Introduction to Druid
Druid is a project on Alibaba Open Source Platform. The whole project is composed of database connection pool, plug-in framework and SQL parser. The main purpose of this project is to extend some limitations of JDBC and enable programmers to achieve some special requirements, such as requesting credentials from key service, statistics of SQL information, and SQL performance receipts. Set, SQL injection check, SQL translation, etc., programmers can customize to achieve their own functions.
Druid is first and foremost a database connection pool, but it is not only a database connection pool, but also contains a ProxyDriver, a series of built-in JDBC component libraries, and an SQL Parser. Druid is the best database connection pool for monitoring in the Java world. It also performs well in terms of function, performance and scalability.
1. What can Druid do?
- Instead of other Java connection pools, Druid provides an efficient, powerful and scalable database connection pool.
- It can monitor database access performance. Druid provides a powerful StatFilter plug-in, which can count the execution performance of SQL in detail. It is very helpful for online analysis of database access performance.
- Database password encryption. Writing database passwords directly in configuration files is a bad behavior, which can easily lead to security problems. Druid Druiver and Druid Data Source both support Password Callback.
- SQL execution log, Druid provides different LogFilter, can support Common-Logging, Log4j and JdkLog, can select the appropriate LogFilter according to need, monitor the application database access.
- Extending JDBC, if you want to have programming requirements for JDBC layer, you can easily write JDBC layer extension plug-ins through the Filter mechanism provided by Druid.
2. Spring Boot Integrated Druid
It is very gratifying that Ali has also provided Spring Boot Starter support for Druid. The official website explains this: Druid Spring Boot Starter is used to help you easily integrate Druid database connection pool and monitoring in Spring Boot project.
What did Druid Spring Boot Starter do? In fact, this component package is very simple, mainly provides a lot of automated configuration, according to the Spring Book concept of a lot of content is pre-configured, so that we use more simple and convenient.
2. MyBatis uses Druid as connection pool
1. Introducing dependency packages
- The latest version of druid-spring-boot-starter is 1.1.10, which automatically relies on Druid-related packages.
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency>
2. application configuration
- The name of the Druid Spring Boot Starter configuration property fully complies with Druid. Druid database connection pool and monitoring can be configured through the Spring Boot configuration file, and default values are used if no configuration is available.
# Entity class package path mybatis.type-aliases-package=com.neo.model spring.datasource.type: com.alibaba.druid.pool.DruidDataSource spring.datasource.url=jdbc:mysql://localhost:3306/test?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true spring.datasource.username=root spring.datasource.password=root spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver # Initialization size, minimum, maximum number of connections spring.datasource.druid.initial-size=3 spring.datasource.druid.min-idle=3 spring.datasource.druid.max-active=10 # Configuration to get the connection waiting timeout time spring.datasource.druid.max-wait=60000 # Monitor background accounts and passwords spring.datasource.druid.stat-view-servlet.login-username=admin spring.datasource.druid.stat-view-servlet.login-password=admin # Configure StatFilter spring.datasource.druid.filter.stat.log-slow-sql=true spring.datasource.druid.filter.stat.slow-sql-millis=2000
On the basis of previous projects, the configuration of Druid connection pool and SQL monitoring is added, and the monitoring function of StatFilter is turned on by default by druid-spring-boot-starter. Druid Spring Boot Starter is not limited to supporting the above configuration attributes. Configurable attributes that provide setter methods in Druid Data Source will be supported.
- More configuration content can be searched for druid-spring-boot-starter in github
3. View Druid Monitoring Background
-
When the configuration is completed, the project access address is started directly: localhost:8080/druid, and the login page of Druid monitoring background will appear. After entering the account and password, it will go to the home page.
-
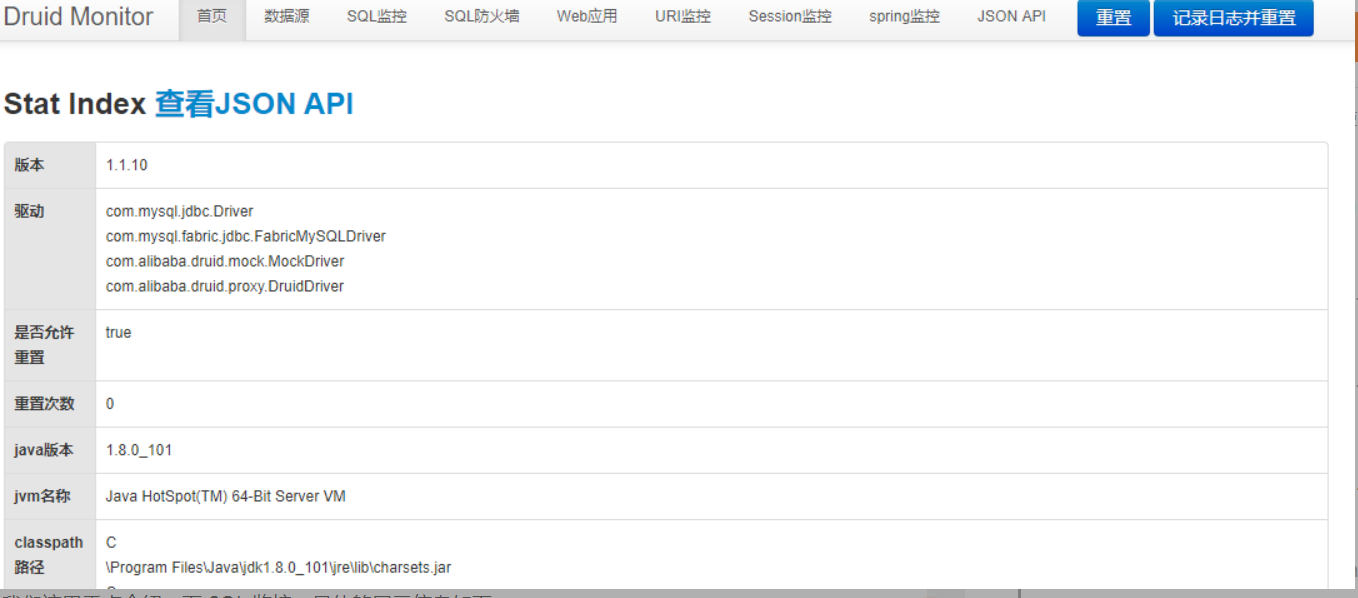
-
Home page will show the JDK version, database driver, JVM related statistics used by the project. According to the menu above, we can see that Druid is very powerful, supporting data source, SQL monitoring, SQL firewall, URI monitoring and many other functions.
-
Here we focus on the SQL monitoring, the specific display information is as follows:
-
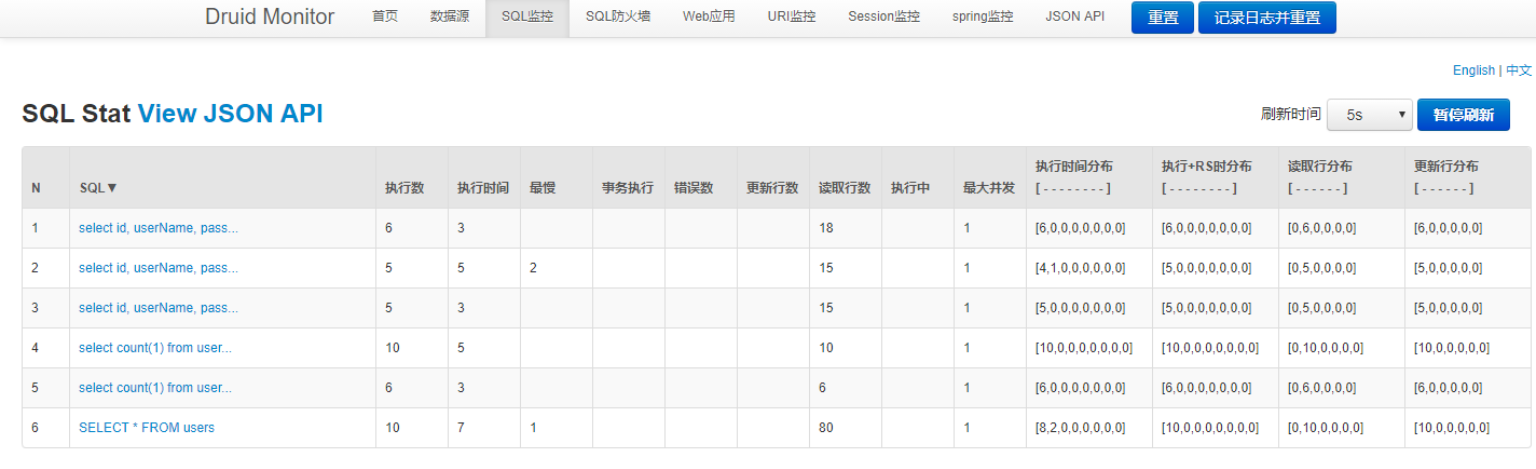
-
The SQL monitoring here prints out the specific execution of the SQL in the project, showing how many times the SQL has been executed, how much data has been returned each time, and what the execution time distribution is. These functions are very practical, convenient for us to find slow SQL in actual production, and finally optimize the SQL.
3. MyBatis + Druid Multiple Data Sources
1. Configuration file
- First, we need to configure two different data sources:
spring.datasource.druid.one.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.one.url = jdbc:mysql://localhost:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true spring.datasource.druid.one.username = root spring.datasource.druid.one.password = root spring.datasource.druid.two.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.two.url = jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true spring.datasource.druid.two.username = root spring.datasource.druid.two.password = root
- The first data source uses spring.datasource.druid.one. * as prefix to connect to database test1, and the second data source uses spring.datasource.druid.two. * as prefix to connect to database test2.
Strongly note: Spring Boot version 2.X no longer supports configuration inheritance. For multiple data sources, all configurations of each data source need to be configured separately, otherwise the configuration will not take effect.
# StatViewServlet configuration spring.datasource.druid.stat-view-servlet.login-username=admin spring.datasource.druid.stat-view-servlet.login-password=admin # Configure StatFilter spring.datasource.druid.filter.stat.log-slow-sql=true spring.datasource.druid.filter.stat.slow-sql-millis=2000 # Druid Data Source 1 Configuration spring.datasource.druid.one.initial-size=3 spring.datasource.druid.one.min-idle=3 spring.datasource.druid.one.max-active=10 spring.datasource.druid.one.max-wait=60000 # Druid Data Source 2 Configuration spring.datasource.druid.two.initial-size=6 spring.datasource.druid.two.min-idle=6 spring.datasource.druid.two.max-active=20 spring.datasource.druid.two.max-wait=120000
- As the public information configuration of Druid, filter and stat are needed to configure other data sources separately.
2. Injecting multiple data sources
-
First, create different Mapper package paths for two data sources, copy the previous User Mapper to the package com.neo.mapper.one and com.neo.mapper.two paths, and rename them User One Mapper and User TwoMapper respectively.
-
Define a MultiDataSourceConfig class to load two different data sources:
@Configuration public class MultiDataSourceConfig { @Primary @Bean(name = "oneDataSource") @ConfigurationProperties("spring.datasource.druid.one") public DataSource dataSourceOne(){ return DruidDataSourceBuilder.create().build(); } @Bean(name = "twoDataSource") @ConfigurationProperties("spring.datasource.druid.two") public DataSource dataSourceTwo(){ return DruidDataSourceBuilder.create().build(); } }
- You must specify a default master data source, using the annotation: @Primary. Data Source Config, which loads and configures two data sources, is consistent with the configuration used by MyBatis multiple data sources in the previous course.
Note: In the case of multiple data sources, we do not need to start the class to add the @MapperScan("com.xxx.mapper") annotation.
3. Test Use
- After all the above configurations are completed, start the project to access this address: localhost:8080/druid, click on the data source to view the database connection information.
If the data source has no information, first access the address: localhost:8080/getUsers, which is used to trigger the database connection. Without the use of SQL, the page can not monitor the configuration information of the data source, and the execution of SQL can not be monitored by the SQL monitoring page.
-

-
Display information extracted from data source 1
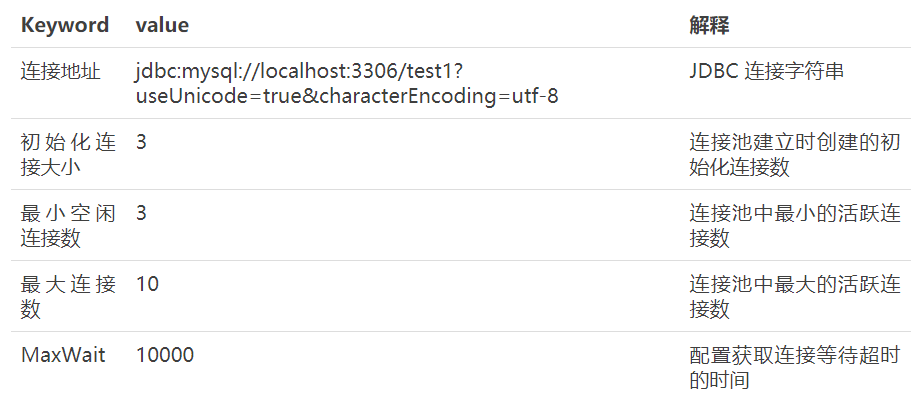
-
Display information extracted from data source 2
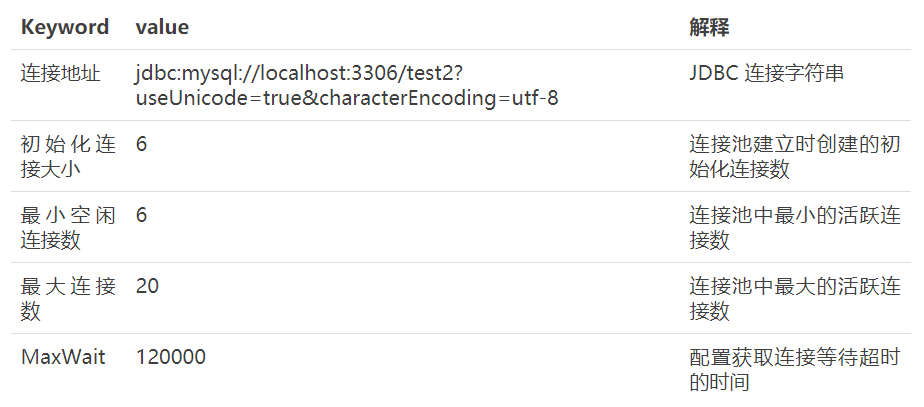
4. Using Druid as Connection Pool in Spring Data JPA
1. Introducing dependency packages
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency>
- Adding Web dependencies is due to the need to keep the container running at startup and to add Web access to the project as follows:
@RestController public class UserController { @Autowired private UserRepository userRepository; @RequestMapping("/getUsers") public List<User> getUsers() { List<User> users=userRepository.findAll(); return users; } }
2. application configuration
# Initialization size, minimum, maximum number of links spring.datasource.druid.initial-size=3 spring.datasource.druid.min-idle=3 spring.datasource.druid.max-active=10 # Configuration to get the connection waiting timeout time spring.datasource.druid.max-wait=60000 # StatViewServlet configuration spring.datasource.druid.stat-view-servlet.login-username=admin spring.datasource.druid.stat-view-servlet.login-password=admin # Configure StatFilter spring.datasource.druid.filter.stat.log-slow-sql=true spring.datasource.druid.filter.stat.slow-sql-millis=2000
3. View Druid Monitoring Background
- Okay, so we successfully configure Druid in the JPA project. Start the project by visiting the address: localhost:8080/getUsers, and then visiting the localhost:8080/druid to view the SQL execution record, as follows:

SQL statements like create table addres... and drop table if exist... will be found because we set JPA's policy to create, spring.jpa.properties.hibernate.hbm2ddl.auto=create, which means that tables will be recreated every time we restart to facilitate our use in testing.
5. JPA + Druid + Multiple Data Sources
Because Druid has not yet been officially optimized for Spring Boot 2.0, there will be problems in some scenarios. For example, if you use druid-spring-boot-starter provided by Druid directly in the case of JPA with multiple data sources, you will get an error. Since druid-spring-boot-starter does not support it, we will use the original Druid. The raw package is encapsulated.
1. Introducing dependency packages
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.10</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <!--<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency>-->
Delete the dependency on druid-spring-boot-starter package, add Druid dependency package, add log4j because Druid relies on log4j to print logs.
2. Multiple Data Source Configuration
- Configuration file we do this design, extract the same configuration of multiple data sources to share, and configure the personality configuration information of each data source separately.
- The configuration of database 1 begins with spring.datasource.druid.one:
spring.datasource.druid.one.url=jdbc:mysql://localhost:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true spring.datasource.druid.one.username=root spring.datasource.druid.one.password=root spring.datasource.druid.one.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.one.initialSize=3 spring.datasource.druid.one.minIdle=3 spring.datasource.druid.one.maxActive=10
- The configuration of database 2 begins with spring.datasource.druid.two:
spring.datasource.druid.two.url=jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true spring.datasource.druid.two.username=root spring.datasource.druid.two.password=root spring.datasource.druid.two.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.two.initialSize=6 spring.datasource.druid.two.minIdle=20 spring.datasource.druid.two.maxActive=30
- The common configuration of multiple data sources, starting with spring.datasource.druid, is a common configuration item for multiple data sources.
Configuration to get the connection waiting timeout time spring.datasource.druid.maxWait=60000 #How often is the configuration interval detected to detect idle connections that need to be closed in milliseconds? spring.datasource.druid.timeBetweenEvictionRunsMillis=60000 #Configure the minimum lifetime of a connection in the pool in milliseconds spring.datasource.druid.minEvictableIdleTimeMillis=600000 spring.datasource.druid.maxEvictableIdleTimeMillis=900000 spring.datasource.druid.validationQuery=SELECT 1 FROM DUAL #y checks if the connection is valid spring.datasource.druid.testWhileIdle=true #Check the availability of connection pools before removing connections from the pool spring.datasource.druid.testOnBorrow=false #Check the availability of connection pools before returning them to the pool spring.datasource.druid.testOnReturn=false # Whether to open PSCache, spring.datasource.druid.poolPreparedStatements=true #And specify the size of the PSCache on each connection spring.datasource.druid.maxPoolPreparedStatementPerConnectionSize=20 #Configure filters for monitoring statistical interception spring.datasource.druid.filters=stat,wall,log4j #Open merge SQL function by connecting Properties attribute, slow SQL record spring.datasource.druid.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=600
-
For more configuration information, please refer to GitHub "/ Alibaba / Druid / wiki / Druid Data Source% E9% 85% 8D% E7% BD% AE% E5% B1% 9E% E6% 80% A7% E5% 88% 97% E8% A1% A8".
-
We define a DruidConfig to load all public configuration items as follows:
@Component @ConfigurationProperties(prefix="spring.datasource.druid") public class DruidConfig { protected String url; protected String username; protected String password; protected String driverClassName; protected int initialSize; protected int minIdle; protected int maxActive; protected int maxWait; protected int timeBetweenEvictionRunsMillis; protected long minEvictableIdleTimeMillis; protected long maxEvictableIdleTimeMillis; protected String validationQuery; protected boolean testWhileIdle; protected boolean testOnBorrow; protected boolean testOnReturn; protected boolean poolPreparedStatements; protected int maxPoolPreparedStatementPerConnectionSize; protected String filters; protected String connectionProperties; // Omit getter setter }
- Define a DruidOne Config to load the configuration item of Data Source 1 and inherit DruidConfig:
@Component @ConfigurationProperties(prefix="spring.datasource.druid.one") public class DruidOneConfig extends DruidConfig{ private String url; private String username; private String password; private String driverClassName; private int initialSize; private int minIdle; private int maxActive; // Omit getter setter }
- Define a DruidTwoConfig to load the configuration item of Data Source 2 and inherit DruidConfig. The code is basically the same as the DruidOneConfig class.
3. Loading at startup
- Create the DruidDBConfig class to inject configuration multi-data source information at startup.
@Configuration public class DruidDBConfig { @Autowired private DruidConfig druidOneConfig; @Autowired private DruidConfig druidTwoConfig; @Autowired private DruidConfig druidConfig; }
- Create the initDruidDataSource() method in the class to initialize the properties of the Druid data source. The personalized configuration of each database is read from the config pair, and the common configuration items are retrieved from the druidConfig object.
private DruidDataSource initDruidDataSource(DruidConfig config) { DruidDataSource datasource = new DruidDataSource(); datasource.setUrl(config.getUrl()); datasource.setUsername(config.getUsername()); datasource.setPassword(config.getPassword()); datasource.setDriverClassName(config.getDriverClassName()); datasource.setInitialSize(config.getInitialSize()); datasource.setMinIdle(config.getMinIdle()); datasource.setMaxActive(config.getMaxActive()); // common config datasource.setMaxWait(druidConfig.getMaxWait()); datasource.setTimeBetweenEvictionRunsMillis(druidConfig.getTimeBetweenEvictionRunsMillis()); datasource.setMinEvictableIdleTimeMillis(druidConfig.getMinEvictableIdleTimeMillis()); datasource.setMaxEvictableIdleTimeMillis(druidConfig.getMaxEvictableIdleTimeMillis()); datasource.setValidationQuery(druidConfig.getValidationQuery()); datasource.setTestWhileIdle(druidConfig.isTestWhileIdle()); datasource.setTestOnBorrow(druidConfig.isTestOnBorrow()); datasource.setTestOnReturn(druidConfig.isTestOnReturn()); datasource.setPoolPreparedStatements(druidConfig.isPoolPreparedStatements()); datasource.setMaxPoolPreparedStatementPerConnectionSize(druidConfig.getMaxPoolPreparedStatementPerConnectionSize()); try { datasource.setFilters(druidConfig.getFilters()); } catch (SQLException e) { logger.error("druid configuration initialization filter : {0}", e); } datasource.setConnectionProperties(druidConfig.getConnectionProperties()); return datasource; }
- InititDruidDataSource () method is called at startup to build different data sources.
@Bean(name = "primaryDataSource") public DataSource dataSource() { return initDruidDataSource(druidOneConfig); } @Bean(name = "secondaryDataSource") @Primary public DataSource secondaryDataSource() { return initDruidDataSource(druidTwoConfig); }
- Next, entity Manager is built from different data sources. Finally, the logic injected into Repository is the same as before. The only change is to build and open monitoring pages in data sources.
4. Open the monitoring page
- Because we use native Druid packages, we need to manually turn on monitoring and configure statistics.
@Configuration public class DruidConfiguration { @Bean public ServletRegistrationBean<StatViewServlet> druidStatViewServlet() { ServletRegistrationBean<StatViewServlet> servletRegistrationBean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*"); servletRegistrationBean.addInitParameter("loginUsername", "admin"); servletRegistrationBean.addInitParameter("loginPassword", "admin"); servletRegistrationBean.addInitParameter("resetEnable", "false"); return servletRegistrationBean; } @Bean public FilterRegistrationBean<WebStatFilter> druidStatFilter() { FilterRegistrationBean<WebStatFilter> filterRegistrationBean = new FilterRegistrationBean<>(new WebStatFilter()); filterRegistrationBean.setName("DruidWebStatFilter"); filterRegistrationBean.addUrlPatterns("/*"); filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"); return filterRegistrationBean; } }
-
When the configuration is completed, restart the startup project access address localhost:8080/druid/sql.html and you can see the SQL operation statements with two data sources, which proves that the configuration of multi-data source SQL monitoring is successful.
-
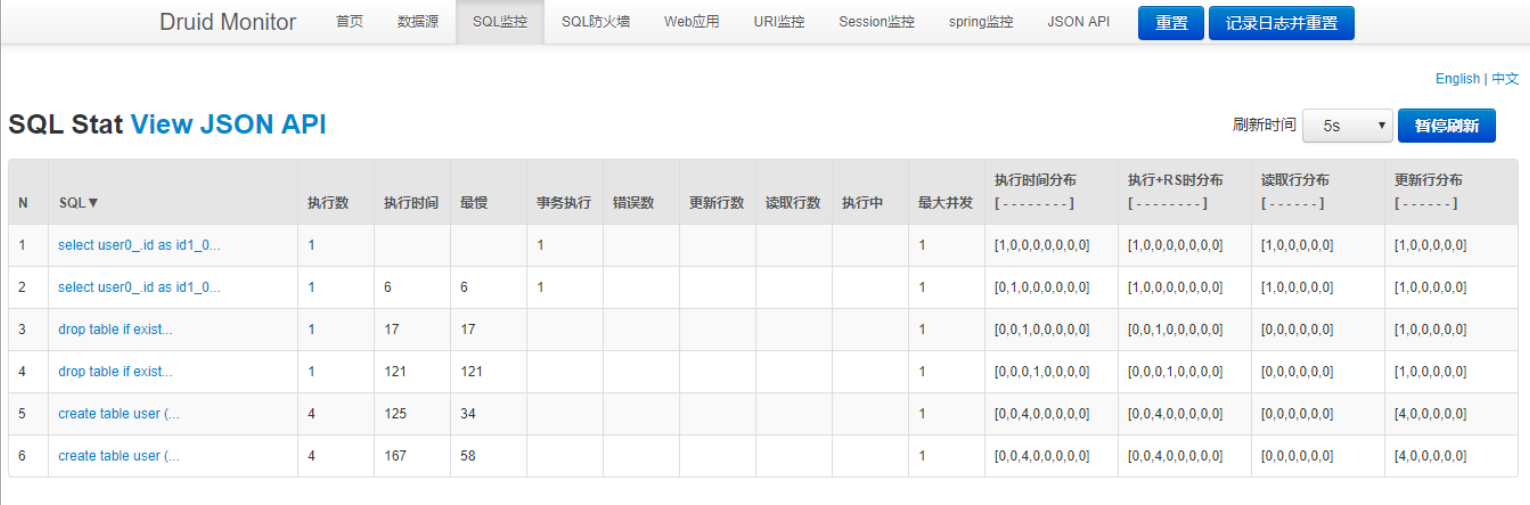
-
At this point, the integration of JPA + Druid + multiple data sources has been completed.
Six, summary
Druid is an excellent open source software for database connection pool. Druid can be easily integrated with druid-spring-boot-starter provided by Druid. Druid provides many preset functions, which are very convenient for us to monitor and analyze SQL. Druid's support for Spring Boot 2.0 is not perfect enough. For special scenarios using Druid, Druid native package can be used for self-encapsulation.