Syntax: size (map < K. V >)
Return value: int
Description: returns the length of the map type
hive> select size(t) from map_table2; 2
2.array type length function: size(Array)
Syntax: size(Array)
Return value: int
Description: returns the length of array type
hive> select size(t) from arr_table2; 4
3. Type conversion function***
Type conversion function: cast
Syntax: cast(expr as)
Return value: Expected "=" to follow "type"
Description: returns the converted data type
hive> select cast('1' as bigint) from tableName;
1
3. lateral view, expand, reflect and window functions in hive
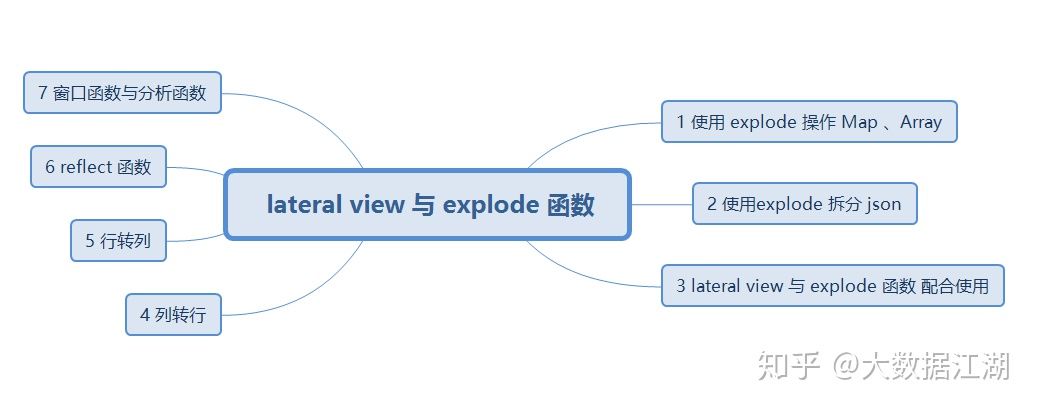
1. Use the expand function to split the Map and Array field data in the hive table
lateral view is used with split, expand and other udtfs. It can split a row of data into multiple rows of data. On this basis, it can aggregate the split data. lateral view first calls UDTF for each row of the original table. UDTF will split a row into one or more rows. lateral view combines the results to generate a virtual table supporting alias tables.
Expand can also be used to split the complex array or map structure in the hive column into multiple rows
Requirements: the data format is as follows
zhangsan child1,child2,child3,child4 k1:v1,k2:v2
lisi child5,child6,child7,child8 k3:v3,k4:v4
Fields are separated by \ t, and all child ren need to be split into one column
+----------+--+ | mychild | +----------+--+ | child1 | | child2 | | child3 | | child4 | | child5 | | child6 | | child7 | | child8 | +----------+--+
The key and value of the map are also disassembled to obtain the following results
+-----------+-------------+--+ | mymapkey | mymapvalue | +-----------+-------------+--+ | k1 | v1 | | k2 | v2 | | k3 | v3 | | k4 | v4 | +-----------+-------------+--+
Step 1: create hive database
Create hive database
hive (default)> create database hive_explode; hive (default)> use hive_explode;
Step 2: create the hive table, and then use expand to split the map and array
hive (hive_explode)> create table t3(name string,children array<string>,address Map<string,string>) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':' stored as textFile;
Step 3: load data
node03 Execute the following command to create a table data file mkdir -p /export/servers/hivedatas/ cd /export/servers/hivedatas/ vim maparray zhangsan child1,child2,child3,child4 k1:v1,k2:v2 lisi child5,child6,child7,child8 k3:v3,k4:v4
Load data in hive table
hive (hive_explode)> load data local inpath '/export/servers/hivedatas/maparray' into table t3;
Step 4: use explode to split the data in hive
Separate the data in the array
hive (hive_explode)> SELECT explode(children) AS myChild FROM t3;
Separate the data in the map
hive (hive_explode)> SELECT explode(address) AS (myMapKey, myMapValue) FROM t3;
2. Split json strings using explode
Requirements: some data formats are as follows:
a:shandong,b:beijing,c:hebei|1,2,3,4,5,6,7,8,9|[{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
Where the separator between fields is|
We need to parse all the monthSales corresponding to the following column (row to column)
4900
2090
6987
Step 1: create hive table
hive (hive_explode)> create table explode_lateral_view (`area` string, `goods_id` string, `sale_info` string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' STORED AS textfile;
Step 2: prepare data and load data
The prepared data are as follows
cd /export/servers/hivedatas
vim explode_json
a:shandong,b:beijing,c:hebei|1,2,3,4,5,6,7,8,9|[{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
Load the data into the hive table
hive (hive_explode)> load data local inpath '/export/servers/hivedatas/explode_json' overwrite into table explode_lateral_view;
Step 3: split the Array with explode
hive (hive_explode)> select explode(split(goods_id,',')) as goods_id from explode_lateral_view;
Step 4: use explode to disassemble the Map
hive (hive_explode)> select explode(split(area,',')) as area from explode_lateral_view;
Step 5: disassemble the json field
hive (hive_explode)> select explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{')) as sale_info from explode_lateral_view;
Then we want to use get_json_object to obtain the data whose key is monthSales:
hive (hive_explode)> select get_json_object(explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{')),'$.monthSales') as sale_info from explode_lateral_view;
Then the exception failed: semanticeexception [error 10081]: udtf's are not supported outside the select clause, nor needed in expressions
Udtf expand cannot be written in other functions
If you write this, you want to check two fields
select explode(split(area,',')) as area,good_id from explode_lateral_view;
Failed: semanticeexception 1:40 only a single expression in the select claim is supported with udtf's. error encoded near token 'good_id’
When using UDTF, only one field is supported. At this time, the final view is required
3. Use with final view
Query multiple fields with lateral view
hive (hive_explode)> select goods_id2,sale_info from explode_lateral_view LATERAL VIEW explode(split(goods_id,','))goods as goods_id2;
The final view expand (split (goods_id, ',', '')) goods is equivalent to a virtual table, which is the same as the original table expand_ lateral_ View Cartesian product association.
It can also be used multiple times
hive (hive_explode)> select goods_id2,sale_info,area2 from explode_lateral_view LATERAL VIEW explode(split(goods_id,','))goods as goods_id2 LATERAL VIEW explode(split(area,','))area as area2;It is also the result of the Cartesian product of three tables
Finally, we can completely convert a row of data in json format into a two-dimensional table through the following sentences
hive (hive_explode)> select get_json_object(concat('{',sale_info_1,'}'),'$.source') as source,
get_json_object(concat('{',sale_info_1,'}'),'$.monthSales') as monthSales,
get_json_object(concat('{',sale_info_1,'}'),'$.userCount') as monthSales,
get_json_object(concat('{',sale_info_1,'}'),'$.score') as monthSales from explode_lateral_view
LATERAL VIEW explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{'))sale_info as sale_info_1;
Summary:
Later view usually appears together with UDTF to solve the problem that UDTF does not allow in the select field.
Multiple Cartesian view can be implemented similar to Cartesian product.
Outer keyword can output the empty result of UDTF that is not output as NULL to prevent data loss.
4. Column to row
1. Description of related functions
CONCAT(string A/col, string B/col...): returns the result of connecting input strings. Any input string is supported;
CONCAT_WS(separator, str1, str2,...): it is a special form of CONCAT(). The separator between the first parameter and the remaining parameters. The delimiter can be the same string as the remaining parameters. If the delimiter is NULL, the return value will also be NULL. This function skips any NULL and empty strings after the delimiter parameter. The separator will be added between the connected strings;
COLLECT_SET(col): the function only accepts basic data types. Its main function is to de summarize the values of a field and generate an array type field.
2. Data preparation
Table 6-6 data preparation
name constellation blood_type Sun WuKong Aries A Lao Wang sagittarius A Song song Aries B Zhu Bajie Aries A Miss Luo Yu feng sagittarius A
3. Demand
Classify people with the same constellation and blood type. The results are as follows:
Sagittarius, A old Wang Fengjie
Aries, A monkey king, pig Bajie
Aries, B song
4. Create local constellation.txt and import data
The node03 server executes the following command to create a file. Note that the data is divided using \ t
cd /export/servers/hivedatas vim constellation.txt
Sun WuKong Aries A Lao Wang sagittarius A Song song Aries B Zhu Bajie Aries A Miss Luo Yu feng sagittarius A
5. Create hive table and import data
Create hive table and load data
hive (hive_explode)> create table person_info( name string, constellation string, blood_type string) row format delimited fields terminated by "\t";
Load data
hive (hive_explode)> load data local inpath '/export/servers/hivedatas/constellation.txt' into table person_info;
6. Query data as required
hive (hive_explode)> select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select
name,
concat(constellation, "," , blood_type) base
from
person_info) t1
group by
t1.base;
5. Row train
1. Function description
Expand (Col): split the complex array or map structure in the hive column into multiple rows.
LATERAL VIEW
Usage: final view udtf (expression) tablealias as columnalias
Explanation: used with split, expand and other udtfs. It can split a column of data into multiple rows of data. On this basis, it can aggregate the split data.
2. Data preparation
cd /export/servers/hivedatas vim movie.txt
Use \ t to split data fields
<Suspect tracking suspense,action,science fiction,plot <Lie to me> Suspense,gangster ,action,psychology,plot <War wolf 2 War,action,disaster
3. Demand
Expand the array data in the movie category. The results are as follows:
<Suspect tracking suspense <Suspect tracking action <Suspect tracking science fiction <Plot of suspect tracking <Lie to me> Suspense <Lie to me> gangster <Lie to me> action <Lie to me> psychology <Lie to me> plot <War wolf 2 War <Action of war wolf 2 <Wolf 2 disaster
4. Create hive table and import data
Create hive table
create table movie_info( movie string, category array<string>) row format delimited fields terminated by "\t" collection items terminated by ",";
Load data
load data local inpath "/export/servers/hivedatas/movie.txt" into table movie_info;
5. Query data as required
select movie, category_name from movie_info lateral view explode(category) table_tmp as category_name;
6. reflect function
The reflect function can support the calling function in java, and seckill all udf functions in sql.
Use Max in java.lang.Math to find the maximum value in the two columns
Create hive table
create table test_udf(col1 int,col2 int) row format delimited fields terminated by ',';
Prepare data and load data
cd /export/servers/hivedatas vim test_udf 1,2 4,3 6,4 7,5 5,6
Load data
hive (hive_explode)> load data local inpath '/export/servers/hivedatas/test_udf' overwrite into table test_udf;
Use Max in java.lang.Math to find the maximum value in the two columns
hive (hive_explode)> select reflect("java.lang.Math","max",col1,col2) from test_udf;
Different records execute different java built-in functions
Create hive table
hive (hive_explode)> create table test_udf2(class_name string,method_name string,col1 int , col2 int) row format delimited fields terminated by ',';
Prepare data
cd /export/servers/hivedatas vim test_udf2 java.lang.Math,min,1,2 java.lang.Math,max,2,3
Load data
hive (hive_explode)> load data local inpath '/export/servers/hivedatas/test_udf2' overwrite into table test_udf2;
Execute query
hive (hive_explode)> select reflect(class_name,method_name,col1,col2) from test_udf2;
Judge whether it is a number
Using the functions in apache commons, the jar s under commons have been included in the classpath of hadoop, so they can be used directly.
The usage is as follows:
select reflect("org.apache.commons.lang.math.NumberUtils","isNumber","123");
7. Window function and analysis function
hive also has many window functions and analysis functions, which are mainly used in the following scenarios
(1) Used for partition sorting
(2) Dynamic Group By
(3)Top N
(4) Cumulative calculation
(5) Hierarchical query
1. Create hive table and load data
Create table
hive (hive_explode)> create table order_detail( user_id string,device_id string,user_type string,price double,sales int )row format delimited fields terminated by ',';
Load data
cd /export/servers/hivedatas vim order_detail zhangsan,1,new,67.1,2 lisi,2,old,43.32,1 wagner,3,new,88.88,3 liliu,4,new,66.0,1 qiuba,5,new,54.32,1 wangshi,6,old,77.77,2 liwei,7,old,88.44,3 wutong,8,new,56.55,6 lilisi,9,new,88.88,5 qishili,10,new,66.66,5
Load data
hive (hive_explode)> load data local inpath '/export/servers/hivedatas/order_detail' into table order_detail;
2. Window function
FIRST_VALUE: the first value after sorting in the group up to the current line
LAST_VALUE: the last value until the current row after sorting in the group
LEAD(col,n,DEFAULT): used to count the value of the nth row down in the window. The first parameter is the column name, the second parameter is the next nth row (optional, the default is 1), and the third parameter is the default value (when the next nth row is NULL, the default value is taken, or NULL if not specified)
LAG(col,n,DEFAULT): opposite to lead, it is used to count the value of the nth row up in the window. The first parameter is the column name, the second parameter is the nth row up (optional, the default is 1), and the third parameter is the default value (the default value is taken when the nth row up is NULL, or NULL if it is not specified)
3. OVER clause
1. Use the standard aggregate functions COUNT, SUM, MIN, MAX, AVG
2. Use the PARTITION BY statement to use one or more columns of the original data type
3. Use the PARTITION BY and ORDER BY statements to use one or more data types for partitioning or sorting
4. Use the window specification, which supports the following formats:
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING) (ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING) (ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING 1 2 3
When the window clause condition is missing after ORDER BY, the window specification defaults to range between unbounded prediction and current row
When both ORDER BY and window clauses are missing, the window specification defaults to row between unbounded forecasting and unbounded following
The OVER clause supports the following functions, but they are not supported with windows.
Ranking functions: Rank, NTile, DenseRank, CumeDist, PercentRank
Lead and Lag functions
Use the window function to calculate the sales volume
Use the window function sum over to count sales
hive (hive_explode)> select user_id, user_type, sales, --All rows in the group sum(sales) over(partition by user_type) AS sales_1 , sum(sales) over(order by user_type) AS sales_2 , --The default is from the starting point to the current row, if sales Same, the accumulation result is the same sum(sales) over(partition by user_type order by sales asc) AS sales_3, --From the starting point to the current line, the result is the same as sales_3 Different. According to the sorting order, the results may accumulate differently sum(sales) over(partition by user_type order by sales asc rows between unbounded preceding and current row) AS sales_4, --Current row+3 lines ahead sum(sales) over(partition by user_type order by sales asc rows between 3 preceding and current row) AS sales_5, --Current row+3 lines ahead+1 line back sum(sales) over(partition by user_type order by sales asc rows between 3 preceding and 1 following) AS sales_6, --Current row+All lines back sum(sales) over(partition by user_type order by sales asc rows between current row and unbounded following) AS sales_7 from order_detail order by user_type, sales, user_id;
After statistics, the results are as follows:
+-----------+------------+--------+----------+----------+----------+----------+----------+----------+----------+--+ | user_id | user_type | sales | sales_1 | sales_2 | sales_3 | sales_4 | sales_5 | sales_6 | sales_7 | +-----------+------------+--------+----------+----------+----------+----------+----------+----------+----------+--+ | liliu | new | 1 | 23 | 23 | 2 | 2 | 2 | 4 | 22 | | qiuba | new | 1 | 23 | 23 | 2 | 1 | 1 | 2 | 23 | | zhangsan | new | 2 | 23 | 23 | 4 | 4 | 4 | 7 | 21 | | wagner | new | 3 | 23 | 23 | 7 | 7 | 7 | 12 | 19 | | lilisi | new | 5 | 23 | 23 | 17 | 17 | 15 | 21 | 11 | | qishili | new | 5 | 23 | 23 | 17 | 12 | 11 | 16 | 16 | | wutong | new | 6 | 23 | 23 | 23 | 23 | 19 | 19 | 6 | | lisi | old | 1 | 6 | 29 | 1 | 1 | 1 | 3 | 6 | | wangshi | old | 2 | 6 | 29 | 3 | 3 | 3 | 6 | 5 | | liwei | old | 3 | 6 | 29 | 6 | 6 | 6 | 6 | 3 | +-----------+------------+--------+----------+----------+----------+----------+----------+----------+----------+--+
be careful:
The result is related to ORDER BY, which is ascending by default
If ROWS BETWEEN is not specified, the default is from the starting point to the current row;
If ORDER BY is not specified, all values in the group will be accumulated;
The key is to understand the meaning of ROWS BETWEEN, also known as the WINDOW clause:
Predicting: forward
FOLLOWING: back
CURRENT ROW: CURRENT ROW
UNBOUNDED: UNBOUNDED (start or end)
Unbounded forecasting: indicates the starting point from the front
UNBOUNDED FOLLOWING: indicates to the following end point
The usage of other COUNT, AVG, MIN, MAX and SUM is the same.
Find the first and last values after grouping first_value and last_value
Use first_value and last_value find the first and last values after grouping
select user_id, user_type, ROW_NUMBER() OVER(PARTITION BY user_type ORDER BY sales) AS row_num, first_value(user_id) over (partition by user_type order by sales desc) as max_sales_user, first_value(user_id) over (partition by user_type order by sales asc) as min_sales_user, last_value(user_id) over (partition by user_type order by sales desc) as curr_last_min_user, last_value(user_id) over (partition by user_type order by sales asc) as curr_last_max_user from order_detail; +-----------+------------+----------+-----------------+-----------------+---------------------+---------------------+--+ | user_id | user_type | row_num | max_sales_user | min_sales_user | curr_last_min_user | curr_last_max_user | +-----------+------------+----------+-----------------+-----------------+---------------------+---------------------+--+ | wutong | new | 7 | wutong | qiuba | wutong | wutong | | lilisi | new | 6 | wutong | qiuba | qishili | lilisi | | qishili | new | 5 | wutong | qiuba | qishili | lilisi | | wagner | new | 4 | wutong | qiuba | wagner | wagner | | zhangsan | new | 3 | wutong | qiuba | zhangsan | zhangsan | | liliu | new | 2 | wutong | qiuba | qiuba | liliu | | qiuba | new | 1 | wutong | qiuba | qiuba | liliu | | liwei | old | 3 | liwei | lisi | liwei | liwei | | wangshi | old | 2 | liwei | lisi | wangshi | wangshi | | lisi | old | 1 | liwei | lisi | lisi | lisi | +-----------+------------+----------+-----------------+-----------------+---------------------+---------------------+--+
4. Analysis function
1.ROW_NUMBER():
Starting from 1, the sequence of records in the group is generated in order. For example, the pv rank and row of each day in the group are generated in descending order of pv_ There are many application scenarios for number (). For example, get the records that rank first in the group; Get the first refer ence in a session.
2.RANK() :
Generate the ranking of data items in the group. Equal ranking will leave a vacancy in the ranking
3.DENSE_RANK() :
Generate the ranking of data items in the group. If the ranking is equal, there will be no vacancy in the ranking
4.CUME_DIST :
Rows less than or equal to the current value / total rows in the group. For example, count the proportion of the number of people whose salary is less than or equal to the current salary in the total number of people
5.PERCENT_RANK :
RANK value of current row in the group - 1 / total number of rows in the group - 1
6.NTILE(n) :
It is used to divide the grouped data into n slices in order and return the current slice value. If the slices are uneven, the distribution of the first slice is increased by default. NTILE does not support ROWS BETWEEN, such as NTILE (2) over (partition by cookie order by createtime ROWS BETWEEN 3 predicting and current row).
RANK,ROW_NUMBER,DENSE_ Use of rank over
Using these functions, you can find topN by grouping
Demand: sort by user type to get the top N data with the largest sales volume
select user_id,user_type,sales, RANK() over (partition by user_type order by sales desc) as r, ROW_NUMBER() over (partition by user_type order by sales desc) as rn, DENSE_RANK() over (partition by user_type order by sales desc) as dr from order_detail; +-----------+------------+--------+----+-----+-----+--+ | user_id | user_type | sales | r | rn | dr | +-----------+------------+--------+----+-----+-----+--+ | wutong | new | 6 | 1 | 1 | 1 | | qishili | new | 5 | 2 | 2 | 2 | | lilisi | new | 5 | 2 | 3 | 2 | | wagner | new | 3 | 4 | 4 | 3 | | zhangsan | new | 2 | 5 | 5 | 4 | | qiuba | new | 1 | 6 | 6 | 5 | | liliu | new | 1 | 6 | 7 | 5 | | liwei | old | 3 | 1 | 1 | 1 | | wangshi | old | 2 | 2 | 2 | 2 | | lisi | old | 1 | 3 | 3 | 3 | +-----------+------------+--------+----+-----+-----+--+
Use NTILE to calculate the percentage
We can use NTILE to divide our data into several parts, and then calculate the percentage
Slice data using NTILE
select user_type,sales, --Divide the data into 2 pieces in the group NTILE(2) OVER(PARTITION BY user_type ORDER BY sales) AS nt2, --Divide the data into 3 pieces in the group NTILE(3) OVER(PARTITION BY user_type ORDER BY sales) AS nt3, --Divide the data into 4 pieces within the group NTILE(4) OVER(PARTITION BY user_type ORDER BY sales) AS nt4, --Divide all data into 4 pieces NTILE(4) OVER(ORDER BY sales) AS all_nt4 from order_detail order by user_type, sales;
The results are as follows:
+------------+--------+------+------+------+----------+--+ | user_type | sales | nt2 | nt3 | nt4 | all_nt4 | +------------+--------+------+------+------+----------+--+ | new | 1 | 1 | 1 | 1 | 1 | | new | 1 | 1 | 1 | 1 | 1 | | new | 2 | 1 | 1 | 2 | 2 | | new | 3 | 1 | 2 | 2 | 3 | | new | 5 | 2 | 2 | 3 | 4 | | new | 5 | 2 | 3 | 3 | 3 | | new | 6 | 2 | 3 | 4 | 4 | | old | 1 | 1 | 1 | 1 | 1 | | old | 2 | 1 | 2 | 2 | 2 | | old | 3 | 2 | 3 | 3 | 2 | +------------+--------+------+------+------+----------+--+
Use NTILE to get the user id of the top 20% of sales
select user_id from (select user_id, NTILE(5) OVER(ORDER BY sales desc) AS nt from order_detail )A where nt=1; +----------+--+ | user_id | +----------+--+ | wutong | | qishili |
5. Enhanced aggregation Cube and Grouping and Rollup
These analysis functions are usually used in OLAP and cannot be accumulated. They need to be counted according to the indicators of drilling up and drilling down in different dimensions, such as the number of UV s per hour, day and month.
GROUPING SETS
In a GROUP BY query, aggregation based on different dimension combinations is equivalent to UNION ALL for GROUP BY result sets of different dimensions,
The group__ ID, indicating which grouping set the result belongs to.
Requirements: according to user_type and sales are grouped to obtain data respectively
0: jdbc:hive2://node03:10000>select user_type, sales, count(user_id) as pv, GROUPING__ID from order_detail group by user_type,sales GROUPING SETS(user_type,sales) ORDER BY GROUPING__ID;
The results are as follows:
+------------+--------+-----+---------------+--+ | user_type | sales | pv | grouping__id | +------------+--------+-----+---------------+--+ | old | NULL | 3 | 1 | | new | NULL | 7 | 1 | | NULL | 6 | 1 | 2 | | NULL | 5 | 2 | 2 | | NULL | 3 | 2 | 2 | | NULL | 2 | 2 | 2 | | NULL | 1 | 3 | 2 | +------------+--------+-----+---------------+--+
Requirements: according to user_type, sales, and user_type + salt are grouped separately to obtain statistical data
0: jdbc:hive2://node03:10000>select user_type, sales, count(user_id) as pv, GROUPING__ID from order_detail group by user_type,sales GROUPING SETS(user_type,sales,(user_type,sales)) ORDER BY GROUPING__ID;
The results are as follows:
+------------+--------+-----+---------------+--+ | user_type | sales | pv | grouping__id | +------------+--------+-----+---------------+--+ | old | NULL | 3 | 1 | | new | NULL | 7 | 1 | | NULL | 1 | 3 | 2 | | NULL | 6 | 1 | 2 | | NULL | 5 | 2 | 2 | | NULL | 3 | 2 | 2 | | NULL | 2 | 2 | 2 | | old | 3 | 1 | 3 | | old | 2 | 1 | 3 | | old | 1 | 1 | 3 | | new | 6 | 1 | 3 | | new | 5 | 2 | 3 | | new | 3 | 1 | 3 | | new | 1 | 2 | 3 | | new | 2 | 1 | 3 | +------------+--------+-----+---------------+--+
6. Use cube and ROLLUP to aggregate according to all combinations of dimensions of GROUP BY.
Aggregate cube s
Requirement: no grouping, by user_type, sales and user_type+sales to get statistics by grouping
0: jdbc:hive2://node03:10000>select user_type, sales, count(user_id) as pv, GROUPING__ID from order_detail group by user_type,sales WITH CUBE ORDER BY GROUPING__ID; +------------+--------+-----+---------------+--+ | user_type | sales | pv | grouping__id | +------------+--------+-----+---------------+--+ | NULL | NULL | 10 | 0 | | new | NULL | 7 | 1 | | old | NULL | 3 | 1 | | NULL | 6 | 1 | 2 | | NULL | 5 | 2 | 2 | | NULL | 3 | 2 | 2 | | NULL | 2 | 2 | 2 | | NULL | 1 | 3 | 2 | | old | 3 | 1 | 3 | | old | 2 | 1 | 3 | | old | 1 | 1 | 3 | | new | 6 | 1 | 3 | | new | 5 | 2 | 3 | | new | 3 | 1 | 3 | | new | 2 | 1 | 3 | | new | 1 | 2 | 3 | +------------+--------+-----+---------------+--+
ROLLUP for aggregation
rollup is a subset of CUBE, mainly the leftmost dimension, from which hierarchical aggregation is performed.
select user_type, sales, count(user_id) as pv, GROUPING__ID from order_detail group by user_type,sales WITH ROLLUP ORDER BY GROUPING__ID; +------------+--------+-----+---------------+--+ | user_type | sales | pv | grouping__id | +------------+--------+-----+---------------+--+ | NULL | NULL | 10 | 0 | | old | NULL | 3 | 1 | | new | NULL | 7 | 1 | | old | 3 | 1 | 3 | | old | 2 | 1 | 3 | | old | 1 | 1 | 3 | | new | 6 | 1 | 3 | | new | 5 | 2 | 3 | | new | 3 | 1 | 3 | | new | 2 | 1 | 3 | | new | 1 | 2 | 3 | +------------+--------+-----+---------------+--+
4. Custom functions for hive
1. Hive custom function
1) Hive comes with some functions, such as max/min, but the number is limited. You can easily expand it by customizing UDF.
2) When the built-in function provided by Hive cannot meet your business processing needs, you can consider using user-defined function (UDF).
3) There are three types of user-defined functions:
(1)UDF(User-Defined-Function)
One in and one out
(2)UDAF(User-Defined Aggregation Function)
Aggregate function, one more in and one out
Similar to: count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
One in and many out
Such as lateral view explore()
4) Official document address
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
5) Programming steps:
(1) Inherit org.apache.hadoop.hive.ql.UDF
(2) You need to implement the evaluate function; The evaluate function supports overloading;
6) Precautions
(1) UDF must have a return type, which can return null, but the return type cannot be void;
(2) Text/LongWritable and other types are commonly used in UDF, and java type is not recommended;