Welcome to pay attention to personal Wechat Public Number: Xiaoha learns Java, pushes dry articles in the Java field every day, and pays attention to free and no routine with 100G mass learning and interview resources yo!!
Personal website: https://www.exception.site/springboot/spring-boot2-kafka
What is Kafka?
Kafka is an Apache Foundation open source distributed publish-subscribe message middleware, stream processing platform. It originated from LinkedIn and was written in Scala and Java. It became the Apache project in 2011 and the top-level project under the Apache Foundation in 2012.
Kafka is designed for distributed high throughput systems. Compared with other message middleware, such as RabbitMq, Kafka has better throughput, built-in partitioning, replication and intrinsic fault tolerance, making it very suitable for large data applications. In addition, Kafka supports offline and online consumption of news.
Why use Kafka
- Low latency - Kafka supports low latency messaging, which is extremely fast and achieves 200 W write/sec.
- High Performance - Kafka has high throughput for publishing and subscribing messages. Even if TB-level messages are stored, stable performance can still be guaranteed.
- Reliability - Kafka is distributed, partitioned, replicated and fault-tolerant, guaranteeing zero downtime and zero data loss.
- Extensibility - Kafka supports cluster level expansion.
- Durability - Kafka uses "distributed submission logs" where messages can be quickly persisted on disk.

Kafka Environmental Installation
Next, Xiaoha will show you how to use the simplest single-machine installation method in Linux system, because this article focuses on Spring Boot 2.x fast integration Kafka.
Download Kafka
Visit Kafka's official website http://kafka.apache.org/downloads Download the tgz package. The demo version here is the latest version 2.3.0.
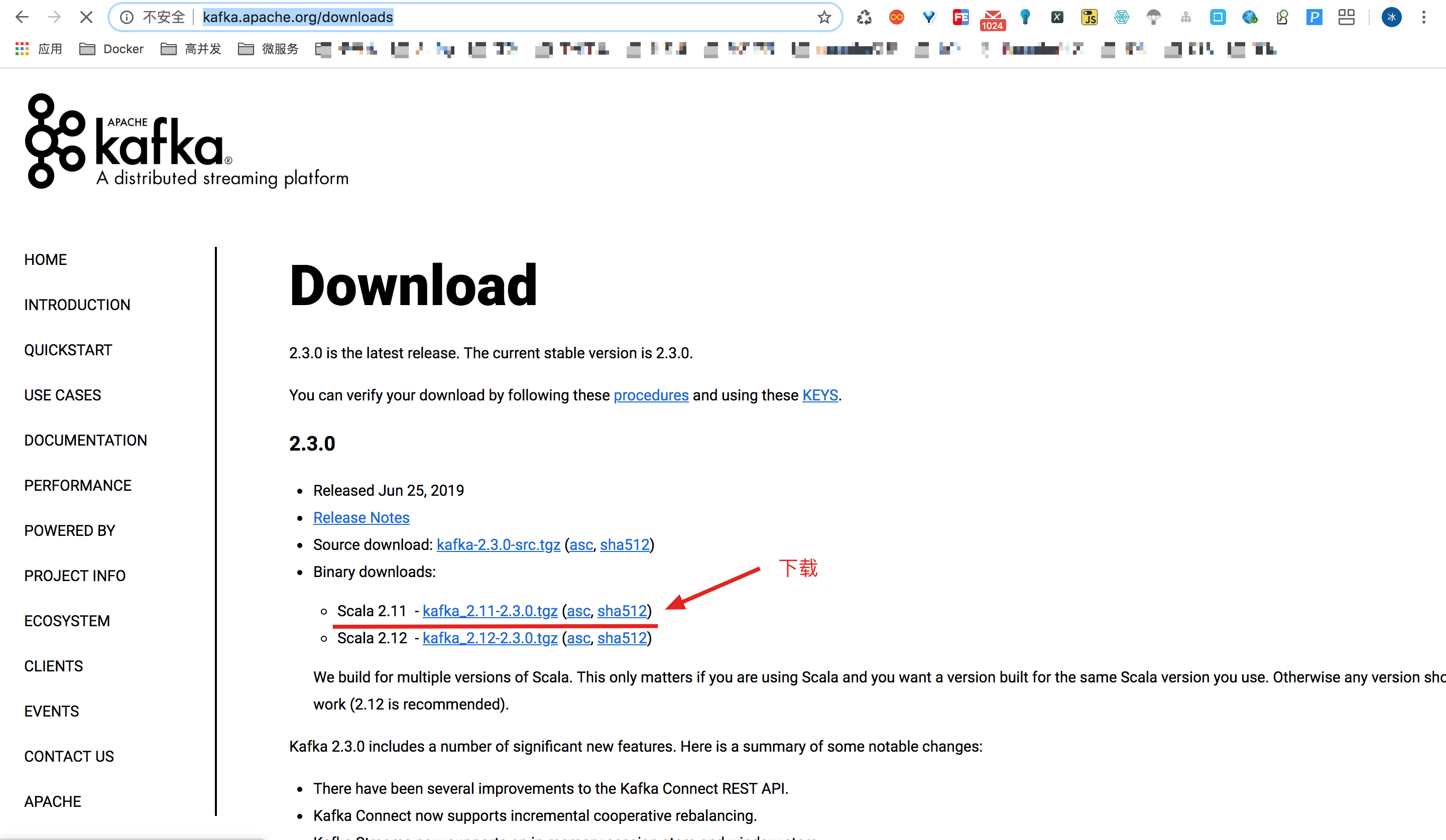
Unzip and enter the directory
After downloading, place it in the specified location and execute the command to decompress:
tar -zxvf kafka_2.11-2.3.0.tgz
After decompression, enter the Kafka directory:
cd kafka_2.11-2.3.0
Start zookeeper
Start zk single node instance by zookeeper-server-start.sh startup script under bin directory:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
Start Kafka
Start with kafka-server-start.sh under bin directory:
bin/kafka-server-start.sh config/server.properties
Note: Kafka defaults to port 9092, pay attention to closing the firewall, Aliyun server, remember to add security group.
Spring Boot 2.x began to integrate
Create a new Spring Boot 2.x Web project.
Project structure
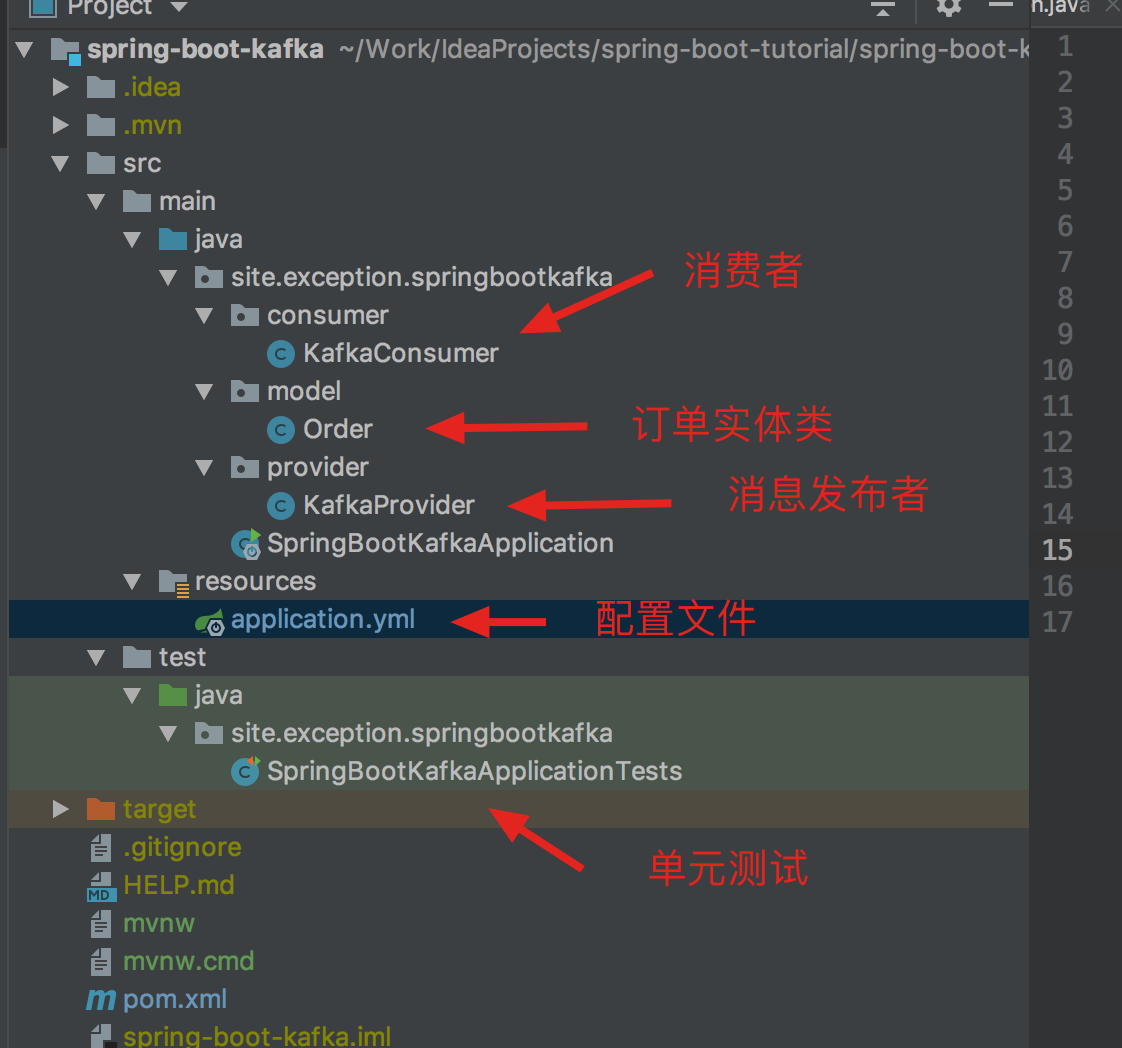
Adding maven dependencies
Xiao Ha's complete maven dependence here is as follows:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>site.exception</groupId> <artifactId>spring-boot-kafka</artifactId> <version>0.0.1-SNAPSHOT</version> <name>spring-boot-kafka</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- Kafka --> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka-test</artifactId> <scope>test</scope> </dependency> <!-- lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <!-- Alibaba fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.58</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
Add kafka configuration
Modify the application.yml file and add kafka configuration:
spring: kafka: # Specify kafka address, I am here, directly on the local host, if the external network address, pay attention to modify [PS: you can specify more] bootstrap-servers: localhost:9092 consumer: # Specify group_id group-id: group_id auto-offset-reset: earliest # Specify the encoding and decoding method of message key and message body key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer producer: # Specify the encoding and decoding method of message key and message body key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
On auto-offset-reset
The auto.offset.reset configuration has three values that can be set as follows:
- earliest: when there is a submitted offset under each partition, start to consume from the submitted offset; when there is no submitted offset, start to consume from the beginning;
- latest: when there is a submitted offset under each partition, consumption starts from the submitted offset; when there is no submitted offset, consumption of the newly generated data under that partition;
- None: When a submitted offset exists in each topic partition, it will be consumed after offset; as long as there is no submitted offset in one partition, an exception will be thrown.
The default recommendation is earliest. After setting this parameter, kafka reboots after an error and finds the unconsumed offset to continue to consume.
The latest settings are easy to lose messages. If there are problems with kafka and data are written to top, restart kafka at this time. This settings will start to consume from the latest offset, regardless of the problems in the middle.
The none settings are unused, incompatibility is too poor, and problems often arise.
Add an Order Class
In the analog business system, the user sends a message for the consumption of other services for each order:
/** * @author Dog Ha (Public No. Xiao Ha Learns Java) * @date 2019/4/12 * @time 3:05 p.m. * @discription Order Entity Class **/ @Data @Builder @AllArgsConstructor @NoArgsConstructor public class Order { /** * Order id */ private long orderId; /** * Order number */ private String orderNum; /** * Order creation time */ private LocalDateTime createTime; }
Add a message publisher
Create a new KafkaProvider message provider class with the following source code:
/** * @author Dog Ha (Public No. Xiao Ha Learns Java) * @date 2019/4/12 * @time 3:05 p.m. * @discription informant **/ @Component @Slf4j public class KafkaProvider { /** * Message TOPIC */ private static final String TOPIC = "xiaoha"; @Autowired private KafkaTemplate<String, String> kafkaTemplate; public void sendMessage(long orderId, String orderNum, LocalDateTime createTime) { // Build an order class Order order = Order.builder() .orderId(orderId) .orderNum(orderNum) .createTime(createTime) .build(); // Send a message, json of the order class as the body of the message ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(TOPIC, JSONObject.toJSONString(order)); // Monitoring callback future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() { @Override public void onFailure(Throwable throwable) { log.info("## Send message fail ..."); } @Override public void onSuccess(SendResult<String, String> result) { log.info("## Send message success ..."); } }); } }
Add a message consumer
When the message is sent out, of course, a consumer is needed. After the consumer gets the message, he does the related business processing. Here, Xiaoha just prints the message body.
Add the Kafka Consumer consumer class:
/** * @author Dog Ha (Public No. Xiao Ha Learns Java) * @date 2019/4/12 * @time 3:05 p.m. * @discription News consumers **/ @Component @Slf4j public class KafkaConsumer { @KafkaListener(topics = "xiaoha", groupId = "group_id") public void consume(String message) { log.info("## consume message: {}", message); } }
With the @KafkaListener annotation, we can specify topics and groupId that need to be monitored. Note that topics here are an array, which means that we can specify multiple topics, such as @KafkaListener(topics = {"xiaoha", "xiaoha2"}, groupId = "group_id").
Note: The message publisher's TOPIC needs to be consistent with the TOPIC monitored by the consumer. If not, the message can not be consumed.
unit testing
New unit tests, release of functional test messages, and consumption.
/** * @author Dog Ha (Public No. Xiao Ha Learns Java) * @date 2019/4/12 * @time 3:05 p.m. * @discription **/ @RunWith(SpringRunner.class) @SpringBootTest public class SpringBootKafkaApplicationTests { @Autowired private KafkaProvider kafkaProvider; @Test public void sendMessage() throws InterruptedException { // Send 1000 messages for (int i = 0; i < 1000; i++) { long orderId = i+1; String orderNum = UUID.randomUUID().toString(); kafkaProvider.sendMessage(orderId, orderNum, LocalDateTime.now()); } TimeUnit.MINUTES.sleep(1); } }
Send 1000 messages to see if they can be released and consumed properly. The console log is as follows:
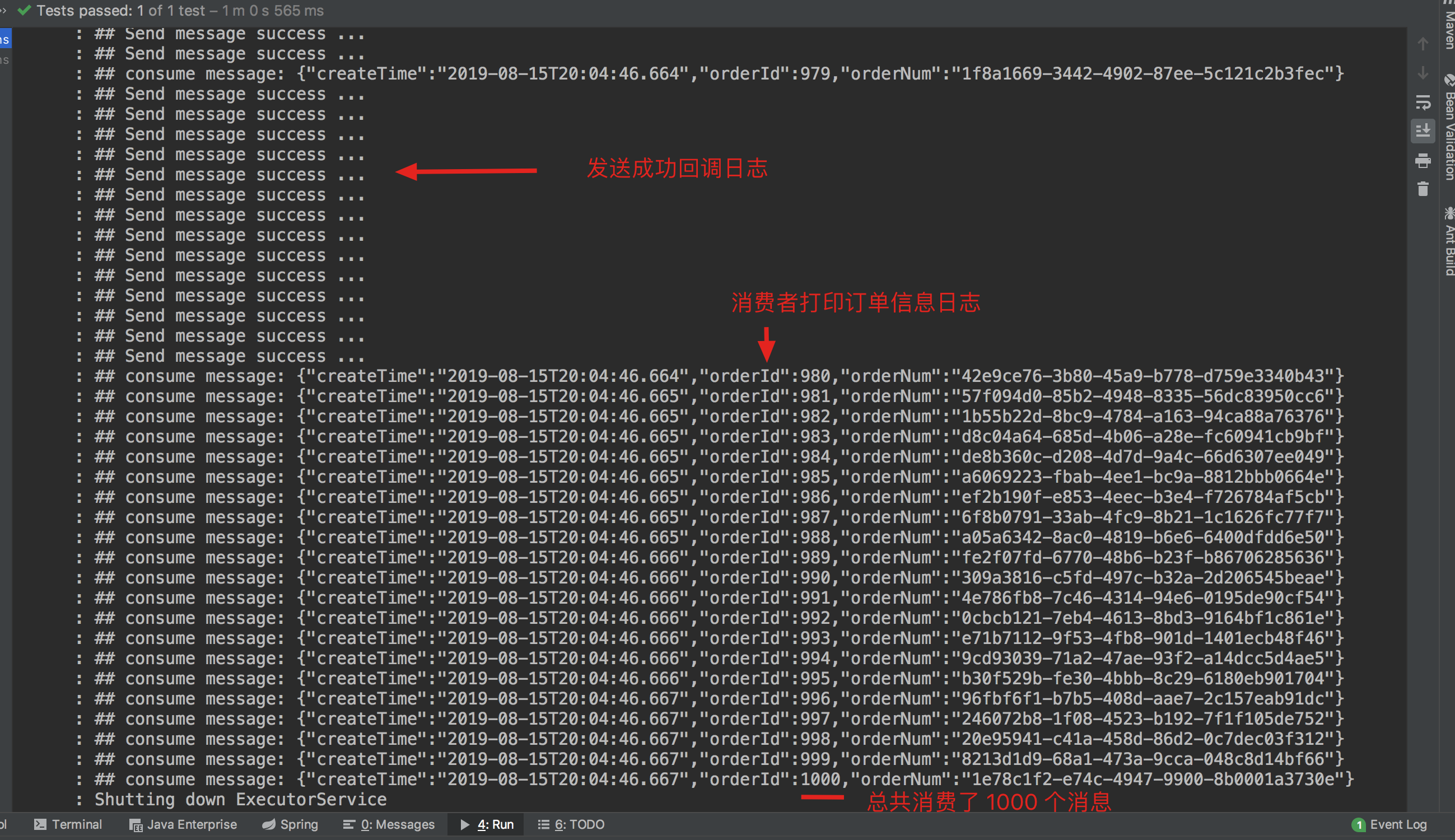
It can be found that 1000 messages were sent successfully and consumed normally.
Let's verify Kafka's topic list again, see if xiaoha's topic is created properly, and execute the kafka-topics.sh script that looks at the topic list under bin directory:
bin/kafka-topics.sh --list --zookeeper localhost:2181

All right, great success!
summary
Xiaoha shared with you today, how to install a stand-alone version of Kafka environment, how to quickly integrate message middleware Kafka in Spring Boot 2.x, and demonstrated the relevant sample code to publish messages and consumer messages. I hope you can get some results after reading it. See you next time!
GitHub source address
https://github.com/weiwosuoai/spring-boot-tutorial/tree/master/spring-boot-kafka
Reference material
https://zh.wikipedia.org/wiki/Kafka
https://www.w3cschool.cn/apache_kafka/
https://juejin.im/post/5d406a925188255d352ab24e
https://www.jianshu.com/p/e1df7d18bb8f
Free Sharing | Interview & Learning Welfare Resources
Recently found a good PDF resource on the Internet, "Java Core Knowledge & Interview. pdf" to share with you, not only the interview, learning, you are worth having!!!
Access: Pay attention to the public number: Xiaoha learns Java, and replies to resources in the background. You can get resource links free of charge and without routines. Here is the catalogue and some screenshots.





Say the important thing twice, pay attention to the public number: Xiaoha learns Java, and replies to the resources in the background. You can get the resources links free of charge and without routines!!!
Welcome to the Wechat Public Number: Xiaoha Learns Java
