Recently, the task is relatively light, and I have free time to learn learning technology, so I come to study how to realize the separation of reading and writing. Here we use blog to record the process. On the one hand, it can be viewed in the future, and on the other hand, it can also be shared with you (most of the information on the Internet is really copied and copied, without format, it's really hard to see).
Full code: https://github.com/FleyX/demo-project/tree/master/dxfl
1. Background
. When the number of users increases gradually and the single machine database cannot meet the performance requirements, the read-write separation transformation (applicable to read more and write less) will be carried out. One database will be written and read more than one database. Usually, a database cluster will be made to enable master-slave backup and one master-slave to improve the read-write performance. When more read-write separations of users are not satisfied, distributed databases are needed (you may learn how to deal with them later).
Under normal circumstances, the implementation of read-write separation requires a database cluster with one master and many slaves, and data synchronization. This article records how to use mysql to build a primary and multiple configurations, and the next one records how to realize the separation of reading and writing at the code level.
2. Building a master-slave database cluster
. Refer to this for modification method: Click to jump.
-
Main database configuration
A new user is created in the master database to read the binary log of the master database from the slave database. The sql statement is as follows:
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY '123456';#Create user mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';#Assign permissions mysql>flush privileges; #Refresh permissionsAt the same time, modify mysql configuration file to open binary log. The new part is as follows:
[mysqld] server-id=1 log-bin=master-bin log-bin-index=master-bin.indexThen restart the database and use the show master status; statement to view the master database status, as shown below:

-
Configuration from library
Also add a few lines of configuration first:
[mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-binThen restart the database and connect to the main database with the following statement:
CHANGE MASTER TO MASTER_HOST='192.168.226.5', MASTER_USER='root', MASTER_PASSWORD='123456', MASTER_LOG_FILE='master-bin.000003', MASTER_LOG_POS=154;Then run start slave; start the backup. The normal situation is as follows: Slave_IO_Running and Slave_SQL_Running is yes.
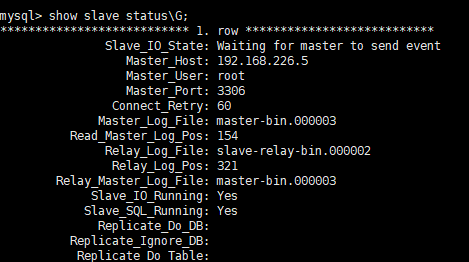
You can use this step to open multiple slave libraries.
by default, all operations of the master database will be backed up to the slave database. In fact, some databases may need to be ignored. The following configurations can be added to the master database:
# Which databases are not synchronized binlog-ignore-db = mysql binlog-ignore-db = test binlog-ignore-db = information_schema # Only which databases are synchronized, in addition, others are not synchronized binlog-do-db = game
3. Code level separation of reading and writing
The code environment is the springboot+mybatis+druib connection pool. To separate read and write, you need to configure multiple data sources. In the write operation, you need to select the write data source, and in the read operation, you need to select the read data source. There are two key points:
- How to switch data sources
- How to choose the right data source according to different methods
1) How to switch data sources
. Therefore, our goal is very clear. Create multiple datasources and put them into the TargetDataSource. At the same time, override the terminecurrentlookupkey method to decide which key to use.
2) How to select a data source
Generally, transactions are annotated in the service layer. Therefore, when you start the service method call, you need to determine the data source. What common method can operate before you start executing a method? I'm sure you've already thought of that as "face-to-face". There are two ways to do this:
- Annotation type, which defines a read-only annotation. The method annotated by the data uses the read library
- Method name: write the pointcut according to the method name. For example, getXXX uses the read library, setXXX uses the write library
3) , coding
a. Write configuration file and configure two data source information
only required information, others have default settings
mysql: datasource: #Number of readers num: 1 type-aliases-package: com.example.dxfl.dao mapper-locations: classpath:/mapper/*.xml config-location: classpath:/mybatis-config.xml write: url: jdbc:mysql://192.168.226.5:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true username: root password: 123456 driver-class-name: com.mysql.jdbc.Driver read: url: jdbc:mysql://192.168.226.6:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true username: root password: 123456 driver-class-name: com.mysql.jdbc.Driver
b. Write DbContextHolder class
. The code is as follows:
/** * Description Switch read / write mode here * The principle is to use ThreadLocal to save whether the current thread is in read mode (by starting READ_ONLY annotation sets the mode to read mode before operation, * Clear the data after the operation to avoid memory leakage. At the same time, in order to write to the thread in the future, read mode is still used * @author fxb * @date 2018-08-31 */ public class DbContextHolder { private static Logger log = LoggerFactory.getLogger(DbContextHolder.class); public static final String WRITE = "write"; public static final String READ = "read"; private static ThreadLocal<String> contextHolder= new ThreadLocal<>(); public static void setDbType(String dbType) { if (dbType == null) { log.error("dbType Empty"); throw new NullPointerException(); } log.info("set up dbType Is:{}",dbType); contextHolder.set(dbType); } public static String getDbType() { return contextHolder.get() == null ? WRITE : contextHolder.get(); } public static void clearDbType() { contextHolder.remove(); } }
c. Override the determinecurrent lookupkey method
spring will use this method to decide which database to use when it starts database operation, so we call the getDbType() method of the DbContextHolder class above to get the current operation category, and at the same time, we can perform load balancing of the read database. The code is as follows:
public class MyAbstractRoutingDataSource extends AbstractRoutingDataSource { @Value("${mysql.datasource.num}") private int num; private final Logger log = LoggerFactory.getLogger(this.getClass()); @Override protected Object determineCurrentLookupKey() { String typeKey = DbContextHolder.getDbType(); if (typeKey == DbContextHolder.WRITE) { log.info("Write library used"); return typeKey; } //Use random numbers to decide which reader to use int sum = NumberUtil.getRandom(1, num); log.info("Read library used{}", sum); return DbContextHolder.READ + sum; } }
d. Write configuration class
. First, generate the data source. Use @ ConfigurProperties to automatically generate the data source:
/** * Write data source * * @Primary Flag if the Bean is candidate for multiple similar beans, the Bean will be considered first. * When configuring multiple data sources, note that there must be a Primary data source, and use @ Primary to mark the Bean */ @Primary @Bean @ConfigurationProperties(prefix = "mysql.datasource.write") public DataSource writeDataSource() { return new DruidDataSource(); }
Similar to read data sources, note that as many read databases as there are, you need to set as many read data sources, and the Bean name is read + sequence number.
then set the data source, using the MyAbstractRoutingDataSource class we wrote earlier
/** * Set the data source route, and determine which data source to use through the determineCurrentLookupKey in this class */ @Bean public AbstractRoutingDataSource routingDataSource() { MyAbstractRoutingDataSource proxy = new MyAbstractRoutingDataSource(); Map<Object, Object> targetDataSources = new HashMap<>(2); targetDataSources.put(DbContextHolder.WRITE, writeDataSource()); targetDataSources.put(DbContextHolder.READ+"1", read1()); proxy.setDefaultTargetDataSource(writeDataSource()); proxy.setTargetDataSources(targetDataSources); return proxy; }
Next, you need to set sqlSessionFactory
/** * Multiple data sources need to set sqlSessionFactory by themselves */ @Bean public SqlSessionFactory sqlSessionFactory() throws Exception { SqlSessionFactoryBean bean = new SqlSessionFactoryBean(); bean.setDataSource(routingDataSource()); ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(); // Location of entity class bean.setTypeAliasesPackage(typeAliasesPackage); // XML configuration of mybatis bean.setMapperLocations(resolver.getResources(mapperLocation)); bean.setConfigLocation(resolver.getResource(configLocation)); return bean.getObject(); }
/** * Set the transaction. The transaction needs to know which data source is currently used for transaction processing */ @Bean public DataSourceTransactionManager dataSourceTransactionManager() { return new DataSourceTransactionManager(routingDataSource()); }
4) , select data source
? Here are two ways:
a. Annotative
.
@Target({ElementType.METHOD,ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) public @interface ReadOnly { }
@Aspect @Component public class ReadOnlyInterceptor implements Ordered { private static final Logger log= LoggerFactory.getLogger(ReadOnlyInterceptor.class); @Around("@annotation(readOnly)") public Object setRead(ProceedingJoinPoint joinPoint,ReadOnly readOnly) throws Throwable{ try{ DbContextHolder.setDbType(DbContextHolder.READ); return joinPoint.proceed(); }finally { //Be clear about DbType. On the one hand, in order to avoid memory leakage, it is more important to avoid the impact on subsequent operations performed on this thread DbContextHolder.clearDbType(); log.info("eliminate threadLocal"); } } @Override public int getOrder() { return 0; } }
b. Method name
this method can't be annotated, but it needs to write the method name in service according to certain rules, and then set the database category by faceting. For example, setXXX is set to write, getXXX is set to read, so I won't write the code, and I should know how to write it.
4. Testing

The separation of reading and writing is just a temporary solution to database expansion, and it can't be done once and for all. As the load increases further, it's certainly not enough to have only one database for writing, and there is a upper limit for a single table database, and mysql can maintain good query performance with a maximum of ten million levels of data. In the end, it will become a sub database and sub table architecture. See this section for the sub database and sub table: https://www.tapme.top/blog/detail/2019-03-20-10-38
This article was originally published in:www.tapme.top/blog/detail/2018-09-10-10-38