Introduction case
create table test01 ( a1 int(4) not NULL, a2 int(4) not NULL, a3 int(4) not NULL, a4 int(4) not NULL ); alter table test01 add index idx_a1_a2_a3_a4(a1,a2,a3,a4);
① explain select a1,a2,a3,a4 from test01 where a1=1 and a2=2 and a3=3 and a4=4; -- Recommended writing explain select a1,a2,a3,a4 from test01 where a4=4 and a3=3 and a2=2 and a1=1; -- Above 2 SQL,All composite indexes are used
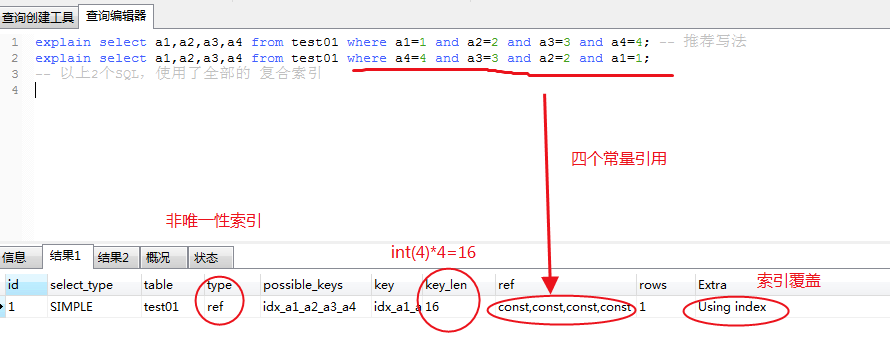
② explain select a1,a2,a3,a4 from test01 where a1=1 and a2=2 and a4=4 order by a3=3; -- above sql Yes a1,a2 Two indexes. The two fields do not need to be queried back to the table, --yes using index; and a4 The index is invalidated due to cross column use
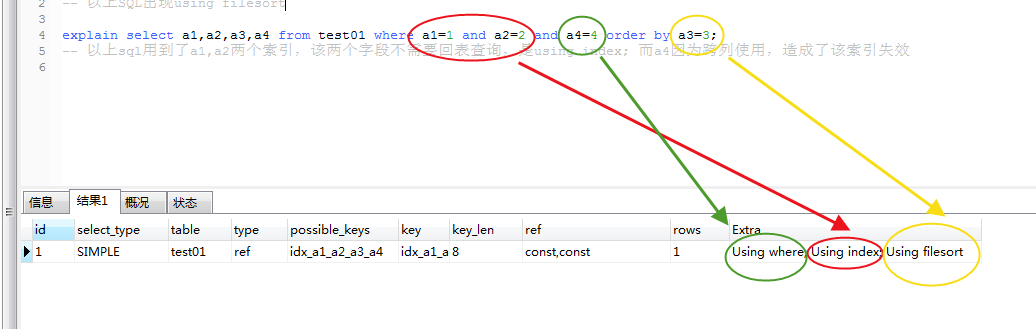
③ explain select a1,a2,a3,a4 from test01 where a1=1 and a4=4 order BY a3=3; -- above SQL Appearing Using As shown below
1. Single table optimization case
Table creation:
create table book( bid int(4) primary key, name varchar(20) not null, authorid int(4) not null, publicid int(4) not null, typeid int(4) not null ); insert into book values(1,'tjava',1,1,2) ; insert into book values(2,'tc',2,1,2) ; insert into book values(3,'wx',3,2,1) ; insert into book values(4,'math',4,2,3) ; commit;

-- query authorid=1 And typeid 2 or 3 and according to typeid Sorted in descending order bid explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ;

Obviously, this table has type=all and no index, so it needs to be optimized.
1. Introduction optimization
alter table book add index idx_bta (bid,typeid,authorid);

It can be optimized to using index: it indicates that the performance has been improved and index coverage has occurred. As long as all the columns used are in the index, it is index overwrite
using filesort: high performance consumption.
An "extra" sort (query) is required.
It is common in the order by statement. For a single index: where fields, order by fields
using where (table back query required)
Suppose age is an index column
However, in the query statement select age,name from... where age =..., the original table must be queried for Name in this statement, so using where will be displayed
2. Adjust the order of indexes according to the actual parsing order of SQL
The parsing order of SQL is: from... on... join... where... group by... having... select distinct... order by... limit
The order of indexing should be: first reference the field after where, and then select the field after
-- Once the index is upgraded and optimized, the previously discarded index needs to be deleted to prevent interference. drop index idx_bta on book; -- according to SQL Adjust the order of indexes according to the actual parsing order: alter table book add index idx_tab (typeid,authorid,bid); -- Although you can query back to the table bid,But will bid Put it in the index to promote the use using index ; explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ;

3. Adjust the index order again
Because the range query in sometimes fails, exchange the order of indexes and put typeid in(2,3) last.
drop index idx_tab on book; -- Exchange index order alter table book add index idx_atb (authorid,typeid,bid); explain select bid from book where authorid=1 and typeid in(2,3) order by typeid desc ; -- The parsing order is where and order by Splicing sequence: first authorid,after typeid,After execution select Index of bid -- authorid,typeid,bid The order of is consistent with that of the composite index, and there is no cross column using index

Summary:
a. The best left prefix maintains the consistency of index definition and order of use

b. The index needs to be optimized step by step
c. Put the range query with In at the end of the where condition to prevent invalidation.
Note: This is not bad
Note: in this example, both Using where(Need to return to the original table); Using index(No need to return to the original table): reason: where authorid=1 and typeid in(2,3)in authorid In index(authorid,typeid,bid)Therefore, there is no need to go back to the original table (it can be found directly in the index table); and typeid Although it is also indexed(authorid,typeid,bid)Medium, but with in The range query has enabled the typeid Index failure(See index type range),Therefore, it is equivalent to No typeid This index, so you need to go back to the original table( using where); For example, none of the following In,Will not appear using where explain select bid from book where authorid=1 and typeid =3 order by typeid desc ; You can also pass key_len prove In Can invalidate an index.
2. Double table optimization case
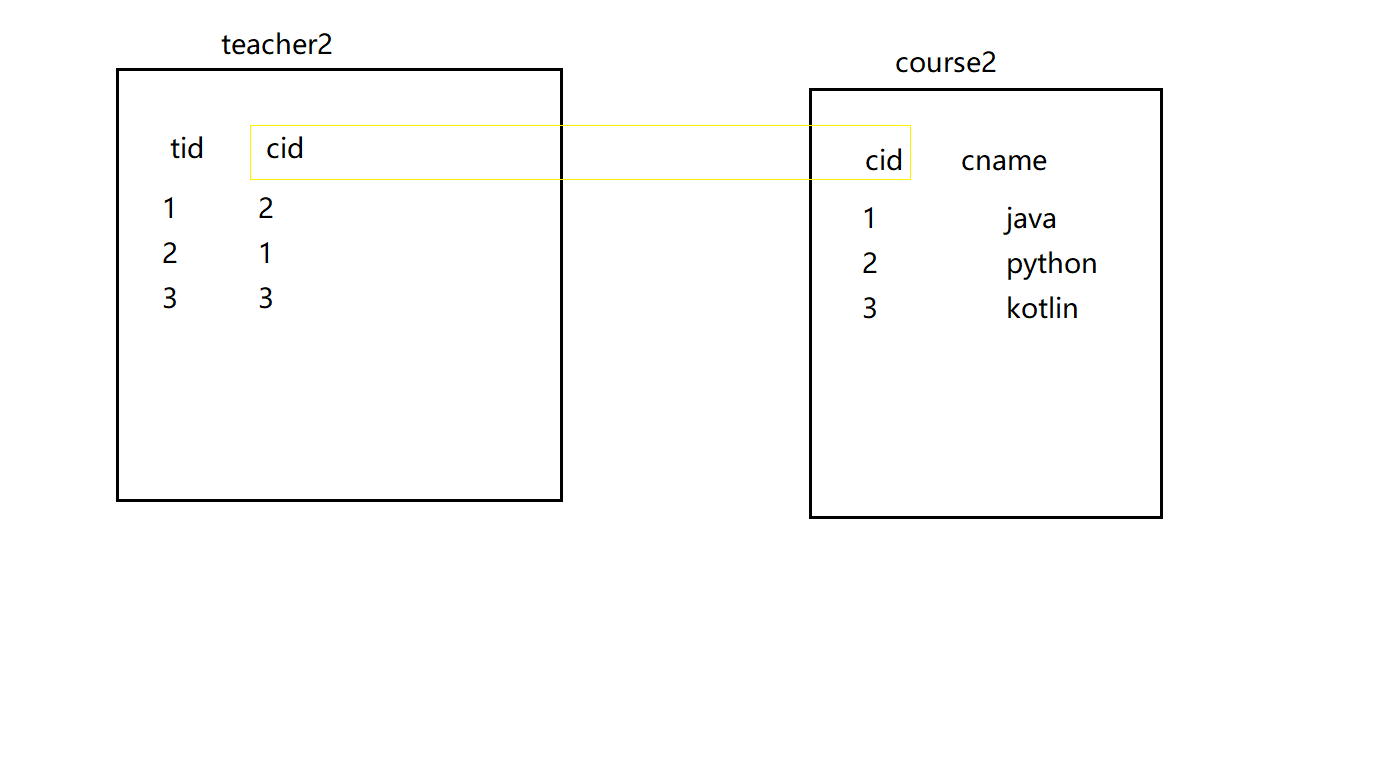
Table creation:
create table teacher2( tid int(4) primary key, cid int(4) not null ); insert into teacher2 values(1,2); insert into teacher2 values(2,1); insert into teacher2 values(3,3); create table course2( cid int(4) , cname varchar(20) ); insert into course2 values(1,'java'); insert into course2 values(2,'python'); insert into course2 values(3,'kotlin'); commit;
Multi table query:
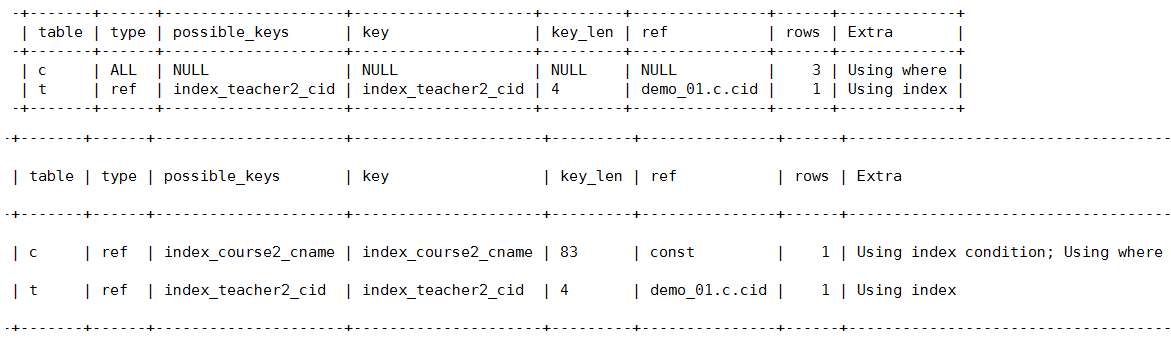
explain select * from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';
Which table is the Index added to?
Small table: 10
Large meter: 300
where Small table.x 10 = Big watch.y 300; --How many cycles? 10
Big watch.y 300 = Small table.x 10 --300 cycles
Small table drives large table:
select ...where Small table.x10 = Big watch.x300 ;
for(int i=0;i<Small table.length;i++) Execute 10 times
{
for(int j=0;j<Big watch.length;j++) 300 times
{
...
}
}
Large table drives small table:
select ...where Big watch.x300=Small table.x10 ;
for(int i=0;i<Big watch.length300;i++)
{
for(int j=0;j<Small table.length10;j++)
{
...
}
}
-- Above 2 FOR Cycle, and eventually cycle 3000 times;
-- However, for double-layer loops, it is generally recommended to put loops with small data in the outer layer and loops with large data in the memory. This will improve the efficiency.
-- The small table is on the left and the large table is on the right, so the small data is placed outside(Left)
1. The index is built on a frequently used field (left outer join course2 c on t.cid=c.cid in this question, the t.cid field is frequently used, so the field is cited) [generally, for the left outer connection, the left table is cited; for the right outer connection, the right table is cited]
-- to teacher Tabular cid Field reference alter table teacher2 add index index_teacher2_cid(cid) ; Using join buffer:-- extra An option in to: Mysql The engine uses connection cache. Because the statements written by itself are poor, mysql Through the service layer SQL The optimizer optimizes for us.

2. Because where c.cname='java ';, index the CNAME of the course table:
-- to course Tabular cname Caucasian citation alter table course2 add index index_course2_cname(cname);
3. Three table optimization case
a. Small table drives large table
b. The index is based on frequently queried fields
Table creation and composite index:
create table test03( a1 int(4) not null, a2 int(4) not null, a3 int(4) not null, a4 int(4) not null ); alter table test03 add index idx_a1_a2_a3_4(a1,a2,a3,a4) ;-- Composite index
Execution plan analysis:
1. Recommended writing method: composite indexes are matched in order
-- It is recommended because of the order in which the index is used( where The following order) is consistent with the order of the composite index -- All composite indexes are used, ken_len=16 explain select a1,a2,a3,a4 from test03 where a1=1 and a2=2 and a3=3 and a4 =4 ;

2. Flashback, but there is no cross column. It is possible that the optimizer will help optimize. Depending on the situation:
-- Although the writing order and index order are inconsistent, but sql Before the actual implementation SQL The optimizer's adjustment results are the same as the previous one SQL Is consistent. -- All composite indexes are used, ken_len=16 explain select a1,a2,a3,a4 from test03 where a4=1 and a3=2 and a2=3 and a1 =4 ;

3. Indexes are used across columns, resulting in index invalidation
-- Yes a1 a2 Two indexes. These two fields do not need to be queried back to the table using index ; -- and a4 Because of cross column use, the index is invalid and needs to be queried back to the table using where; -- The above can be passed key_len Verify explain select a1,a2,a3,a4 from test03 where a1=1 and a2=2 and a4=4 order by a3;
The splicing order of where and order by is a1, a2 and a3, which is consistent with the order of the composite index (a1, a2, a3 and A4). There is no using filesort, and no additional query is required for sorting.

4. Using indexes across columns results in Using filesort
-- When SQL There it is using filesort(Sorting within the file, "one more additional search/Sort) -- Do not use across columns( where and order by Put it together a1,a3,Do not use across columns),It's over here a2,yes a3 Sorting requires additional queries explain select a1,a2,a3,a4 from test03 where a1=1 and a4=4 order by a3;

How to understand where and order by? Don't use them across columns

For example, using filesort does not appear:
explain select a1,a2,a3,a4 from test03 where a1=1 and a4=4 order by a2 , a3;
Summary:
a. If (a,b,c,d) the composite index and the order of use are all consistent (and not used across columns), then all composite indexes are used.
If parts are consistent (and not used across columns), partial indexes are used. select a, c where a = and b= and d=
b. where and order by are spelled together. Do not use them across columns