This article is from https://blog.csdn.net/UbuntuTouch/article/details/99546568 , with amendments and deletions.
In the previous article, we have described how to use the REST interface to create index es, documents, and actions in ES.In today's article, we'll show you how to use ES to search for our data.ES is a near real-time search.Let's continue with our last exercise. Start using Elasticsearch (1): How to create an index, add, delete, update documents".
There are two types of searches in Elasticsearch:
- queries
- aggregations
The difference between them is that query is used for full-text search and aggregation is used for statistics and analysis of data.You can also combine the two, for example, we can query the document before aggregating it:
GET blogs/_search { "query": { "match": { "title": "community" } }, "aggregations": { "top_authors": { "terms": { "field": "author" } } } }
In the above search, first search for documents with'community'in the title, then aggregate the data for information about the author.
Search all documents
We can search all documents using the following commands:
GET /_search
No index is specified here, and all indexes under that cluster will be searched.The default number of returned data is currently 10 unless we set size:
GET /_search?size=20
The above command is also equivalent to:
GET /_all/_search
We can also search for multiple index es like this:
POST /index1,index2,index3/_search
The code above indicates a search for index1, index2, index3 indexes.
Of course, we can even write as follows:
POST/index*, -index3/_search
The code above indicates that all indexes starting with index are searched, but index3 indexes are excluded.
If we only want to search for our specific index, such as twitter, we can do this:
GET twitter/_search GET /twitter/_search
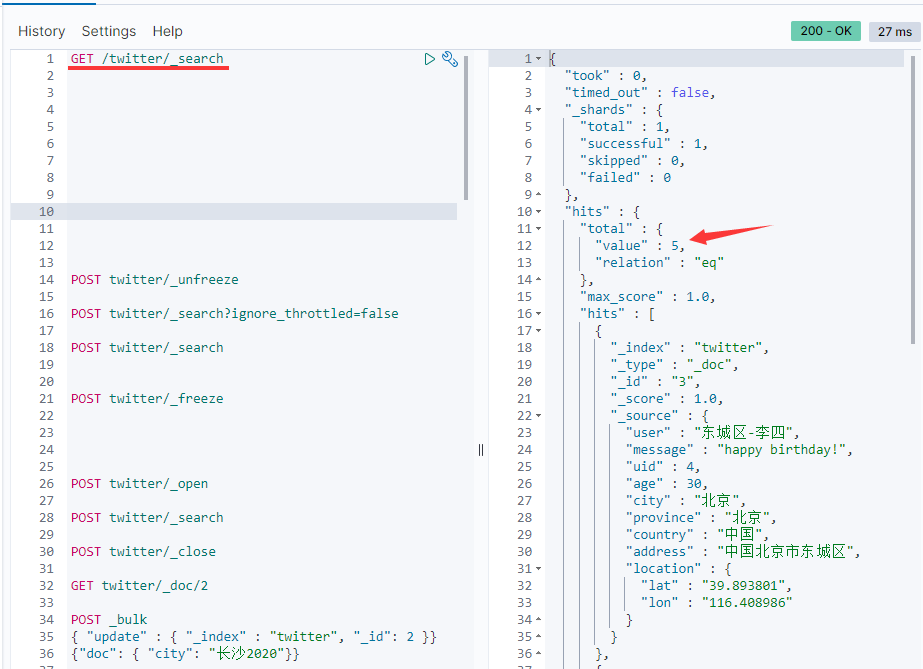
From the results above, you can see that there are five documents in the twitter index.In the hits array above, we can see all the results.At the same time, we can also see a so-called _The item of the scope that represents the relevance of search results.The higher this value is, the more relevant the search matches will be.Without sort by default, search results are ranked from most relevant to least relevant.
By default, the paging size is 10, which returns 10 data.You can get the number we want by setting the size parameter.Paging can also be done with from:
GET twitter/_search?size=2&from=2
This allows me to use the from parameter for paging.
The from here is a zero-based ordinal, not the current number of pages.
The above query is similar to the following statement of a DSL query:
GET twitter/_search { "size": 2, "from": 2, "query": { "match_all": {} } }
They can use filter_path controls fewer fields of output, such as:
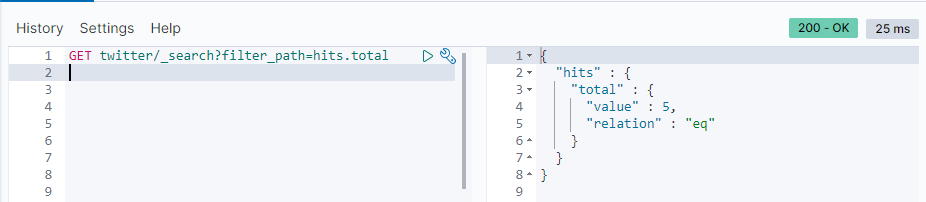
GET twitter/_search?filter_path=hits.total
The results executed above will be directly fromHits.totalStart returning:
source filtering
We can use _source to define the field you want to return:
GET twitter/_search { "_source": ["user", "city"], "query": { "match_all": { } }
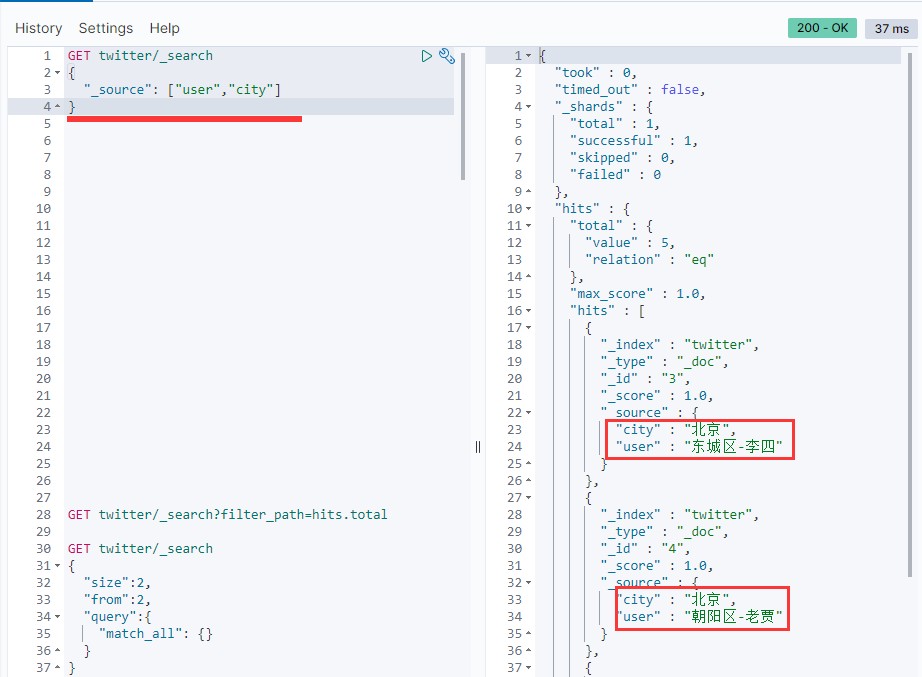
You can see that only the user and city fields are in _Return in source.If set _Sorce is false and does not return any _Sorce information:
GET twitter/_search { "_source": false }
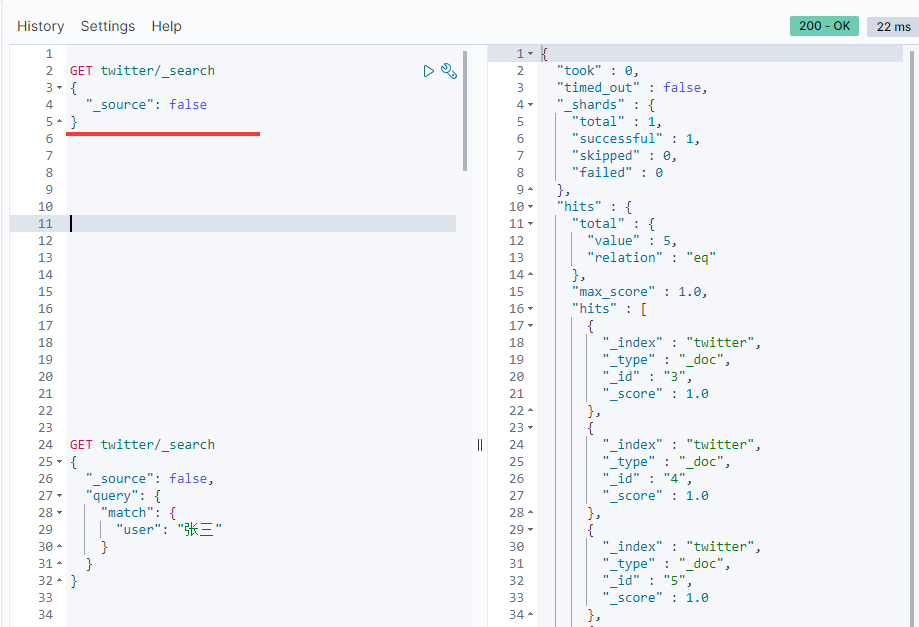
You can see that only _id and _score and so on, any other _None of the source fields were returned.You can also receive control in the form of wildcards, such as:
GET twitter/_search { "_source": { "includes": ["user*", "location*"], "excludes": ["*.lat"] } }
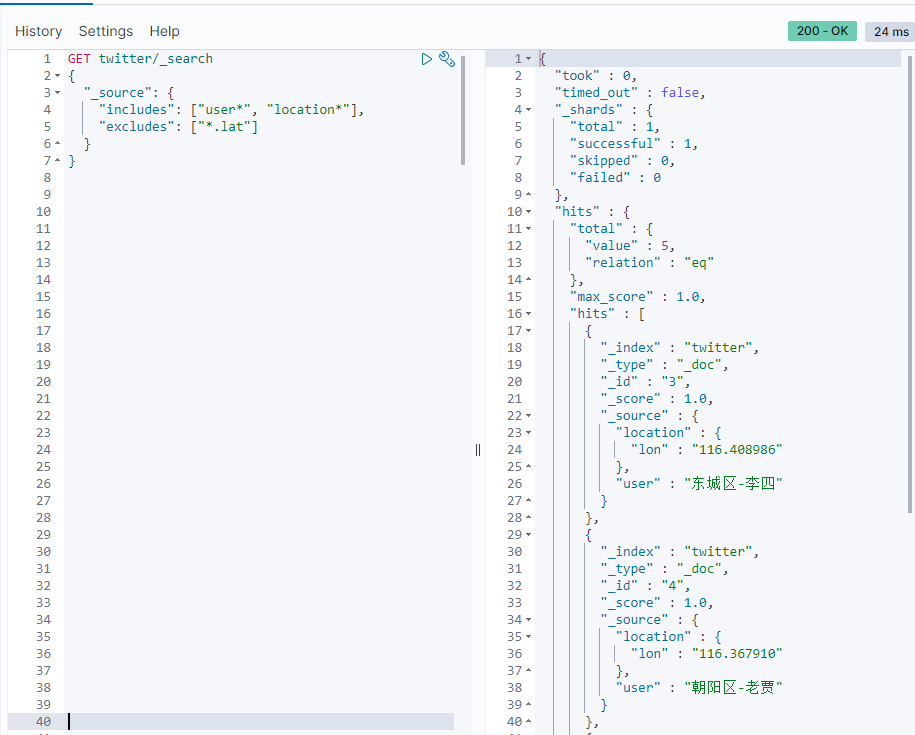
Script fields
Sometimes the field we want may be _There is nothing in source at all, so we can use script field to generate these fields.Allow return for each match script evaluation (based on different fields), for example:
GET twitter/_search { "query": { "match_all": {} }, "script_fields": { "years_to_100": { "script": { "lang": "painless", "source": "100-doc['age'].value" } }, "year_of_birth":{ "script": "2019 - doc['age'].value" } }
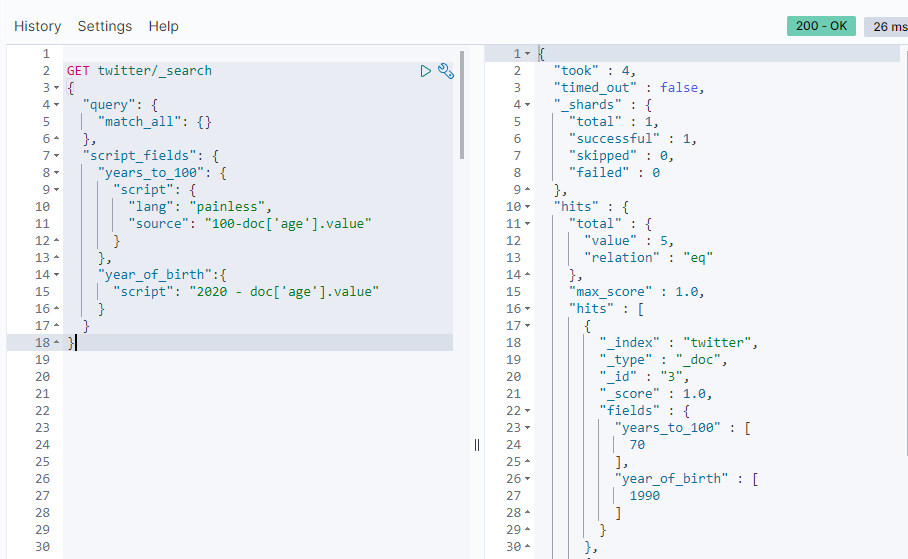
This script-based method of generating query results can be very resource intensive for a large number of documents
Count API
We often query how many documents are in our index, so we can use _count focuses on querying:
GET twitter/_count
If we want to know the number of documents that meet the criteria, we can use the following format:
GET twitter/_count { "query": { "match": { "city": "Beijing" } } }
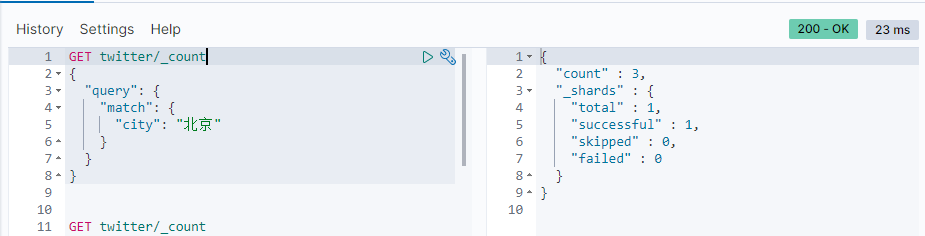
Modify settings
You can get an index settings through the following interfaces:
GET twitter/_settings
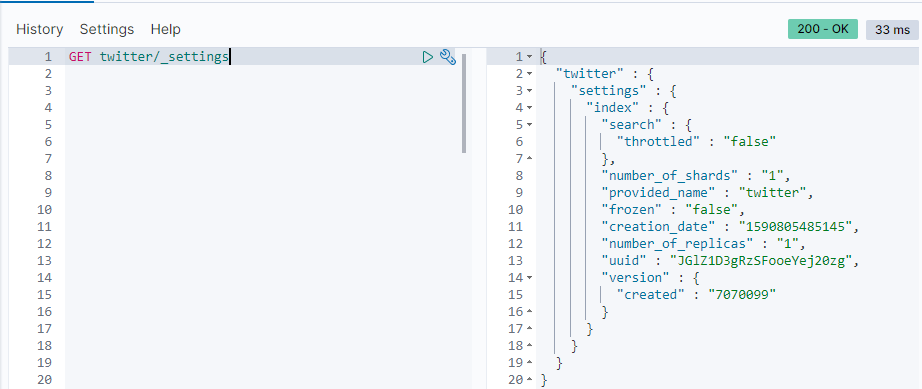
Here we can see how many shards and replicas the twitter index has.We can also set it through the following interfaces:
PUT twitter { "settings": { "number_of_shards": 1, "number_of_replicas": 1 } }
Once number_of_shards is fixed and cannot be modified unless you delete the index and re-index it.This is because which shard is and number_to store each document inOf_Shards is related to this number.Once this number changes, it will be inaccurate to look for the shard in which that document is located later.
Modify the mapping of index
Elasticsearch is called schemaless, and in practice, each index has a corresponding mapping.This mapping was generated when we created the first document.It is an automatic identification of each input field to determine its data type.We can understand schemaless as follows:
- Documentation can be created without first defining a corresponding mapping.Field types are dynamically recognized.This is different from traditional databases;
- If new fields are added dynamically, mapping can also automatically adjust and identify newly added fields.
One problem with automatic field recognition is that some fields may not be recognized accurately, such as the location information in our example.So we need to modify this field.
We can query the mapping of the current index with the following commands:
GET twitter/_mapping
The data shown is as follows:
{ "twitter" : { "mappings" : { "properties" : { "address" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "age" : { "type" : "long" }, "city" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "country" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "location" : { "properties" : { "lat" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "lon" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } }, "message" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "province" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "uid" : { "type" : "long" }, "user" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }
From the above display, you can see that latitude and longitude in location is a multi-field type.
"location" : { "properties" : { "lat" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "lon" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } }
This is obviously not what we want.The correct type should be: geo_point.We'll revise our mapping again.
Note: We cannot dynamically modify mapping for an index that has already been established.This is because once modified, the previously created index becomes unsearchable.One way is to reindex to re-index.If a new field is added to the previous mapping, then we can avoid re-indexing.
In order to properly create our mapping, we must first delete the previous twitter index and use settings to create it.The specific steps are as follows:
DELETE twitter PUT twitter { "settings": { "number_of_shards": 1, "number_of_replicas": 1 } } PUT twitter/_mapping { "properties": { "address": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "age": { "type": "long" }, "city": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "country": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "location": { "type": "geo_point" }, "message": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "province": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "uid": { "type": "long" }, "user": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } }
Re-view our mapping:
GET twitter/_mapping
We can see that we have created a new mapping.We run our previous bulk interface again and import the data we need into the twitter index.
POST _bulk { "index" : { "_index" : "twitter", "_id": 1} } {"user":"Elm-Zhang San","message":"It's a nice day today. Go outside","uid":2,"age":20,"city":"Beijing","province":"Beijing","country":"China","address":"Haidian District, Beijing, China","location":{"lat":"39.970718","lon":"116.325747"}} { "index" : { "_index" : "twitter", "_id": 2 }} {"user":"Dongcheng District-Lao Liu","message":"Start, next stop is Yunnan!","uid":3,"age":30,"city":"Beijing","province":"Beijing","country":"China","address":"No. 3 Taiji Plant, Dongcheng District, Beijing, China","location":{"lat":"39.904313","lon":"116.412754"}} { "index" : { "_index" : "twitter", "_id": 3} } {"user":"Dongcheng District-Li Si","message":"happy birthday!","uid":4,"age":30,"city":"Beijing","province":"Beijing","country":"China","address":"Dongcheng District, Beijing, China","location":{"lat":"39.893801","lon":"116.408986"}} { "index" : { "_index" : "twitter", "_id": 4} } {"user":"Chaoyang District-Lao Jia","message":"123,gogogo","uid":5,"age":35,"city":"Beijing","province":"Beijing","country":"China","address":"Jianguomen, Chaoyang District, Beijing, China","location":{"lat":"39.718256","lon":"116.367910"}} { "index" : { "_index" : "twitter", "_id": 5} } {"user":"Chaoyang District-King","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"Beijing","province":"Beijing","country":"China","address":"Chaoyang District, Beijing, China","location":{"lat":"39.918256","lon":"116.467910"}} { "index" : { "_index" : "twitter", "_id": 6} } {"user":"Rainbow Bridge-Lao Wu","message":"Friends are coming Today's birthday, friends are coming,What birthday happy Ready!","uid":7,"age":90,"city":"Shanghai","province":"Shanghai","country":"China","address":"Minhang District, Shanghai, China","location":{"lat":"31.175927","lon":"121.383328"}}
So far, we have completely built the index we need.Below, we start using DSL (Domain Specifc Lanaguage) to help us with our queries.
Query Data
In this section, we'll show you how to query the data we want from our ES index.
GET twitter/_search { "query": { "match": { "city": "Beijing" } } }
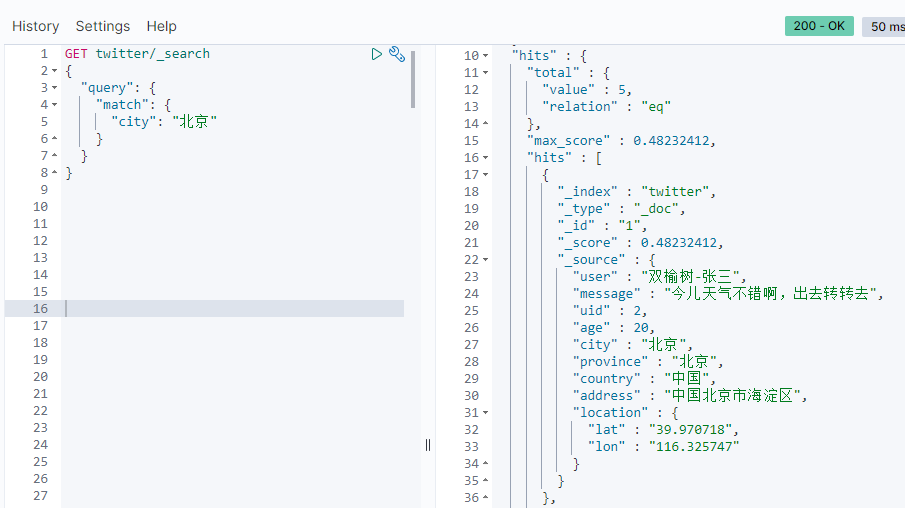
From the results of the query, we can see that five users are from Beijing, and the results of the query are sorted by relavance.
In many cases, we can also use script query to do this:
GET twitter/_search { "query": { "script": { "script": { "source": "doc['city'].contains(params.name)", "lang": "painless", "params": { "name": "Beijing" } } } } }
The script query above is the same as the query above, but we do not recommend you use this method.In contrast, script query's approach is less efficient.
The above search can also be done as follows:
GET twitter/_search?q=city:"Beijing"
If you want to know more, you can read more about " Elasticsearch: Using URI Search".
If we don't need this score, we can choose a filter to do it:
GET twitter/_search { "query": { "bool": { "filter": { "term": { "city.keyword": "Beijing" } } } } }
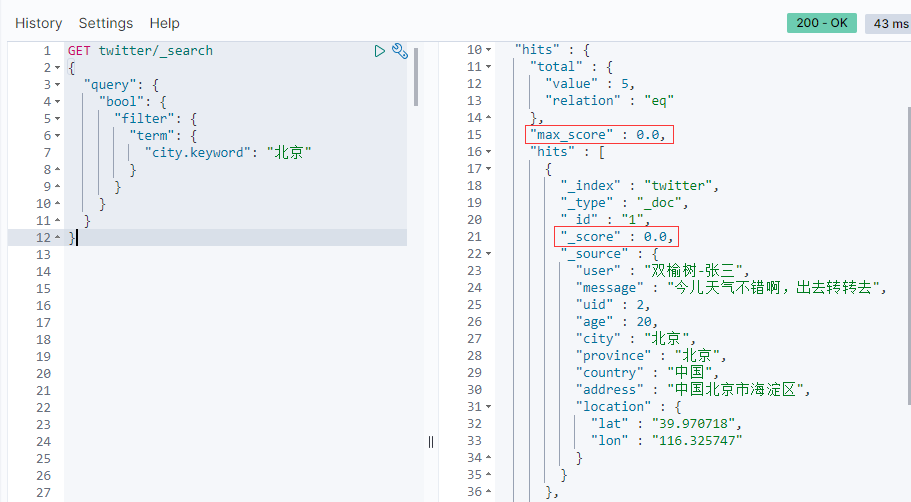
From the results returned, _The score item is zero.For this kind of search, just yes or no.We don't care about their relevance.Here we useCity.keyword.It may be unfamiliar to someone new to Elasticsearch.The correct understanding is that city is a multi-field item in our mapping.It is both text and keyword type.For an item of type keyword, all the characters in the item are treated as strings.They do not need to be index ed when creating documents.The keyword field is used for exact searches, aggregation s, and sorting.
So in our filter, we use term to complete this query.
We can also use the following methods to achieve the same effect:
GET twitter/_search { "query": { "constant_score": { "filter": { "term": { "city": { "value": "Beijing" } } } } } }
The above code does not query data in version 7.7
When we use match query, the default operation is OR, which can be queried as follows:
GET twitter/_search { "query": { "match": { "user": { "query": "Chaoyang District-Lao Jia", "operator": "or" } } } }
The above query is the same as the following:
GET twitter/_search { "query": { "match": { "user": "Chaoyang District-Lao Jia" } } }
This is because the default operation is the or operation.The result of the above query is that any of the five words "Chao", "Yang", "Zone", "Old" and "Jia" will be displayed:
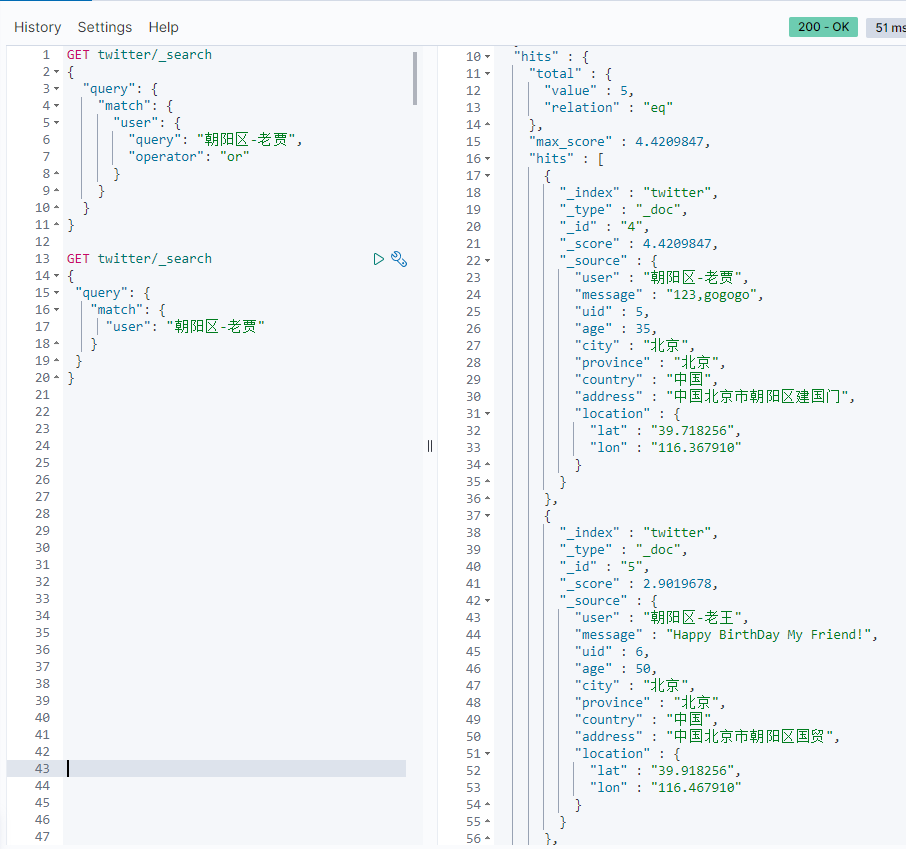
We can also set the parameter minimum_should_match to set at least the matching term.For example:
GET twitter/_search { "query": { "match": { "user": { "query": "Chaoyang District-Lao Jia", "operator": "or", "minimum_should_match": 3 } } } }
It shows that we need to match at least three of the five words "Chao", "Yang", "Zone", "Old" and "Jia".Display results:
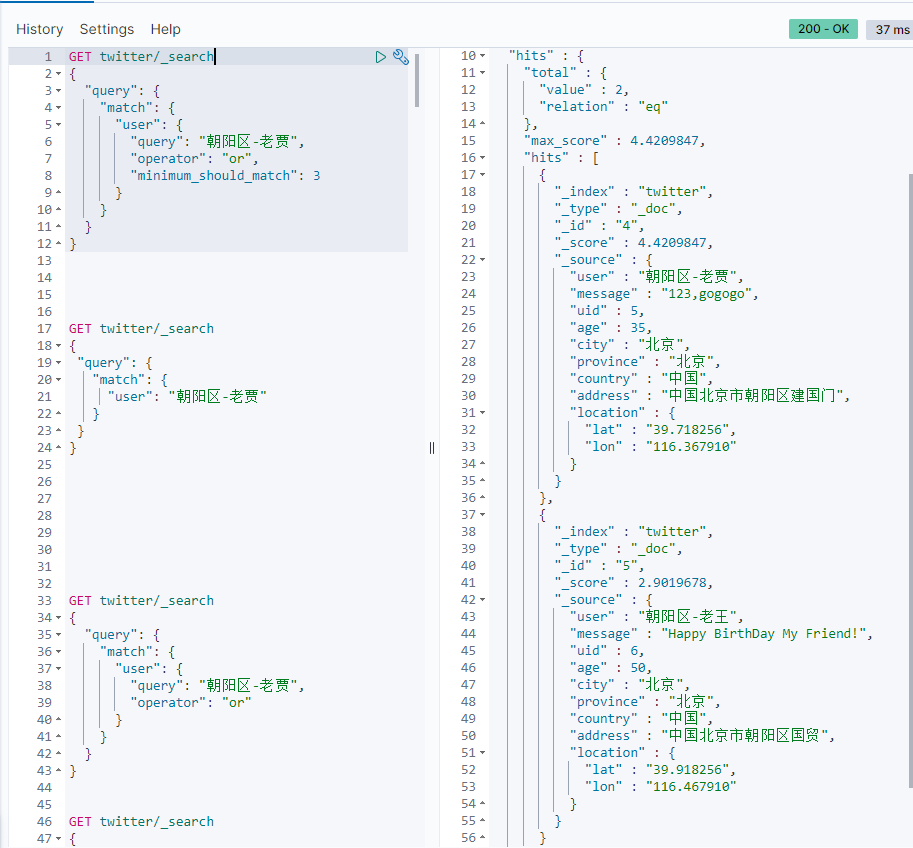
We can also change to "and" and "Look at the operation:
GET twitter/_search { "query": { "match": { "user": { "query": "Chaoyang District-Lao Jia", "operator": "and" } } } }
The result shown is:
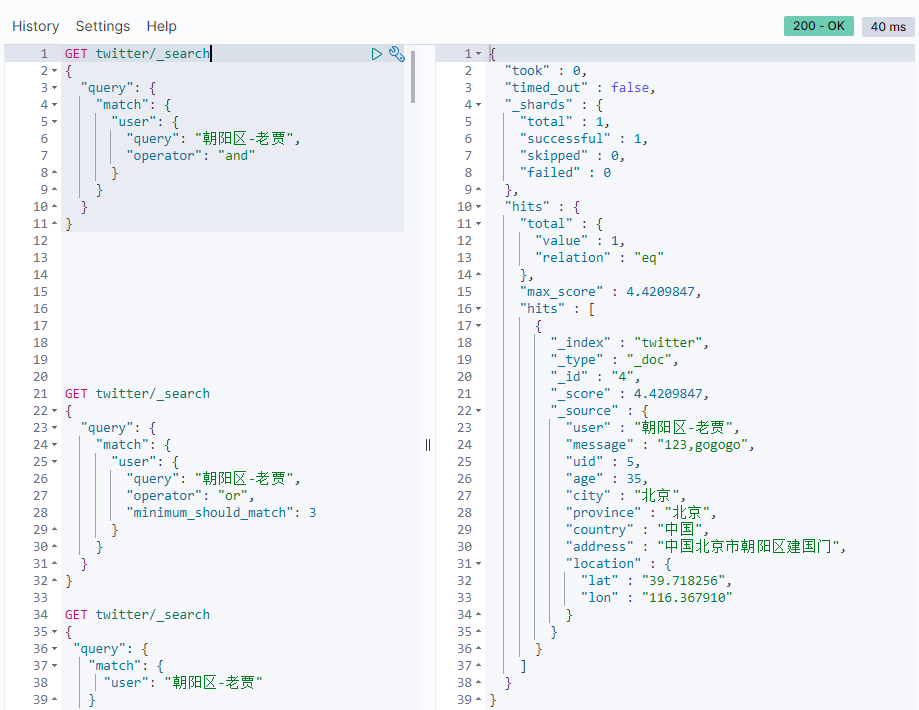
In this case, you need to match the five words of the index at the same time.Clearly, we can improve the accuracy of our search by using and.
Multi_match
In the above search, we specifically specified a proprietary field to search for, but in many cases, we don't know which field contains the keyword, so in this case, we can use multi_match to search:
GET twitter/_search { "query": { "multi_match": { "query": "Chaoyang", "fields": [ "user", "address^3", "message" ], "type": "best_fields" } } }
In the code above, we searched for three fields at the same time: user, adress, and message, but weighted address three times the score for documents with "sunrise".Return results:

Prefix query
Returns a document that contains a specific prefix in the field provided.
GET twitter/_search { "query": { "prefix": { "user": { "value": "towards" } } } }
Query all documents in the user field that begin with "face":

Term query
Term query performs exact word matching in a given field.Therefore, you need to provide accurate terminology to get the right results.
GET twitter/_search { "query": { "term": { "user.keyword": { "value": "Chaoyang District-Lao Jia" } } } }
Here, we useUser.keywordTo match "Chaoyang District-Laojia" accurately and query the corresponding documents:
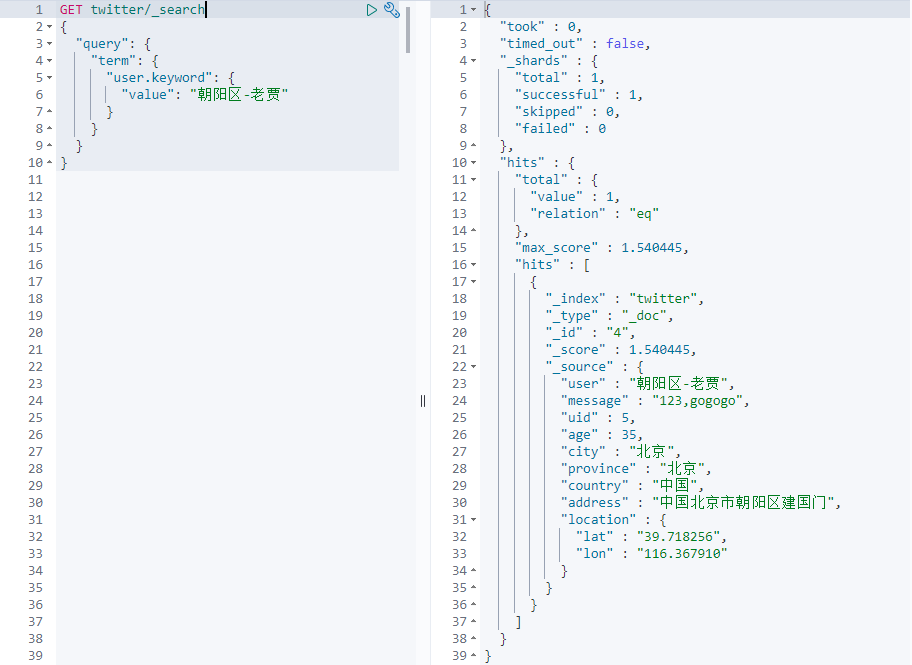
Terms query
If we want to query multiple terms, we can do this in the following ways:
GET twitter/_search { "query": { "terms": { "user.keyword": [ "Elm-Zhang San", "Dongcheng District-Lao Liu" ] } } }
Query aboveUser.keywordIt contains all documents of "Shuangelm-Zhang San" or "Dongcheng-Lao Liu":
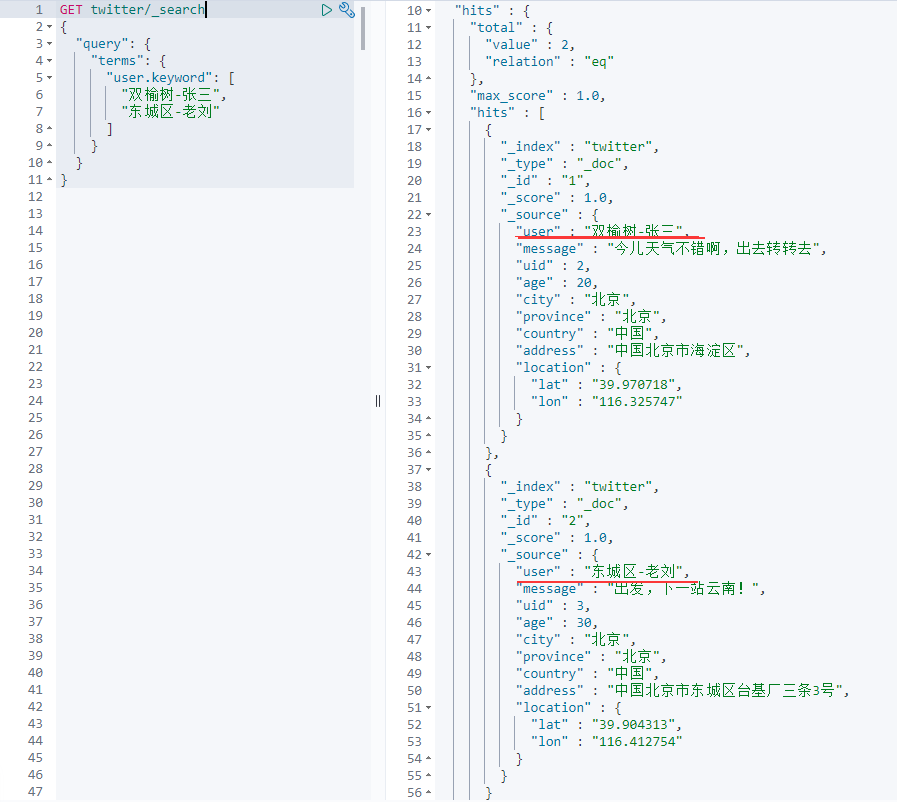
compound query
What is a composite query?If the above query is a leaf query, a composite query can combine many leaf queries to form a more complex query.Its general format is:
POST _search { "query": { "bool" : { "must" : { "term" : { "user" : "kimchy" } }, "filter": { "term" : { "tag" : "tech" } }, "must_not" : { "range" : { "age" : { "gte" : 10, "lte" : 20 } } }, "should" : [ { "term" : { "tag" : "wow" } }, { "term" : { "tag" : "elasticsearch" } } ], "minimum_should_match" : 1, "boost" : 1.0 } } }
As we can see from the above, it is must, must_under bool Not, should and filter together.For our example,
GET twitter/_search { "query": { "bool": { "must": [ { "match": { "city": "Beijing" } }, { "match": { "age": "30" } } ] } } }
The query is that city must be in Beijing and is exactly 30 years old.
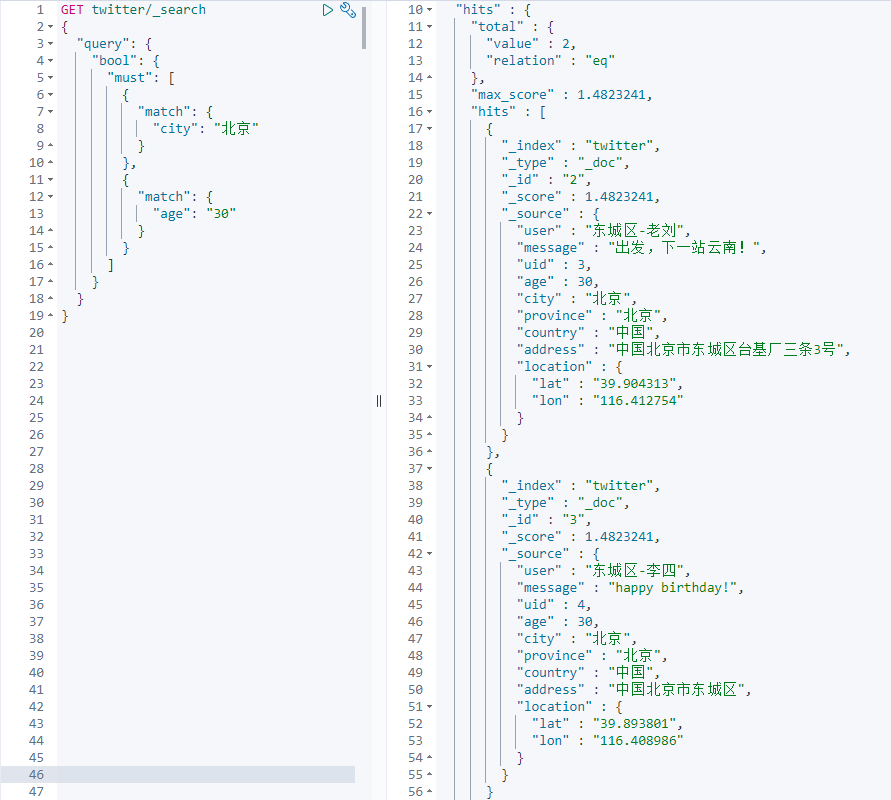
If we want to know why we got this result, we can add "explain" to the search instructions: true.
GET twitter/_search { "query": { "bool": { "must": [ { "match": { "city": "Beijing" } }, { "match": { "age": "30" } } ] } }, "explain": true }
You can see some explanations in the results:
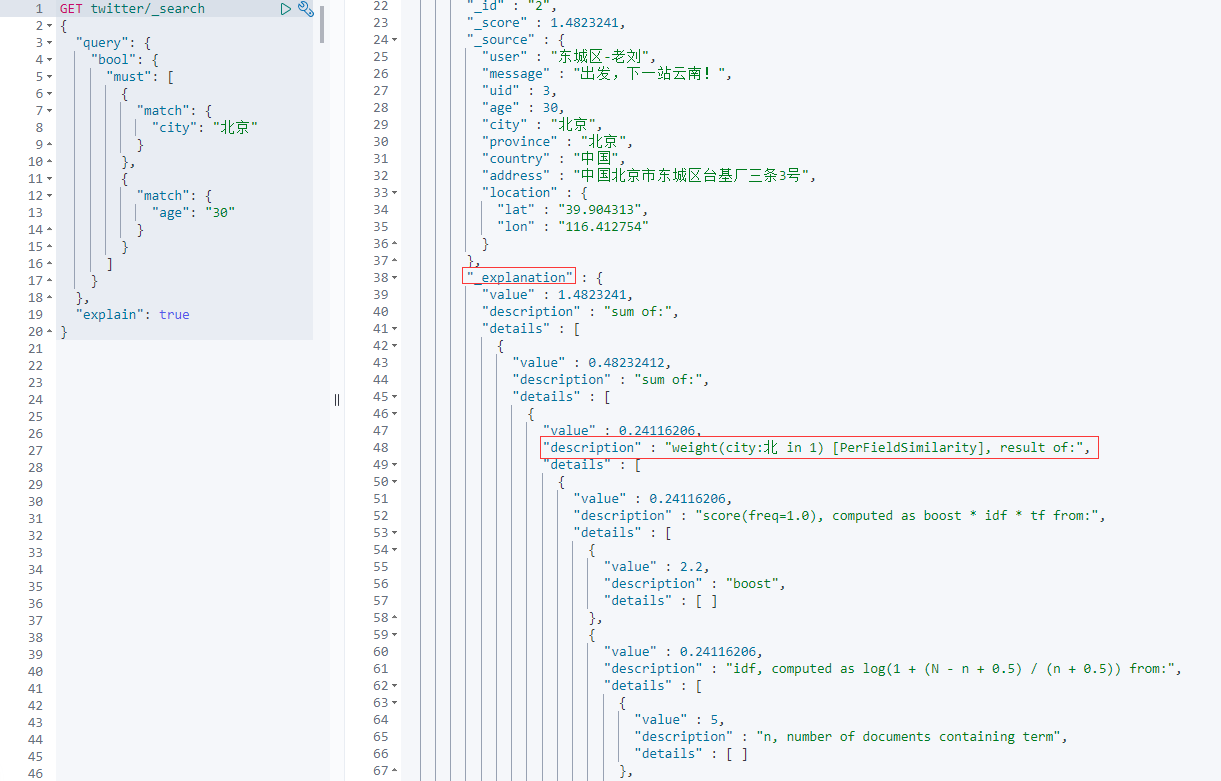
There are two results shown above.Again, we can use must_not excludes certain conditions:
GET twitter/_search { "query": { "bool": { "must_not": [ { "match": { "city": "Beijing" } } ] } } }
The code above is looking for all documents that are not in Beijing:
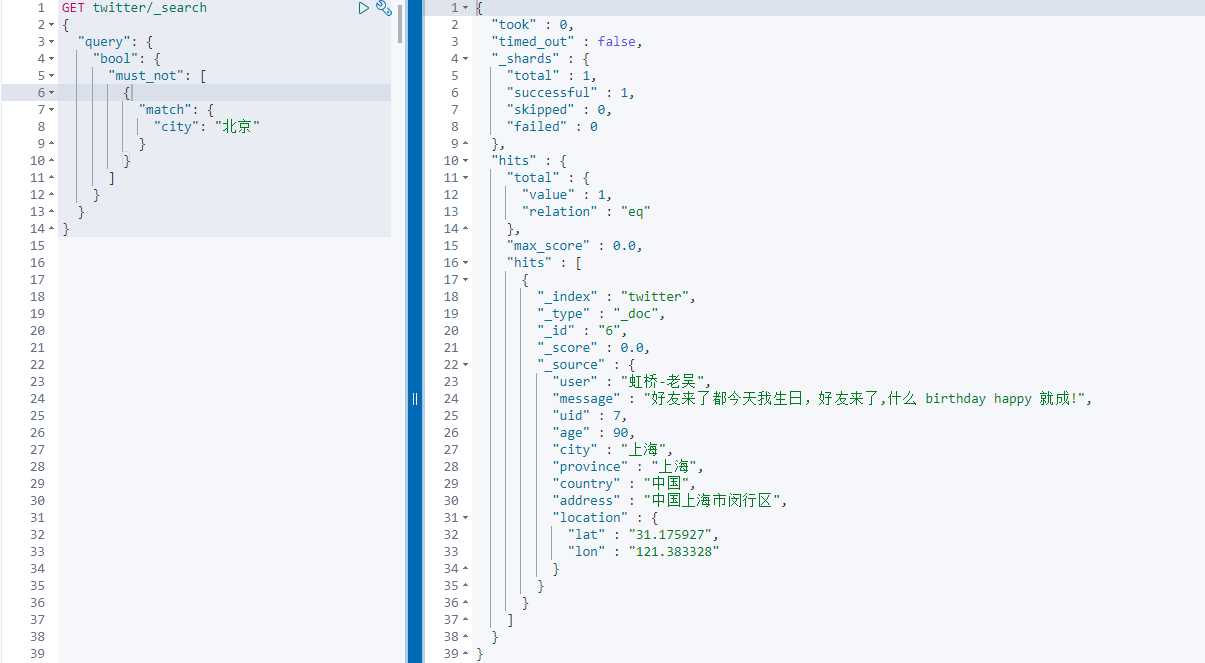
Only one document was searched.He is from Shanghai and the rest are from Beijing.
Next, let's try should.It means "or", that is, if there is one, it is better, if not.For example:
GET twitter/_search { "query": { "bool": { "must": [ { "match": { "age": "30" } } ], "should": [ { "match_phrase": { "message": "Happy birthday" } } ] } } }
The search is that age must be 30 years old, but if there is a "Hanppy birthday" in the document, the relevance will be higher, and the search results will be at the top:
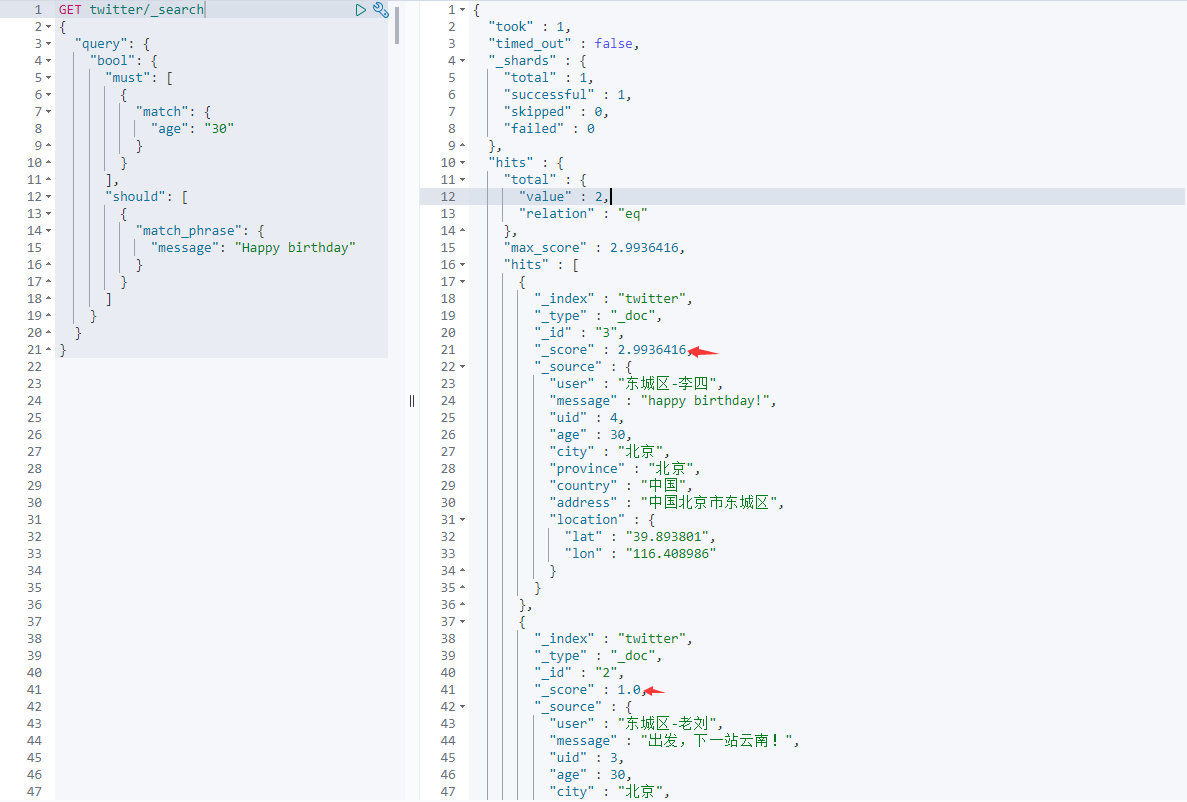
As we can see from the above results, the same two documents are aged 30 years. The first document has the string "Happy birthday" in the message, so its results are in the top and more relevant.We can get from its _You can see that in score.In the second document, age is 30, but its message does not contain the word "Happy birthday", but its result is still significant, except that the score is lower.
When using the composite query above, bool requests are usually must, must_not, should, and one or several of the filter s combined.We must pay attention to:
Query type pairs hits and _Impact of score | Clause | Impact #hits | Impact_score | | :------------ |:---------------:| -----:| | must | Yes | Yes | | must_not | Yes | No | | should | No* | Yes | | filter | Yes | No |
As the table above shows, should only affects hits in special cases.Normally, it does not affect the number of documents searched.So under what circumstances will the results of the search be affected?This is the case for should-only searches, that is, if you do not have must, must_in bool query In the case of nots and filter s, one or more shoulds must have a match to produce results, such as:
GET twitter/_search { "query": { "bool": { "should": [ { "match": { "city": "Beijing" } }, { "match": { "city": "Wuhan" } } ] } } }
The results of the above query are:
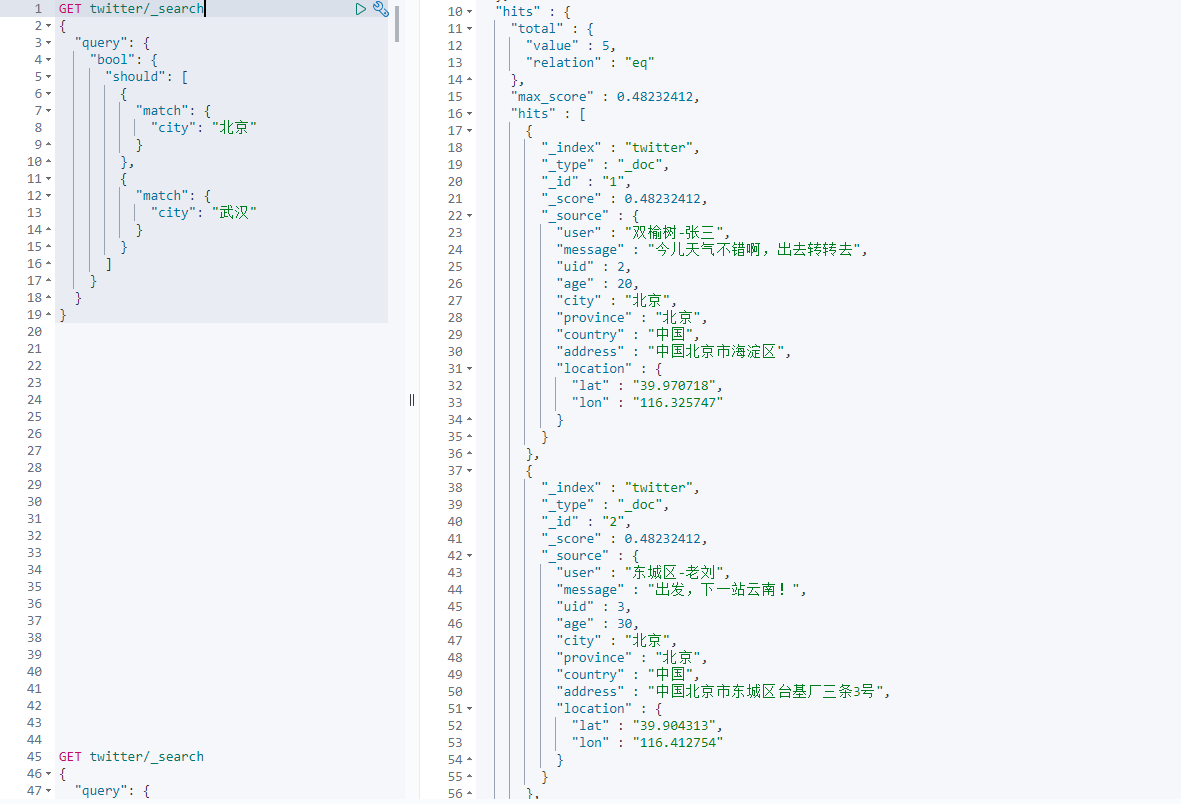
In this case, should will affect the results of the query.
Location Query
The most powerful thing about Elasticsearch is location queries.This is not available in many relational databases.Let's take a simple example: