Start with a case
pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.dongua</groupId>
<artifactId>es-springboot-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>es-springboot-demo</name>
<properties>
<java.version>11</java.version>
<elasticsearch.version>7.14.1</elasticsearch.version>
</properties>
<dependencies>
<!-- That's it -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
applicantion.yml
spring:
elasticsearch:
rest:
# uri of es
uris: http://localhost:9200
# Connection timeout
connection-timeout: 1
# Read timeout
read-timeout: 30
Of course, it can also be defined according to its own configuration class
@EqualsAndHashCode(callSuper = true)
@ConfigurationProperties(prefix = "elasticsearch")
@Data
@Configuration
public class RestHighClientConfig extends AbstractElasticsearchConfiguration {
private String host;
private int port;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
return new RestHighLevelClient
(RestClient.builder(new HttpHost(host, port, "http")));
}
// This will do
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
elasticsearch: host: 127.0.0.1 port: 9200
pojo
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
// Alias, if not set_ The value of class is its full path, such as com.xxx.pojo.Product
@TypeAlias("product")
// Name of index
@Document(indexName = "product")
// Set the number of slices to 3
@Setting(shards = 3)
public class Product {
// Unique identification, duplicate will be overwritten
@Id
private Long id;
// text type, which can be queried by word segmentation
@Field(type = FieldType.Text)
private String title;
// Keyword type, query according to the whole word
@Field(type = FieldType.Keyword)
private String category;,
// Double type
@Field(type = FieldType.Double)
private Double price;
// This field is not used as an index. It is an index by default. It is set to false here
@Field(type = FieldType.Keyword, index = false)
private String images;
}
Document annotation
Overview of mapping notes (from the official website)
In the mappingelastic searchconverter, use the mapping file of metadata driven objects. Metadata is taken from entity attributes that can be annotated.
The following notes are available:
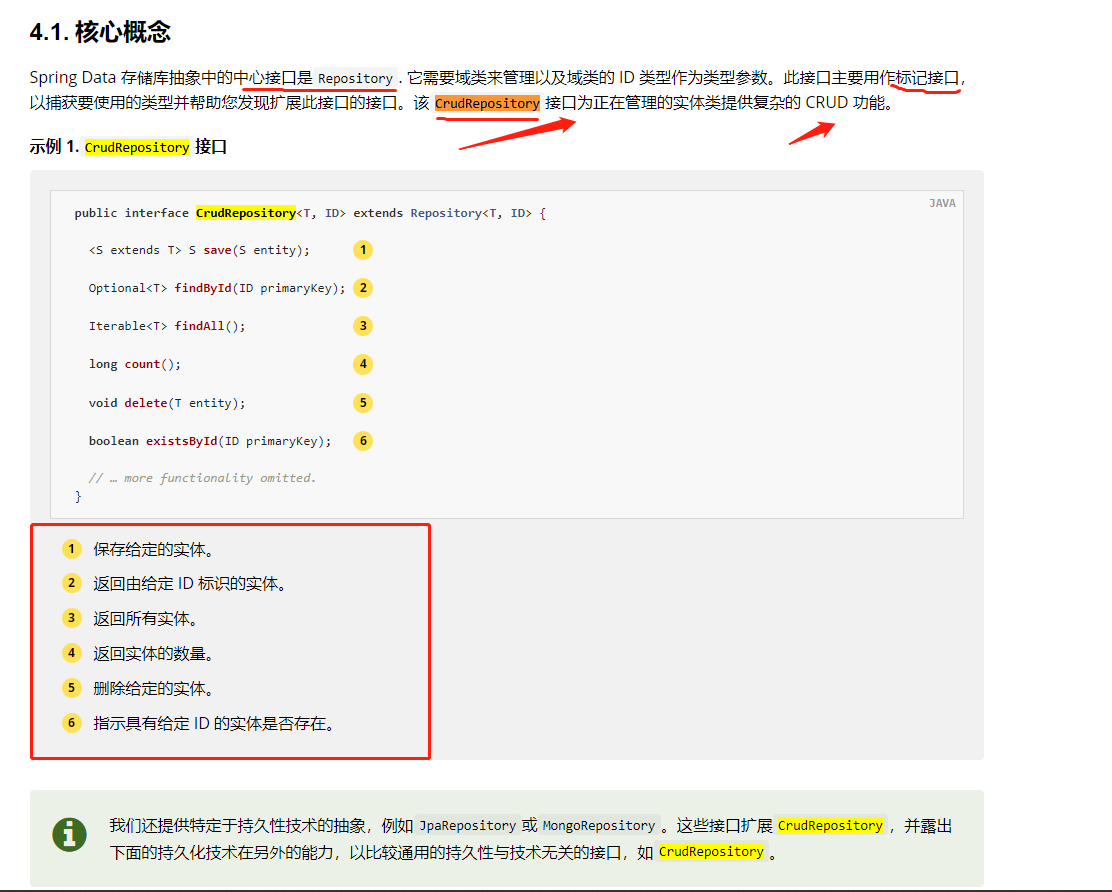
@Document: applied at the class level, indicating that the class is a candidate mapped to the database. The most important attributes are:
indexName: the index name that stores the entity. This can include a SpEL template expression, such as "log-#{T(java.time.LocalDate).now().toString()}"
Type: mapping type. If not set, the lowercase simple name of the class is used. (deprecated since version 4.0)
createIndex: marks whether an index is created when the repository boots. The default value is true. See automatically creating an index using the appropriate mapping
versionType: configuration of version management. The default value is EXTERNAL.
@Id: applied at the field level to mark the field for identification purposes.
@Transient: by default, all fields are mapped to the document when stored or retrieved. This comment does not include this field.
@PersistenceConstructor: marks that the given constructor - even a package protected constructor - is used when instantiating objects from the database. Constructor parameters map by name to key values in the retrieved document.
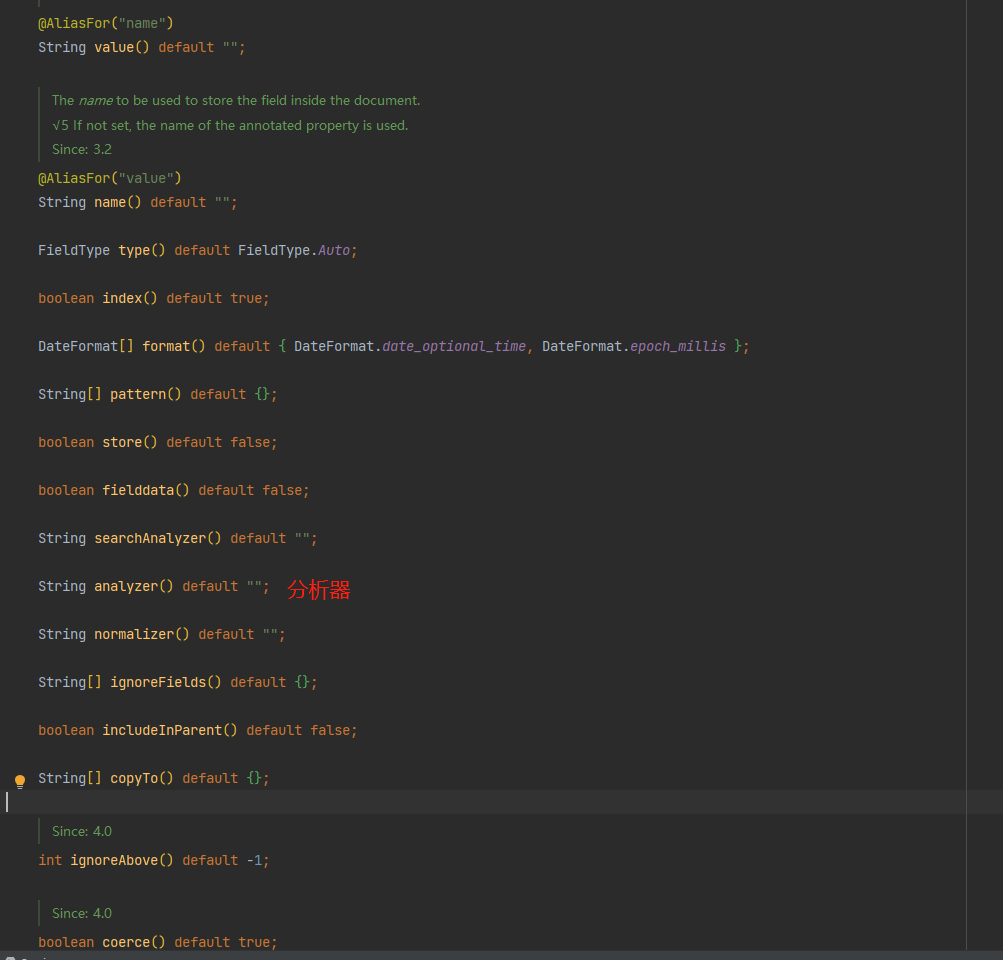
@Field: it is applied to the field level and defines the attributes of the field. Most attributes are mapped to their respective Elasticsearch Mapping definitions
Name: field name, because it will be represented in the Elasticsearch document. If it is not set, the Java field name will be used.
Type: field type, which can be Text, Keyword, long, integer, Short, Byte, double, float, Half_Float,Scaled_Float,Date,Date_Nanos,Boolean,Binary,Integer_Range,Float_Range,Long_Range,Double_Range,Date_Range,Ip_ One of range and Object, nested, Ip, TokenCount, Percolator, Flattened, Search_As_You_Type. View Elasticsearch mapping types
format: one or more built-in date formats
pattern: one or more custom date formats
store: Flag whether the original field value should be stored in Elasticsearch. The default value is false.
Index setting (excerpted from the official website)
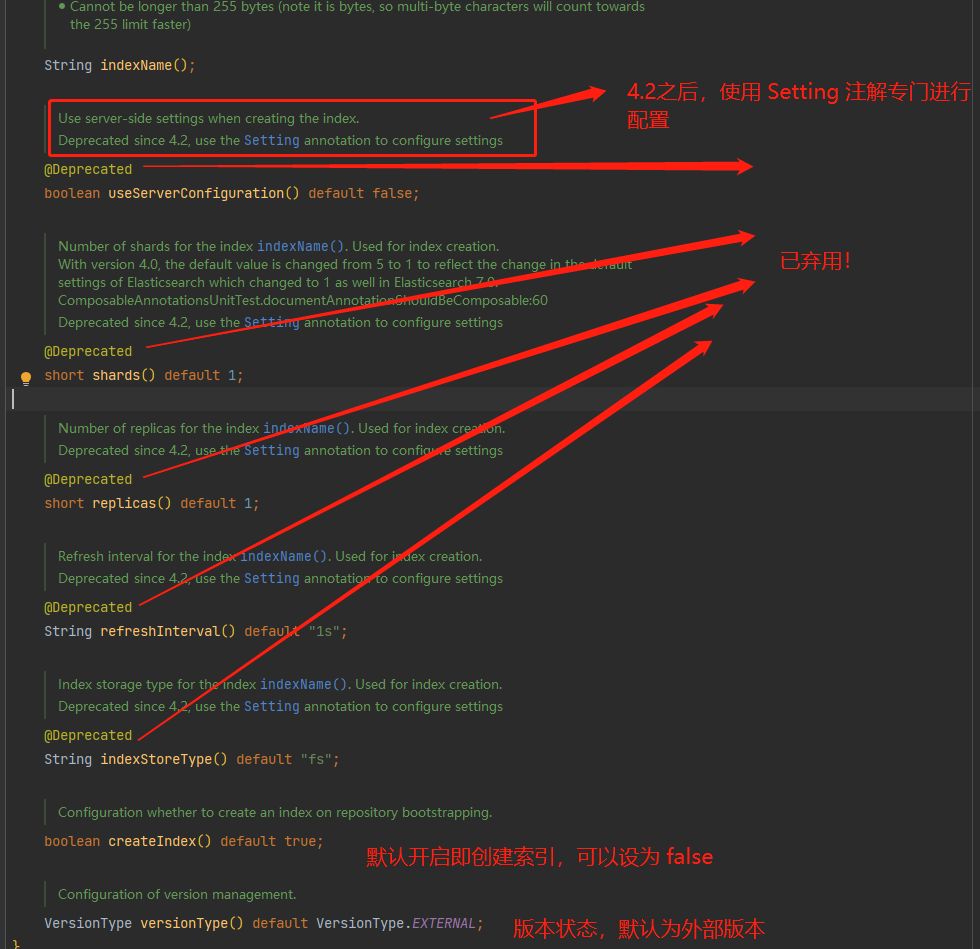
When using Spring Data Elasticsearch to create an Elasticsearch index, you can use the @ Setting annotation to define different index settings. The following parameters are available:
useServerConfiguration does not send any setting parameters, so Elasticsearch server configuration determines them.
settingPath is a JSON file that defines settings that must be resolved in the classpath
The number of shards to use. The default value is 1
Number of replicas. The default value is 1
Refreshinterval, the default is "1s"
indexStoreType, default to "fs"
You can also define index sorting
@Setting source code
@Persistent
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@Target({ ElementType.TYPE })
public @interface Setting {
/**
* Resource path for a settings configuration
* Set the configured resource path. It does not exist by default
*/
String settingPath() default "";
/**
* Use server-side settings when creating the index.
* Use server-side settings when creating indexes. Default false
*/
boolean useServerConfiguration() default false;
/**
* Number of shards for the index. Used for index creation. <br/>
* With version 4.0, the default value is changed from 5 to 1 to reflect the change in the default settings of
* Elasticsearch which changed to 1 as well in Elasticsearch 7.0.
*/
short shards() default 1;
/**
* Number of replicas for the index. Used for index creation.
*/
short replicas() default 1;
/**
* Refresh interval for the index. Used for index creation.
* Refresh interval for the index. Used to create an index. The so-called refreshing the index is to brush the index into the OS Cache once every 1 second by default
*/
String refreshInterval() default "1s";
/**
* Index storage type for the index. Used for index creation.
* The index storage type of the index. Used to create an index. The default is fs
*/
String indexStoreType() default "fs";
/**
* fields to define an index sorting
* Fields that define index sort
* @since 4.2
*/
String[] sortFields() default {};
/**
* defines the order for {@link #sortFields()}. If present, it must have the same number of elements
* Define the order of sortFields(). If it exists, it must have the same number of elements
* @since 4.2
*/
SortOrder[] sortOrders() default {};
/**
* defines the mode for {@link #sortFields()}. If present, it must have the same number of elements
* Defines the schema for sortFields(). If it exists, it must have the same number of elements
* @since 4.2
*/
SortMode[] sortModes() default {};
/**
* defines the missing value for {@link #sortFields()}. If present, it must have the same number of elements
* Defines the missing value for sortFields(). If it exists, it must have the same number of elements
* @since 4.2
*/
SortMissing[] sortMissingValues() default {};
// Provides an internal enumeration for use
enum SortOrder {
asc, desc
}
enum SortMode {
min, max
}
enum SortMissing {
_last, _first
}
}
Official case
@Document(indexName = "entities")
@Setting(
sortFields = { "secondField", "firstField" }, // 1 place
sortModes = { Setting.SortMode.max, Setting.SortMode.min }, // 2 places
sortOrders = { Setting.SortOrder.desc, Setting.SortOrder.asc },
sortMissingValues = { Setting.SortMissing._last, Setting.SortMissing._first })
class Entity {
@Nullable
@Id private String id;
@Nullable
@Field(name = "first_field", type = FieldType.Keyword)
private String firstField;
@Nullable @Field(name = "second_field", type = FieldType.Keyword)
private String secondField;
// getter and setter...
}
1. Place: when defining the sorting field, use the name of the Java attribute (firstField) instead of the name that may be defined for Elasticsearch (first_field)
2. sortModes,sortOrders and sortMissingValues at are optional, but if they are set, the number of entries must match the number of sortFields elements
It means naming, distinguishing between hump and underline. The attribute of java uses hump and the database uses underline
@Filed
Repository
import com.dongua.pojo.Product;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
// This is the core of some of our CRUD packages, which will be explored later
@Repository
public interface ProductDao extends ElasticsearchRepository<Product,Long> {
}
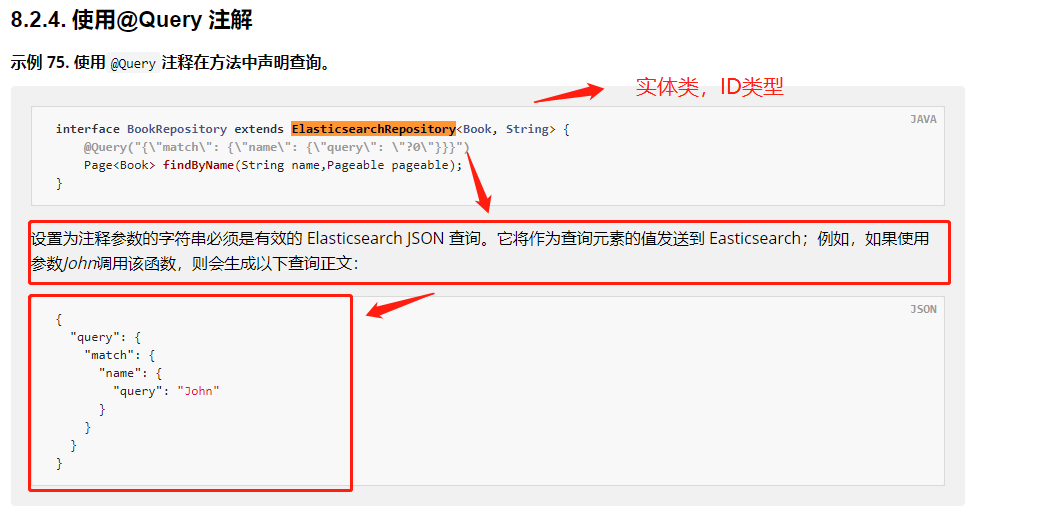
Query annotation (from the official website)
Inherit the method from ElasticsearchRepository
Test ElasticsearchRestTemplate
According to the tips on the official website and the code, test several APIs first
@SpringBootTest
public class SpringDataESProductDaoTest {
// ElasticsearchRestTemplate actually implements the ElasticsearchOperations interface
@Resource
ElasticsearchRestTemplate restTemplate;
@Resource
private ProductDao productDao;
/**
* Add a new document
*/
@Test
public void save() {
Product product = new Product();
// Globally unique, duplicate will overwrite
product.setId(1L);
product.setTitle("Huawei Mobile 4");
product.setCategory("mobile phone");
product.setPrice(2999.0);
product.setImages("http://www.xxx/hw.jpg");
product.setScore(1);
productDao.save(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/1
//Modify a document
@Test
public void update() {
Product product = new Product();
product.setId(1L);
product.setTitle("Xiaomi 2 mobile phone");
product.setCategory("mobile phone");
product.setPrice(9999.0);
product.setImages("http://www.xxx/xm.jpg");
product.setScore(8);
productDao.save(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/1
//Query document by id
@Test
public void findById() {
Product product = productDao.findById(2L).get();
System.out.println(product);
}
// Query all documents
@Test
public void findAll() {
Iterable<Product> products = productDao.findAll();
for (Product product : products) {
System.out.println(product);
}
}
// Delete index
@Test
public void deleteIndex() {
// The indexOps() index operation method of restTemplate is used here
// The method provided by dao does not support operation index
boolean delete = restTemplate.indexOps(Product.class).delete();
System.out.println("delete = " + delete);
}
//Delete a document
@Test
public void delete() {
Product product = new Product();
product.setId(2L);
productDao.delete(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/2
//Batch add documents
@Test
public void saveAll() {
List<Product> productList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Product product = new Product();
product.setId(Long.valueOf(i));
product.setTitle("[" + i + "]Mi phones");
product.setCategory("mobile phone");
product.setPrice(1999.0 + i);
product.setImages("http://www.xxx/xm.jpg");
productList.add(product);
}
productDao.saveAll(productList);
}
//Paging query
@Test
public void findByPageable() {
// Set sorting (sorting method, positive or reverse order, sorting id)
Sort sort = Sort.by(Sort.Direction.DESC, "id");
int currentPage = 0;//Current page, the first page starts from 0, and 1 represents the second page
int pageSize = 5;//How many are displayed per page
// Set query paging
// Even if the sort parameter is not provided, he will make some sort rule by himself
PageRequest pageRequest = PageRequest.of(currentPage, pageSize, sort);
//Paging query
Page<Product> productPage = productDao.findAll(pageRequest);
System.out.println("Total number of elements = " + productPage.getTotalElements());
for (Product Product : productPage.getContent()) {
System.out.println(Product);
}
}
}
I won't operate the test one by one. Just pay attention to some places
- When the save and update methods are executed, the index has been initialized
- Only some api tests are listed here. Others can try them slowly
- productDao cannot perform index level operations. It can only operate on document data
Core class
ElasticsearchRestTemplate
ElasticsearchRestTemplate inherits AbstractElasticsearchTemplate

AbstractElasticsearchTemplate implements ElasticsearchOperations interface

ElasticsearchOperations inherits DocumentOperations, SearchOperations

Explanation of Elasticsearch operation from the official website:
- IndexOperations defines index level operations, such as creating or deleting indexes.
- DocumentOperations defines operations that store, update, and retrieve entities based on IDS.
- SearchOperations defines the operation of searching multiple entities using a query
- ElasticsearchOperations combines the DocumentOperations and SearchOperations interfaces.
ElasticsearchOperations
Write a TestController to test a wave of ElasticsearchOperations
// Test ElasticsearchOperations
@RestController
@RequestMapping("/")
public class TestController {
private final ElasticsearchOperations elasticsearchOperations;
public TestController(ElasticsearchOperations elasticsearchOperations) {
this.elasticsearchOperations = elasticsearchOperations;
}
@PostMapping("/user")
public String save(@RequestBody User user) {
// Index query object: set query criteria
IndexQuery indexQuery = new IndexQueryBuilder()
// . withVersion(2L) set the version number to 2
.withId(String.valueOf(user.getId()))// Set the index id to user's id
.withObject(user) // Tell him which entity object it is
.build(); // return
// IndexCoordinates.of("user") the index name is user, which is user-defined
// If there is no such index, he will create the index himself and add / update a User document data
return elasticsearchOperations.index(indexQuery, IndexCoordinates.of("user"));
}
@PostMapping("/product")
public String save2(@RequestBody Product product) {
IndexQuery indexQuery = new IndexQueryBuilder()
.withId(String.valueOf(product.getId()))
.withObject(product)
.build();
return elasticsearchOperations.index(indexQuery, IndexCoordinates.of("product"));
}
// Find by id
@GetMapping("/user/{id}")
public User findById(@PathVariable("id") Long id) {
return elasticsearchOperations.get(String.valueOf(id), User.class, IndexCoordinates.of("user"));
}
// Query all
@GetMapping("/user/")
public List<SearchHit<User>> search() {
SearchHits<User> hits = elasticsearchOperations.search(Query.findAll(), User.class, IndexCoordinates.of("user"));
hits.forEach(System.out::println);
return hits.getSearchHits();
}
@GetMapping("/product/")
public List<SearchHit<Product>> search2() {
SearchHits<Product> hits = elasticsearchOperations.search(Query.findAll(), Product.class, IndexCoordinates.of("product"));
hits.forEach(System.out::println);
return hits.getSearchHits();
}
}
Some query conditions of indexQuery
- If the document data corresponding to the query criteria is found, the document will be updated (note the version constraint)
- Add if not found
IndexOperations part of the source code
package org.springframework.data.elasticsearch.core;
·······
/**
* IndexOperations Bind to an entity class or IndexCoordinate by
*/
public interface IndexOperations {
boolean create();
boolean create(Map<String, Object> settings);
boolean create(Map<String, Object> settings, Document mapping);
boolean createWithMapping();
boolean delete();
boolean exists();
void refresh();
Document createMapping();
Document createMapping(Class<?> clazz);
default boolean putMapping() {
return putMapping(createMapping());
}
boolean putMapping(Document mapping);
default boolean putMapping(Class<?> clazz) {
return putMapping(createMapping(clazz));
}
Map<String, Object> getMapping();
Settings createSettings();
Settings createSettings(Class<?> clazz);
Settings getSettings();
Settings getSettings(boolean includeDefaults);
}
ElasticsearchRepository
ElasticsearchRepository inherits PagingAndSortingRepository

PagingAndSortingRepository inherits from CrudRepository
CrudRepository
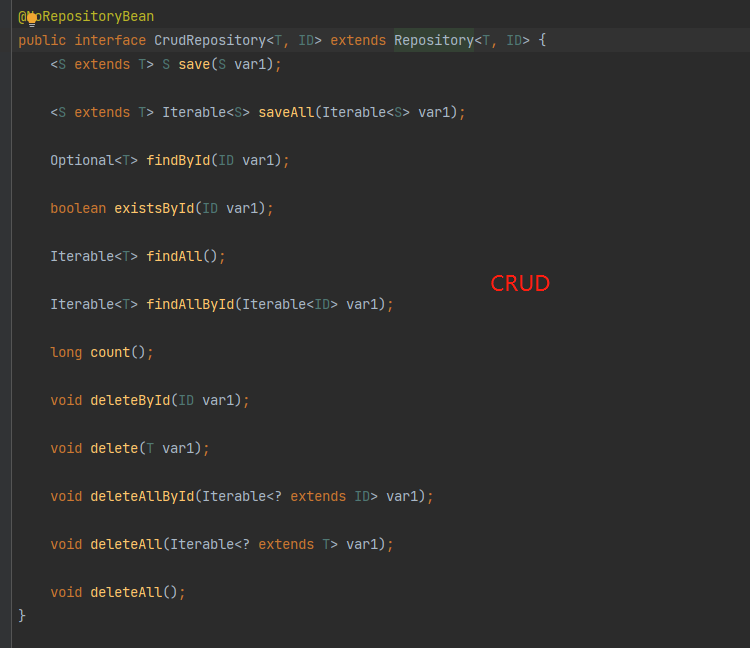
Explain CrudRepository on the official website
Relationship between ElasticsearchRestTemplate
- ElasticsearchRestTemplate is an implementation of ElasticsearchOperations using the interface of the advanced REST client.
- ElasticsearchRestTemplate still uses RestHighLevelClient
Our custom configuration class inherits the AbstractElasticsearchConfiguration abstract class source code
public abstract class AbstractElasticsearchConfiguration extends ElasticsearchConfigurationSupport {
/**
* Return the {@link RestHighLevelClient} instance used to connect to the cluster. <br />
*
* @return never {@literal null}.
*/
@Bean
public abstract RestHighLevelClient elasticsearchClient();
/**
* Creates {@link ElasticsearchOperations}.
*
* @return never {@literal null}.
*/
@Bean(name = { "elasticsearchOperations", "elasticsearchTemplate" })
public ElasticsearchOperations elasticsearchOperations(ElasticsearchConverter elasticsearchConverter,
RestHighLevelClient elasticsearchClient) {
ElasticsearchRestTemplate template = new ElasticsearchRestTemplate(elasticsearchClient, elasticsearchConverter);
template.setRefreshPolicy(refreshPolicy());
return template;
}
}
In essence, it is only a layer of encapsulation for RestHighLevelClient
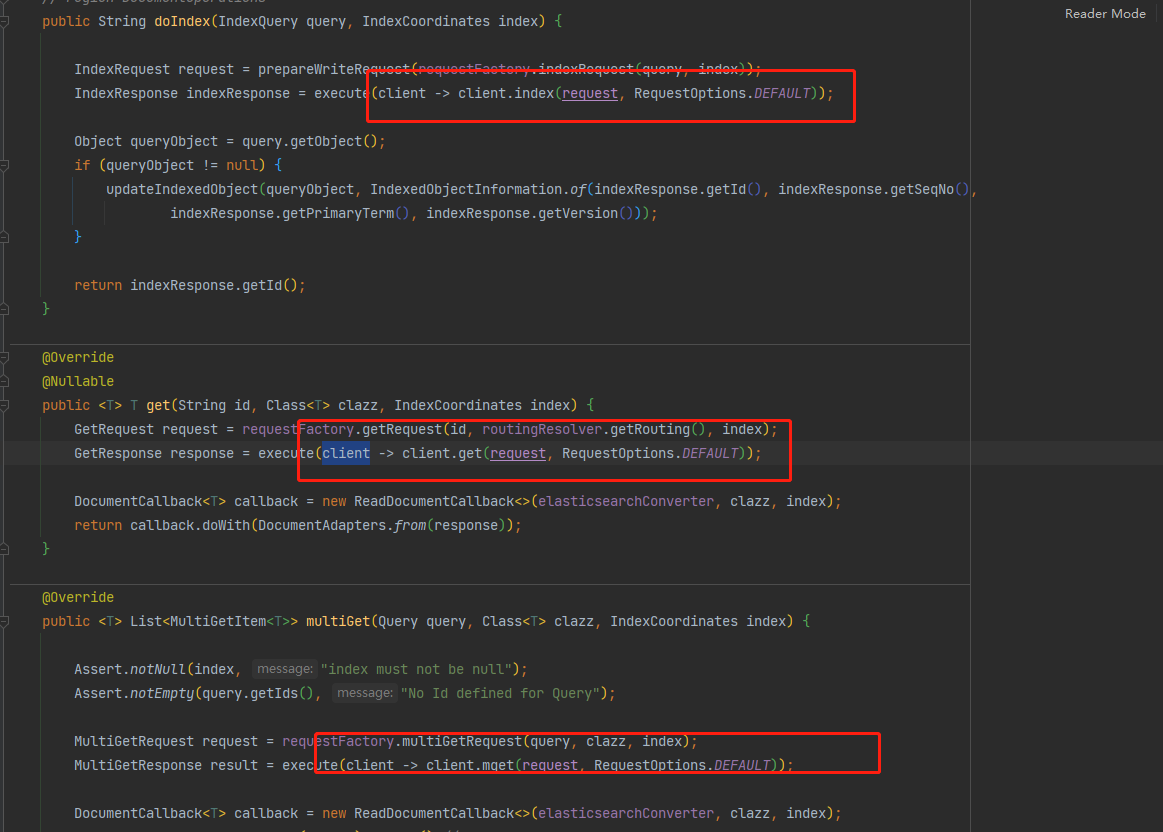
Therefore, it is more comfortable for us to use this ElasticsearchRestTemplate, and there is a lot of redundancy when using RestHighLevelClient.