SparkStreaming reads the Kafka data source and writes it to the Mysql database
1, Experimental environment
The tools used in this experiment are
kafka_2.11-0.11.0.2;
zookeeper-3.4.5;
spark-2.4.8;
Idea;
MySQL5.7
What is zookeeper?
Zookeeper mainly serves distributed services, which can be used for unified configuration management, unified naming service, distributed lock and cluster management. Using distributed system can not avoid the problems of node management (real-time perception of node status, unified management of docking points, etc.), and because these problems are relatively troublesome and improve the complexity of the system, zookeeper, as a middleware that can solve these problems, came into being.
What is Kafka?
In short, Kafka is a distributed message queue system developed by Linkedin. It is not only a message queue system, but also a real-time stream processing application and saving stream data. The main goal of Kafka development is to build a data processing framework to deal with massive logs, user behavior and website operation statistics. Combined with the requirements of data mining, behavior analysis and operation monitoring, it is necessary to meet the requirements of low latency and batch throughput performance in various real-time online and batch offline processing applications. Fundamentally speaking, high throughput is the first requirement, followed by real-time and persistence.
kafka and zookeeper:
A typical Kafka cluster includes several products, several brokers (generally, the greater the number of brokers, the higher the cluster throughput), several Consumer groups, and a zookeeper cluster. Kafka manages cluster configuration through zookeeper, elects leader s, and rebalance when the Consumer Group changes. Produce r publishes messages to broker using push mode, and Consumer subscribes to and consumes messages from broker using pull mode. Kafka depends on zookeeper.
2, Preparatory work
On the virtual machine: after configuring the corresponding environment, start zookeeper and then Kafka.
On Windows: add kafka dependency in pom.xml file of maven project of idea:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>2.4.8</version>
</dependency>
3, Train of thought analysis
1. Server side: start Kafka when zookeeper is started, and start the producer of Kafka as the data source for generating data.
2. Client: write SparkStreaming program on idea as a consumer to consume the data generated by Kafka in real time and process the data, that is, word frequency statistics.
3. Store the result data of the client into the MySQL database.
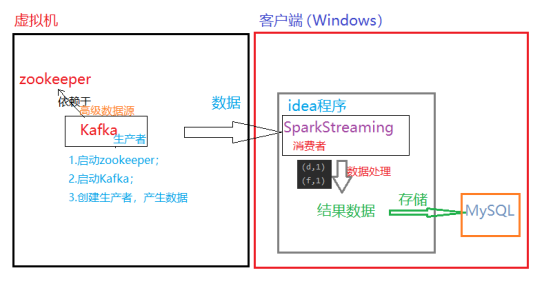
4, Code implementation
1. Test
1.1 write consumer programs on idea:
package scala.sparkstreaming
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
object KafkaDemo {
def main(args:Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("KafkaDemo").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "zyx:9092",//The host name is zyx
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("test", "t100")//The topic name is test
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value))
val resultRDD: DStream[(String, Int)] = mapDStream.flatMap(_._2.split(" ")).map((_, 1)).reduceByKey(_ + _)
//Print
resultRDD.print()
//start-up
streamingContext.start()
//Wait for the end of the calculation
streamingContext.awaitTermination()
}
}
1.2 create Kafka producer: / training / Kafka_ 2.11-0.11.0.2/bin/kafka-console-producer.sh -- broker list zyx: 9092 -- topic test

Additional:
Here, you can also create Kafka consumers at another terminal: / training/kafka_2.11-0.11.0.2/bin/kafka-console-consumer.sh --bootstrap-server zyx:9092 --topic test --from-beginning
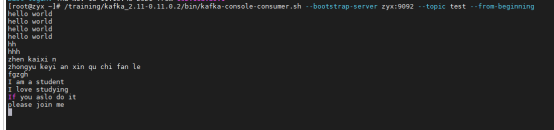
1.3 operation procedure;
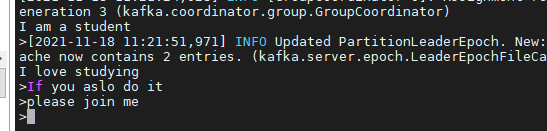
1.4 input data:
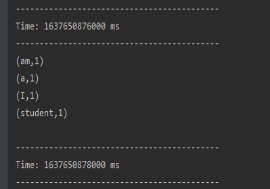
1.5 viewing operation results:
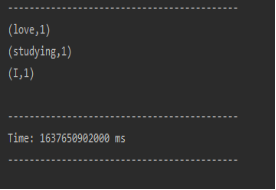
2. Write the result data to MySQL database:
2.1 add the code of data writing to the database on the basis of the previous program, as follows:
package scala.sparkstreaming
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
object KafkaDemo {
def main(args:Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("KafkaDemo").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "zyx:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("test", "t100")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value))
val resultRDD: DStream[(String, Int)] = mapDStream.flatMap(_._2.split(" ")).map((_, 1)).reduceByKey(_ + _)
//Print
resultRDD.print()
//Save DStream to MySQL database
resultRDD.foreachRDD(rdd => {
def func(records: Iterator[(String,Int)]) {
var conn: Connection = null
var stmt: PreparedStatement = null
try {
//Defines how MySQL is linked and its user name and password
val url = "jdbc:mysql://Localhost: 3306 / Lianxi? Useunicode = true & characterencoding = UTF-8 "/ / the database is Lianxi
val user = "root"
val password = "123456"
conn = DriverManager.getConnection(url, user, password)
records.foreach(p => {
val sql = "insert into zklog(information,count) values (?,?)"//In the zklog table in the Lianxi database, there are two columns: information and count
stmt = conn.prepareStatement(sql);
stmt.setString(1, p._1.trim)
stmt.setInt(2,p._2.toInt)
stmt.executeUpdate()
})
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (stmt != null) {
stmt.close()
}
if (conn != null) {
conn.close()
}
}
}
val repartitionedRDD = rdd.repartition(3)
repartitionedRDD.foreachPartition(func)
})
//start-up
streamingContext.start()
//Wait for the end of the calculation
streamingContext.awaitTermination()
}
}
2.2 run the idea program and input data at the server (if the producer is gone, it needs to be recreated. If the creation fails, Kafka may hang up and restart):

2.3 viewing data in MySQL table:
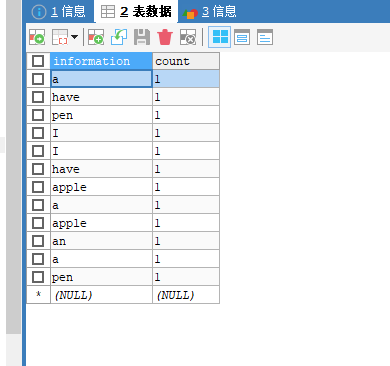
Reference blog:
https://blog.csdn.net/sujiangming/article/details/121391972?spm=1001.2014.3001.5501
Stand alone installation of zookeeper
Installation and basic operation of Kafka