This paper mainly shares the splitting, extracting and merging of text data to prepare for the next visual analysis.
The data comes from the employment information of boss and dragnet data analysis positions, totaling 9458.
The crawling methods of the pull-hook are as follows: Python selenium+beautifulsoup login crawl hook
Environment Configuration
# Jupyter Notebook %matplotlib inline import pandas as pd import warnings warnings.filterwarnings('ignore')
The original data is as follows:
[job_link] and [company_link] do not need, delete
The use of jieba and wordcloud by [company_describe] and [job_skills] is not covered in this article.If you are interested in word clouds, please see my blog: Python jieba+wordcloud Making Ci Cloud
This paper mainly shows how to handle the two columns, [experience] and [city]. The other columns are much the same but not repeated.
Data preparation
bs=pd.read_csv('boss.csv',encoding='gbk') lg=pd.read_csv('lagou.csv',encoding='gbk') #Merge data to see if missing values exist all_data=pd.concat([bs,lg],ignore_index=True) all_data.info() #Delete unwanted information del all_data['job_link'] del all_data['company_link'] #Filling in missing values all_data['company_describe']=all_data['company_describe'].fillna('Not yet')
Processing of experience columns

The text in this column is a mixture of experience and academic qualifications.But if you look only at the first few columns, it's easy to ignore some of the outliers.
If you look only at the first few columns, you will miss some anomalous data.Using [all_data.tail()] observation, we found that some data is [salary + experience + academic qualifications], which requires us to divide it into [experience + academic qualifications] and unify the data form of this column.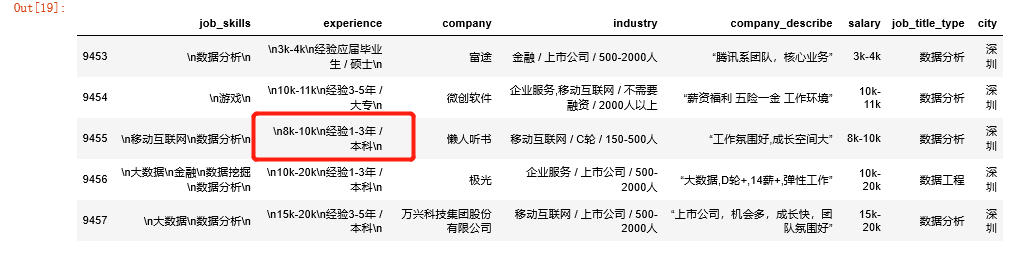
Use of split
Using split in pandas requires first converting the split's dataset into a string.The first parameter [a] in split (a, b) represents a string as a split point, and the second parameter [b] represents the number of times to split, i.e., into [b+1] elements.A list is returned when the split is complete.Extracting elements from a list must be converted again to strings.
#Create a new column of "e1" to fit the cut text in the form of "experience + education" all_data['e1']=all_data.experience.str.split("k",2).str[2]
Taken apart, with the string'k'as the split point, the data is divided into two categories: a list of only one element K without salary, and a list of three elements with salary.Select the third element of all the lists in this column, and only one element of the list will appear as NaN in the [e1], while the other will capture the information we want.
There are many NaN s in the [e1] column extracted at this time: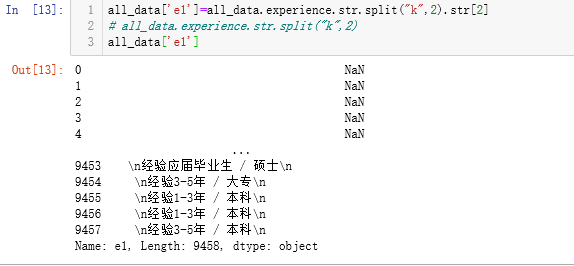
Filna Fill Data
The NaN data of e1 column is populated with the experience column data, which ultimately unifies the entire column data into experience + academic qualifications.
all_data['e1']=all_data['e1'].fillna(all_data.experience) all_data.tail(10)
The processed e1 looks like this: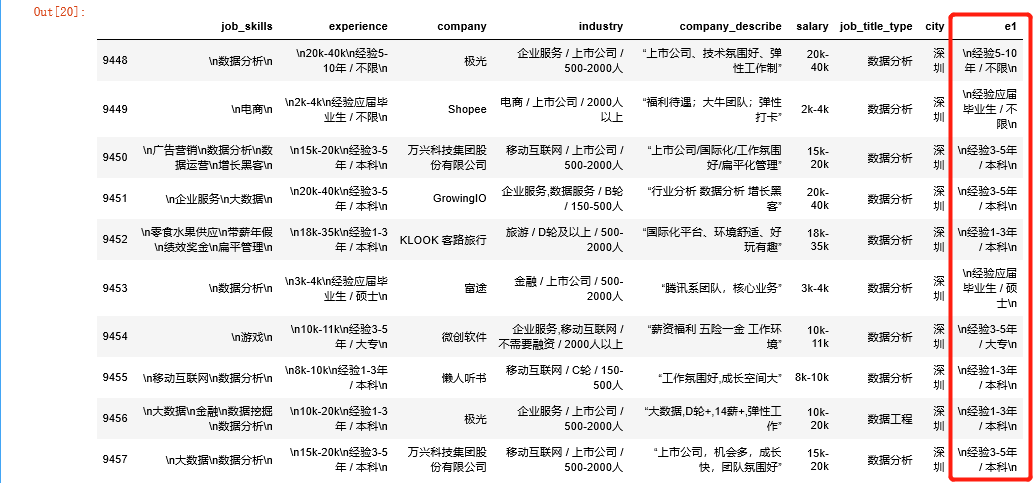
extract + regular expression
When text data comes in this form of mixing letters and numbers, we need to use str.extract+regular expressions to extract it.The parameter [expand=Fales] returns the dataframe data, which if True is the data frame.
Regular expressions in extract need to be enclosed in quotes
#Regular match, match [begins with a number and ends with a number] all_data['job_experience']=all_data['e1'].str.extract(('.*?(\d.*\d)'),expand=False)

findall Multi-condition Matching
The above processing results indicate that NaN still exists because of the experience of [graduates], [unlimited], [less than one year].
The most intuitive difference between findall and extract is that findall matches multiple times, all eligible elements return a group, while extract only matches once and returns a number directly; findall can match multiple conditions, but extract cannot.
For example, in the same example above, the function is replaced by extract(), which gives you a list, as shown in the following figure.
findall's multiple criteria match, the criteria are enclosed in double quotes, and the criteria are separated by'|'. Multiple elements will appear if the match succeeds multiple times.
all_data['e1'].str.findall('through|Unlimited|1 year|Current')

Of course, we don't need to.
all_data['job_experience1']=all_data['e1'].str.findall('Unlimited|1 year|Current').str[0]

Same as fillna above
all_data['job_experience']=all_data['job_experience'].fillna(all_data.job_experience1) all_data.job_experience.value_counts()

Replace with loc[] (1)
From the tag above, the expression is not complete enough, we use loc[] to replace the content.
df.loc[df ['column name to be replaced'] =='content to be replaced','under which column name to be replaced'] ='content to be replaced'
all_data.loc[all_data['job_experience']=='1 year','job_experience']='1 Under year' all_data.loc[all_data['job_experience']=='Current','job_experience']='1 Under year' all_data.loc[all_data['job_experience']=='3-5','job_experience']='3-5 year' all_data.loc[all_data['job_experience']=='1-3','job_experience']='1-3 year' all_data.loc[all_data['job_experience']=='5-10','job_experience']='5-10 year' all_data.loc[all_data['job_experience']=='10','job_experience']='10 Years or more' all_data.job_experience.value_counts()

Substitution is certainly not limited to the original column, and the analysis of the urban part will be taken as an example later.
Delete filtered data
It can be seen that there is strange data mixed in, temporary or part-time jobs should be deleted.
#Delete text with'/'in job_experience column all_data=all_data.drop(all_data[all_data['job_experience'].str.contains('/')].index)
This code has three layers, meaning from inside to outside:
Select the column [job_experience] in all_data that contains the data [/].
All_data[]. index is the index to get the required data;
Delete data using all_data.drop()
Finally, separate academic qualifications
degree='Junior College|Undergraduate|master|doctor' all_data['degree']=(all_data['e1'].str.findall(degree).str[0]) all_data['degree']=all_data['degree'].fillna('Unlimited') del all_data['e1'] del all_data['experience'] del all_data['job_experience1']

Processing of city columns
Take a look first:
Interchange between contains and loc[] (2)
The city I selected is only north-wide and deep, with a lot of data and needs to be replaced.
You need to convert the data to a string before using contains.Contains returns a Boolean value with True data containing the string you are looking for.This method can be very complex and simplified, locking in special symbols in some columns, such as the deletion method used above.One method of substitution using LOC [] has been discussed previously, and this shows another method of substitution using contains() and loc.
all_data.location.str.contains('Beijing')
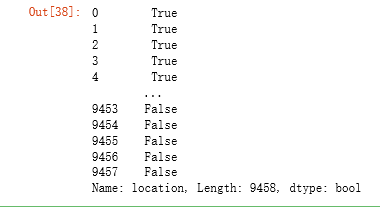
all_data['bj']=all_data.location.str.contains('Beijing') all_data['sh']=all_data.location.str.contains('Shanghai') all_data['gz']=all_data.location.str.contains('Guangzhou') all_data['sz']=all_data.location.str.contains('Shenzhen') all_data.loc[all_data['bj']==True,'city']='Beijing' all_data.loc[all_data['sh']==True,'city']='Shanghai' all_data.loc[all_data['gz']==True,'city']='Guangzhou' all_data.loc[all_data['sz']==True,'city']='Shenzhen' #Delete redundant data del all_data['bj'] del all_data['sh'] del all_data['sz'] del all_data['gz'] del all_data['location']
You can see that loc [here] selects the data from the [bj] column, but replaces it with the [city] column.
finish

