2021SC@SDUSC
catalogue
1.PP-OCR character recognition strategy
2. Introduction to this strategy
Data enhancement in image field
PP - Introduction to OCR data enhancement strategy
2, Introduction to BDA and TLA
1. Overview of data enhancement methods
Shortcomings of traditional data enhancement methods
3. Implementation and results of TLA
2. Character recognition processing
1, Previous review
1.PP-OCR character recognition strategy
The selection of strategy is mainly used to enhance the model capability and reduce the model size. Here are nine strategies adopted by PP-OCR character recognizer:
- Light backbone, MobileNetV3 large x0.5 is selected to weigh accuracy and efficiency;
- Data enhancement, BDA (Base Dataaugmented) and TIA (Luo et al. 2020);
- The cosine learning rate is attenuated to effectively improve the text recognition ability of the model;
- Feature map discrimination, adapt to multi language recognition, and modify the stride of down sampling feature map;
- Regularization parameters, weight attenuation to avoid over fitting;
- Preheating of learning rate is also effective;
- The full connection layer is used to encode the sequence features into prediction characters to reduce the size of the model;
- The pre training model is trained on a large data set such as ImageNet, which can achieve faster convergence and better accuracy;
- PACT quantization, skipping the LSTM layer;
2. Introduction to this strategy
- Data enhancement, BDA (Base Data Augmented) and TIA (Luo et al. 2020)
Why data enhancement
- Data is the raw material of machine learning, and most machine learning tasks have supervision tasks, so they rely very much on training data. For example, a certain data belongs to a certain category because of certain characteristics. Through this process, we can finally harvest a model that can predict some laws, and then use this model to make some predictions. Therefore, if you want to make the model have better results, you need larger and better quality data. When there are only a few samples, you need data enhancement to improve the amount of data.
- It is time-consuming and laborious to label data manually, and when it is necessary to label a large amount of data, it is inevitable that labeling errors will be caused by various human factors, so as to reduce the data quality
- It is time-consuming and laborious to label data manually, and when it is necessary to label a large amount of data, it is inevitable that labeling errors will be caused by various human factors, so as to reduce the data quality
Data enhancement test process
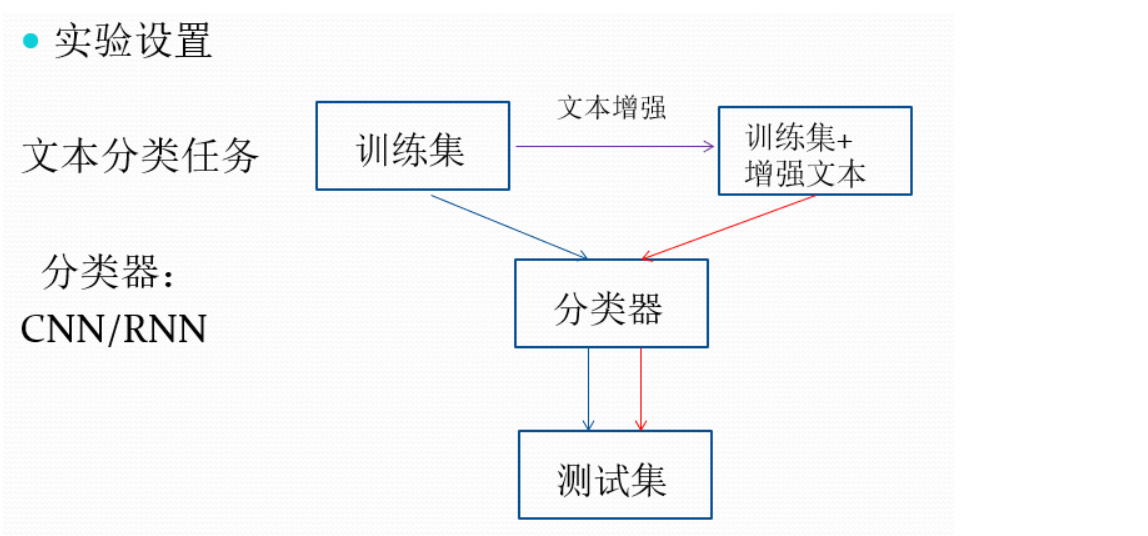
Data enhancement in image field
Through the translation, rotation, clipping, occlusion, inversion, zooming and grayscale processing of the original picture, a large amount of data is generated on the premise that the category of the original picture remains unchanged. In addition to these simple methods, there are many machine learning methods, such as generating a lot of simulation images against network GAN.
PP - Introduction to OCR data enhancement strategy
Image character recognition is divided into two different scenarios, document text and scene text. Scene text refers to the text in the natural scene as shown in the figure. It usually changes greatly due to some factors, such as perspective, zoom, bending, confusion, font, multilingual, blur, lighting, etc. Document text is more common in practical applications. However, there are different problems to be solved, such as high density and long text. Document image text recognition often needs to structurally process the results. At the same time, handwritten text recognition is also a great challenge to image text recognition because of too many handwritten styles and high cost of handwritten annotation text image acquisition .
In order to achieve more accurate identification, paddy OCR adopts the combination of data enhancement and network enhancement. In addition to the traditional enhancement methods such as rotation, scaling and perspective, PP-OCR builds a bridge between the isolated process of data enhancement and network optimization, and generates training samples more suitable for training for identifying the network. In addition, this article will introduce BDA and TLA from two aspects: technical introduction and code interpretation.
2, Introduction to BDA and TLA
1. Overview of data enhancement methods
In the task of image classification, data enhancement is a common regularization method. At the same time, it has become a necessary step to improve the performance of the model in character recognition. Data enhancement can be seen from Alex net to EfficientNet. The methods of data enhancement have gradually changed from the traditional methods of clipping, rotation and mirroring to the current hot NAS search methods such as AutoAug and RandAug.
The following is a simple classification of data enhancement methods:
- Standard data augmentation: generally refers to some common data augmentation methods in the early stage or earlier stage of deep learning;
-
Image transformation class: generally refers to a group of transformation combinations searched based on NAS, including autofragment, randfragment, fast autofragment, fast autofragment, greedy fragment, etc;
-
Image clipping: refers to some data augmentation methods similar to dropout proposed in the era of deep learning, including CutOut, RandErasing, HideAndSeek, GridMask, etc;
-
Image aliasing class: generally refers to operations at the batch level, including Mixup, Cutmix, Fmix, etc
The existing geometric data enhancement includes translation, rotation, clipping, occlusion, inversion, zooming, grayscale and so on. PP-OCR mainly adopts Distort effect , optical stretch imaging, perspective attribute 3D deformation, etc. to process the input image to achieve the effect of data enhancement. The specific processing methods include Bilinear interpolation interpolation), Add Gaussian noise Image data enhancement and anti shake jitter Bisection cutting (Application of the crop() function) Wait.
2.TLA related
Shortcomings of traditional data enhancement methods
In the traditional data enhancement method, the random augmentation strategy of each sample is the same, ignoring the differences between samples and the optimization process of the network. Under the manually controlled static samples, the augmentation may produce many useless samples for training, which is difficult to meet the requirements of dynamic optimization. TLA is a learnable enhancement method, which can adapt to tasks.
Common geometric markers, such as inversion, rotation, scaling and perspective, are usually useful for single object recognition. However, text images contain multiple characters and do not contribute significantly to text diversity.
Advantages of TLA algorithm
- It is the first enhancement method specially designed for sequence characters;
- The framework of data enhancement and recognition model is jointly optimized. The enhanced samples are generated through automatic learning, which is more effective for the training model. The proposed framework is end-to-end without any fine tuning;
A large number of experiments on the benchmarks of various scene texts and handwritten texts show that. Reinforcement and joint learning methods significantly improve the performance of the recognizer.
Introduction to TLA algorithm
Scene text recognition technology:
There are multiple characters in the scene text image, which is more difficult to recognize than a single character. Scene text recognition methods can be divided into the following two types: location-based and non segmentation:
The former attempts to locate characters, recognize them, and group all characters into text strings. The latter benefits from the success of deep neural network, which models text recognition as a sequence recognition problem. Based on convolutional neural networks (CNNs), recurrent neural networks (RNNs) are applied to deal with the spatial dependence of sequence objects. In addition, the problem of sequence to sequence mapping is solved by attention mechanism.
For the recognition of irregular text, TLA proposes a correction network to eliminate distortion and reduce the difficulty of recognition. Iteratively remove perspective distortion and text line curvature. By using more geometric constraints and supervision for each character, an accurate text shape description is given. However, text recognition in irregular scenes is still a challenging problem.
Handwritten text recognition technology:
Early methods used hybrid hidden Markov model to embed word images and text strings into common quantum space, and transformed the recognition task into nearest neighbor problem.
In the era of deep learning, cnn is used first and then rmn is used to extract features, which has achieved good results. A sequence to sequence domain adaptive network is proposed to solve the problem of handwriting style diversity. The intermediate feature space is confrontational distorted to alleviate the lack of change in some sparse training data sets. Because of the diversity of writing styles, handwritten text recognition is still a challenging problem.
Overall:
First, Learning agents can predict the distribution of mobile states to create more difficult training samples. Then, the enhancement module generates enhancement samples respectively according to the random motion state and the predicted motion state. The difficulty of sample recognition is measured by the recognition network. Finally, the agent takes the more difficult mobile state as a guide and updates itself. As shown in the figure below:
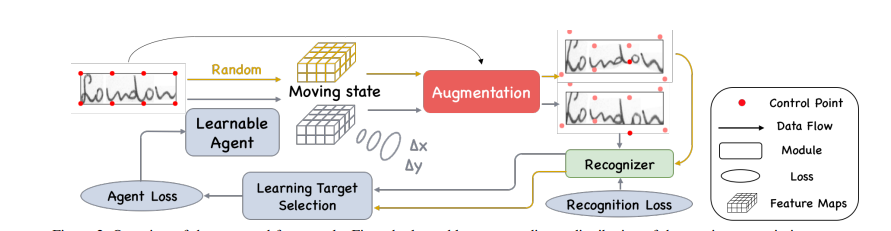
3. Implementation and results of TLA
Overall framework
As shown in the figure above, the proposed framework consists of three main modules: agent network, enhancement module and identification network.
First, we initialize a set of custom benchmarks on the image. The motion state predicted by the agent network and the randomly generated motion state are fed back to the enhancement module. The move status represents the movement of a set of custom fiducials. Then the enhancement module takes the image as the input and performs the transformation based on the motion state respectively. The recognizer predicts the text string on the enhanced image. Finally, measure the recognition degree and enhance the difficulty of the image under the measurement of editing distance. Agents learn from the more difficult mobile state and explore the weaknesses of the recognizer.
Enhancement module
Text addition process
The image is divided into 3 patches (n = 3) and the moving radius is limited to 10(R = 10). Red dots indicate control points
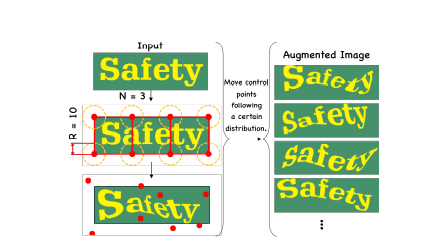
Elastic transformation

Comparison of elastic (similar) and rigid transformations. The motion of the reference point on all images is the same. Rigid transformation maintains the relative shape (real for general objects), but text image enhancement requires more flexible deformation of each character. Therefore, elastic (similarity) transformation is more suitable for text image enhancement.
Joint training programme
The learning scheme of agent network is shown in the figure below.
First, the learnable agent predicts a moving state distribution, aiming to create a more difficult training sample. The random motion state is also fed to the gain module. Then the enhancement module generates enhancement samples according to the two motion states. then, The recognition network takes the amplified sample as input and predicts the text string. The difficulty of this pair of samples is measured by the editing distance between the ground real value and the predicted text string. Finally, the agent updates itself based on the more difficult mobile state. The unified framework is end-to-end trainable.

3, Main code analysis
1. Image and word processing
Code location:

Main code segments (three operations: distort, stretch and perspective):
import numpy as np
from .warp_mls import WarpMLS
def tia_distort(src, segment=4):
img_h, img_w = src.shape[:2]
cut = img_w // segment
thresh = cut // 3
src_pts = list()
dst_pts = list()
src_pts.append([0, 0])
src_pts.append([img_w, 0])
src_pts.append([img_w, img_h])
src_pts.append([0, img_h])
dst_pts.append([np.random.randint(thresh), np.random.randint(thresh)])
dst_pts.append(
[img_w - np.random.randint(thresh), np.random.randint(thresh)])
dst_pts.append(
[img_w - np.random.randint(thresh), img_h - np.random.randint(thresh)])
dst_pts.append(
[np.random.randint(thresh), img_h - np.random.randint(thresh)])
half_thresh = thresh * 0.5
for cut_idx in np.arange(1, segment, 1):
src_pts.append([cut * cut_idx, 0])
src_pts.append([cut * cut_idx, img_h])
dst_pts.append([
cut * cut_idx + np.random.randint(thresh) - half_thresh,
np.random.randint(thresh) - half_thresh
])
dst_pts.append([
cut * cut_idx + np.random.randint(thresh) - half_thresh,
img_h + np.random.randint(thresh) - half_thresh
])
trans = WarpMLS(src, src_pts, dst_pts, img_w, img_h)
dst = trans.generate()
return dst
def tia_stretch(src, segment=4):
img_h, img_w = src.shape[:2]
cut = img_w // segment
thresh = cut * 4 // 5
src_pts = list()
dst_pts = list()
src_pts.append([0, 0])
src_pts.append([img_w, 0])
src_pts.append([img_w, img_h])
src_pts.append([0, img_h])
dst_pts.append([0, 0])
dst_pts.append([img_w, 0])
dst_pts.append([img_w, img_h])
dst_pts.append([0, img_h])
half_thresh = thresh * 0.5
for cut_idx in np.arange(1, segment, 1):
move = np.random.randint(thresh) - half_thresh
src_pts.append([cut * cut_idx, 0])
src_pts.append([cut * cut_idx, img_h])
dst_pts.append([cut * cut_idx + move, 0])
dst_pts.append([cut * cut_idx + move, img_h])
trans = WarpMLS(src, src_pts, dst_pts, img_w, img_h)
dst = trans.generate()
return dst
def tia_perspective(src):
img_h, img_w = src.shape[:2]
thresh = img_h // 2
src_pts = list()
dst_pts = list()
src_pts.append([0, 0])
src_pts.append([img_w, 0])
src_pts.append([img_w, img_h])
src_pts.append([0, img_h])
dst_pts.append([0, np.random.randint(thresh)])
dst_pts.append([img_w, np.random.randint(thresh)])
dst_pts.append([img_w, img_h - np.random.randint(thresh)])
dst_pts.append([0, img_h - np.random.randint(thresh)])
trans = WarpMLS(src, src_pts, dst_pts, img_w, img_h)
dst = trans.generate()
return dst2. Character recognition processing
Code location:

Main code snippet:
class RecAug(object):
#......
return data
class ClsResizeImg(object):
#......
return data
class RecResizeImg(object):
#......
return data
class SRNRecResizeImg(object):
#......
return data
#Various image operation functions
def resize_norm_img(img, image_shape):
def resize_norm_img_chinese(img, image_shape):
def resize_norm_img_srn(img, image_shape):
def srn_other_inputs(image_shape, num_heads, max_text_length):
def flag():
def cvtColor(img):
def blur(img):
def jitter(img):
def add_gasuss_noise(image, mean=0, var=0.1):
def get_crop(image):
#Configuration class
class Config:
"""
Config
"""
#Various configuration functions
def rad(x):
def get_warpR(config):
def get_warpAffine(config):
def warp(img, ang, use_tia=True, prob=0.4):
summary
The above is the introduction of the data enhancement strategy of today's PP-OCR character recognition model. After that, we will continue to introduce other strategies of PP-OCR character recognition model