Preface
Recently, when Baidu wants to learn Spark's newer Structured Streaming, all of them are monotonous wordcount s, which are quite speechless.You have to figure out for yourself what you can do with the Select and Filter operations of the Dataframe.Because of using Python, using Pandas, and trying to turn Pandas to process, readStream does not support the direct toPandas() method.Finally, when I flip over the official API, I find that there is another powerful operation for Dataframe that can be used in readStream: UDF.
Environmental preparation
- Hadoop 2.8.5
- Spark 2.4.3
- Python 3.7.3
- jieba (jieba word segmentation tool, provides TF-IDF keyword extraction method, pip install jieba)
The code below the program is executed in an interactive environment, pyspark.
Data preparation
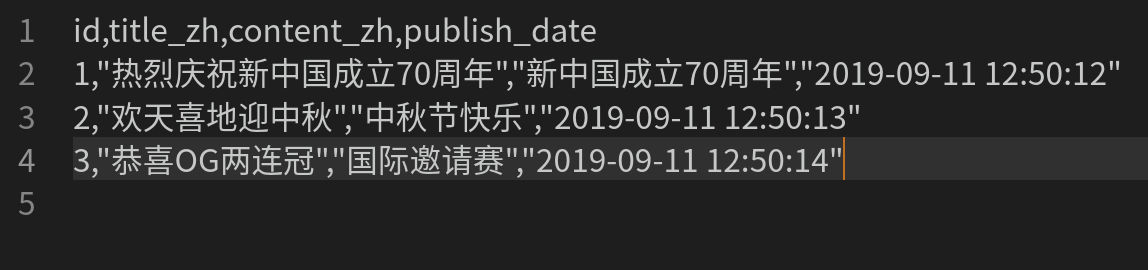
| id | title_zh | content_zh | publish_date | |
|---|---|---|---|---|
Suppose the CSV data, as shown in the table above, represents the article id, title, content, and publishing time, respectively.
There are requirements for extracting keywords from headings and adding keywords to new columns.(There are also keywords to extract articles, but the principle is the same, so you don't write more.)
Read data
There are two steps to reading a csv file: defining the schema and reading the file according to the schema.
Define schema:
In this case, id is of type Integer, publish_date is of type TimestampType, and the rest is StringType.First introduce partial dependency:
from pyspark.sql.functions import udf from pyspark.sql.types import StructType,StringType,IntegerType,TimestampType
Define a StructType:
sdf=StructType().add('id',IntegerType()) sdf.add('title_zh',StringType()).add('content_zh',StringType()) sdf.add('publish_date',TimestampType())
Set up a listening folder that spark will automatically read to stream when a new CSV file is generated, and the path needs to indicate either hdfs:///or file://
rcsv=spark.readStream.options(header='true',multiline='true',inferSchema='true').schema(sdf).csv("file:///home/moon/document/test')
Determine Stream by rcsv.isStreaming
Processing data
Processing data in three steps:
- Define a keyword extraction method that selects the most coefficientd words and eliminates pure numbers
- Construct the extraction method into Udf
- Call Udf using Dataframe's Conversion method
Finally, select the output mode, output destination, and output the results.The following code goes directly to the comment:
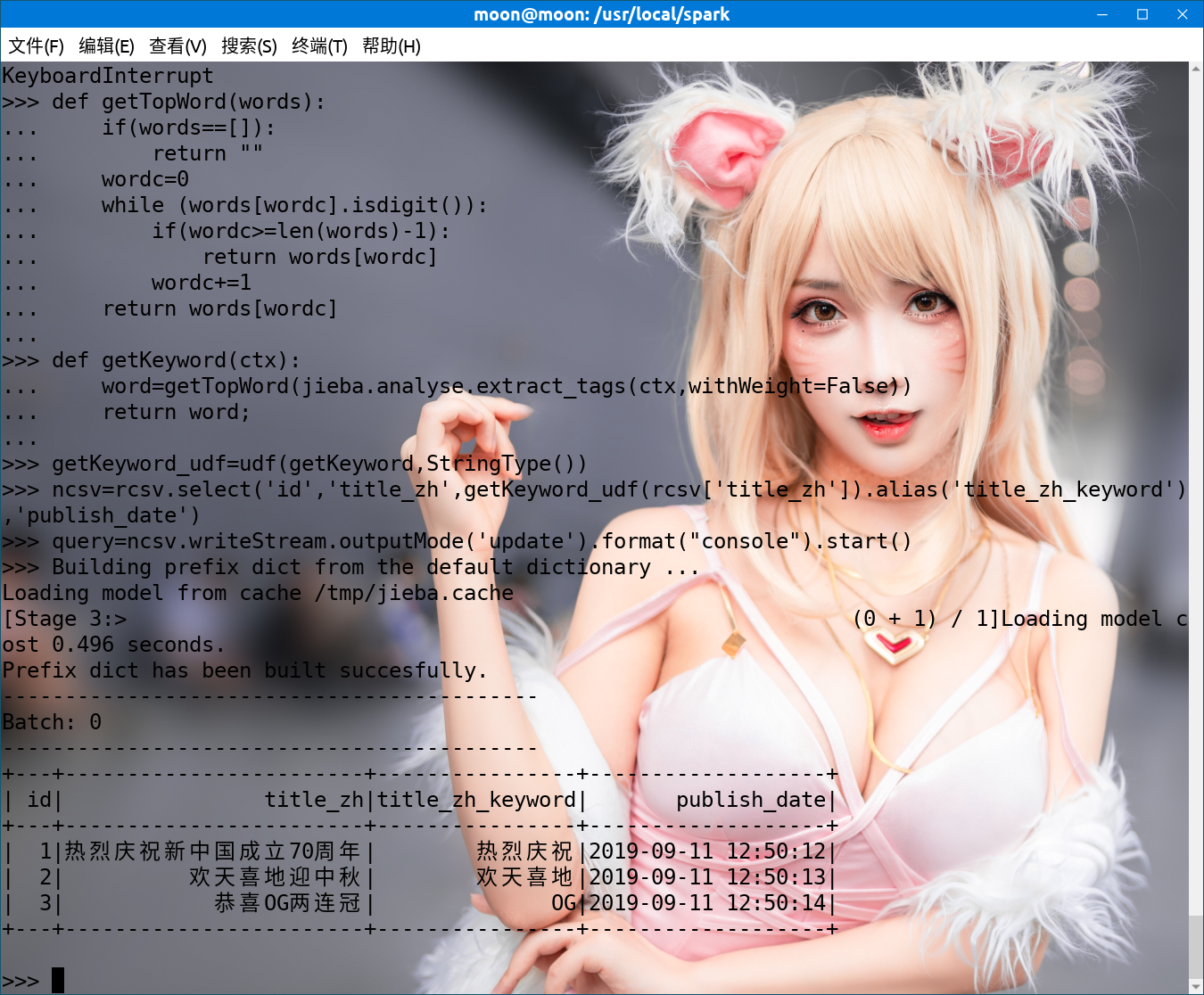
#Introducing jieba dependencies import jieba import jieba.analyse def getTopWord(words): if(words==[]): return "" wordc=0 while (words[wordc].isdigit()): if(wordc>=len(words)-1): return words[wordc] wordc+=1 return words[wordc] def getKeyword(ctx): #The extract_tags method has an optional topK=N parameter to extract N words, but there is another way to exclude pure numbers here, so use its default value word=getTopWord(jieba.analyse.extract_tags(ctx,withWeight=False)) return word; #Parameter is (method name, return type), method can be lambda, return type is required.When invoked, udf is called line by line getKeyword_udf=udf(getKeyword,StringType()) #Use udf method for the column ['title_zh'] and select to generate a new column, alias() to define the alias, and finally get a new readStream ncsv=rcsv.select('id','title_zh',getKeyword_udf(rcsv['title_zh']).alias('title_zh_keyword'),'publish_date') #Set the output mode to update, complete, and Append; output to the command line.I can't tell for more details. I suggest looking at the official documents. query=ncsv.writeStream.outputMode('update').format("console").start()
Result
All the above code, in pyspark, just enter the code one by one, the path will be replaced according to your own actual, the data content and type can be adjusted according to your own preferences.
The CSV file for this example is shown in Fig.
The execution results are as follows:
PS: Miss Sister Weibo@is just a short story, invading and deleting ~ (I don't believe anyone will report me anyway)