Recently, a project is being perfected. Because the display interface uses django, but wants to decouple. The backstage and display interface do not directly use django's ORM, so we use SQL Alemchy to do the database interface of back-end data collection. But the performance of SQL Alemchy is not good. Today, we want to test the bottleneck of its performance. Here is the following. Cheng Jilu:
Query testing
The test code is as follows:
def pymsql_select():
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', db='test')
cursor = conn.cursor()
for i in range(1, 10000):
sql = "select count(*) from informations_alarm;"
cursor.execute(sql)
print(cursor.fetchone())
def alchemy_select():
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/test", max_overflow=5)
# Create mysql operation object
Session = sessionmaker(bind=engine)
session = Session()
for i in range(1, 10000):
count = session.query(Alarm).count()
print(count)
def alchemy_select_withsql():
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/test", max_overflow=5)
# Create mysql operation object
Session = sessionmaker(bind=engine)
session = Session()
for i in range(1, 10000):
count = session.execute("select count(*) from informations_alarm")
print(count.first())
if __name__ == '__main__':
pymsql_select()
alchemy_select()
alchemy_select_withsql()Firstly, the pymysql, pymsql_select function, is tested directly. The results are as follows: 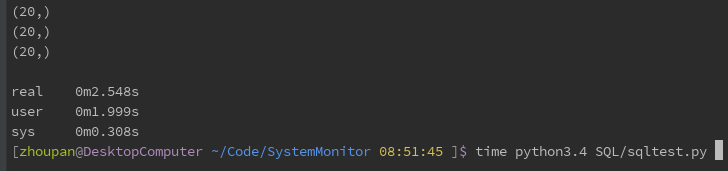
Then the test uses the ORM of SQLAlchemy to test, which is the function alchemy_select. The results are as follows:
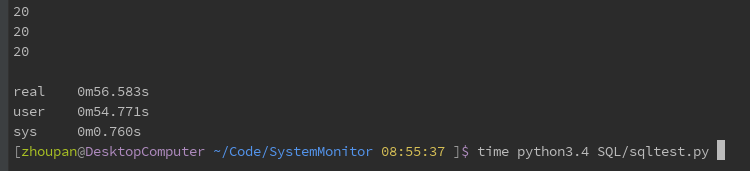
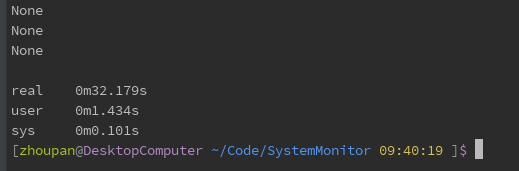
Finally, the function alchemy_select_withsql is used to execute the SQL statement directly by using SQLAlchemy. The results are as follows:
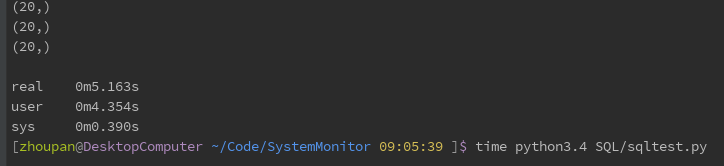
The following test database is written:
def pymsql_select():
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', db='test')
cursor = conn.cursor()
for i in range(1, 400):
sql = "INSERT INTO informations_alarm(receive_id,client_id,cpu,svmem,swap,diskio,diskusage,snetio,level,message) VALUES (1,1,1,1,1,1,1,1,1,\'1\');"
cursor.execute(sql)
conn.commit()
print(cursor)
def alchemy_select():
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/test", max_overflow=5)
# Create mysql operation object
Session = sessionmaker(bind=engine)
session = Session()
for i in range(1, 400):
alarm = Alarm(receive_id=1, client_id=1, cpu=1, svmem=1,
swap=1,
diskio=1, diskusage=1, snetio=1,
level=1, message=1)
session.add(alarm)
result = session.commit()
print(result)
def alchemy_select_withsql():
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/test", max_overflow=5)
# Create mysql operation object
Session = sessionmaker(bind=engine)
session = Session()
for i in range(1, 400):
count = session.execute("INSERT INTO informations_alarm(receive_id,client_id,cpu,svmem,swap,diskio,diskusage,snetio,level,message) VALUES (1,1,1,1,1,1,1,1,1,\'1\');")
print(session.commit())
if __name__ == '__main__':
pymsql_select()
#alchemy_select()
#alchemy_select_withsql()Because 10,000 pieces of data were too much and time-consuming, 400 pieces of data were inserted into the test.
Firstly, the pymysql, pymsql_select function, is tested directly. The results are as follows:
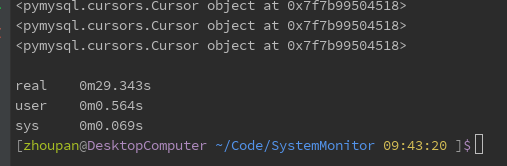
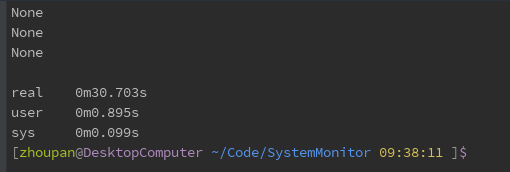
Then the test uses the ORM of SQLAlchemy to test, which is the function alchemy_select. The results are as follows:
Finally, the function alchemy_select_withsql is used to execute the SQL statement directly by using SQLAlchemy. The results are as follows:
Overall, using pymysql directly is preferable, but pymysql is often not used in this way, but every time we create a new connection and execute the release, while SQL Alemchy uses the connection pool mechanism, guaranteeing only one operation entry at a time. Here is to test the general use of pymysql:
def pymsql_select():
for i in range(1, 400):
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', db='test')
cursor = conn.cursor()
sql = "INSERT INTO informations_alarm(receive_id,client_id,cpu,svmem,swap,diskio,diskusage,snetio,level,message) VALUES (1,1,1,1,1,1,1,1,1,\'1\');"
cursor.execute(sql)
conn.commit()
conn.close()
print(cursor)The results are as follows: 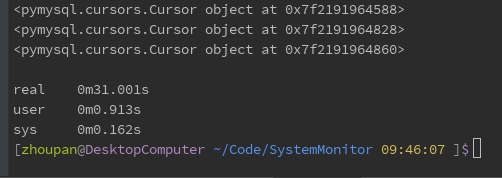
The query code is as follows:
def pymsql_select():
for i in range(1, 10000):
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', db='test')
cursor = conn.cursor()
sql = "select count(*) from informations_alarm;"
cursor.execute(sql)
print(cursor.fetchone())
conn.close()The results are as follows: 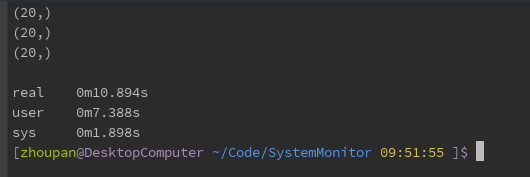
Thus, we have basically concluded that:
In terms of single thread, the ORM of SQL Alemchy is still inferior to pymysql, but without ORM to execute SQL directly, because SQL Alemchy uses connection pool technology to avoid the time-consuming of opening and closing connections many times, so it is obviously superior to pymysql in both writing and reading, so you want to use SQL Alemchy, and if you want efficiency, you should use SQL Alemchy directly. Execute SQL.
The bottleneck of SQL Alemchy lies in the ORM section. It transforms the corresponding objects into SQL statements through the object mechanism. Because python is famous for its inefficiency, a lot of time is spent on transformation, which leads to inefficiency.