1. Write a word-count case. Some of the introductions have been introduced in the code comments. There is no extra space to write about the use of storm.
The code is as follows:
1. Write a spout to generate a sentence, as follows
/**
* @Auther: 18030501
* @Date: 2018/10/24 14:25
* @Description: Data stream generator
*
* spout The process with bolt is as follows
* SentenceSpout-->SplitSentenceBolt-->WordCountBolt-->ReportBolt
*/
@Slf4j
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] sentences = {
"my name is whale",
"i like play games",
"my game name is The boy with the cannon",
"so no one dares to provoke me.",
"my girl friend is beautiful"
};
private int index = 0;
/**
* open()The method is defined in the I Spout interface and invoked when the pout component is initialized.
* open()Accept three parameters:
* A Map with Storm Configuration
* A TopologyContext object that provides information about components in a topology
* SpoutOutputCollector Object Provides a Method to Launch tuple
* In this example, we do not need to perform initialization, but simply store a SpoutOutputCollector instance variable.
*/
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
log.info("----SentenceSpout.open----");
this.collector = spoutOutputCollector;
}
/**
* nextTuple()Method is the core of any Spout implementation.
* Storm Call this method and issue a tuple to the collector of the output.
* Here, we just send out the sentences of the current index and add the index to prepare for the next sentence.
*/
@Override
public void nextTuple() {
if (index < sentences.length){
this.collector.emit(new Values(sentences[index]));
index++;
}
Utils.sleep(1);
}
/**
* declareOutputFields Defined in the IComponent interface, all Storm components (spout and bolt) must implement this interface
* Used to tell Storm stream components what data streams will be emitted, and the tuple of each stream will contain fields
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
log.info("-----SentenceSpout.declareOutputFields----");
declarer.declare(new Fields("sentence"));
}
}
2. Bolt for sentence segmentation
/**
* @Auther: 18030501
* @Date: 2018/10/24 14:41
* @Description: Word splitter, subscribe to the tuple stream emitted by sentence spout, realize word splitting
*/
@Slf4j
public class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
/**
* prepare()The method is similar to ISpout's open() method.
* This method is called when the blot is initialized and can be used to prepare the resources used by bolt, such as database connections.
* Like the EnenceSpout class, the SplitSentenceBolt class does not require much additional initialization.
* So the prepare() method only saves references to the OutputCollector object.
*/
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
log.info("----SplitSentenceBolt.prepare----");
this.collector = outputCollector;
}
/**
* SplitSentenceBolt The core function is to define the execute() method in the class IBolt, which is defined in the IBolt interface.
* This method is called every time Bolt receives a subscribed tuple from the stream.
* In this case, the value of "sentence" is found in the received tuple.
* The value is split into individual words and a new tuple is emitted according to the word.
*/
@Override
public void execute(Tuple input) {
String sentence = input.getStringByField("sentence");
// Use spaces to divide sentences into words
String[] words = sentence.split(" ");
for (String word : words) {
this.collector.emit(new Values(word));//Launch data to the next bolt
}
}
/**
* splitSentenceBolt Class defines a tuple flow, each containing a field ("word")
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
log.info("----SplitSentenceBolt.declareOutputFields----");
declarer.declare(new Fields("word"));
}
}
3. Bolt of Word Counting
/**
* @Auther: 18030501
* @Date: 2018/10/24 14:54
* @Description: Subscribe to the output stream of split sentence bolt to count words and send the current count to the next bolt
*/
@Slf4j
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
// Store words and corresponding counts
private Map<String, Long> countMap = null;
/**
* Most instance variables are typically instantiated in prepare(), and this design pattern is determined by how topology is deployed.
* Because when deploying a topology, component spout and bolt are serialized instance variables sent over the network.
* If spout or bolt has any non-serializable instance variables that are instantiated before serialization (for example, created in constructors)
* NotSerializableException will be thrown and the topology will not be published.
* In this case, because HashMap is serializable, it can be safely instantiated in the constructor.
* However, it is usually best to replicate and instantiate basic data types and serializable objects in constructors
* In the prepare() method, the non-serializable objects are instantiated.
*/
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
log.info("----WordCountBolt.prepare----");
this.collector = outputCollector;
this.countMap = new HashMap<>();
}
/**
* In the execute() method, the count of the words we find (initialized to 0 if they do not exist)
* Then the count is added and stored, and a new word and a binary set of the current count are emitted.
* Transmit counts as streams allow other bolt subscriptions to the topology and perform additional processing.
*/
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = this.countMap.get(word);
if (count == null) {
count = 0L;//If not, initialize to 0
}
count++;//Increase count
this.countMap.put(word, count);//Storage count
this.collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//Declare an output stream where tuple includes words and corresponding counts, which are emitted backwards
//Other bolt s can subscribe to this data stream for further processing
log.info("----WordCountBolt.declareOutputFields----");
declarer.declare(new Fields("word", "count"));
}
}
4. Bolt for collecting final results
/**
* @Auther: 18030501
* @Date: 2018/10/24 15:02
* @Description: Report Generator
*/
@Slf4j
public class ReportBolt extends BaseRichBolt {
// Save words and corresponding counts
private HashMap<String, Long> counts = null;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
log.info("----ReportBolt.prepare----");
this.counts = Maps.newHashMap();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = input.getLongByField("count");
this.counts.put(word, count);
//Real time output
log.info("Real-time output results:{}", this.counts);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//Here's the end bolt. No data streams need to be emitted. There's no need to define it here.
}
/**
* cleanup Is defined in the IBolt interface
* Storm This method is called before terminating a bolt
* In this case, we use the cleanup() method to output the final count when the topology is closed
* Usually, the cleanup() method is used to release resources occupied by bolt, such as open file handles or database connections.
*
* But when the Storm topology runs on a cluster, the IBolt.cleanup() method is not guaranteed to execute (here is the development model, not the production environment).
*/
@Override
public void cleanup() {
log.info("----ReportBolt.cleanup----");
log.info("---------- FINAL COUNTS -----------");
ArrayList<String> keys = new ArrayList<>();
keys.addAll(this.counts.keySet());
Collections.sort(keys);
for (String key : keys) {
System.out.println(key + " : " + this.counts.get(key));
}
log.info("----------------------------");
}
}
5. Define startup classes, which provide two ways to test and submit clusters:
Submit cluster mode:
/**
* @Auther: 18030501
* @Date: 2018/10/24 15:08
* @Description: Implementing Word Counting topology
* <p>
* Storm Routing mode:
* shuffle grouping:Shuffle mode, randomly averaged to downstream nodes
* fields grouping:Fields with the same value are assigned to the same node (i.e. data streams that continuously track a fixed feature)
* global grouping: Force to a unique node, in fact if there are more than one node to the node with the lowest task number
* all grouping: Mandatory to all nodes, use carefully
* Partial Key grouping: The latest supported Fields grouping with load balancing
* Direct grouping: Manually specify the node to flow to
*/
@Slf4j
public class StormApp {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) {
// 1. Instantiate spout and bolt
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
// 2. Create a topology instance
//TopologyBuilder provides a streaming-style API to define data flows between topology components
TopologyBuilder builder = new TopologyBuilder();
// 3. Register a sentence spout and default an Executor (thread) and a task
builder.setSpout(SENTENCE_SPOUT_ID, spout, 1);
// 4. Register a Split Sentence Bolt and subscribe to the data stream sent by sentence
// The shuffleGrouping method tells Storm to randomly and evenly distribute the tuple emitted by SentenceSpout to an instance of Split SentenceBolt
// Split SentenceBolt word splitter sets two Task s and one Executor (thread)
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 1).setNumTasks(2).shuffleGrouping(SENTENCE_SPOUT_ID);
// 5. Register WordCountBolt and subscribe to Split Sentence Bolt
//fieldsGrouping routes tuple s containing specific data to special bolt instances
//Here the fieldsGrouping() method ensures that all tuple s with the same "word" field are routed to the same WordCountBolt instance
//WordCountBolt Word Counter Sets 2 Executors (Threads)
builder.setBolt(COUNT_BOLT_ID, countBolt, 2).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// 6. Register ReportBolt and subscribe to WordCountBolt
//Global Grouping routes all tuple s emitted by WordCountBolt to a unique ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
// The Config class is a subclass of HashMap < String, Object> to configure the behavior of the topology runtime
Config config = new Config();
// Setting the number of worker s
config.setNumWorkers(1);
config.setDebug(false);
config.setMaxSpoutPending(1000);
// Submit to cluster
try {
StormSubmitter.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
} catch (AlreadyAliveException e) {
log.error("submit topology error",e);
} catch (InvalidTopologyException e) {
log.error("submit topology error",e);
}
}
}
Local test mode:
/**
* @Auther: 18030501
* @Date: 2018/10/26 11:30
* @Description: Local test mode
*/
public class StormAppTest {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) {
// 1. Instantiate spout and bolt
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
// 2. Create a topology instance
//TopologyBuilder provides a streaming-style API to define data flows between topology components
TopologyBuilder builder = new TopologyBuilder();
// 3. Register a sentence spout, set two Executors (threads), default one
builder.setSpout(SENTENCE_SPOUT_ID, spout, 1);
// 4. Register a Split Sentence Bolt and subscribe to the data stream sent by sentence
// The shuffleGrouping method tells Storm to randomly and evenly distribute the tuple emitted by SentenceSpout to an instance of Split SentenceBolt
// Split SentenceBolt word splitter sets two Task s and one Executor (thread)
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 1).setNumTasks(2).shuffleGrouping(SENTENCE_SPOUT_ID);
// 5. Register WordCountBolt and subscribe to Split Sentence Bolt
//fieldsGrouping routes tuple s containing specific data to special bolt instances
//Here the fieldsGrouping() method ensures that all tuple s with the same "word" field are routed to the same WordCountBolt instance
//WordCountBolt Word Counter Sets 2 Executors (Threads)
builder.setBolt(COUNT_BOLT_ID, countBolt, 2).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// 6. Register ReportBolt and subscribe to WordCountBolt
//Global Grouping routes all tuple s emitted by WordCountBolt to a unique ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
// The Config class is a subclass of HashMap < String, Object> to configure the behavior of the topology runtime
Config config = new Config();
// Setting the number of worker s
config.setNumWorkers(1);
LocalCluster cluster = new LocalCluster();
// Local submission
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}
Now that the code has been written, we begin to pack it and submit it it to the storm machine.
It should be noted here that:
1. To use maven packaging, you need to exclude the jar package of storm and not enter the jar package.
2. Use the following packaging configuration
<!-- Use this plug-in to enter dependent packages -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.example6.demo6.storm.StormApp</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
Operation steps:
1. Upload the jar package to the server
2. Start storm Service
3. Submit tasks to the cluster using the following commands:
./storm jar /home/storm/demo6-0.0.1-SNAPSHOT-jar-with-dependencies.jar com.example6.demo6.storm.StormApp word-count-topology
Description of parameters:
jar: running job
/home/storm/demo6-0.0.1-SNAPSHOT-jar-with-dependencies.jar: The path to your jar package
com.example6.demo6.storm.StormApp: Startup class
word-count-topology: name of the topology
After executing the order, the effect is as follows: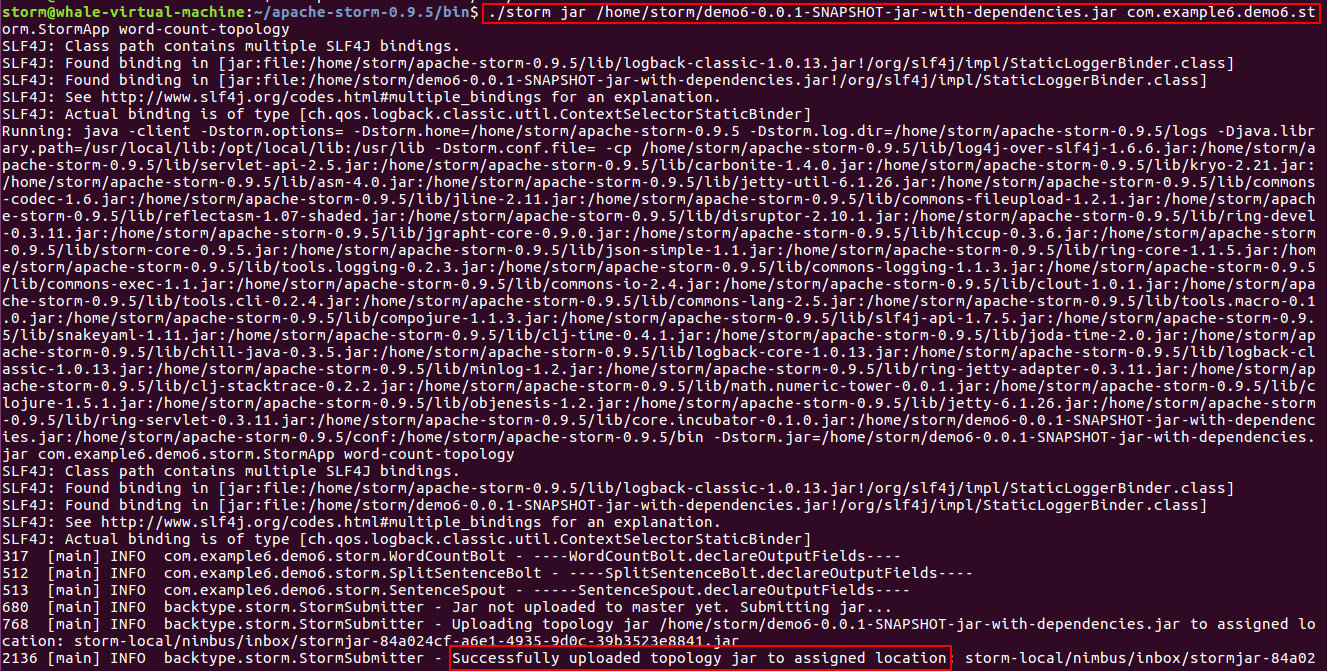
At this point, login to StormUI to see the running status:
Overview of the entire Storm: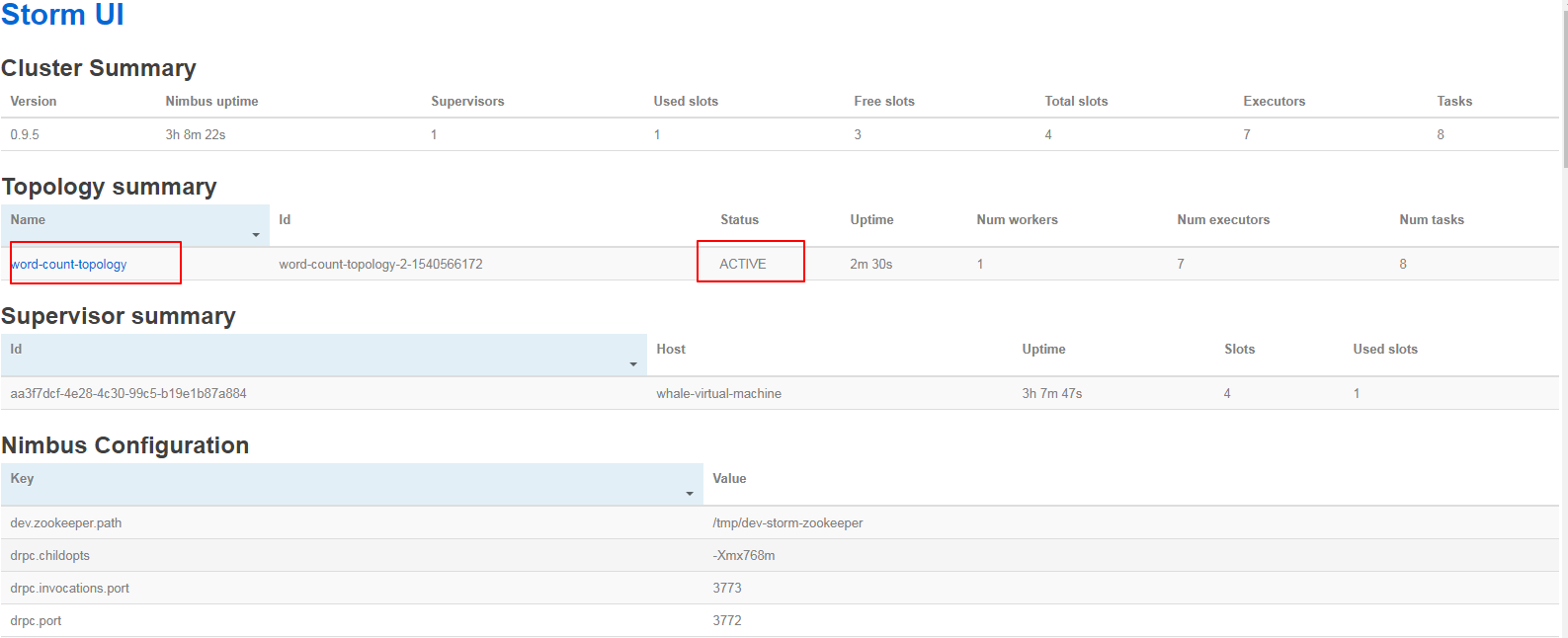
Enter the specific topology to see the details: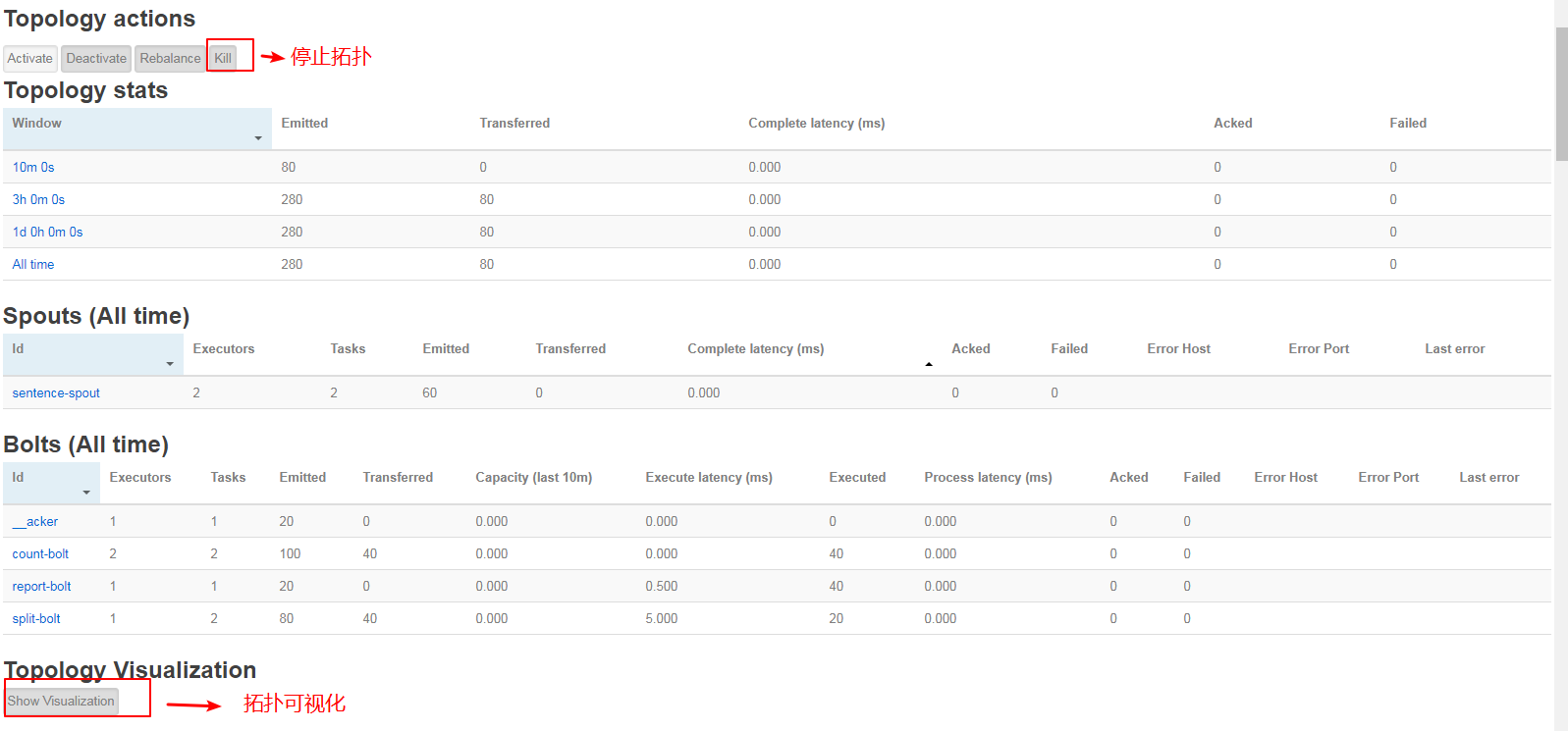
View the storm Run Log:
The specific execution log is in the work-port.log file: