Preface
Integrating Mybtis is very simple for Spring Boot. Through this article, you can get started quickly without pressure, but before I start, I want to talk about my version information:
maven 3.2.5
jdk 1.8
Spring Boot 2.1.6
Create a project
The automated configuration of idea is still used, but here we need to check the following dependencies:
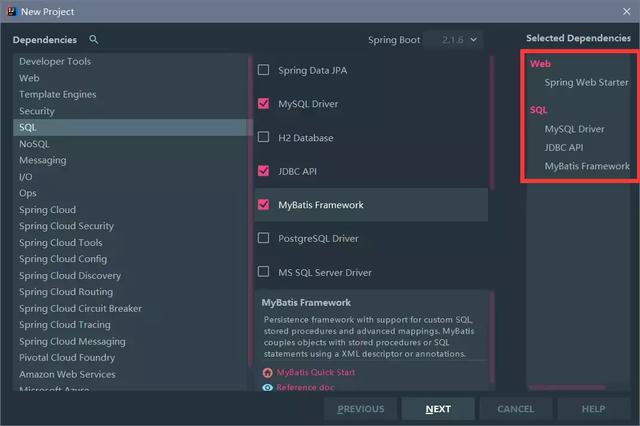
If you check MyBatis, you will find that your pom file contains:
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.0</version> </dependency>
This dependence
As long as it's with *-spring-boot-starter, it's officially recommended by Spring Boot. Here's mybatis. Let's take a look at all the packages under mybatis:
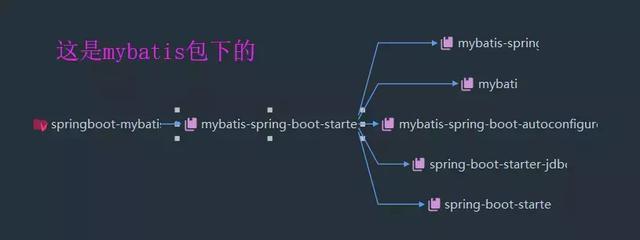
We found that it introduced mybatis-spring packages and so on, as well as mybatis-spring-boot-autoconfigure, which means automatic configuration. For Spring Boot, automatic configuration is a major feature.
Configuring Druid data sources
Spring Boot 2.x data source is hikari, while 1.x is Tomcat, so we need to configure our own data source as follows
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.16</version> </dependency>
Just introduce this dependency.
Then under the application.yml configuration file:
spring: datasource: password: root username: root url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource initialSize: 5 minIdle: 5 maxActive: 20 maxWait: 60000 timeBetweenEvictionRunsMillis: 60000 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 FROM DUAL testWhileIdle: true testOnBorrow: false testOnReturn: false poolPreparedStatements: true #Configuration of filters intercepted by monitoring statistics, removal of the monitoring interface sql can not be counted,'wall'for firewalls filters: stat,wall,log4j maxPoolPreparedStatementPerConnectionSize: 20 useGlobalDataSourceStat: true connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
The following list of attributes is not valid. If you want to be valid, you need special configuration. Druid monitoring is also configured:
package com.carson.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid() {
return new DruidDataSource();
}
//Configuration Druid Monitoring
//1) Configure a Servlet for the management background
@Bean
public ServletRegistrationBean statViewServlet() {
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
Map<String, String> initParams = new HashMap<>();
//Here is the account password of druid monitor, which can be set at will.
initParams.put("loginUsername", "admin");
initParams.put("loginPassword", "123456");
initParams.put("allow", "");
initParams.put("deny", "192.123.11.11");
//Setting initialization parameters
bean.setInitParameters(initParams);
return bean;
}
//2) Configure a monitor filter
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}Start the main class to see if you can enter the Druid Monitor. If you make a mistake, add a log4j dependency:
<dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <!--I don't know why., No addition log4j If you do, you will make a mistake.-->
View the effect:
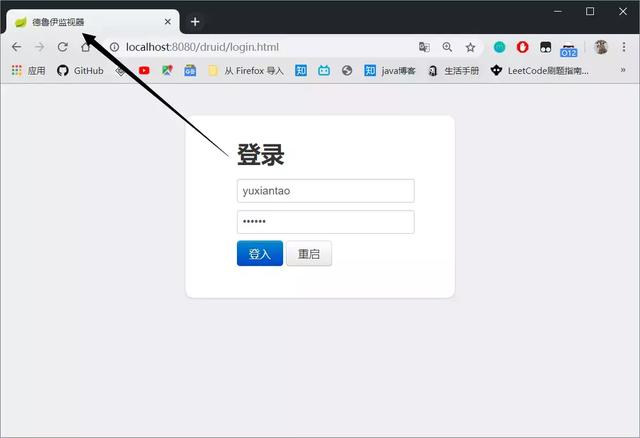
Using SpringBook to Build Tables
Then two SQL files are introduced under resources/sql:
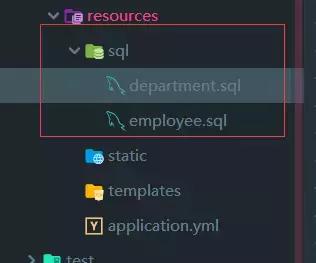
department.sql:
SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for department -- ---------------------------- DROP TABLE IF EXISTS `department`; CREATE TABLE `department` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `departmentName` VARCHAR(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
employee.sql:
SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for employee -- ---------------------------- DROP TABLE IF EXISTS `employee`; CREATE TABLE `employee` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `lastName` VARCHAR(255) DEFAULT NULL, `email` VARCHAR(255) DEFAULT NULL, `gender` INT(2) DEFAULT NULL, `d_id` INT(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
And write in the application.yml file:
schema: - classpath:sql/department.sql - classpath:sql/employee.sql initialization-mode: always
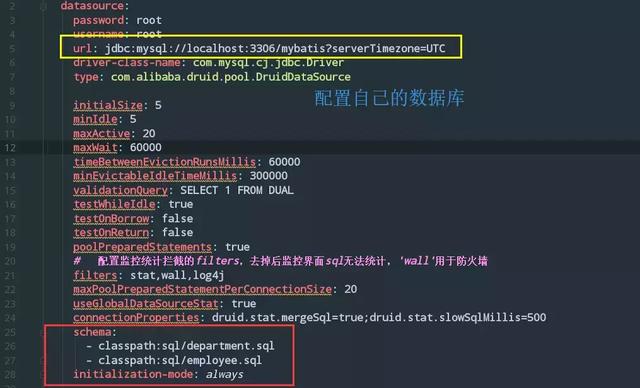
schema `is the same level as password/username and so on. Oh, yes, if you are above springboot 2.x, you may need to add the initialization-mode attribute.
Run the main class to see if the table was built successfully.
If your program starts up after setting up sql file, it will report an error:
Restart idea.
Check if the schema is configured with the correct sql file name
schema:
- (blank) classpath:sql/xxx.sql
Attention format
Corresponding database entity class
Employee.java
package com.carson.domain;
public class Employee {
private Integer id;
private String lastName;
private Integer gender;
private String email;
private Integer dId;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public Integer getGender() {
return gender;
}
public void setGender(Integer gender) {
this.gender = gender;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Integer getdId() {
return dId;
}
public void setdId(Integer dId) {
this.dId = dId;
}
}Department.java
package com.carson.domain;
public class Department {
private Integer id;
private String departmentName;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getDepartmentName() {
return departmentName;
}
public void setDepartmentName(String departmentName) {
this.departmentName = departmentName;
}
}Remember to comment out all the schema attributes of my configuration file just now. We don't want to create tables again when we run it next time.
Database Interaction
- Annotated Edition
Create a Mapper and write sql statements directly on it
package com.carson.mapper;
import com.carson.domain.Department;
import org.apache.ibatis.annotations.*;
//Specify that this is a mapper
@Mapper
public interface DepartmentMapper {
@Select("select * from department where id=#{id}")
public Department getDepById(Integer id);
@Delete("delete from department where id=#{id}")
public int deleteDepById(Integer id);
@Insert("insert into department(departmentName) values(#{departmentName})")
public int insertDept(Department department);
@Update("update department set departmentName=#{departmentName} where id=#{id}")
public int updateDept(Department department);
}Then write a Controller:
package com.carson.controller;
import com.carson.domain.Department;
import com.carson.mapper.DepartmentMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController //controller for returning json data
public class DeptController {
@Autowired
DepartmentMapper departmentMapper;
@GetMapping("/dept/{id}")
public Department getDept(@PathVariable("id") Integer id) {
return departmentMapper.getDepById(id);
}
@GetMapping
public Department inserDept(Department department) {
departmentMapper.insertDept(department);
return department;
}
}By @PathVariable, placeholder parameters in URLs can be bound to the input parameters of controller processing methods: The {xxx} placeholder in URLs can be bound to the input parameters of operation methods through @PathVariable("xxx").
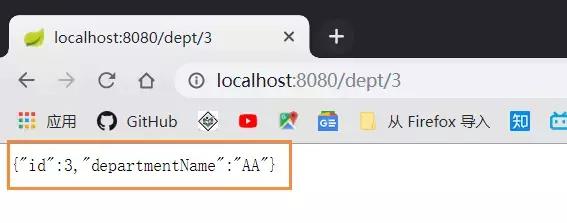
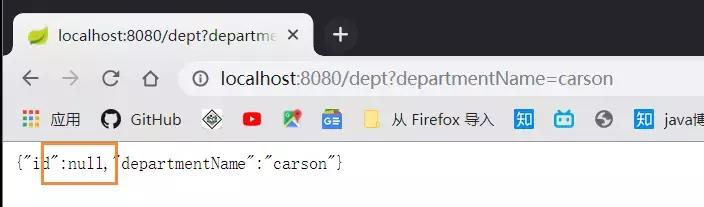
Start the main class and enter this: localhost:8080/dept?departmentName=AA, which adds a data to the database:

Then query: localhost:8080/dept/3, my database id is 3, so I want to query 3:
However, a problem was found that the id could not be obtained when inserting data:
So let's use an @Options annotation:
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into department(departmentName) values(#{departmentName})")
public int insertDept(Department department);Add to insert's @value annotation in mapper just now
useGeneratedKeys: Use the generated primary key
keyProperty: Which attribute in Department is the primary key, which is our id
Try inserting a data:
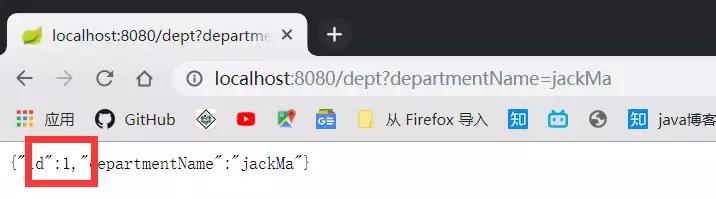
But actually forgot to comment out the schema, resulting in each run will re-create the database, you should pay attention to
There is another problem.
We change the field name of the database to department_name and the entity class is department Name.
And correct sql statement
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into department(department_name) values(#{departmentName})")
public int insertDept(Department department);
@Update("update department set department_name=#{departmentName} where id=#{id}")
public int updateDept(Department department);Then, in the case of query operation:
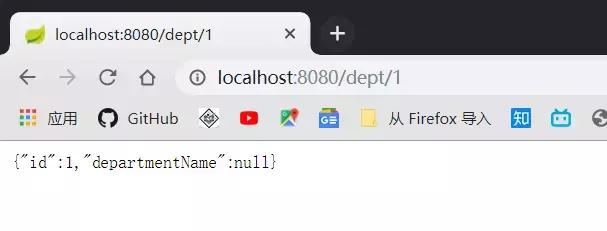
We found that we couldn't get departmentName. Spring used to use configuration files to deal with this situation, but now we don't have xml files. What should we do?
Nothing is difficult in the world.
Create a custom configuration class:
package com.carson.config;
import org.mybatis.spring.boot.autoconfigure.ConfigurationCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MyBatisConfig {
@Bean
public ConfigurationCustomizer configurationCustomizer() {
return new ConfigurationCustomizer() {
@Override
public void customize(org.apache.ibatis.session.Configuration configuration) {
configuration.setMapUnderscoreToCamelCase(true);
}
};
}
}Notice the setMap UnderscoreToCamelCase here, which means:

Good translation, my English is too poor, visit http://localhost:8080/dept/1 query operation again, I found that it is no longer null:
{"id":1,"departmentName":"jackMa"}The horse always shows up correctly!
MapperScan annotations
Scanner, used to scan mapper interface
I tag it on the startup class (you can tag it anywhere):
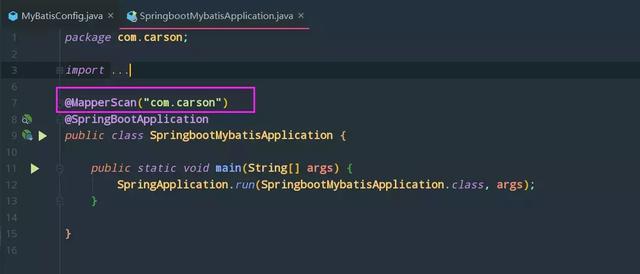
Specify a package that scans all mapper interfaces under the package, prevents you from having too many mapper files, and forgets to add the @mapper annotation, which improves correctness.
- Configuration file version
Annotations seem convenient, but if you encounter complex sql, such as dynamic SQL and so on, you still need to use xml configuration files.
Create an Employee Mapper interface:
package com.carson.mapper;
import com.carson.domain.Employee;
public interface EmployeeMapper {
public Employee getEmpById(Integer id);
public void insertEmp(Employee employee);
}Create a mybatis-config.xml global configuration file under resources/mybatis:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> </configuration>
Create the EmployeeMapper.xml mapping file under the resources/mybatis/mapper package:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- Binding interface And write two SQL Sentence-->
<mapper namespace="com.carson.mapper.EmployeeMapper">
<select id="getEmpById" resultType="com.carson.domain.Employee">
select * from employee where id = #{id}
</select>
<insert id="insertEmp">
insert into employee(lastName,email,gender,d_id) values (#{lastName}, #{email},#{gender},#{d_id})
</insert>
</mapper>Then add a configuration under the application.yml configuration file:
#mybatis attributes are on the same level as spring attributes. Don't get the format wrong mybatis: #Specify global configuration files config-location: classpath:mybatis/mybatis-config.xml #Specify the mapper mapping file,* on behalf of all mapper-locations: classpath:mybatis/mapper/*.xml
Let's add a section of Controller to the DeptController class just now.
@Autowired
EmployeeMapper employeeMapper
@GetMapping("emp/{id}")
public Employee getEmp(@PathVariable("id") Integer id) {
return employeeMapper.getEmpById(id);
}Start the main class and visit localhost:8080/emp/1 to see the results:
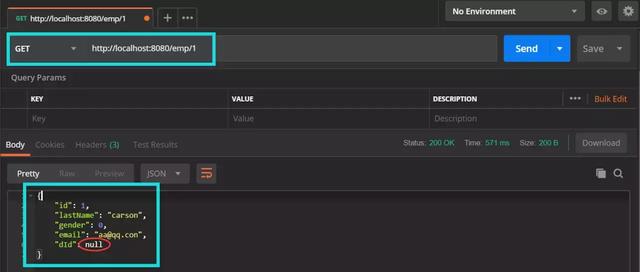
We find that dId is not queried because the database field is d_id and dId is in java. So we need to configure something like the annotated version just now. Let's open the mapper global configuration file and add:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings> </configuration>
mapUnderscoreToCamelCase: Whether to turn on the automatic camel case mapping, which is a similar mapping from the classical database column name A_COLUMN to the classical Java attribute name aColumn.
Test again:
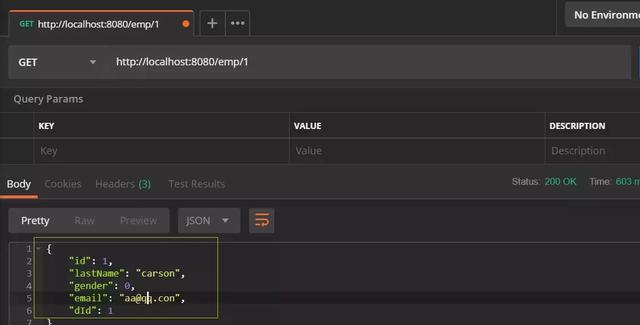
You can see that it has been successful.
Regardless of the version, it should be decided according to the actual situation. Although annotations are convenient, complex business is not possible.