springboot Integrates Quatz to Realize Distributed Timing Task Cluster
Reference 1:https://blog.csdn.net/fyfguuug/article/details/79358159
Reference 2:https://blog.csdn.net/qq_41866572/article/details/80061853
Reference 3:https://blog.csdn.net/wanghaoalain/article/details/79288387
Thank the author!
What is quartz?
If you only use timing tasks, you can use spring's schedule to achieve, convenient, less code. Easy to achieve, but think about a problem.
When a project is deployed in a distributed way, every jar package contains a timing task, and all servers run at the same time. A timing task is executed many times, which causes many problems.
The simplest way to solve the problem is to change the project, leaving only one project with a fixed task, and nothing else. However, there will be a single point of failure. It is not the best way to solve the problem.
The best way is to use quartz to schedule scheduled tasks.
The advantages of quartz are:
1. We can schedule multiple scheduled tasks.
2. It can decouple the code and configure it by configuration file.
3. Powerful, complex time task scheduling can be set through cron expression.
Quatz Core Points:
1.job: (the interface scheduled by tasks), we need to implement job, and inherit TimerTask rewrite run method, rewrite excute method in job, excute method is the execution location of task scheduling method.
2.JobDetail: Job instances must be implemented through JobDetail (based on builder mode)
3.trigger (including CronTrigger and simple Trigger): specify the frequency and time of task scheduling. When to Schedule Tasks (builder-based) Triggers
4. Schduler: A scheduler (based on factory mode) that schedules triggers with a job detail instance and a trigger instance.
How Clusters Work in Quartz
Each node in a Quartz cluster is a separate Quartz application, which manages other nodes. This means that you must start or stop each node separately. Unlike many application server clusters, independent Quartz nodes do not communicate with other nodes or management nodes. Quartz applications perceive another application through database tables. Without db, it would be imperceptible.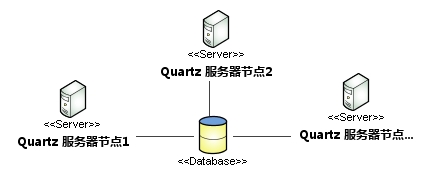
Realization
1. Import database tables
Because the Quartz cluster depends on the database, you must first create the table of the Quartz database. Quartz includes SQL scripts for all supported database platforms. This is my SQL table.
Note: The table names created are lowercase and capitalization is used in the code, so the database using liunx will not find the tables, modify the tables or change the database configuration as appropriate.
/* Navicat MySQL Data Transfer Source Server : 192.168.163.128_3306 Source Server Version : 50540 Source Host : 192.168.163.128:3306 Source Database : primer Target Server Type : MYSQL Target Server Version : 50540 File Encoding : 65001 Date: 2018-08-29 22:56:23 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for qrtz_blob_triggers -- ---------------------------- DROP TABLE IF EXISTS `qrtz_blob_triggers`; CREATE TABLE `qrtz_blob_triggers` ( `SCHED_NAME` varchar(120) NOT NULL, `TRIGGER_NAME` varchar(200) NOT NULL, `TRIGGER_GROUP` varchar(200) NOT NULL, `BLOB_DATA` blob, PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`), KEY `SCHED_NAME` (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`), CONSTRAINT `qrtz_blob_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `qrtz_triggers` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_calendars -- ---------------------------- DROP TABLE IF EXISTS `qrtz_calendars`; CREATE TABLE `qrtz_calendars` ( `SCHED_NAME` varchar(120) NOT NULL, `CALENDAR_NAME` varchar(200) NOT NULL, `CALENDAR` blob NOT NULL, PRIMARY KEY (`SCHED_NAME`,`CALENDAR_NAME`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_cron_triggers -- ---------------------------- DROP TABLE IF EXISTS `qrtz_cron_triggers`; CREATE TABLE `qrtz_cron_triggers` ( `SCHED_NAME` varchar(120) NOT NULL, `TRIGGER_NAME` varchar(200) NOT NULL, `TRIGGER_GROUP` varchar(200) NOT NULL, `CRON_EXPRESSION` varchar(120) NOT NULL, `TIME_ZONE_ID` varchar(80) DEFAULT NULL, PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`), CONSTRAINT `qrtz_cron_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `qrtz_triggers` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_fired_triggers -- ---------------------------- DROP TABLE IF EXISTS `qrtz_fired_triggers`; CREATE TABLE `qrtz_fired_triggers` ( `SCHED_NAME` varchar(120) NOT NULL, `ENTRY_ID` varchar(95) NOT NULL, `TRIGGER_NAME` varchar(200) NOT NULL, `TRIGGER_GROUP` varchar(200) NOT NULL, `INSTANCE_NAME` varchar(200) NOT NULL, `FIRED_TIME` bigint(13) NOT NULL, `SCHED_TIME` bigint(13) NOT NULL, `PRIORITY` int(11) NOT NULL, `STATE` varchar(16) NOT NULL, `JOB_NAME` varchar(200) DEFAULT NULL, `JOB_GROUP` varchar(200) DEFAULT NULL, `IS_NONCONCURRENT` varchar(1) DEFAULT NULL, `REQUESTS_RECOVERY` varchar(1) DEFAULT NULL, PRIMARY KEY (`SCHED_NAME`,`ENTRY_ID`), KEY `IDX_QRTZ_FT_TRIG_INST_NAME` (`SCHED_NAME`,`INSTANCE_NAME`), KEY `IDX_QRTZ_FT_INST_JOB_REQ_RCVRY` (`SCHED_NAME`,`INSTANCE_NAME`,`REQUESTS_RECOVERY`), KEY `IDX_QRTZ_FT_J_G` (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`), KEY `IDX_QRTZ_FT_JG` (`SCHED_NAME`,`JOB_GROUP`), KEY `IDX_QRTZ_FT_T_G` (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`), KEY `IDX_QRTZ_FT_TG` (`SCHED_NAME`,`TRIGGER_GROUP`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_job_details -- ---------------------------- DROP TABLE IF EXISTS `qrtz_job_details`; CREATE TABLE `qrtz_job_details` ( `SCHED_NAME` varchar(120) NOT NULL, `JOB_NAME` varchar(200) NOT NULL, `JOB_GROUP` varchar(200) NOT NULL, `DESCRIPTION` varchar(250) DEFAULT NULL, `JOB_CLASS_NAME` varchar(250) NOT NULL, `IS_DURABLE` varchar(1) NOT NULL, `IS_NONCONCURRENT` varchar(1) NOT NULL, `IS_UPDATE_DATA` varchar(1) NOT NULL, `REQUESTS_RECOVERY` varchar(1) NOT NULL, `JOB_DATA` blob, PRIMARY KEY (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`), KEY `IDX_QRTZ_J_REQ_RECOVERY` (`SCHED_NAME`,`REQUESTS_RECOVERY`), KEY `IDX_QRTZ_J_GRP` (`SCHED_NAME`,`JOB_GROUP`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_locks -- ---------------------------- DROP TABLE IF EXISTS `qrtz_locks`; CREATE TABLE `qrtz_locks` ( `SCHED_NAME` varchar(120) NOT NULL, `LOCK_NAME` varchar(40) NOT NULL, PRIMARY KEY (`SCHED_NAME`,`LOCK_NAME`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_paused_trigger_grps -- ---------------------------- DROP TABLE IF EXISTS `qrtz_paused_trigger_grps`; CREATE TABLE `qrtz_paused_trigger_grps` ( `SCHED_NAME` varchar(120) NOT NULL, `TRIGGER_GROUP` varchar(200) NOT NULL, PRIMARY KEY (`SCHED_NAME`,`TRIGGER_GROUP`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_scheduler_state -- ---------------------------- DROP TABLE IF EXISTS `qrtz_scheduler_state`; CREATE TABLE `qrtz_scheduler_state` ( `SCHED_NAME` varchar(120) NOT NULL, `INSTANCE_NAME` varchar(200) NOT NULL, `LAST_CHECKIN_TIME` bigint(13) NOT NULL, `CHECKIN_INTERVAL` bigint(13) NOT NULL, PRIMARY KEY (`SCHED_NAME`,`INSTANCE_NAME`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_simple_triggers -- ---------------------------- DROP TABLE IF EXISTS `qrtz_simple_triggers`; CREATE TABLE `qrtz_simple_triggers` ( `SCHED_NAME` varchar(120) NOT NULL, `TRIGGER_NAME` varchar(200) NOT NULL, `TRIGGER_GROUP` varchar(200) NOT NULL, `REPEAT_COUNT` bigint(7) NOT NULL, `REPEAT_INTERVAL` bigint(12) NOT NULL, `TIMES_TRIGGERED` bigint(10) NOT NULL, PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`), CONSTRAINT `qrtz_simple_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `qrtz_triggers` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_simprop_triggers -- ---------------------------- DROP TABLE IF EXISTS `qrtz_simprop_triggers`; CREATE TABLE `qrtz_simprop_triggers` ( `SCHED_NAME` varchar(120) NOT NULL, `TRIGGER_NAME` varchar(200) NOT NULL, `TRIGGER_GROUP` varchar(200) NOT NULL, `STR_PROP_1` varchar(512) DEFAULT NULL, `STR_PROP_2` varchar(512) DEFAULT NULL, `STR_PROP_3` varchar(512) DEFAULT NULL, `INT_PROP_1` int(11) DEFAULT NULL, `INT_PROP_2` int(11) DEFAULT NULL, `LONG_PROP_1` bigint(20) DEFAULT NULL, `LONG_PROP_2` bigint(20) DEFAULT NULL, `DEC_PROP_1` decimal(13,4) DEFAULT NULL, `DEC_PROP_2` decimal(13,4) DEFAULT NULL, `BOOL_PROP_1` varchar(1) DEFAULT NULL, `BOOL_PROP_2` varchar(1) DEFAULT NULL, PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`), CONSTRAINT `qrtz_simprop_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `qrtz_triggers` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for qrtz_triggers -- ---------------------------- DROP TABLE IF EXISTS `qrtz_triggers`; CREATE TABLE `qrtz_triggers` ( `SCHED_NAME` varchar(120) NOT NULL, `TRIGGER_NAME` varchar(200) NOT NULL, `TRIGGER_GROUP` varchar(200) NOT NULL, `JOB_NAME` varchar(200) NOT NULL, `JOB_GROUP` varchar(200) NOT NULL, `DESCRIPTION` varchar(250) DEFAULT NULL, `NEXT_FIRE_TIME` bigint(13) DEFAULT NULL, `PREV_FIRE_TIME` bigint(13) DEFAULT NULL, `PRIORITY` int(11) DEFAULT NULL, `TRIGGER_STATE` varchar(16) NOT NULL, `TRIGGER_TYPE` varchar(8) NOT NULL, `START_TIME` bigint(13) NOT NULL, `END_TIME` bigint(13) DEFAULT NULL, `CALENDAR_NAME` varchar(200) DEFAULT NULL, `MISFIRE_INSTR` smallint(2) DEFAULT NULL, `JOB_DATA` blob, PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`), KEY `IDX_QRTZ_T_J` (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`), KEY `IDX_QRTZ_T_JG` (`SCHED_NAME`,`JOB_GROUP`), KEY `IDX_QRTZ_T_C` (`SCHED_NAME`,`CALENDAR_NAME`), KEY `IDX_QRTZ_T_G` (`SCHED_NAME`,`TRIGGER_GROUP`), KEY `IDX_QRTZ_T_STATE` (`SCHED_NAME`,`TRIGGER_STATE`), KEY `IDX_QRTZ_T_N_STATE` (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`,`TRIGGER_STATE`), KEY `IDX_QRTZ_T_N_G_STATE` (`SCHED_NAME`,`TRIGGER_GROUP`,`TRIGGER_STATE`), KEY `IDX_QRTZ_T_NEXT_FIRE_TIME` (`SCHED_NAME`,`NEXT_FIRE_TIME`), KEY `IDX_QRTZ_T_NFT_ST` (`SCHED_NAME`,`TRIGGER_STATE`,`NEXT_FIRE_TIME`), KEY `IDX_QRTZ_T_NFT_MISFIRE` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`), KEY `IDX_QRTZ_T_NFT_ST_MISFIRE` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`,`TRIGGER_STATE`), KEY `IDX_QRTZ_T_NFT_ST_MISFIRE_GRP` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`,`TRIGGER_GROUP`,`TRIGGER_STATE`), CONSTRAINT `qrtz_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `JOB_NAME`, `JOB_GROUP`) REFERENCES `qrtz_job_details` (`SCHED_NAME`, `JOB_NAME`, `JOB_GROUP`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Introducing pom dependencies
<!-- quartz timer -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.0</version>
</dependency>
<!--druid Connection pool-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.12</version>
</dependency>
Introducing quartz.properties configuration
Note here that db persistence is required for distributed cluster runtime, so all nodes need to share a data source.
Key configurations are annotated.
#============================================================================ # Configure JobStore # Using Spring datasource in SchedulerConfig.java # Spring uses LocalDataSourceJobStore extension of JobStoreCMT #============================================================================ org.quartz.jobStore.useProperties=false #Prefix of table name org.quartz.jobStore.tablePrefix = QRTZ_ #The isClustered attribute is true, and you tell the Scheduler instance to participate in a cluster org.quartz.jobStore.isClustered = true #The cluster CheckinInterval attribute defines how often Scheduler instances are checked into the database (in milliseconds), with a default value of 15,000. org.quartz.jobStore.clusterCheckinInterval = 3000 org.quartz.jobStore.misfireThreshold = 60000 org.quartz.jobStore.txIsolationLevelReadCommitted = true #The class attribute is JobStoreTX, which persists tasks to data. quartz relies on database query task status org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate #============================================================================ # Configure Main Scheduler Properties # Needed to manage cluster instances #============================================================================ #The instance Name attribute can be any value used in JDBC JobStore to uniquely identify instances, but it must be the same across all cluster nodes. org.quartz.scheduler.instanceName = ClusterQuartz #The instance Id attribute is AUTO, which generates the instance ID based on the host name and timestamp. org.quartz.scheduler.instanceId= AUTO org.quartz.scheduler.rmi.export = false org.quartz.scheduler.rmi.proxy = false org.quartz.scheduler.wrapJobExecutionInUserTransaction = false #============================================================================ # Configure ThreadPool # Can also be configured in spring configuration # The thread pool in java used here #============================================================================ #org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool #org.quartz.threadPool.threadCount = 5 #org.quartz.threadPool.threadPriority = 5 #org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
springboot configuration class
Almost every line of code has detailed comments. This is not detailed here. See the code.
package com.jd.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.jd.task.SimpleJob;
import com.jd.task.SimpleJobTwo;
import org.quartz.Scheduler;
import org.springframework.beans.factory.config.PropertiesFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.scheduling.quartz.CronTriggerFactoryBean;
import org.springframework.scheduling.quartz.JobDetailFactoryBean;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
import javax.sql.DataSource;
import java.io.IOException;
import java.util.Properties;
import java.util.concurrent.Executor;
@Configuration
public class TaskConfig {
//Configuring data sources
@Bean
public DataSource druidDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/schedule?serverTimezone=GMT%2B8");
dataSource.setUsername("root");
dataSource.setPassword("112233");
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
return dataSource;
}
//Configure quartz configuration file
@Bean
public Properties quartzProperties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));
// Properties in quartz.properties are read and injected before the object is initialized
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
}
//Configure Timing Task 1
@Bean
public JobDetailFactoryBean job1() {
JobDetailFactoryBean jobDetail = new JobDetailFactoryBean();
//Implementation of Configuration Task
jobDetail.setJobClass(SimpleJob.class);
//Persistence or not
jobDetail.setDurability(true);
//Are exceptions re-executed
jobDetail.setRequestsRecovery(true);
//Configure Timing Task Information
jobDetail.setName("job1111------");
jobDetail.setGroup("quartzTest--------");
jobDetail.setDescription("This is job1111");
return jobDetail;
}
//Configuring Timing Task 2
@Bean
public JobDetailFactoryBean job2() {
JobDetailFactoryBean jobDetail = new JobDetailFactoryBean();
jobDetail.setJobClass(SimpleJobTwo.class);
jobDetail.setDurability(true);
jobDetail.setRequestsRecovery(true);
jobDetail.setName("job22222------");
jobDetail.setGroup("quartzTest--------");
jobDetail.setDescription("This is job2222");
return jobDetail;
}
//Configuring Task Timing Rule 1
@Bean
public CronTriggerFactoryBean trigger1() {
CronTriggerFactoryBean cronTrigger = new CronTriggerFactoryBean();
//Grouping of Timing Rules
cronTrigger.setGroup("TriggerTest11111");
//Configure the task jobdetail to execute
cronTrigger.setJobDetail(job1().getObject());
//Configuration execution rules are executed every five seconds
cronTrigger.setCronExpression("0/5 * * * * ?");
return cronTrigger;
}
//Configuring Task Timing Rule 2
@Bean
public CronTriggerFactoryBean trigger2() {
CronTriggerFactoryBean cronTrigger = new CronTriggerFactoryBean();
cronTrigger.setGroup("TriggerTest2222");
cronTrigger.setJobDetail(job2().getObject());
cronTrigger.setCronExpression("0/8 * * * * ?");
return cronTrigger;
}
//Configuring a task scheduling factory to generate a task scheduler is the core of quartz
@Bean
public SchedulerFactoryBean schedulerFactoryBean() throws IOException {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
//Open Update job
factory.setOverwriteExistingJobs(true);
//If not configured, instance Name in quartz.properties will be used
//factory.setSchedulerName("Cluster_Scheduler");
//Configure the data source, which is the database location for the tables quartz uses
factory.setDataSource(druidDataSource());
//Set the key of the instance in the spring container
factory.setApplicationContextSchedulerContextKey("applicationContext");
//Configure thread pool
factory.setTaskExecutor(schedulerThreadPool());
//Configuration Profile
factory.setQuartzProperties(quartzProperties());
//Configure the task execution rules, and the parameters are a variable array
factory.setTriggers(trigger1().getObject(),trigger2().getObject());
return factory;
}
//Open the current task scheduler
@Bean
public Scheduler scheduler() throws Exception {
Scheduler scheduler = schedulerFactoryBean().getScheduler();
scheduler.start();
return scheduler;
}
//Thread pool configuration
@Bean
public Executor schedulerThreadPool() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(20);
executor.setQueueCapacity(50);
return executor;
}
}
Write timed tasks
Timing tasks need to implement job interface, but quartz has a simple abstract implementation, which simplifies the amount of code. It only needs direct inheritance.
Here, I post the source code. At first, I saw that the data had the job interface, and inherited the Quartz JobBean. I didn't understand it very well. Then I read the source code.
public abstract class QuartzJobBean implements Job
Write timed tasks:
First Timing Task
@Component
public class SimpleJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("=========SimpleJob Medium executeInternal Method executed===="+new Date());
}
}
Second Timing Task
@Component
public class SimpleJobTwo extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
System.out.println("-----------------SimpleJobTwo The task has been carried out.------"+new Date());
}
}
test
First test the timing task
Start the project:
Output: No problem with timing tasks
Retest multiple projects
Put the project into a jar package and run it.
Change the original project to port and run again.
When there is only one project, two will execute on the same project, as shown in the figure above.
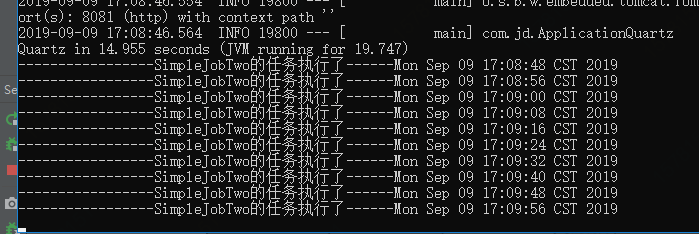
When two start-ups:
It will be carried out separately: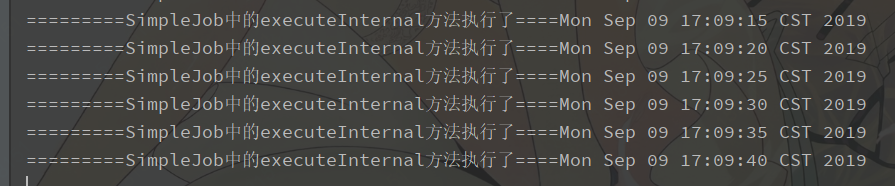
At the same time, there are two items of information in the database:
summary
Solve the single point of failure, can also execute timing.