Spark SQL (DataFrame) is introduced in websites and some books to generate final running statements based on the corresponding operations. This article starts with a simple, low-level problem and ends with a look at the generated code to find the root cause of the problem and a brief introduction to how to debug SparkSQL.
Sources of the problem:
1 2 3 4 5 6 7 8 9 |
|
After running, compute always reports NullPointerException exceptions. The operation of RDD and Scala is incomprehensible. How can it become Access(null,null,null)? Although df. flatMap (Access (). map (. compute) is working properly, I still want to see what SparkSQL has done!!!
What did SparkSQL do?
Spark RDD clearly defines the operation in RDD compute. SparkSQL's operations were eventually converted into a Logical Plan, and it was impossible to see what it did.
In fact, SparkSQL has an explaining method to view program execution plans, similar to the explaining method of database SQL. (The code is all posted here, and you can remove the comments yourself according to the situation.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
Running the above code, the task execution plan is output in the console window:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
OK, when you see the execution plan, what does the generated code look like? And how to debug the generated code?
Hack source code
Before debugging, change the code to recompile catalyst for debugging and replace spark-catalyst_2.11 under maven:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
SparkSQL generates code using janino. Official documents provide debugging information: http://janino-compiler.github.io/janino/#debugging . Simply explain the following three modifications:
- Look at the org.codehaus.janino.Scanner constructor, and if debugging and optionalFileName==null are configured, the source code is saved to a temporary file.
- I didn't expect to annotate setClassName at first. Then I copied CodeGenerator doCompile slowly to the example provided by the official website. I changed setClassName to setExtendedClass and turned it into a pop-up source page. See the setExtendedClass below and comment out the setClassName.
- What the parameters in the source code can't be viewed is that this option is removed at compile time. Set debugVars to true.
Operation and debugging
Prepare for commissioning first:
- Interrupt a breakpoint in the compute method and debug it.
- Modify log4j log level: log4j.logger.org.apache.spark.sql.catalyst.expressions.codegen=DEBUG
- Import the project into eclipse (IDEA does not pop up the source code)
Then run. Click Generated Iterator in the Debug view, click the Find Source button in the pop-up code view, and then the Edit Source Lookup Path to add the path target/generated-sources (note that absolute paths are used here)! Next, step by step.
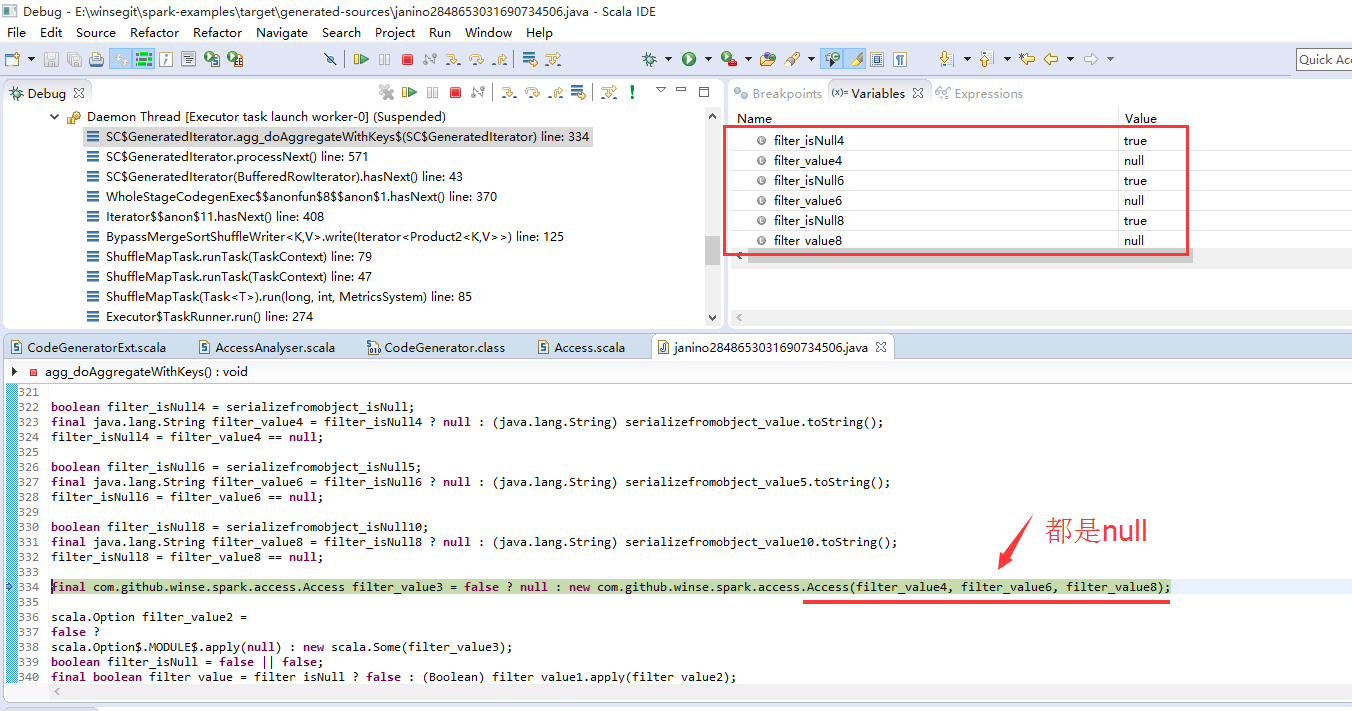
Debugging the generated code can better understand the execution plan of the previous explain. Seeing the code makes it easy to understand the original Access(null,null,null): the problem of object-to-field deserialization.
from:http://www.winseliu.com/blog/2016/10/12/sparksql-view-and-debug-generatecode/