2021SC@SDUSC
Submit Differences
To facilitate user review and prepare for merge, you need to design an algorithm to count the differences between two submissions (branches). Before thinking about the specific flow of the algorithm, you need to summarize the types of differences.
Difference Type
If there are two commit commits, Parent, let's assume we consider the differences between Commits and Parents. That is, Commit is my submission and Parent is someone else's submission. Now you need to consider how my submission differs from others'submissions.
File Differences
| difference | Explain | Symbol |
|---|---|---|
| Add to | Commit added the file relative to Parent. | A |
| delete | Commit deleted the file relative to Parent. | D |
| modify | Commit added the file relative to Parent. | M |
| rename | Commit renamed the file relative to Parent and the contents have not been modified. | R |
Catalog differences
| difference | Explain | Symbol |
|---|---|---|
| Add to | Commit added the directory relative to Parent. | B |
| delete | Commit deleted the directory relative to Parent. | C |
| rename | Commit renamed the directory relative to Parent, and the link has not been modified. | E |
Unmerged differences
Special cases in the three-way difference.
| difference | Explain |
|---|---|
| STATUS_UNMERGED_NONE | Not merged |
| STATUS_UNMERGED_BOTH_CHANGED | Both are modified: the same file is modified to a different result |
| STATUS_UNMERGED_BOTH_ADDED | Both are added: both merges add the same file |
| STATUS_UNMERGED_I_REMOVED | One removes the file, the other modifies it |
| STATUS_UNMERGED_OTHERS_REMOVED | One modifies the file, the other removes the file |
| STATUS_UNMERGED_DFC_I_ADDED_FILE | One replaces the directory with a file, the other modifies the file in the directory |
| STATUS_UNMERGED_DFC_OTHERS_ADDED_FILE | One modifies the files in the directory and the other replaces the directory with a file |
(The purpose in actual use is unknown because no relevant implementation code has been found)
algorithm
Technological process
-
Homogeneous Recursion
The goal is to recursively traverse the parts of each file tree that have the same location. The pseudocode is as follows:
File tree isomorphic recursion ( Tree[s][n]: n A directory with the same location on the road file tree: Dirents[n]: n Catalog items with the same location on the road file tree While (1): Get isomorphic catalog items to Dirents If n Road Dirents Exactly the same: Return File Difference Processing ( Dirents) Catalog Difference Processing ( Dirents) File Difference Processing ( Dirents[n]: n Files with the same location on the road file tree: Get the corresponding Files,Then call the difference callback function Catalog Difference Processing ( Dirents[n]: n Files with the same location on the road file tree: Get the corresponding Dir,Then call the difference callback function File tree isomorphic recursion ( Dirs)
-
Homogeneous catalog items
It is important for isomorphic recursion to be able to achieve multichannel location isomorphism that you need to obtain isomorphic catalog items, which require some benchmarks. Returning to the nature of location isomorphism, it essentially requires that nodes have exactly the same path to the root. Consider searching for binary/multifork trees, because there are weights, so it is easy to find paths where nodes in multiple trees have exactly the same root weights. So what can you use as weights in a file tree? File/directory name.
We think that directory items with the same name are also positionally isomorphic in multi-location isomorphic directories. Based on this assumption, we can quickly devise an efficient and complex way to traverse isomorphisms. Consider sorting directory items by name (which is also the default when getting Seafdir), then we can use a similar merge sort method to get multiple identical directory items based on multiple pointers.
Of course, knowing the isomorphism alone is still not enough, because our purpose is to know the difference of isomorphism, so we need to use the difference algorithm further to get the difference.
Two way difference and three way difference
There are two different algorithms for generating submissions:
-
Two-way difference: Applies to normal submissions. Determine the difference between Commit and Parent. Non-differentiated content can be identified directly, while content needs to be judged for modification.
-
Three-way difference: Applies to merged submissions. Determine the difference between Commit and ParentA and ParentB. You can distinguish the addition or deletion of Commits relative to both. However, the modification still needs to be judged by the content.
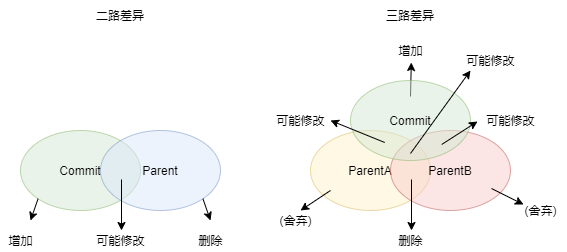
Neither the two-way nor the three-way differences tell whether the user renamed the file or directory, because in name-based location isomorphism, renaming is equivalent to adding after deletion. This will be handled in post-processing.
Postprocessing
-
Approximate judgment of rename
It is known that in name-based homogeneity, if a file is renamed, it may be judged both deleted and increased. So how do you restore the real state?
The answer is that you only need to find the same content, and if a delete-add pair exists under the same content, the directory or file is considered renamed.
Note that this is an approximation, and it is possible that the user really deletes and increases, but since we do not monitor the user's behavior, it is considered renamed.
-
Redundant empty directory
Another point where a bug occurs is in the empty directory. An empty directory is a special existence where all empty directories point to the same empty directory object because their contents are the same, so SHA1, the object name, is the same. Therefore, there are two cases where an empty directory can be misjudged:
- After adding files to an empty directory, it is determined that the empty directory has been deleted.
- When a directory is empty, it is determined that the empty directory is increased.
So how do you handle both cases? In fact, it is very simple to traverse through all directories with added or deleted states, then make a special judgment and correct the difference type.
Realization
-
Differential Objects
typedef struct DiffEntry { // Differential Objects char type; // Difference Type char status; // Difference status int unmerge_state; // Unmerged state unsigned char sha1[20]; // Used to resolve rename issues char *name; // Name char *new_name; // New name, used only for rename scenarios gint64 size; // Size gint64 origin_size; // Original size, used only to modify the situation } DiffEntry; -
Difference Comparison Options
typedef struct DiffOptions { // Comparison Options char store_id[37]; // Storage id int version; // seafile version // Two callbacks DiffFileCB file_cb; // File Difference Processing Callback DiffDirCB dir_cb; // Directory Difference Processing Callback void *data; // User parameters } DiffOptions;The directory and file callback functions need to be set when the structure is passed in to the difference comparison operation in use. Callback is the difference algorithm.
-
Difference comparison algorithm
- Homogeneous Location Recursion
static int // File Tree Homogeneous Recursion diff_trees_recursive (int n, SeafDir *trees[], const char *basedir, DiffOptions *opt); int // File Tree Differential Processing, Encapsulation diff_trees (int n, const char *roots[], DiffOptions *opt) static int // Catalog Difference Processing diff_directories (int n, SeafDirent *dents[], const char *basedir, DiffOptions *opt) static int // File Difference Processing diff_files (int n, SeafDirent *dents[], const char *basedir, DiffOptions *opt)- Difference algorithm
static int // Two-way File Difference Processing twoway_diff_files (int n, const char *basedir, SeafDirent *files[], void *vdata) static int // Two-way directory difference handling twoway_diff_dirs (int n, const char *basedir, SeafDirent *dirs[], void *vdata, gboolean *recurse) static int // Three-way File Differential Processing threeway_diff_files (int n, const char *basedir, SeafDirent *files[], void *vdata) static int // Three-way directory difference handling (default no operation) threeway_diff_dirs (int n, const char *basedir, SeafDirent *dirs[], void *vdata, gboolean *recurse)One of the little things worth mentioning is how to judge if the content is the same. This again reflects the benefits of the SHA1 Abstract naming: we only need to compare the IDs of two file system objects to directly determine if their contents are the same.
- Postprocessing
void // Resolve renaming issues diff_resolve_renames (GList **diff_entries) void // Solve the problem of redundant empty directories diff_resolve_empty_dirs (GList **diff_entries)
-
encapsulation
- General Submission
int // Compare differences between two submissions diff_commits (SeafCommit *commit1, SeafCommit *commit2, GList **results, // Results are recorded in the results list gboolean fold_dir_diff); int // Compare the differences between the two submissions; Given Root Directory diff_commit_roots (const char *store_id, int version, const char *root1, const char *root2, GList **results, gboolean fold_dir_diff);- Submit after merge
int // Compare differences before and after merging (compared with two parent submissions) diff_merge (SeafCommit *merge, GList **results, gboolean fold_dir_diff); int // Compare the differences before and after merging; Given Root Directory diff_merge_roots (const char *store_id, int version, const char *merged_root, const char *p1_root, const char *p2_root, GList **results, gboolean fold_dir_diff);
Branch Merge
Merger, Conflict and Resolution
Merging is an important means of combining multiple submissions (branches). A merged object is a merge of two submissions, but is generally considered a merge of branches because branches are required as a submission pointer. The nature of branch merging in the graph is that the degree equals two, that is, the generation of a submission is generated by two parent submissions and can carry incremental content.
Conflict resolution is the most important issue when merging two submissions (branches). Conflict judgments are actually similar to difference judgments, all made with the help of location homogeneity, and are not described here. The key issue here is how to determine and resolve conflicts. Conflicts are sensitive to users, who need to choose which content to put in a new version by comparing it. Conflicts can also be user-defined, and all non-identical content can be conflicts.
There are two solutions: the first is two-way merger, the second is three-way merge.
Two-way merge is very simple, only the same content is retained, deletion, addition and modification are all left to the user's choice. Because it is entirely impossible to decide whether to keep or discard the non-identical contents of the two paths. This is easy to do, but cumbersome for users, but it's very safe because the conflicting choices are entirely left to the users and can be completely user-defined.
The three-way merge has some autonomy. It introduces Base, the common ancestor of the two branches, and then uses Base to decide whether to keep the content or leave it to the user. This improves efficiency, but is not necessarily insured, because conflicts between algorithm definitions may not be user-defined.
Three-way merger
The merged participants consist of three branches, Base, Head, Remote. Our goal is to merge Head and Remote, and Base is their common ancestor.
After the introduction of Base, all the differences have criteria to judge. The algorithm considers that changes (including additions and deletions) that do not cross between the two branches relative to their ancestors are preserved, while cross-changes are conflicting. Such a conflict definition actually fits most situations and further narrows the potential scope of conflict, so to speak, a balance has been found between efficiency and user needs.
We use tables to represent the possible occurrence of three branches in a merge. Assuming that the content of the isomorphic portion of each branch is capitalized, the following merge results can be obtained:
| Base | Head | Remote | Result | Explain |
|---|---|---|---|---|
| A | A | A | A | Same Content |
| A | A | B | B | If only one of the parties has changed, then choose the one that changed |
| A | B | A | B | Ditto |
| A | B | B | B | If both parties have the same changes, choose the modified |
| A | B | C | conflict | If both sides have changed and are different, a conflict is reported and needs to be resolved by the user |
From: https://blog.csdn.net/longintchar/article/details/83049840
From the table above, we can directly show how the merging of isomorphic locations is handled. So the three-way merge algorithm also appears naturally: apply the previous isomorphic recursion, and then implement the judgment in the table.
Realization
Function recursion and invocation flow as shown in Fig.
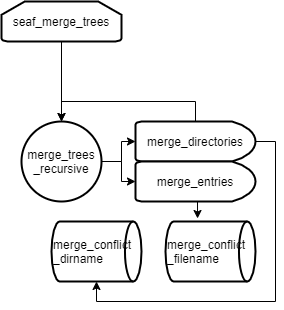
The content is to implement the three-way merge algorithm (the two-way merge is not implemented, only callback functions will be called).
Finally, you need to clarify the storage of the merged results. For merged results, there are two options:If do_merge=true, writes directly to the hard disk and returns a root directory id to merged_tree_root; Conversely, only callback functions are called.
No more detailed source code will be pasted here as follows: merge-new.c.