1. introduction
When there is a large amount of data in a table, it is natural for us to think of splitting the table into many small tables. When we execute the query, we go to each small table to query. Finally, we summarize the data set and return it to the caller to speed up the query. For example, the order table and inventory table of e-commerce platform have been read and written for many years, and the accumulated data is extremely huge. At this time, we can think of the method of table partition to reduce the operation and maintenance costs and improve the reading and writing performance. For example, put the orders in the first half of the year into a historical partition table, and put the inactive inventory into a historical partition table. As of SQL Server 2016, a table or index can have up to 15000 partitions.
2. table partition
2.1 division scope
Partition range refers to the partition boundary conditions of the tables to be partitioned based on the key fields in the business selection table. After the partition, the specific location of the data is very important, so that only the corresponding partition can be accessed when necessary. Note that partition refers to the logical separation of data, not the physical location of data on the disk. The location of data is determined by the file group, so it is generally recommended that a partition corresponds to a file group.
2.2 partition key
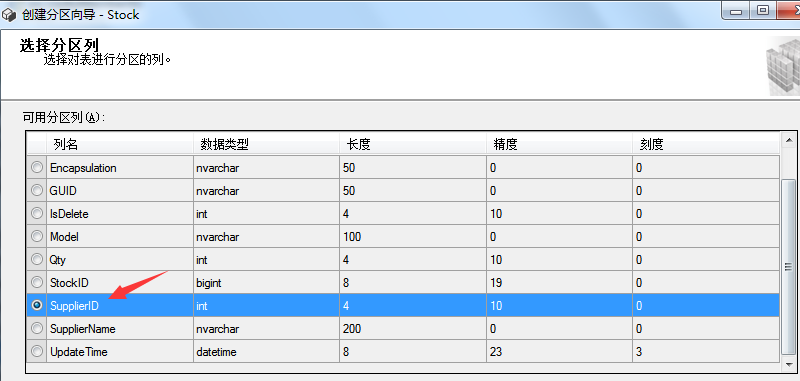
The fields in the partition table can be used as partition keys, such as the supplier ID in the inventory table. The first step in partitioning tables and indexes is to define the key data for partitioning.
2.3 index partition
In addition to partitioning the data set of the table, you can also partition the index. Partitioning the table and its index with the same function usually optimizes performance.
3. Create table partition
3.1 creating a filegroup
In the demonstration example here, I add three filegroups to the TestDB database according to the business scenario, and the three filegroups correspond to three partitions respectively. The advantage of multiple filegroups is that they can put data into corresponding filegroups according to different business scenarios, optimize performance and maintain data at the same time. The number of filegroups is determined by the hardware. It is better to have one filegroup corresponding to one partition for easy maintenance. Usually filegroups are on different disks, but because of the demonstration, I only store them on one disk.
--Create four filegroups
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup1
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup2
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup3
3.2 specify file group storage path
After creating a filegroup, specify the location and size of the disk where the filegroup is stored.
--Create four ndf Files, corresponding to each filegroup, FILENAME File storage path ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile1', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile1.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup1 ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile2', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile2.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup2 ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile3', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile3.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup3
Note (attach delete filegroup T-SQL):
ALTER DATABASE [TestDB] REMOVE FILE SupIDGroupFile3
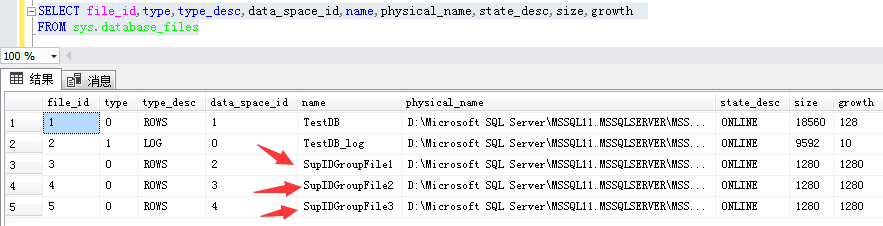
You can view the file group storage information through the following T-SQL statements:
SELECT file_id,type,type_desc,data_space_id,name,physical_name,state_desc,size,growth
FROM sys.database_files
3.3 create partition function
How to create table partition boundary values must be determined according to the business scenario. For example, the inventory table of my test library has about 360000 data, and the inventory data of some suppliers is much larger than that of other suppliers, so I can consider using the supplier ID field as the boundary value partition. For example: according to T-SQL statistics, 18080 suppliers have the largest inventory data, so I can divide 18080 suppliers into three areas.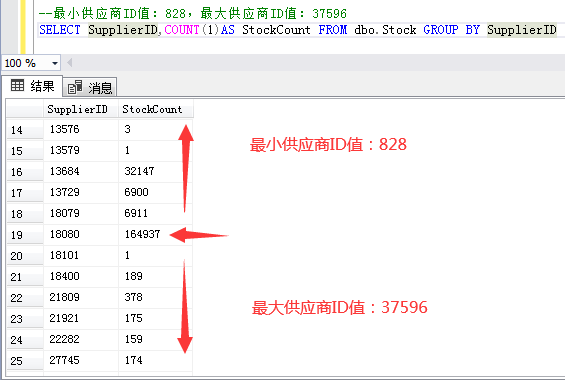
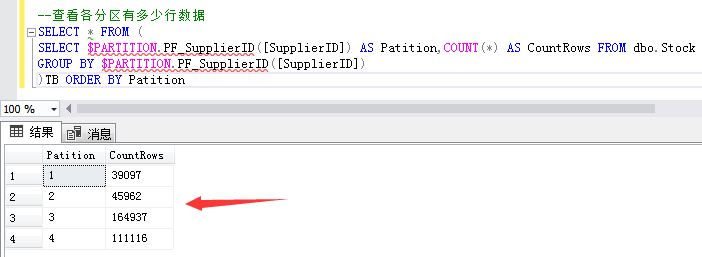
The first partition range record: 39097 inventory data with supplier ID less than or equal to 13570.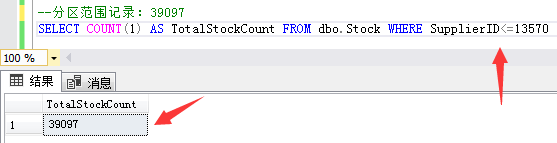
The second partition range record: 45962 inventory data with supplier ID greater than 13570 and less than or equal to 18079.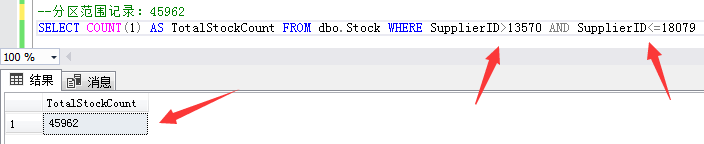
The third partition range records: 164937 inventory data with supplier ID greater than 18079 and less than or equal to 18080.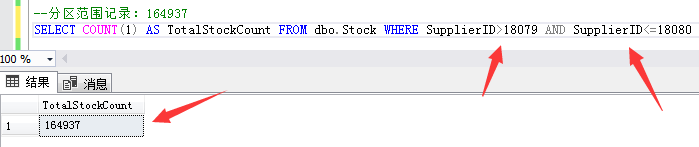
The fourth partition range record: 111116 inventory data with supplier ID greater than 18080.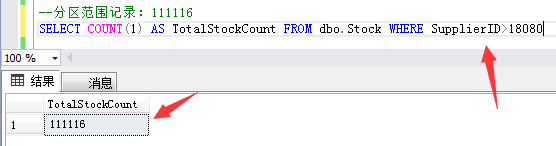
According to the above partition range records, we can set the supplier ID as the boundary value and execute the following T-SQL statement to set the boundary value:
--Set boundary value CREATE PARTITION FUNCTION PF_SupplierID(int) AS RANGE LEFT FOR VALUES (13570,18079,18080)
After execution, it is shown as follows:
3.4 create partition scheme
Execute the following T-SQL statement to create the partition scheme:
--Create partition scheme
CREATE PARTITION SCHEME PS_SupplierID
AS PARTITION PF_SupplierID TO ([PRIMARY], [SupIDGroup1],[SupIDGroup2],[SupIDGroup3])
After execution, it is shown as follows:
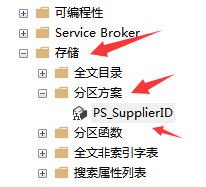
3.5 create partition table
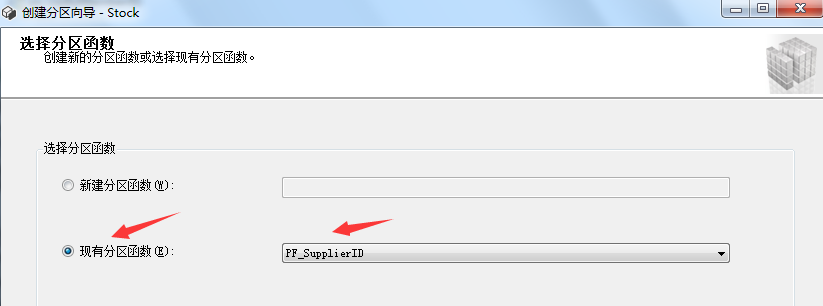
The above partitioning steps are all prepared for the next step of creating partition tables. Now let's see how to create partition tables. Right click the table to be partitioned - > Save - > create partition. The specific steps are as follows: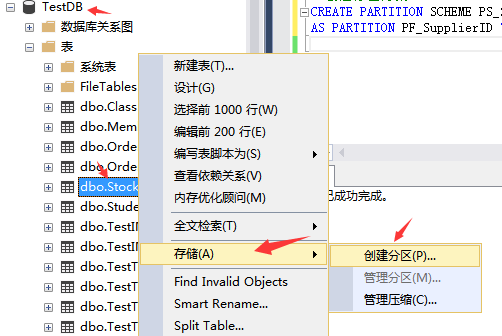
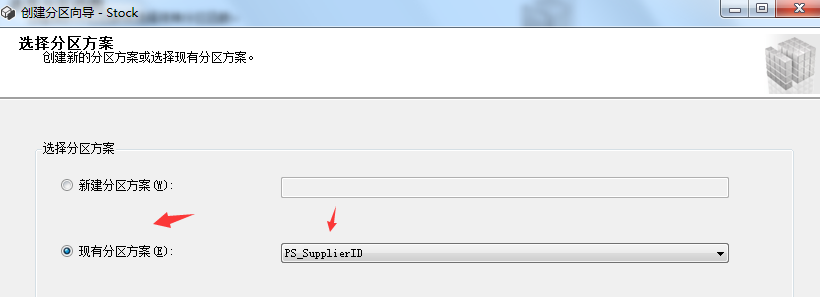
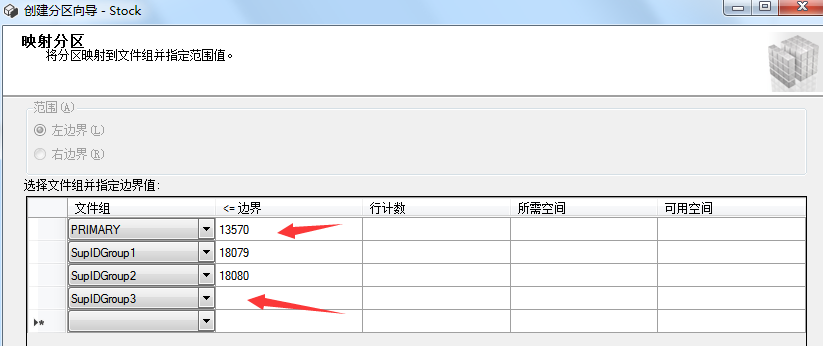
3.6 create partition index
--Create partition index CREATE NONCLUSTERED INDEX [NCI_SupplierID] ON dbo.Stock ( SupplierID ASC ) INCLUDE ( [Model],[Brand],[Encapsulation]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO
perhaps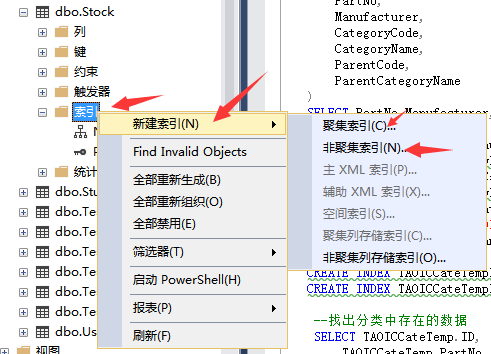
After execution, it is shown as follows:
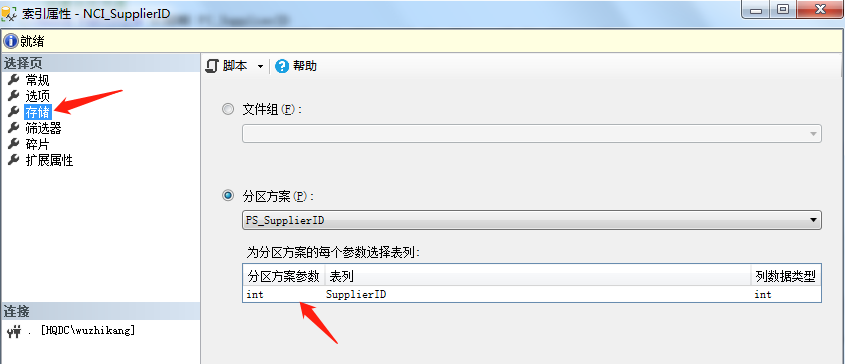
After creating the index, let's take a look at the partition:
--Check how many rows of data are in each partition SELECT * FROM ( SELECT $PARTITION.PF_SupplierID([SupplierID]) AS Patition,COUNT(*) AS CountRows FROM dbo.Stock GROUP BY $PARTITION.PF_SupplierID([SupplierID]) )TB ORDER BY Patition
Finally, let's look at the table data query after adding indexes: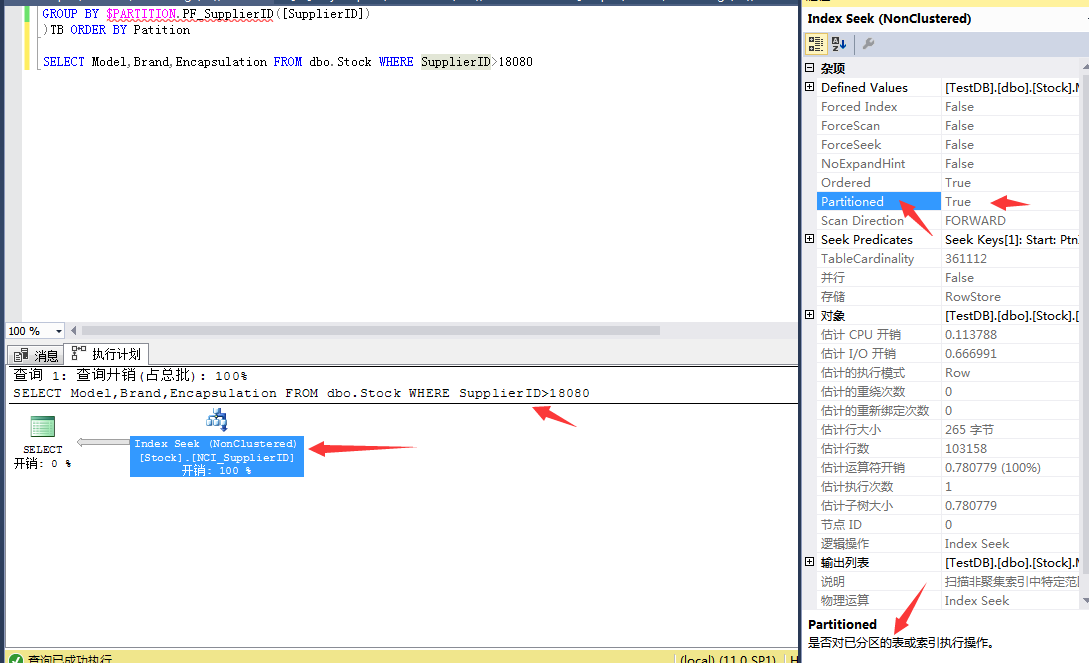
4. Advantages and disadvantages of table partition
Advantage:
● improve query performance: query on partition objects can only search the partition they care about, and improve the retrieval speed.
● enhanced availability: if one partition of the table fails, the data of the table in other partitions is still available.
● convenient maintenance: if a partition of the table fails, you need to repair the data, just repair the partition.
● balanced I/O: different partitions can be mapped to different disks to balance I/O and improve the performance of the whole system.
Disadvantages:
Partition table correlation: there is no way to directly convert existing tables to partition tables.