Preface
It feels like hystrix is wonderful, and the documents are very good, so where is this summary?
Before writing Hystrix, let's briefly talk about fuses and current limiting, so that when you finish reading, you can easily understand Hystrix.
Fuse
The fuse model is derived from Martin Fowler's Circuit Breaker article. "Fuse" is a kind of switching device, which is used to protect the overload of the circuit. When there is a short circuit in the circuit, the "fuse" can cut off the fault circuit in time to prevent serious consequences such as overload, fever and even fire.
There are three states in fuse design, life and life, cycling and reciprocating.
- Closed (closed, traffic can enter normally)
- Open (that is, the fuse state, once the error reaches the threshold, the fuse will open, rejecting all traffic)
- Half-open (half-open state, open state will automatically enter this state after a period of time, re-receive traffic, once the request fails, re-enter open state, but if the number of successful reached the threshold, will enter closed state)
The overall process is shown in the following figure:
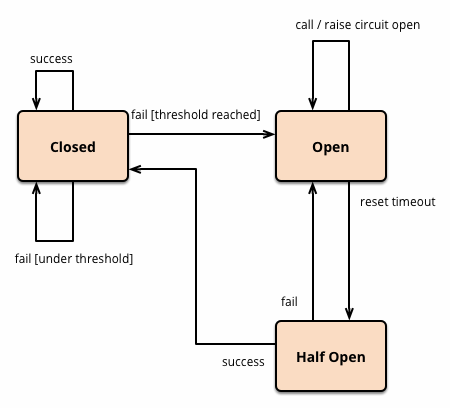
CLOSED Close State: Allows traffic to pass through.
OPEN open state: traffic is not allowed to pass through, that is, in a degraded state, degraded logic.
HALF_OPEN semi-open state: Allow some traffic to pass through, and pay attention to the results of these traffic, if there are timeouts, exceptions, etc., will enter the OPEN state, if successful, then will enter the CLOSED state.
In the distributed architecture, the fuse mode is also similar. When a service unit fails (similar to short circuit with electrical appliances), it returns an error response to the caller through the fault monitoring of the circuit breaker (similar to fuse), rather than waiting for a long time. In this way, the thread will not be occupied and released for a long time because of calling the fault service, and the spread of the fault in the distributed system will be avoided.
Current limiting
In the development of high concurrent systems, there are many ways to protect the system, such as caching, degrading and current limiting. The purpose of caching is to speed up system access and increase system processing capacity, which can be described as a silver bullet against high concurrency. Degradation is a scenario that needs to be temporarily shielded when the service goes wrong or affects the performance of the core process, and then opened after the peak or problem has been solved. Some scenarios can not be solved by caching and downgrading, such as scarce resources (secondkill, snap-up), writing services (such as comments, orders), frequent complex queries (the last pages of comments), etc. Therefore, there is a need for a means to limit concurrency/requests in these scenarios, which is current limiting.
The purpose of current limiting is to protect the system by limiting the speed of concurrent access/requests or requests within a time window. Once the speed limit is reached, the system can deny service (directed to error pages or inform that resources are no longer available), queue or wait (such as secondkill, comment, order), degrade (return to the bottom of the cycle). According to or default data, such as goods details page inventory default inventory. In pressure measurement, we can find the processing peak value of each system, then we can set the peak value threshold, when the system is overloaded, we can guarantee the system availability by rejecting overload requests. In addition, the current limiting threshold can be dynamically adjusted according to the throughput, response time and availability of the system.
In general, the limitations for developing high concurrent system scenarios are: limiting total concurrency (such as database connection pool and thread pool), limiting instantaneous concurrency (such as limit_conn module of Nginx, which is used to limit instantaneous concurrent connections), limiting average rate in time windows (such as Rate Limiter of Guava, limit_req module of Nginx). To limit the average rate per second, as well as the remote interface call rate, limit the consumption rate of MQ, and so on. In addition, it can limit the current according to the number of network connections, network traffic, CPU or memory load.
Current Limiting Algorithms
Common current limiting algorithms are token bucket and leaky bucket. Counters can also be used for rough current limiting.
Token Bucket
The token bucket algorithm is a bucket that stores a fixed capacity token and adds tokens to the bucket at a fixed rate. The token bucket algorithm is described as follows:
- Assuming a limit of 2r/s, tokens are added to the bucket at a fixed rate of 500 milliseconds.
- The bucket holds up to b tokens. When the bucket is full, the newly added token will be discarded or rejected.
- When an n-byte packet arrives, n tokens are deleted from the bucket, and then the packet is sent to the network.
- If there are fewer than n tokens in the bucket, the token is not deleted and the packet is current-limited (either discarded or waiting in the buffer).
Leaky bucket algorithm
The leaky bucket can be used for flow shaping and flow control when it is used as a measuring tool. The leaky bucket algorithm is described as follows:
- A leaky bucket with a fixed capacity flows water droplets at a constant fixed rate.
- If the barrel is empty, no water droplets need to flow out.
- Water droplets can flow into the leaky bucket at any rate.
- If the inflow droplets exceed the capacity of the bucket, the inflow droplets overflow (are discarded), and the capacity of the leaky bucket remains unchanged.
Token bucket versus leaky bucket
- The token bucket adds tokens to the bucket at a fixed rate. Whether the request is processed depends on whether the token in the bucket is sufficient. When the number of tokens is reduced to zero, the new request is rejected.
- The leaky bucket outflows requests at a constant fixed rate, and the request inflow rate is arbitrary. When the number of requests accumulates to the leaky bucket capacity, the new requests are rejected.
- The token bucket limits the average inflow rate (allowing burst requests to be processed as long as there are tokens, supporting multiple tokens at a time), and allows burst traffic for a given program.
- The leaky bucket limits the constant outflow rate (that is, the outflow rate is a constant value, such as the rate of all 1, but not one at a time and two at a time), thus smoothing the burst inflow rate.
- Token buckets allow sudden bursts of certain programs, while leaky buckets are primarily designed to smooth the inflow rate.
- The implementation of the two algorithms can be the same, but the direction is opposite, and the effect of current limiting is the same for the same parameters.
Common current limiting methods include: limiting total concurrency (database connection pool, thread pool), limiting instantaneous concurrency (such as limit_conn module of Nginx), limiting average rate of time window (such as Rate Limiter of Guava, limit_req module of Nginx), limiting call rate of remote interface, limiting consumption rate of MQ, etc. From the application level, it can be divided into: access layer current limiting, application layer current limiting and distributed current limiting.
What is Hystrix
This section is easy to read. I've copied it down to see the document Hystrix: https://github.com/Netflix/Hystrix/wiki
In a distributed environment, some of the many service dependencies inevitably fail. Hystrix is a library that helps you control the interaction between these distributed services by adding deferred fault-tolerant and fault-tolerant logic. Hystrix achieves this goal by isolating access points between services, preventing cascading failures between them, and providing backup options, all of which can improve the overall resilience of the system.
Hystrix is designed to perform the following actions:
- Access dependencies through third-party client libraries (usually over the network) to prevent and control delays and failures.
- Stop cascading failures in complex distributed systems.
- Quick failure and quick recovery.
- If possible, retreat and downgrade gracefully.
- Realize near real-time monitoring, alarm and operation control.
Applications in complex distributed architectures have many dependencies, and each dependency inevitably fails at some point. If the host application is not isolated from these external failures, it may be dragged down by them.
For example, for an application that relies on 30 services, each service has 99.99% uptime. You can expect the following:
99.9930 = 99.7% available
That is to say, 0.03% of 100 million requests = 30,000,000 will fail.
If all goes well, two hours of service per month is not available.
The reality is usually worse.
When all is well, the request looks like this:
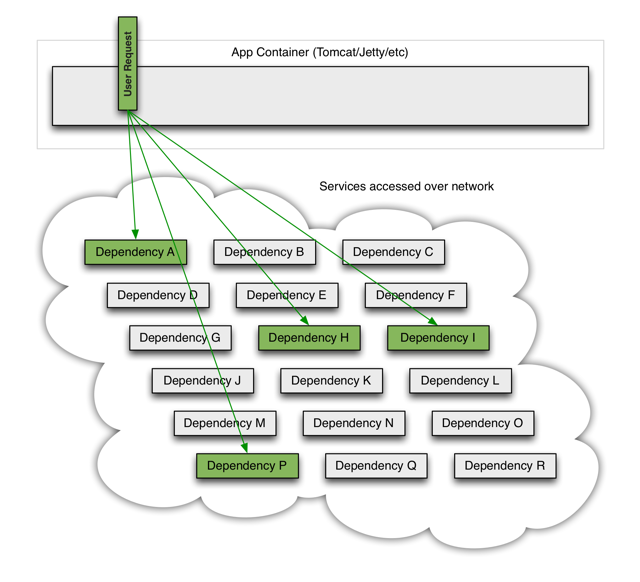
When one of the systems has latency, it may block the entire user request:
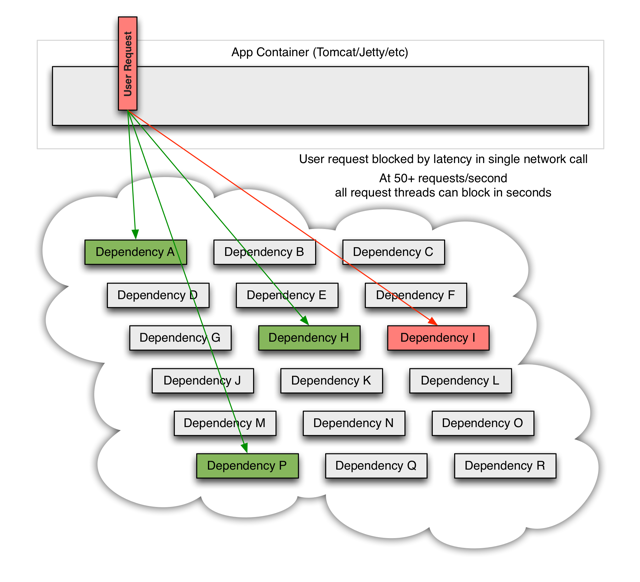
In the case of high traffic, the delay of a back-end dependency may cause all resources on all servers to be saturated in seconds (PS: means that subsequent requests will not provide immediate service)
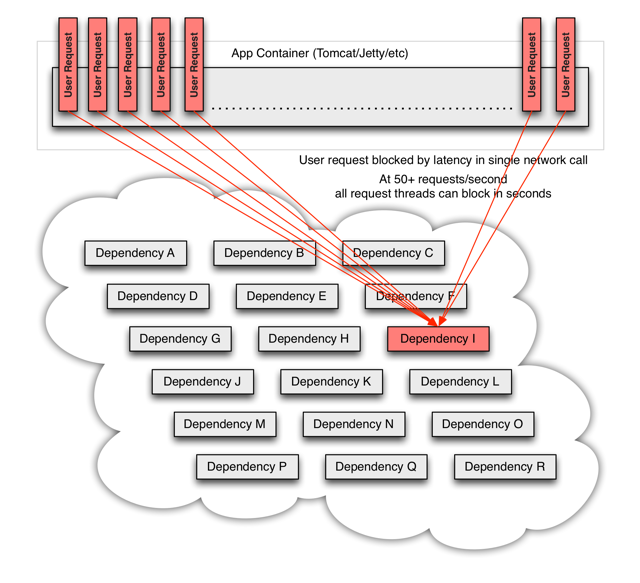
When you use Hystrix to wrap each underlying dependency, the architecture shown in the figure above will change to something similar to the one shown below. Each dependency is isolated from each other, resources that can be saturated in the event of delay are limited, and are covered in fallback logic, which determines the response to any type of failure in the dependency: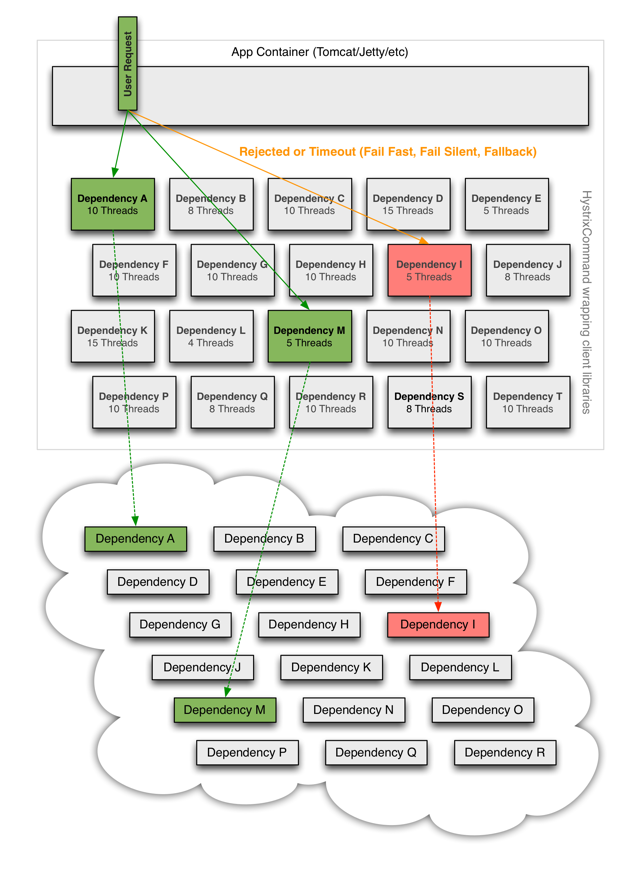
Feign calls using the Hystrix example
First of all, the previous sections of the environment, ah, no or need to see my previous articles bar
pom.xml
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>
feign call interface
@FeignClient(name = "trade-promotion", fallback = PromotionClientFallback.class) public interface PromotionClient { @RequestMapping(value = "/Promotion/delete", method = RequestMethod.GET) String releasePromotion(@RequestParam int orderID); }
fallback class
@Component public class PromotionClientFallback implements PromotionClient { @Override public String releasePromotion(@RequestParam int orderID) { return "hello ,fallback !"; } }
call
@RestController @RequestMapping(value = "/promotion", method = RequestMethod.GET) public class PromotionController { @Autowired PromotionClient promotionClient; @RequestMapping(value = "/delete") public String delete(@RequestParam int orderID) { return promotionClient.releasePromotion(orderID); } }
configuration file
#hystrix
feign.hystrix.enabled=true
Well, yes. Let's say that if the remote call interface is abnormal, Fallback will be executed to return "hello, fallback!"
If you want to know why you failed, why you failed.
@Component public class PromotionClientFallbackFactory implements FallbackFactory<PromotionClient> { @Override public PromotionClient create(Throwable cause) { return new PromotionClient() { @Override public String releasePromotion(int orderID) { return "fallback:orderid=" + orderID + ",message:" + cause.getMessage(); } }; } }
@FeignClient(name = "trade-promotion", fallbackFactory = PromotionClientFallbackFactory.class) public interface PromotionClient { @RequestMapping(value = "/Promotion/delete", method = RequestMethod.GET) String releasePromotion(@RequestParam int orderID); }
Okay, that's ok ay.
Hystrix configuration
#hystrix
feign.hystrix.enabled=true
#Whether to turn on fallback function, default is true
hystrix.command.default.fallback.enabled=true
#Opening the hystrix request timeout mechanism can also be set to never timeout
hystrix.command.default.execution.timeout.enabled=true
#Set the timeout time (in milliseconds) for caller execution, default: 1000
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=10000
#This property sets the maximum number of concurrent requests allowed from the calling thread to the HystrixCommand.getFallback () method
#If maximum concurrency is achieved, subsequent requests are rejected and exceptions are thrown.
#Default is 10
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests = 500
#When HystrixCommand.run() uses the isolation strategy of SEMAPHORE, set the maximum concurrency
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests = 1000
#Whether to turn on the circuit breaker function, default to true
hystrix.command.default.circuitBreaker.enabled=true
#This property sets the minimum number of requests in the scroll window that will cause the circuit breaker to trip
#If the value of this property is 20, the circuit breaker will not open during the window time (for example, within 10 seconds) if only 19 requests are received and all failures occur.
#Default value: 20
hystrix.command.default.circuitBreaker.requestVolumeThreshold=200
#After the circuit breaker trips, hystrix will reject new requests within this time limit, and only after this time will the circuit breaker open the gate.
#Default value: 5000
hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds=60000
#Set a threshold for the percentage of failures. If the failure ratio exceeds this value, the circuit breaker trips and enters fallback logic
#Default value: 50, or 50%
hystrix.command.default.circuitBreaker=50
#If true is set, the circuit breaker is forced to close, allowing all requests to be executed regardless of whether the number of failures reaches the circuitBreaker.errorThresholdPercentage value.
#Default value: false
hystrix.command.default.circuitBreaker.forceOpe=false
#If true is set, the circuit breaker is forced to close, allowing all requests to be executed regardless of whether the number of failures reaches the circuitBreaker.errorThresholdPercentage value.
#Default value: false
hystrix.command.default.circuitBreaker.forceClosed=false
#Set the core size of the thread pool, which is the maximum number of concurrent executions. Default 10
hystrix.threadpool.default.coreSize=500
#Maximum queue length. Set the maximum length of BlockingQueue. Default - 1.
#If set to - 1, Synchronize Queue is used.
#LinkedBlockingQueue is used for other positive integers.
hystrix.threadpool.default.maxQueueSize=1000
#Set a threshold for rejecting requests. Only maxQueueSize is valid when it is -1.
#The reason for setting a value is that the maxQueueSize value cannot be changed at run time. We can dynamically modify the allowable queue length by modifying this variable. Default 5
hystrix.threadpool.default.queueSizeRejectionThreshold=1000
#Set the time length of the statistical scroll window, default value: 10000
hystrix.command.default.metrics.rollingStats.timeInMilliseconds=10000
#Set the number of barrels in the scroll window.
#Note: The following configuration must be valid, otherwise an exception will be thrown.
#metrics.rollingStats.timeInMilliseconds % metrics.rollingStats.numBuckets == 0
#For example: 10000/10, 10000/20 is the correct configuration, but 10000/7 is wrong.
#In highly concurrent environments, the recommended length of time per bucket is greater than 100 ms
#Default value: 10
hystrix.command.default.metrics.rollingStats.numBuckets=10
#Sets whether execution delays are tracked and calculated as a percentage of failures. If set to false, all statistics return - 1
#Default value:true
hystrix.command.default.metrics.rollingPercentile.enabled=true
#This property sets the duration of the statistical scroll percentage window, default value: 60000
hystrix.command.default.metrics.rollingPercentile.timeInMilliseconds=60000
#Set the number of buckets in the statistical scroll percentage window
#Note: The following configuration must be valid, otherwise an exception will be thrown.
#metrics.rollingPercentile.timeInMilliseconds % metrics.rollingPercentile.numBuckets == 0
#For example: 60000/6, 60000/60 is the correct configuration, but 10000/7 is wrong.
#In highly concurrent environments, the length of time per bucket is recommended to be greater than 1000ms
#Default value: 6
hystrix.command.default.metrics.rollingPercentile.numBuckets=6
#This property sets the maximum execution time saved per bucket. If the number of buckets is 100 and the statistics window is 10s, if there are 500 executions in the 10s, only the last 100 executions will be counted in the bucket.
#Default value: 100
hystrix.command.default.metrics.rollingPercentile.bucketSize=100
#Sampling time interval
hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds=500
summary
See more official documents and recommend how hystrix works. It's wonderful. Go ahead, it's convenient for you again. If you can't learn well, you can blame yourself for being too busy to read the documents. https://github.com/Netflix/Hystrix/wiki
When you have time to write down hystrix's monitoring, that's all for today, 88