Case classification
Case has two formats: 1. Simple Case function and 2.Case search function.
Simple Case function:
CASE sex WHEN '1' THEN 'male' WHEN '2' THEN 'female' ELSE 'Other' END
Case search function
CASE WHEN sex = '1' THEN 'male' WHEN sex = '2' THEN 'female' ELSE 'Other' END
The same function can be achieved in two ways. Simple Case functions are relatively concise, but there are some functional limitations compared with Case search functions, such as writing judgments. Another problem to note is that the Case function only returns the first qualified value, and the rest of the Case section will be automatically ignored.
For example, in the following paragraph of SQL, you will never get the result of "Category 2".
CASE
WHEN col_1 IN ( 'a', 'b') THEN 'first kind'
WHEN col_1 IN ('a') THEN 'Second category'
ELSE'Other' ENDClassic chestnut
The table structure and data are as follows:
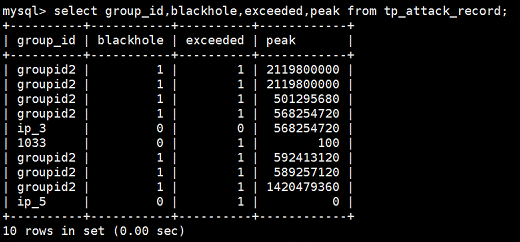
Grouping statistics according to group_id: number, maximum peak, number of black holes, number of hyperfields
strSQL := "select count(group_id),max(peak),"
strSQL += "ifnull(sum(case when blackhole=1 then 1 else 0 end),0) blackhole,"
strSQL += "ifnull(sum(case when exceeded=1 then 1 else 0 end),0) exceeded "
strSQL += "from tp_attack_record where "
for _,groupid := range req.GroupId {
strSQL +=fmt.Sprintf("group_id='%s' or ",groupid)
}
strSQL = strSQL[:len(strSQL)-3]
strSQL += "group by group_id"The statistical results are as follows:
AttackStatistics resp: {"status":
{"retcode":0,"code":"ok","msg":"success"},"data":
[{"groupid":"1033","attackTimes":1,"attackPeak":100,"blackHoleTimes":0,"overPeakTimes":1},
{"groupid":"groupid2","attackTimes":7,"attackPeak":2119800000,"blackHoleTimes":7,"overPeakTimes":7},
{"groupid":"ip_3","attackTimes":1,"attackPeak":568254720,"blackHoleTimes":0,"overPeakTimes":0},
{"groupid":"ip_5","attackTimes":1,"attackPeak":0,"blackHoleTimes":0,"overPeakTimes":1}]}Group statistics by group_id: number of peak intervals
strSQL := "select "
strSQL += "ifnull(sum(case when peak<? then 1 else 0 end),0) peak10,"
strSQL += "ifnull(sum(case when peak>=? and peak<? then 1 else 0 end),0) peak50,"
strSQL += "ifnull(sum(case when peak>=? and peak<? then 1 else 0 end),0) peak100,"
strSQL += "ifnull(sum(case when peak>=? and peak<? then 1 else 0 end),0) peak150,"
strSQL += "ifnull(sum(case when peak>=? and peak<? then 1 else 0 end),0) peak200,"
strSQL += "ifnull(sum(case when peak>=? and peak<? then 1 else 0 end),0) peak300 "
strSQL += "from tp_attack_record where "
for _,groupid := range req.GroupId {
strSQL +=fmt.Sprintf("group_id='%s' or ",groupid)
}
strSQL = strSQL[:len(strSQL)-3]
strSQL += "group by group_id"The statistical results are as follows:
AttackStatistics resp: {"status":
{"retcode":0,"code":"ok","msg":"success"},"data":
[{"groupid":"1033","less_10":1,"in_10_50":0,"in_50_100":0,"in_100_150":0,"in_150_200":0,"in_250_300":0},
{"groupid":"groupid2","less_10":7,"in_10_50":0,"in_50_100":0,"in_100_150":0,"in_150_200":0,"in_250_300":0},
{"groupid":"ip_3","less_10":1,"in_10_50":0,"in_50_100":0,"in_100_150":0,"in_150_200":0,"in_250_300":0},
{"groupid":"ip_5","less_10":1,"in_10_50":0,"in_50_100":0,"in_100_150":0,"in_150_200":0,"in_250_300":0}]}Known data are grouped and analyzed in another way
There are the following data: (To see more clearly, I did not use the country code, but used the country name as Primary Key directly)

According to the country's population data, the population of Asia and North America is counted. The following results should be obtained:
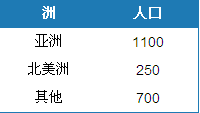
What would you do to solve this problem? Generating a View with Continental Code is a solution, but it's difficult to dynamically change the way statistics are done.
If you use the Case function, the SQL code is as follows:
SELECT SUM(population), CASE country WHEN'China' THEN 'Asia' WHEN 'India'THEN 'Asia' WHEN 'Japan' THEN 'Asia' WHEN 'U.S.A' THEN 'North America' WHEN 'Canada' THEN 'North America' WHEN 'Mexico' THEN 'North America' ELSE 'Other' END FROM Table_A GROUP BY CASE country WHEN 'China' THEN 'Asia' WHEN 'India' THEN 'Asia' WHEN 'Japan' THEN 'Asia' WHEN 'U.S.A' THEN 'North America' WHEN 'Canada' THEN'North America' WHEN 'Mexico' THEN'North America' ELSE 'Other' END;
Similarly, we can use this method to judge wage levels and count the number of people in each level. The SQL code is as follows:
SELECT CASE WHEN salary <= 500THEN '1' WHEN salary > 500 AND salary <=600 THEN'2' WHEN salary > 600 AND salary <=800 THEN'3' WHEN salary > 800 AND salary <=1000 THEN '4' ELSE NULL END salary_class, -- Alias name COUNT(*) FROM Table_A GROUP BY CASE WHEN salary <= 500 THEN '1' WHEN salary > 500 AND salary <=600 THEN'2' WHEN salary > 600 AND salary <=800 THEN'3' WHEN salary > 800 AND salary <=1000 THEN '4' ELSE NULL END;
Grouping different conditions with an SQL statement
The following data are available
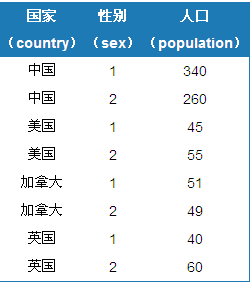
Grouped by country and gender, the results are as follows
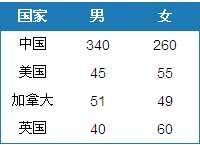
In general, UNION can also be used to query with a single statement. But that adds to the consumption (two Select parts), and the SQL statements are longer.
The following is a Case function to complete this function of SQL:
SELECT country, SUM( CASE WHEN sex ='1' THEN population ELSE 0 END), --Male population SUM( CASE WHEN sex ='2' THEN population ELSE 0 END) --Female population FROM Table_A GROUPBYcountry;
In this way, we use Select to complete the output form of two-dimensional tables, fully demonstrating the power of Case function.
Use Case Function in Check
The use of Case functions in Check is a very good solution in many cases. There may be many people who don't use Check at all, so I suggest you try using Check in SQL after looking at the following examples.
Let's take an example.
Company A, the company has a rule that female employees must be paid more than 1000 yuan. If expressed in terms of Check and Case, as follows
CONSTRAINT check_salary CHECK ( CASE WHEN sex = '2' THEN CASE WHEN salary > 1000 THEN 1 ELSE 0 END ELSE 1 END = 1 )
If Check is used only:
CONSTRAINT check_salary CHECK ( sex = '2' AND salary > 1000 )
The qualifications of the female staff were met, and the male staff could not input them.
Selective UPDATE Based on Conditions
For example, there are the following update conditions
- For staff with salaries above 5000, the salary will be reduced by 10%.
- Employees whose wages range from 2000 to 4600 are paid 15% more.
It's easy to consider choosing to execute two UPDATE statements, as follows
- condition 1
UPDATE Personnel SET salary = salary *0.9 WHERE salary >=5000;
- condition 2
UPDATE Personnel SET salary = salary *1.15 WHERE salary >= 2000AND salary< 4600;
But things aren't as simple as you think. Suppose there's a person who pays 5,000 yuan. First of all, according to condition 1, wages are reduced by 10% to 4500. Next, when running the second SQL, because this person's salary is 4500 in the range of 2000 to 4600, it needs to be increased by 15%. Finally, this person's salary is 5175, which not only did not decrease, but increased. If the opposite is done, the wage of 4600 people will be reduced instead. No matter how absurd the rule is.
If we want an SQL statement to implement this function, we need to use the Case function. The code is as follows:
UPDATE Personnel
SET salary =
CASE
WHEN salary >=5000 THEN salary *0.9
WHEN salary >= 2000 AND salary <4600 THEN salary *1.15
ELSE salary END; One thing to note here is that the ELS Esalary in the last line is necessary. Without this line, the wages of those who do not meet these two conditions will be written as NUll, which is a big deal. The default value of the Else part in the Case function is NULL, which is something to be noted.
This method can also be used in many places, such as changing the primary key.
Generally speaking, to exchange Primary key,a and b of two data, we need to go through three processes: temporary storage, copy and read back the data. If we use the Case function, everything will be much simpler.
| p_key | col_1 | col_2 |
| a | 1 | Zhang San |
| b | 2 | Li Si |
| c | 3 | Wang Wu |
Assuming the above data, the primary keys a and b need to be exchanged. If implemented with the Case function, the code is as follows:
UPDATESomeTable
SET p_key =
CASE
WHEN p_key = 'a' THEN 'b'
WHEN p_key = 'b' THEN 'a'
ELSE p_key END
WHERE p_key IN ('a', 'b');
Similarly, two Unique key s can be exchanged. It should be noted that if there is a need to exchange primary keys, the design of this table is mostly inadequate at the beginning. It is suggested that the design of the checklist is appropriate.
Check for consistency of data between two tables
Case function is different from DECODE function. In case function, you can use BETWEEN,LIKE,ISNULL,IN,EXISTS and so on. For example, with IN and EXISTS, sub-queries can be made to achieve more functions.
The following example illustrates that there are two tables, tbl_A and tbl_B, with keyCol columns in both tables. Now we compare the two tables. If the data of the keyCol column in tbl_A can be found in the data of the keyCol column in tbl_B, the result'Matched'will be returned, and if not, the result'Unmatched'.
To achieve this function, you can use the following two statements:
When using IN
SELECT keyCol, CASE WHEN keyCol IN ( SELECT keyCol FROM tbl_B ) THEN 'Matched' ELSE 'Unmatched' END Label FROM tbl_A;
When using EXISTS
SELECT keyCol, CASE WHEN EXISTS ( SELECT * FROM tbl_B WHERE tbl_A.keyCol = tbl_B.keyCol) THEN'Matched' ELSE 'Unmatched' END Label FROM tbl_A;
The results using IN and EXISTS are the same. NOT IN and NOT EXISTS can also be used, but NULL should be noted at this time.
Use summation function in Case function
Suppose you have the following table
| Student number (std_id) | Course ID(class_id) | Class_name | Major in flag (main_class_flg) |
| 100 | 1 | Economics | Y |
| 100 | 2 | history | N |
| 200 | 2 | history | N |
| 200 | 3 | archaeology | Y |
| 200 | 4 | Computer | N |
| 300 | 4 | Computer | N |
| 400 | 5 | Chemistry | N |
| 500 | 6 | Mathematics | N |
Some students choose to take several courses at the same time (100,200). Others choose only one course (300,400,500). Students who take many courses should choose one course as their major and write Y in flag. Students who choose only one course, major in flag as N (in fact, if you write in Y, there will be no trouble below, for example, please include more).
Now we need to query the table according to the following two conditions:
-
The person who takes only one course returns the ID of that course.
-
Those who take more than one course return the ID of the selected main course.
The simple idea is to execute two different SQL statements for queries.
Conditions 1: Students who choose only one course
SELECT std_id, MAX(class_id) AS main_class FROM Studentclass GROUP BY std_id HAVING COUNT(*) =1;
Implementation Result 1
STD_ID MAIN_class 300 4 400 5 500 6
Conditions 2: Students who choose multiple courses
SELECT std_id, class_id AS main_class FROM Studentclass WHERE main_class_flg = 'Y' ;
Implementation Result 2
STD_ID MAIN_class 100 1 200 3
If we use the Case function, we can solve the problem with only one SQL statement, as follows:
SELECT std_id, CASE WHEN COUNT(*) = 1 --The situation of students who choose only one course THEN MAX(class_id) ELSE MAX(CASE WHEN main_class_flg = 'Y' THEN class_id ELSE NULL END ) END ASmain_class FROM Studentclass GROUP BY std_id;
Operation result
STD_ID MAIN_class 100 1 200 3 300 4 400 5 500 6
By nesting the case function in the case function and using the case function in the aggregate function, we can easily solve this problem. Using the Case function gives us more freedom.
Finally, let's remind novices who use Case functions not to make mistakes.
CASE col_1 WHEN 1 THEN 'Right' WHEN NULL THEN'Wrong' END
In this statement, When Null always returns unknown, so there will never be Wrong. Because the actual meaning of this sentence is
WHEN col_1 =NULL, this is an incorrect use, at this time we should choose to use WHEN col_1 IS NULL.
Summary
There are two main benefits of combining select with case:
- Flexible organizational format for displaying query results
- It effectively avoids multiple visits to the same table or several tables.
Here is a simple example to illustrate.
For example, the table students (id, name, birthday, sex, grade) requires that the number of boys and girls be counted according to each grade. The header of the statistical results is grade, number of boys and number of girls. If you don't need to select case when, in order to show the number of men and women side by side, it is very troublesome to count them. First, the grade information is determined, then the number of boys and girls is selected according to the grade, and it is easy to make mistakes.
Use select case when to write as follows:
SELECT grade, COUNT(CASE WHEN sex = 1 THEN 1 ELSE NULL END)Number of boys, COUNT(CASE WHEN sex = 2 THEN 1 ELSE NULL END)Female student number FROM students GROUP BY grade;
End