SQL statement is a command grammar common to all relational databases, while JDBC API is only a tool to execute SQL statement. JDBC allows the same programming interface to execute SQL statement for different platforms and databases.
Basic concepts of relational database and basic commands of MySQL
A database is just a place to store user data. When users access and operate the data in the database, they need the help of the Database Management System. The full name of Database Management System is Database Management System, referred to as DBMS. Generally speaking, database and Database Management System are called database. Generally speaking, database includes not only the part of storing user data, but also the management system of managing database.
DBMS is the knowledge base of all data. It is responsible for the management of data storage, security, consistency, concurrency, recovery and access operations. DBMS has a data dictionary (also known as a system table) for storing information about each transaction it owns, such as name, structure, location and type. This data about data is also called metadata.
In the history of database development, the following types of database systems have appeared in chronological order:
network data model
Hierarchical database
relational database
Object-oriented database
An instance of a MySQL database can contain multiple databases at the same time. MySQL uses the following commands to see how many databases are included in the current instance
show databases;
create new database
create database [IF NOT EXISTS] database name;
Delete the specified database
delete database database name;
Enter the specified database
use database name;
Query how many tables are contained in the database
show tables;
View the table structure of the specified data table
desc shows that;
MySQL databases usually support the following two storage mechanisms:
MyISAM: This is MySQL's early default storage mechanism, and it does not support transactions well enough.
InnoDB: InnoDB provides transaction-safe storage mechanisms. InnoDB storage mechanism, if you do not want to use InnoDB tables, skip-innodb option can be used
ENGINE = MyISAM -- Mandatory use of MyISAM
ENGINE = InnoDB -- Force InnoDB
SQL Statement Foundation
The full name of SQL is Structured Query Language, a structured query language. SQL is the standard language for manipulating and retrieving relational databases. Standard SQL statements can be used to manipulate any relational databases.
Using SQL statements, programmers and database administrators (DBA s) can accomplish the following tasks:
Retrieving information in Databases
Update the database information
Change the structure of database
Change system security settings
Increase or Recycle User's Permission to Databases and Tables
Standard SQL statements can usually be divided into the following types:
Query Statement: It is mainly completed by select keyword. Query Statement is the most complex and functional statement in SQL Statement.
DML (Data Manipulation Language, Data Operating Language) Statement: Completed mainly by inset, update, delete keywords
DDL (Data Definition Language, Data Definition Language) Statement: It is mainly completed by create, alter, drop, truncate keywords
DCL (Data Control Language, Data Control Language) Statement: Completed mainly by grant and revoke keywords
Thing Control Statement: It is mainly completed by commit, rollback, savepoint keywords
Naming rules for identifiers:
Identifiers must usually begin with letters
Identifiers include letters, numbers and three special characters ($)
Do not use keywords or reserved words in the current database system. It is usually recommended that multiple words be linked together and separated by.
Objects in the same schema should not have the same name. The schema here refers to the external schema.
DDL statement
DDL statements are statements that operate on database objects, including creating, deleting and alter ing database objects.
Several Common Database Objects in Databases
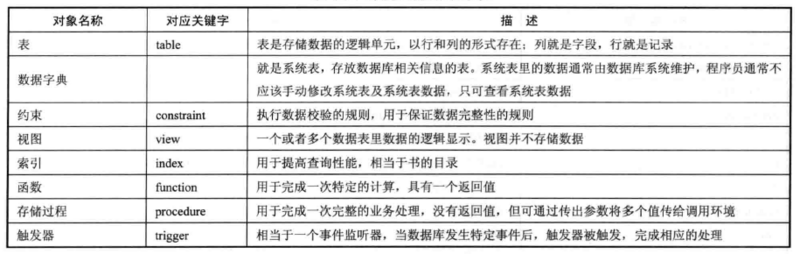
Syntax for creating tables
create table [Schema name.] Table name ( # You can define multiple column definitions columnName1 datatype [default expr] , ... )
Each column definition is separated by an English comma (,), and the last column definition does not need to use an English comma, but ends directly in brackets.
Column names are at the front and column types are at the back. If you want to specify the default value of a column, use the default keyword instead of the equal sign (=)
Using sub-query table-building statement, you can insert data at the same time of table-building. Grammar of Subquery Tables
create table [Schema name.]Table name [column[, cloumn...]] as subquery;
#Create a premium_info data table that is identical to user_info and identical to user_info create table premium_info as select * from user_info;
Modifying table structure grammar
alter table is used to modify table structure, which includes adding column definition, modifying column definition, deleting column, renaming column and so on. String values in SQL statements are caused not only by double quotation marks, but also by single quotation marks.
alter table Table name add ( #You can have multiple column definitions column_name1 datatype [default expr] , ... )
If only one column is added, parentheses can be omitted and only one column definition can be followed by add.
# Add a pre_id field to the premium_info data table with the type int; alter table premium_info add pre_id int; # Add name and duration fields to the premium_info data table, both of which are varchar(255) alter table premium_info add ( name varchar(255) default 'Jimmy', duration varchar(255) )
Modifying the grammar of column definitions
alter table Table name modify column_name datatype [default expr] [first|after col_name];
first or after col_name specifies that the target needs to be modified to the specified location, and the modification statement can only modify one column definition at a time.
#Modify the pre_id column of the premium_info data table to varchar(255) type alter table premium_info modify pre_id varchar(255); #Modify the duration column of premium_info to int type alter table premium_info modify duration int;
If you need MySQL support to modify multiple column definitions at once, you can use multiple modify commands after alter table
Grammar for deleting columns
alter table Table name drop column_name
# Delete the name field in the premium_info table alter talbe premium_info drop name;
Deleting column definitions from a database is usually successful. Deleting column definitions removes data from each row and frees up space occupied by the column in the data block. So it takes a long time to delete fields from large tables, because space needs to be reclaimed.
Two special syntaxes of MySQL: renaming data tables and completely changing column definitions
Syntax for renaming data tables
alter table Table name rename to New table name alter table premium_info rename to premium;
Grammar of the change option
alter table Table name change old_column_name new_column_name type [default expr] [first|after col_name];
alter table premium_info change duration time int;
Grammar for deleting tables
drop table table table name;
# Delete data tables drop table premium_info;
The effect of deleting data tables is as follows
The table structure is deleted and the table object no longer exists
All data in the table has also been deleted.
All relevant indexes and constraints of the table are also deleted.
Syntax of truncate table
Truncate is called truncate a table -- it deletes all the data in the table, but retains the table structure. Truncate is much faster than delete commands in DML, and unlike delete, truncate can delete specified records, truncate can only delete all records of the entire table at once. The syntax of the truncate command:
truncate table name
Database constraints
Constraints are data validation rules enforced on tables. Constraints are mainly used to ensure the integrity of data in databases. In addition, when the data in the table is interdependent, it can protect the relevant data from being deleted.
Five Integrity Constraints
Most databases support the following five types of integrity constraints.
NOT NULL: Non-null constraint specifying that a column cannot be null
UNIQUE: Unique constraint specifying that a column or combination of columns cannot be repeated
PRIMARY KEY: Primary key, specifying that the column's value uniquely identifies the record
FOREIGN KEY: A foreign key that specifies that the row record is subordinate to a record in the main table and is used primarily to ensure referential integrity.
CHECK: Check to specify a Boolean expression that the value of the corresponding column must satisfy
MySQL does not support CHECK constraints
According to the constraints on data columns, the constraints can be divided into the following two categories:
Single row constraints: each constraint constrains only one column
Multi-row constraints: Each constraint constrains multiple data columns
There are two opportunities to specify constraints for data tables:
Specify constraints for corresponding data columns while building tables
Create a table and add constraints by modifying the table
NOT NULL Constraints
Non-null constraints are used to ensure that specified columns are not allowed to be null. Non-null constraints are special constraints and can only be used as column levels.
NULL value characteristics in SQL:
Values of all data types can be null, including int, float, boolean, and so on.
Similar to java, empty strings are not equal to null, and zero is not equal to null.
Construct to specify non-null constraints:
create table null_test ( # A non-null constraint is established, which means that user_id cannot be null user_id int not null, # MySQL's non-null constraint cannot specify a name user_name varchar(255) default 'lin' not null, # The following column can be null by default user_location varchar(255) null )
Non-null constraints can also be added or removed when alter table is used to modify tables:
# Increase non-empty constraints alter table null_test modify user_location varchar(255) not null; # Cancellation of non-empty constraints alter table null_test modify user_name varchar(255) null; # Remove non-null constraints and specify default values alter table null_test modify user_location varchar(255) default 'Nantes' null;
UNIQUE constraint
Uniqueness constraints are used to ensure that duplicate values are not allowed for specified columns or combinations of specified columns, but multiple null values can occur (because null is not equal to null in the database)
Unique constraints can be established using either column-level constraint grammar or table-level constraint grammar. If you need to build composite constraints for multiple columns or specify constraint names for unique constraints, you can only use table-level constraint syntax
When a unique constraint is created, MySQL creates a corresponding unique index on the column or column combination where the unique constraint is located. If no unique constraint is given at least, the unique constraint defaults to the same column name
Using column-level constraint grammar to create unique constraints is very simple, as long as the unique keyword is added after the column definition.
test_name varchar(255) unique
If you need to create a unique constraint for a multi-column combination or want to specify a constraint name by yourself, you need to use table-level constraint grammar, which is as follows:
[constrain constraint name] constraint definition
# Create unique constraints when creating tables, using table-level constraint grammar to build constraints create table unique_test2 ( # A non-null constraint is established, which means that test_id cannot be null test_id int not null, test_name varchar(255), test_pass varchar(255), # Constructing Unique Constraints Using Tables and Constraint Grammar unique (test_name), # Construct unique constraints using table-level constraint grammar and specify constraint names constraint test_uk unique(test_pass)} );
The TABLE statement above establishes unique constraints for test_name and test_pass respectively, which means that the two columns cannot be empty. In addition, unique constraints can be established for the combination of the two columns.
# Create unique constraints when creating tables, using table-level constraint grammar to build constraints create table unique_test3 ( # A non-null constraint is established, which means that test_id cannot be considered NULL test_id int not null, test_name varchar(255), test_pass varchar(255), # Use table-level constraint grammar to construct unique constraints, specifying that a combination of two columns cannot be empty constraint test3_uk unique(test_name, test_pass) );
unique_test2 requires that neither test_name nor test_pass can be duplicated, while unique_test3 only requires that the combination of test_name and test_pass cannot be duplicated.
You can modify the table structure to add unique constraints
# Adding Unique Constraints alter table unique_test3 add unique(test_name, test_pass);
You can use modify keywords when modifying tables and column-level constraints for single columns to increase unique constraints
# Adding unique constraints to user_name column of null_test table alter table null_test modify user_name varchar(255) unique;
For most databases, deletion constraints are grammatical deletion of constraints using drop constraint names after alter table statements, but MySQL does not use this method, but uses drop index and constraint names to delete constraints.
# Delete test3_uk from the unique_test3 table alter table unique_test3 drop index test3_uk;
PRIMARY KEY constraint
Primary key constraints are equivalent to non-null constraints and unique constraints, i.e. columns with primary key constraints are neither allowed to have duplicate values nor null values; if primary key constraints are established for multiple column combinations, each column contained in multiple columns cannot be null, but only those column combinations are required not to be duplicated.
At most one primary key is allowed in each table, but this primary key constraint can be composed of multiple data columns. Primary keys are fields or combinations of fields in a table that uniquely determine a row of records.
Primary key constraints can be constructed using either column-level constraints or table-level constraints. Table-level constraint grammar is used only when combined primary key constraints are required for multiple fields. When a constraint is created using table-level constraint grammar, the constraint name can be specified for that constraint. MySql always names all primary key constraints PRIMARY
Create primary key constraints using primary key
Primary key constraints are created when tables are created using column-level constraint syntax:
create table primary_test ( # Establishing Primary Key Constraints test_id int primary key, test_name varchar(255) );
Create primary key constraints when creating tables, using table-level constraint syntax
create table primary_test2 ( test_id int not null, test_name varchar(255), test_pass varchar(255), # Specify the primary key named test2_pk, which is valid for most databases but not for mysql # The primary key constraint in MySQL database is still primary constraint test2_pk primary key(test_id) );
Primary key constraints are created when creating tables, and composite primary keys are created by multiple columns. Table-level constraint grammar is the only way to use them.
create table primary_test3 ( test_name varchar(255), test_pass varchar(255), # Establishing multi-column composite primary key constraints using table-level constraints primary key(test_name, test_pass) );
If you need to delete the primary key constraint of the specified table, use the drop primary_key sentence after the alter table statement
#Delete primary key constraints alter table primary_test3 drop primary key;
If you need to add primary key constraints to a specified table, you can add primary key constraints by modify ing column definitions, which will increase primary key constraints using column-level constraint grammar
Primary key constraints can also be add ed, which uses table-level constraint grammar to increase primary key constraints
# Adding Primary Key Constraints Using Column Level Constraint Grammar alter table_primary_test3 modify test_name varchar(255) primary key;
#Adding Primary Key Constraints Using Table Level Constraint Grammar alter table primary_test3 add primary key(test_name,test_pass);
MySQL only uses auto_increment to set up self-growth
create table primary_test4 ( # Establish primary key constraints and use self-growth test_id int auto_increment primary key, test_name varchar(255), test_pass varchar(255) );
FOREIGN KEY Constraints
Foreign key constraints mainly guarantee the referential integrity between one or two data tables. Foreign key is the referential relationship between two fields of a table or two fields of two tables. The foreign key ensures the reference relationship between the two fields concerned: the value of the foreign key column of the child (slave) table must be within the range of the value of the reference column of the main table, or be empty.
When the records of the master table are referenced by the records of the slave table, the master table records are not allowed to be deleted. The master table can only be deleted after deleting all the records of the slave table that refer to the records.
Only the primary key column or the unique key column of the main table can be referenced by the external key of the table, so as to ensure that the records from the table can be positioned accurately to the referenced records of the main table. You can have multiple foreign keys in the same table
Foreign key constraints are usually used to define one-to-many, one-to-one relationships between two entities. For one-to-many associations, foreign key columns are usually added at one end of the many. For one-to-one associations, either party can be selected to add foreign key columns, and the tables with foreign key columns are called slave tables. For many-to-many associations, an additional join table is needed to record their associations.
Column-level constraint grammar and table-level constraint grammar can also be used to establish foreign key constraints. If you only create foreign key constraints for individual data columns, you can use column-level constraint syntax; if you need to create foreign key constraints for multiple column combinations, or you need to specify a name for foreign keys, you must use table-level constraints.
Constructing foreign key constraints using column-level constraint grammar directly uses the references keyword, which specifies which table the column refers to and which column refers to the main table.
# In order to ensure that the master table referenced by the slave table exists, it is usually necessary to create the master table first. create table teacher_table1 ( #auto_increment: An automatic numbering strategy representing a database, usually used as the logical primary key of the database teacher_id int auto_increment, teacher_name varchar(255), primary key(teacher_id) ); create table student_table1 ( student_id int auto_increment primary key, student_name varchar(255), # Specify the java_teacher reference to the teacher_id column of teacher_table java_teacher int references teacher_table1(teacher_id) );
However, it is worth noting that although mysql supports the use of column-level constraint grammar to establish foreign key constraints, the foreign key constraints established by this column-level constraint grammar will not take effect. mysql only provides this column-level constraint grammar to maintain good compatibility with standard SQL. If foreign key constraints in mysql are to take effect, table-level constraint grammar should be used.
#In order to ensure that the master table referenced by the slave table exists, it is usually necessary to build the master table first. create table teacher_table ( #auto_increment: An automatic encoding strategy representing a database, usually used as the logical primary key of a data table teacher_id int auto_increment, teacher_name varchar(255), primary key(teacher_id) ); create table student_table ( student_id int auto_increment primary key, studnet_name varchar(255), # Specify the java_teacher reference to the teacher_id column of teacher_table java_teacher int, foreign key(java_teacher) references teacher_table(teacher_id) );
If table-level constraints are used, foreign keys are needed to specify the foreign key columns of this table, and references are used to specify which data columns are referenced to that table and to the main table. Using table-level constraint syntax, you can specify a constraint name for a foreign key. If no constraint name is specified when creating a foreign key constraint, MySQL will name the foreign key constraint table_name_ibfk_n, where table_name is the table name and N is an integer starting from 1.
If you need to explicitly specify the name of a foreign key constraint, you can use constraint to specify the name
create table teacher_table2 ( #auto_increment: An automatic encoding strategy representing a database, usually used as the logical primary key of a data table teacher_id int auto_increment, teacher_name varchar(255), primary key(teacher_id) ); create table student_table2 ( student_id int auto_increment primary key, studnet_name varchar(255), # Specify the java_teacher reference to the teacher_id column of teacher_table java_teacher int, # Use table-level constraint grammar to create foreign key constraints, specifying that the constraint for foreign key constraints is named student_teacher_fk constraint student_teacher_fk foreign key(java_teacher) references teacher_table(teacher_id) );
If you need to create foreign key constraints for multi-column combinations, you must use table-level constraint grammar
create table teacher_table ( teacher_name varchar(255), teacher_pass varchar(255), # Establishing composite primary keys in two columns primary key(teacher_name, teacher_pass) ); create table student_table ( # Establish primary key constraints for this table student_id int auto_increment primary key, student_name varchar(255), java_teacher_name varchar(255), java_teacher_pass varchar(255), # Use table-level constraint grammar to create foreign key constraints, specifying joint foreign keys for two columns foreign key(java_teacher_name, java_teacher_pass) references teacher_table(teacher_name, teacher_pass) );
The grammar of deleting foreign key constraints is also very simple. After alter table, add the word "drop foreign key constraints name".
# Delete the foreign key constraint named student_talbe_ibkf_1 on the student_table3 table alter table student_table drop foreign key student_table_ibkf_1;
Adding foreign key constraints usually uses the add foreign key command, as follows
# Modify the table of student_table to add foreign key constraints alter table student_table add foreign key(java_teacher_name, java_teacher_pass) references teacher_table(teacher_name, teacher_pass);
It is worth noting that foreign key constraints can refer not only to other tables, but also to themselves, which is often referred to as self-correlation.
# Use table-level constraint grammar to create external constraint keys and refer directly to itself create table foreign_test ( foreign_id int auto_increment primary key, foreign_name varchar(255), # Reference the refer_id of this table to the foreign_id column of this table refer_id int, foreign key(refer_id) references foreign_test(foreign_id) );
If you want to define that when you delete a master table record, the records from the slave table will also be deleted, you need to add on delete cascade or on delete set null after establishing a foreign key constraint. The first is to delete the master table record by cascading all the slave table records referring to the master table record; the second is to specify that when deleting the master table record, the slave table record foreign key referring to the master table record is set to NULL.
create table teacher_table ( teacher_id int auto_increment, teacher_name varchar(255), primary key(teacher_id) ); create table studnet_table ( # Establish primary key constraints for this table student_id int auto_increment primary key, studnet_name varchar(255), java_teacher int, # Use table-level constraint grammar to establish foreign key constraints and define cascade deletion foreign key(java_teacher) references teacher_table(teacher_id) on delete cascade # You can also use on delete set null );
CHECK constraint
The syntax for establishing CHECK constraints is simple, as long as check is added after the column definition of the build table
create table check_test ( emp_id int auto_increment, emp_name varchar(255), emp_salary decimal, # Create CHECK constraints check(emp_salary>0) );
Indexes
An index is a database object stored in a schema. Although the index always belongs to the data table, it belongs to the database object as well as the data table. The only way to create an index is to speed up the query of tables, which can quickly locate data by using fast access methods, thus reducing disk I/O.
Indexes, as database objects, are stored independently in data dictionaries, but they cannot exist independently. They must belong to a table.
There are two ways to create an index
Automation: When primary key constraints, unique constraints, and foreign key constraints are defined on the table, the system automatically creates the corresponding index for the data column.
Manual: Users can create index es by creating index statements
There are also two ways to delete an index
Automation: When a data table is deleted, the index on that table is automatically deleted
Manual: Users can delete the specified index on the specified data table by drop index... statement
The grammatical format for creating the index is as follows:
create index index_name on table_name (column[,column]...);
The following index will improve the speed of querying employees tables based on the last_name field
create index emp_last_name_index on employees(last_name);
Indexing multiple columns at the same time
# The following statement indexes the first_name and last_name columns of employees simultaneously create index emp_last_name_index on employees(first_name, last_name);
To delete an index in MySQL, you need to specify a table in the following grammatical format
drop index index index name on table name
The following SQL statement deletes the index of emp_last_name_idx in the employees table
drop index emp_last_index on employees;
The advantage of indexing is to speed up queries, but it also has the following disadvantages:
Similar to the catalogue of books, when records in data tables are added, deleted and modified, the database system needs to maintain the index, so it has certain system overhead.
Storage of index information requires a certain amount of disk space
view
A view looks very much like a data table, but it's not a data table because it can't store data. A view is just a logical display of data in one or more data tables.
Use the advantages of trying:
Access to data can be restricted
Make complex queries simple
Provides data independence
Different displays of the same data are provided
Because a view is only a logical display of data in a data table -- that is, a query result, creating a view is to establish the association between the view name and the query statement. As follows:
create or replace view View name as subquery
As can be seen from the above grammar, the above grammar can be used to create and modify views. The above syntax implies that if the view does not exist, a view is created; if the view with the specified view name already exists, a new view is used to replace the original view. The following subquery is a query statement, which can be very complex.
Once a view is created, there is no difference between using the view language and using the data table, but usually only querying the view data and not modifying the data in the view, because the view itself does not store the data.
create or replace view view_test as select teacher_name, teacher_pass from teacher_table;
Most of the time, we do not recommend directly changing the view's data, because the view does not store the data, it is just equivalent to a named query statement. To enforce that view data is not allowed to be changed, MySQL allows the use of the word with check option when creating a view, which is not allowed to be modified as follows:
create or replace view view_test as select teacher_name form teacher_table # Specify data that is not allowed to modify views with check option;
Delete the view using the following statement:
drop view view name
The following SQL statement deletes the view name just created earlier
drop view view_test;
Grammar of DML Statements
Unlike DDL, DML mainly operates on data in data tables. DML can accomplish the following three tasks:
Insert new data
Modify existing data
Delete unwanted data
The DML statement consists of insert in, update, and delete from commands.
insert into statement
Insert into is used to insert data into a data table. For standard SQL statements, only one record can be inserted at a time. The insert into grammar format is as follows:
insert into table_name [(column[,column..])] values(value,[,vlaue...]);
When insertion is performed, the table name can be bracketed to list all column names that need to be inserted, and the value can be bracketed to list the values that need to be inserted.
For example:
insert into teacher_table2 value ('Vincent');
If you do not want to list all columns in parentheses after a table, you need to specify values for all columns; if the value of a column is uncertain, you assign a null value to that column
insert into teacher_table2 # Use null instead of primary key column values values(null, 'Pigeau');
At this point, however, the value of the primary key column recorded by Pigeau is 2, not null inserted by the SQL statement, because the primary key column is self-growing and the system automatically assigns values to the column.
According to the foreign key constraint rule: the value in the foreign key column must be the value already existing in the reference column, so before inserting records from the table, it is usually necessary to insert records into the main table first, otherwise the foreign key column recorded from the table can only be null. Now insert records from table student_table2
insert into student_table2 # When interpolating in a foreign key column, the value of the foreign key column must be an existing value in the reference column. values (null, 'Mars', 2);
In some special cases, we can use insert statements with sub-queries, insert statements with sub-queries can insert more than one record at a time.
insert into student_table2(student_name) #Insert with the value of the subquery select teacher_name from teacher_table2;
MySQL allows multiple parentheses to contain multiple records after values, indicating that multiple parentheses of multiple records are separated by English commas (,)
insert into teacher_table2 # Insert multiple values at the same time values (null, 'Paris'), (null, 'Nantes');
update statement
The UPDATE statement is used to modify the records of the data table, which can be modified more than one record at a time, and which records can be modified by using the where clause. The absence of where clause means that the value of where expression is always true, that is, all records of the table are modified. The grammatical format of the update statement is as follows:
update teacher_table set column1 = value1[,column=value2]... [WHERE condition];
Using update, you can modify not only multiple records at one time, but also multiple columns at one time. Modifying multiple columns is achieved by using column1=value1,column2=value2 after the set keyword. Modifying the values of multiple columns is separated by English commas (,)
update teacher_table2 set teacher_name = 'king';
You can also specify that only specific records are modified by adding where conditions, as follows
update teacher_table set teacher_name = 'Forest' where teacher_id > 1;
delete from statement
The delete from statement is used to delete records from the specified data table. You do not need to specify a column name when deleting with the delete from statement, because the entire row is always deleted. The delete from statement can delete multiple lines at a time, which lines are limited by where sentences, and only records satisfying where conditions can be deleted. Without where restriction, all records in the table will be deleted
The grammatical format of the delete from statement is as follows:
delete from table_name [WHERE condition];
The following SQL statement will delete all records in the student_table2 table:
delete from studnet_table2;
You can also use where conditions to restrict deletion of only specified records, as shown in the following SQL statement:
delete form teacher_table2 where teacher_id > 2;
When the master table record is referenced by the slave table record, the master table record cannot be deleted. Only after deleting all the records from the slave table referring to the master table record, can the master table record be deleted. In another case, when defining foreign key constraints, the on delete cascade is defined between the master table record and the slave table record, or the on delete null is used to specify that when the master table record is deleted, the value of the foreign key column is set to null by referring to the slave table record of the record in the slave table from the table.
Single table query
The function of the select statement is to query data. Select statement is also the most abundant statement in SQL statement. Select statement can not only execute single table query, but also multi-table join query and sub-query. Select statement is used to select the intersection of specific rows and columns from one or more data tables.
The simplest function of the select statement is shown in the figure.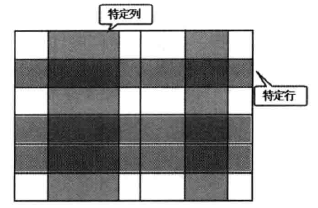
The syntax of the select statement for a single table query is as follows:
select colimn1 colimn2 ... form data source [WHERE condition]
The data sources in the above grammatical format can be tables, views, etc. As can be seen from the above grammatical format, the list after selection is used to select which columns, where condition is used to determine which rows to select, and only records satisfying where condition are selected; if there is no where condition, all rows are selected by default. If you want to select all columns, you can use an asterisk (*) to represent all columns
The following SQL statement will select all rows and columns in the teacher_table table table.
select * from teacher_table;
If you add where criteria, only records that meet where criteria are selected. The following SQL statement will select the values of the record student_name column whose java_teacher value is greater than 3 in the student_table table table table
select student_name from student_table where java_teacher > 3;
When using select statements for queries, you can also use arithmetic operators (+, -, *, /) in select statements to form arithmetic expressions: the rules for using arithmetic expressions are as follows
Arithmetic operators (+, -, *, /) can be used to create expressions for numeric data columns, variables and constants.
Some arithmetic operators (+, -,) can be used to create expressions for date-type data columns, variables and constants. Subtraction operations can be performed between two dates, and addition and subtraction operations can be performed between dates and values.
Operators can operate not only between columns and constants and variables, but also between columns.
The following select statement uses arithmetic operators
# A data column can actually be treated as a variable select teacher_id + 5 from teacher_table; # Query out records in the teacher_table table table where teacher_id* 3 is greater than 4 select * from teacher_table where teacher_id * 3 > 4;
It should be pointed out that after select ion, not only can it be a data column, but also an expression, but also can it be variables, constants and so on.
# A data column can actually be treated as a variable select 3*5, 20 from teacher_table;
The priority of arithmetic operators in SQL language is exactly the same as that in java language. MySQL uses concat function to perform string join operations.
# Select the result of the connection of teacher_name and'xx'strings select concat(teacher_name, 'xx') form teacher_table;
For MySQL, if NULL is used in arithmetic expressions, the return value of the entire arithmetic expression will be null; if NULL appears in string join operators, it will result in null as well.
select concat(teacher_name, null) from teacher_table;
If you don't want to use column names directly as column headings, you can give an individual name to a data column or expression. When aliasing a data column or expression, the alias follows the data column, separated by a space in the middle, or separated by an as keyword.
select teacher_id + 5 as MY_ID from teacher_table;
If special characters (such as spaces) are used in column aliases or case sensitivity is required, they can be achieved by adding double quotation marks to aliases.
# You can list aliases for the selected ones. The aliases include single quotation marks, so the aliases are caused by double quotation marks. select teacher_id + 5 as "MY'id" from teacher_table;
If you need to select multiple columns with aliases for multiple columns, commas are used to separate columns from multiple columns, but spaces are used to separate columns from column names.
select teacher_id + 5 MY_ID, teacher_name Teacher's name from teacher_table;
Aliases can be used not only for columns or expressions, but also for tables. The grammar of aliasing for tables is exactly the same as that of aliasing for columns or expressions.
select teacher_id + 5 MY_ID, teacher_name Teacher's name # Alias t for teacher_table from teacher_table t;
Column names can be treated as variables, so operators can also operate between columns.
select teacher_id + 5 MY_ID, concat(teacher_name, teacher_id) teacher_name from teacher_table where teacher_id * 2 > 3;
By default, select will select all eligible records, even if the two rows are exactly the same. If you want to remove duplicate rows, you can use distinct keyword to remove duplicate rows from query results and compare the execution results of the following two SQL statements:
# Select all records, including duplicate rows select student_name, java_teacher from student_table; # Remove duplicate rows select distinct student_name, java_teacher from student_table;
Note: When using distinct to remove duplicate rows, distinct follows the select keyword. Its function is to remove duplicate values of the following field combinations, regardless of whether the corresponding records are duplicated in the database or not.
You've already seen the role of where: you can control the selection of only the specified rows. Because where contains a conditional expression, basic comparison operators such as >, >=, <, <=, = and <> can be used. The comparison operator in SQL can not only compare the sizes between values, but also between strings and dates.
The comparison operator for judging whether two values are equal is a single equal sign=, and the difference operator is <>; the assignment operator in SQL is not an equal sign, but a colon equal sign (:=).
Special comparison operators supported by SQL
| operator | Meaning |
|---|---|
| expr1 between expr2 and expr3 | Require expr1 >= expr2 and expr2 <= expr3 |
| expr1 in(expr2,expr3,expr4,...) | expr1 is required to be equal to the value of any expression in the following parentheses |
| like | String matching, like after the string support wildcards |
| is null | Requires that the specified value be equal to null |
The following SQL statement selects all records whose student_id is greater than or equal to 2 and less than or equal to 4.
select * from student_table where student_id between 2 and 4; # Select all records with java_teacher less than or equal to 2 and student_id greater than or equal to 2 select * from student_table where 2 between java_teacher and student_id;
When using in comparison, one or more values must be listed in parentheses after in, which requires that the specified column be equal to any value in parentheses.
# Select all records with a value of 2 or 4 for the student_id, java_teacher columns select * from student_table where student_id in(2,4);
Similarly, values in parentheses can be constants, variables, or column names.
# Select all records with a value of 2 for the student_id, java_teacher columns select * from student_table where 2 in(student_id,java_teacher);
Like operators are mainly used for fuzzy queries. For example, if you want to query all records whose names begin with Sun, you need to use fuzzy queries. In fuzzy queries, you need to use like keywords. Two wildcards can be used in SQL statements: underscore () and percentage (%) where the underscore can represent an arbitrary character and percentage can represent any number of characters. The following SQL statement will query all the students whose names begin with Sun.
select * from student_table where student_name like 'Grandchildren%';
The following SQL statement will find out all students whose names are two characters
select * from student_table # Next, use two underscores to represent a character where student_name like '__';
In some special cases, query conditions need to use underscores or percentiles, do not want SQL to use underscores and percentiles as wildcards, which requires the use of escape characters, MySQL uses backslash (/) as escape characters.
# Choose all the students whose names begin with underlining select 8 from student_table where student_name like '\_%';
is null is used to determine whether some values are null or not, and it cannot be judged by = null because null=null returns null in SQL. The following SQL statement will select all records with student_name null in the student_table table table table
select * from student_table where student_name is null;
If there are multiple conditions to be combined after where sentence, SQL provides and and or logic operators to combine two conditions, and provides not to check the logical expression. The following SQL statement will select the student name as two characters, and all records whose student_id is greater than 3.
select * from student_table where student_name like '__' and studnent_id > 3;
The following SQL statement will select all records in the student_table table table whose names do not begin with underscores.
select * from student_table # Use not to decide where condition or not where not student_name like '/_%';
Priority of Compare Operators and Logic Operators in SQL
order by statement
The results after executing the query are sorted by insertion by default; if you need to sort the query results by the size of a column value, you can use the word order by
The ORDER BY statement is used to sort the result set according to the specified column. The ORDER BY statement defaults to sort records in ascending order. If you want to sort records in descending order, you can use the DESC keyword
The grammar of the order by sentence is as follows:
order by column_name1 [desc], column_name...
When sorting, desc keyword should be used after the column (corresponding to asc keyword, the effect of not using ASC keyword is exactly the same, because the default is to sort in ascending order). Column names, sequence names and column aliases can be used to set sort columns in the above grammar. The following SQL statement selects all records in the student_table table table table, and then arranges them in ascending order according to the java_teacher column.
select * from student_table order by java_teacher;
If you need to sort by multiple columns, asc and desc of each column must be set separately. If multiple sorting columns are specified, the first sorting column is the primary sorting column, and the second sorting will only work if there are multiple identical values in the first column. If the SQL statements are first sorted in descending order of the java_teacher column, when the values of the java_teacher column are the same, they are sorted in ascending order of the student_name column.
select * from student_table order by java_teacher desc, student_name;
Database function
Each database extends some functions on the basis of standard SQL. These functions are used for data processing or complex computation. They usually calculate a set of data to get the final output. Generally, a function has one or more inputs, which are called parameters of the function. The parameters are judged and calculated within the function, and only one value is used as the return value. Functions can appear in various places in the SQL statement. The most common location is in the where clause after select.
According to the way the function deals with multi-line data, the function is divided into single-line function and multi-line function. The single-line function calculates the input value of each line separately, and each line gets a result which is returned to the user. The multi-line function calculates the input value of multi-line as a whole, and finally only one result is obtained.
The functions in SQL are somewhat similar to those in java, but the functions in SQL are independent program units. That is to say, when calling a function, it does not need to use any class or object as the caller, but directly executes the function. As follows:
function_name(arg1,arg2...)
Multi-line functions, also known as aggregation functions and grouping functions, are mainly used to complete some statistical functions, which are basically the same in most databases. But the single-line functions in different databases are very different. The single-line functions in MySQL have the following characteristics
The parameters of a one-line function can be variables, constants, or data columns. A single-line function can take more than one parameter, but only one value is returned.
A single-line function acts on each line individually, and each line (which may include multiple parameters) returns a result.
Using one-line functions can change the data type of parameters. One-line functions support nested use, that is, the return value of inner functions is the parameter of outer functions.
MySQL's single-line function classification is shown in the figure.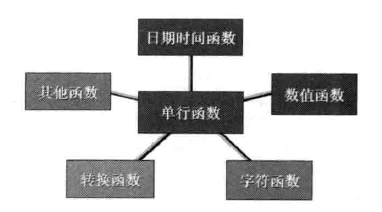
The data types of MySQ database can be roughly divided into numerical type, character type and date-time type. So mysql provides corresponding functions. Conversion functions are mainly responsible for type conversion, and other functions are roughly divided into the following categories
Bit function
Process Control Function
Encryption and decryption function
Information function
# Select the character length of the teacher_name column in the teacher_table table table select char_length(teacher_name) from teacher_table; # Calculate the sin value of the character length of the teacher_name column select sin(char_length(teacher_name)) from teacher_table; # To add a certain amount of time to the specified date, interval is the key word in this usage, requiring a numerical value and a unit. select DATE_ADD('1998-01-02', interval 2 MONTH); # Get the current date select CURDATE(); # Get the current time select curtime(); # The following MD5 is the MD5 encryption function select MD5('testing');
MySQL provides the following functions to handle null
ifnull(expr1, expr2): If expr1 is null, return expr2, otherwise return expr1
nullif(expr1, expr2): If expr1 and expr2 are equal, return null, otherwise return expr1
if(expr1, expr2, expr3): A little like?: Trinomial operators, if expr1 is true, not equal to 0, and not equal to null, return expr2, otherwise return expr3
isnull(expr1): Determines whether expr1 is null, returns true if null, or false if NULL
# If student_name is listed as null, return'No name' select ifnull(student_name, 'No name') from student_table; # If CTO_name is listed as'Wu Bureau', return null select nullif(CTO_name, 'Wu bureau') from CTO_table; # If student_name is listed as null, return'No Name', otherwise return'Named' select if(isnull(student_name), 'No name', 'Have a name') from student_table;
case function
case function, process control function. case functions have two uses
Grammar of the first use of case functions
case value when compare_value1 then result1 when compare_value2 then result2 ... else result end
The case function compares value with compare_value1, compare_value2, and... In turn. If value is equal to the specified compare_value1, the corresponding result1 is returned, otherwise the result after else is returned.
# If java_teacher is 1, return'Java Teacher', return'Spring Teacher'for 2, or return'Other Teachers'. select student_name, case java_teacher when 1 then 'Java Teacher' when 2 then 'Spring Teacher' else 'Other teachers' end from student_table;
Grammar of the second use of case functions
case when condition1 then result1 when condition2 then result2 ... else result end
Conditional expression returning boolean value
# Primary engineers with id less than 3, intermediate engineers with id 3-6 and senior engineers with id less than 3 select employees_name, case when employees_id <= 3 then 'Junior Engineer' when employees_id <= 6 then 'Intermediate Engineer' else 'Senior Engineer' end from employees_table;
Grouping and group functions
A group function is a multi-line function mentioned earlier. A group function is a group of records that are calculated as a whole and return a result instead of a result for each record.
avg([distinct|all]expr): Calculates the average of multiple expr rows, where expr can be a variable, constant, or data column, but its data type must be numeric. Use distinct to indicate that duplicate values are not computed; all indicates that duplicate values need to be computed
count({*|[distinct|all] expr}): Calculates the total number of exprs in multiple rows, where exprs can be variables, constants, or data columns, but the data type must be numeric. Use asterisk (*) to indicate the number of rows recorded in the table
max(expr): Calculate the maximum expr for multiple lines
min(expr): Calculate the minimum value of multiline expr
Sum ([distant | all] expr): Calculates the sum of multiple exprs
# Calculate the number of records in the student_table table table table select count(*) # Calculate the total number of values for the java_teacher column select count(distinct java_teacher) # Statistics the sum of all student_id s select sum(student_id) # The result of the calculation is the number of rows recorded in 20* select sum(20) # Select the maximum value of student_id in the student_table table table select max(student_id) # Select the minimum value of student_id in the student_table table table select min(student_id) # Because expr in sum is constant 23, the value of each line is the same # Use distinct to force no duplicate values, so the following calculation results are 23 select sum(distinct 23) # null is not counted when counts are used to count rows select count(student_name) # For columns where null may occur, you can use the ifnull function to process the column # Calculate the average of all records in the java_teacher column select avg(ifnull(java_teacher, 0)) from student_table; # distinct and * cannot be used simultaneously
group by statement
A group function treats all records as a group. In order to group records explicitly, a group by clause can be used after a select statement, usually followed by one or more column names, indicating that the query results are grouped according to one or more columns. When the values of one or more columns are identical, the system treats these records as a group.
SQL GROUP BY grammar
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name
# count(*) will yield a result for each group select count(*) from student_table # Consider a set of records with the same java_teacher column value group by java_teacher;
If multiple columns are grouped, the values of multiple columns are required to be exactly the same before they are considered as a group.
# count(*) will yield a result for each group select count(*) from student_table # When the values of the java_teacher and student_name columns are exactly the same, they are treated as a set. group by java_teacher, student_name;
having statement
If you need to filter the grouping, you should use the have clause, which is followed by a conditional expression. Only the grouping that satisfies the conditional expression can be selected. The having clause and where clause are very confusing. They both have filtering functions, but they have the following differences.
You cannot filter groups in where clauses, where clauses are only used to filter rows. The filter group must use the have clause
You can't use a group function in where clause, but a group function can only be used in having clause.
The reason for adding the HAVING clause in SQL is that the WHERE keyword cannot be used with the aggregate function.
SQL HAVING grammar
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value
select * from student_table group by java_teacher # Filter groups having count(*) >2;
Multi-table join query
The following book and student tables: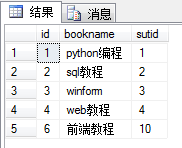
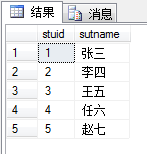
cross join
Cross connection does not require any connection conditions. Returns all rows in the left table, each row in the left table combined with all rows in the right table. Crosslinks are also called Cartesian products.
select * from book as a # Cross join cross join, equivalent to generalized Cartesian product cross join stu as b order by a.id
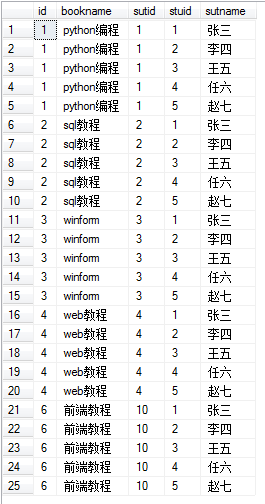
Natural join
Natural joins use the same-name columns in two tables as join conditions; if two tables do not have the same-name columns, natural joins work exactly the same as cross-joins because there are no join conditions.
select s.*, teacher_name from student_table s # Natural join natural join uses the same column in two tables as join condition natural join teacher_table t;
The column value of the joined column is compared using the equal (=) operator in the join condition, but it uses the selection list to indicate the columns included in the query result set and to delete the duplicate columns in the join table.
Connection with using clause
The using clause can specify one or more columns to display the same-name columns in the specified two tables as join conditions. Assuming that there are more than one column with the same name in two tables, if natural join is used, all columns with the same name will be treated as join conditions; using clause, you can show which columns with the same name are specified as join conditions.
select s.*, teacher_name from student_table s # join joins another table join teacher_table t using(teacher id);
Connection using on Clause
The most commonly used connection method, and each on Clause specifies only one connection condition. This means that if an N-table connection is required, an N-1 join...on pair is required.
select s.*, teacher_name from student_table s # join joins another table join teacher_table t # Use on to specify connection conditions on s.java_teacher = t.teacher_id;
In addition to the equivalence condition, the connection condition of on clause can also be non-equivalence condition.
select s.*, teacher_name from student_table s # join joins another table join teacher_table t # Use on to specify connection conditions on s.java_teacher > t.teacher_id;
Equivalent join: Compare the column values of the joined column with the equal sign (=) operator in the join condition, and list all columns in the joined table, including duplicate columns, in the query result.
Unequal join: Compare column values of joined columns using comparison operators other than equal operators under join conditions. These operators include >,>=,<=,<,<,!>,!<and<>
External Link or Left or Right External Link
The three outer joins are left[outer]join, right[outer]join and full[outer]join. The connection conditions of these three outer joins are specified by the on clause, which can be either equivalent or non-equivalent.
Left join
Based on the left table, the data of a.stuid = b.stuid are connected, and then the corresponding items which are not found in the left table are displayed. The right table is listed as null.
select * from book as a left join stu as b on a.sutid = b.stuid
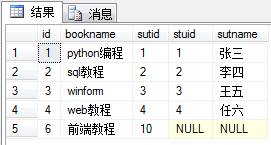
Right join
Based on the right table, the data of a.stuid = b.stuid are connected, but the corresponding items which are not found in the right table are displayed, and the left table is listed as null.
select * from book as a right join stu as b on a.sutid = b.stuid
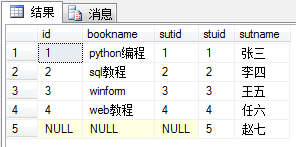
Full connection
A complete external join returns all rows in the left and right tables. When a row does not match rows in another table, the selection list column of another table contains null values. If there are matching rows between tables, the entire result set row contains the data values of the base table
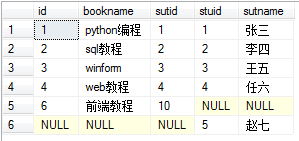
Subquery
Subquery is to nest another query in the query statement. Subquery can support multi-level nesting. For a normal query statement, sub-queries can appear in two places
The form statement is then treated as a data table, which is also called an in-line view, because the essence of the sub-query is a temporary view.
Value of where condition as filter condition
Points of Attention in Using Subqueries
Subqueries are enclosed in parentheses
When subqueries are used as data tables (after from), they can be aliased. When data columns are qualified as prefixes, subqueries must be aliased.
When subqueries are used as filtering conditions, the readability of queries can be enhanced by placing subqueries on the right side of comparison operators.
When sub-queries are used as filtering conditions, single-line sub-queries use single-line operators and multi-line sub-queries use multi-line operators.
select * # Think of subqueries as data tables from (select * from student_table) t where t.java_teacher > 1;
If a subquery returns a single row or column value, it is used as a scalar value, and a single row record comparison operator can also be used.
select * from student_table where java_teacher > # Returning single-row, single-column subqueries can be used as scalar values (select teacher_id from teacher_table where teacher_name = 'Pigeau');
If a subquery returns multiple values, keywords like in, any, and all need to be used
in can be used independently, at this point, multiple values returned by a subquery can be considered as a list of values
select * from student_table where student_id in (select teacher_id from teacher_table);
Any and all can be used in conjunction with operators such as >,>=,<,<=,<>,=. The combination with any means greater than, greater than or equal to, less than, less than or equal to, not equal to, or equal to any of the values; the combination with all means greater than, greater than or equal to, less than, less than or equal to, not equal to, or equal to all the values.
= any and in have the same effect
select * from student_table where student_id = any(select teacher_id from teacher_table);
<ANY should be less than the maximum value in the list of values, and>ANY should be greater than the minimum value in the list of values. <ALL requires less than the minimum value in the list of values,>ALL requires greater than the maximum value in the list of values.
# Select records in the student_table table table with student_id greater than all teacher_id in the teacher_table table table select * from student_table where student_id > all(select teacher_id from teacher_table);
There is also a sub-query that can return multiple rows and columns, where there should be corresponding data columns in the clause, and use parentheses to combine multiple data columns.
select * from student_table where (student_id, student_name) =any(select teacher_id, teacher_name from teacher_table);
Set operation
In order to perform set operations on two result sets, these two result sets must satisfy the following conditions
The number of data columns contained in the two result sets must be equal
The data types of the data columns contained in the two result sets must also correspond one to one.
union operation
Syntax Format of union Operations
Select statement union select statement
Query all teachers and students whose primary key is less than 4
# The results of the query consist of two columns, the first being the int type and the second being the varchar type. select * from teacher_table union select student_id , student_name from student_table;
minus operation
The grammatical format of minus operations is not supported by MySQL.
Select statement minus select statement
If you subtract from all student records the same ID and name recorded by the teacher, you can do the following minus operation
select student_id, student_name from student_table minus # The number of data columns of the two result sets is equal, and the data types correspond to each other, so minus operation can be performed. select teacher_id, teacher_name from teacher_table;
intersect operation
Grammatical Format of Interect Operations
Select statement intersect select statement
Find out the records with the same ID and the same name as the teacher's record in the student's record.
select student_id, student_name from student_table intersect # The number of data columns of the two result sets is equal, and the data types correspond one by one, so intersect operation can be performed. select teacher_id, teacher_name from teacher_table;