1. Description
- Reader: Beginner Spark
- Development environment: IDEA + spark2.4.8+jdk1.8.0_301
- Computer Configuration:
- 4 Core 8 Thread
- View CPU methods:
In Windows, type "wmic" in the cmd command, then enter "cpu get Name", "cpu get NumberOfCores", "cpu get NumberOfLogicalProcessors" in the new window that appears to see the number of physical CPUs, CPU cores, threads.
As shown in the following figure:
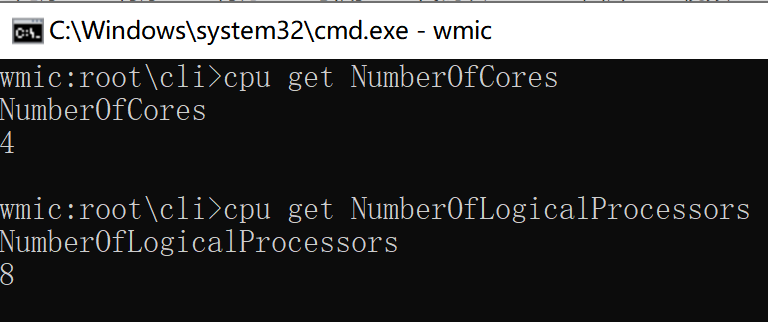
Name: Represents the number of physical CPU s
NumberOfCores: Represents the number of CPU cores
NumberOfLogicalProcessors: Represents the number of CPU threads
Note: The number of cores selected by the CPU in the VM virtual machine actually represents the number of threads.
2. RDD Partition
As we all know, RDD has five features, the first of which is that RDD consists of a group of partitions. Another feature is that there is a default partitioner for data of type Key-Value and no partitioner for type Value. Therefore, we conclude as follows:
- Partitioners are not required for RDD s that only store value s.
- Partitioners are required only if the Key-Value type is stored.
Spark currently supports Hash and Range partitions, and users can customize partitions. Hash partitions are the current default partitions, and partitioners in Spark directly determine the number of partitions in RDD, which partition and Reduce each piece of data in RDD belongs to through the Shuffle process.
3. View the partitioner for RDD
- Partitioner for value RDD
scala> val rdd1 = sc.parallelize(Array(10)) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:25 scala> rdd1.partitioner res8: Option[org.apache.spark.Partitioner] = None
- Partitioner for key-value RDD
scala> val rdd1 = sc.parallelize(Array(("hello", 1), ("world", 1))) rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[3] at parallelize at <console>:25 scala> rdd1.partitioner res11: Option[org.apache.spark.Partitioner] = None
IV. HashPartitioner
The principle of HashPartitioner partitioning: For a given key, its hashCode is calculated and divided by the number of partitions. If the remainder is less than 0, then the number of partitions is added with the remainder (otherwise, 0). The last value returned is the partition ID to which the key belongs.

- Execute in spark-shell:
scala> import org.apache.spark.HashPartitioner scala> val rdd1 = sc.parallelize(Array(("order",1),("order",2),("name","Zhang San"),("name","Li Si"),("order",3),("name","King Five"), | ("order",4),("name","Zhao Six"),("order",5),("name","Ma Chao"),("order",7),("name","Li Kui"),("order",8),("name","Song River"), | ("order",3),("name","Wusong"))) rdd1: org.apache.spark.rdd.RDD[(String, Any)] = ParallelCollectionRDD[11] at parallelize at <console>:25 scala> val rdd2 = rdd1.partitionBy(new HashPartitioner(8)) rdd2: org.apache.spark.rdd.RDD[(String, Any)] = ShuffledRDD[12] at partitionBy at <console>:26 scala> rdd2.partitioner res8: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@8) - Coding implementation in IDEA:
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object PartitionDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) val rdd1 = sc.parallelize(Array((10, "a"), (20, "b"), (30, "c"), (40, "d"), (50, "e"), (60, "f"))) // Take out the partition number and check the partition of the element val rdd2: RDD[(Int, String)] = rdd1.mapPartitionsWithIndex((index, it) => it.map(x => (index, x._1 + " : " + x._2))) println(rdd2.collect.mkString(",")) // Repartition RDD1 using HashPartitioner val rdd3 = rdd1.partitionBy(new HashPartitioner(5)) // Detect partitioning of RDD3 val rdd4: RDD[(Int, String)] = rdd3.mapPartitionsWithIndex((index, it) => it.map(x => (index, x._1 + " : " + x._2))) println(rdd4.collect.mkString(",")) } } - View the results:

5. RangePartitioner
HashPartitioner partitioning drawbacks: It can lead to uneven data volumes in each partition, and in extreme cases, some partitions will have all the data in the RDD. For example, our previous example is an extreme where they all entered partition 0.
RangePartitioner Role: Map numbers in a certain range to a certain partition, try to ensure that the amount of data in each partition is uniform, and there is order between partitions. Elements in one partition must be smaller or larger than those in another partition, but elements in a partition cannot guarantee order. Simply put, map numbers in a certain range to a certain pointArea. The implementation process is:
The first step is to extract the sample data from the whole RDD, sort the sample data, calculate the maximum key value for each partition, and form an Array[KEY] type array variable rangeBounds; (boundary array).
Step 2: Decide where the key is in the range Bounds and give the partition id subscript for the key value in the next RDD; the partitioner requires that the KEY type in the RDD be sortable.
For example, [1,100,200,300,400], and then compare the incoming key to return the corresponding partition id.
- Coding test in IDEA:
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) val rdd1 = sc.parallelize(Array((10, "a"), (20, "b"), (30, "c"), (40, "d"), (50, "e"), (60, "f"))) // Take out the partition number and check the partition of the element val rdd2: RDD[(Int, String)] = rdd1.mapPartitionsWithIndex((index, it) => it.map(x => (index, x._1 + " : " + x._2))) println(rdd2.collect.mkString(",")) // Repartition RDD1 using RangePartitioner val rdd3 = rdd1.partitionBy(new RangePartitioner(5,rdd1)) // Detect partitioning of RDD3 val rdd4: RDD[(Int, String)] = rdd3.mapPartitionsWithIndex((index, it) => it.map(x => (index, x._1 + " : " + x._2))) println(rdd4.collect.mkString(",")) } - View the results:
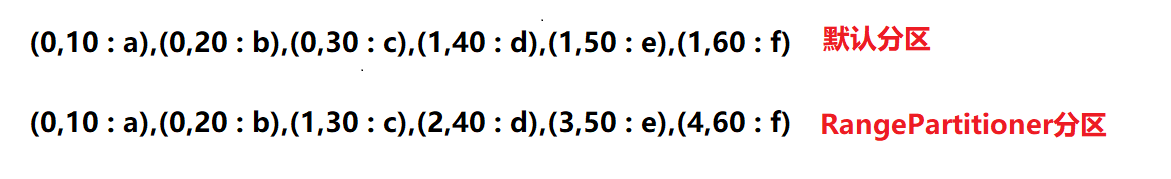
Note: There are five partitions where the data falls in separate partitions
4. RDD Custom Partition Case
To implement a custom partitioner, you need to inherit org.apache.spark.Partitioner and implement the following methods:
1.numPartitions
This method needs to return the number of partitions, which must be greater than 0.
2.getPartition(key)
Returns the partition number (0 to numPartitions-1) of the specified key.
3.equals
Java's standard method of identifying equality. Implementing this method is important and Spark needs to use it to check that your partitioner objects are identical to other partitioner instances so that Spark can determine if two RDD s are partitioned in the same way
4.hashCode
If you override equals, you should also override this method.
- Encoding Implementation [MyPartitioner]
import org.apache.spark.rdd.RDD import org.apache.spark.{Partitioner, SparkConf, SparkContext} /* It is easy to use a custom artitioner: simply pass it to the partitionBy() method. Spark There are many methods that rely on data mixing, such as join() and groupByKey(), They can also receive an optional Artitioner object to control how the output data is partitioned. */ object MyPartitionerDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[*]") val sc = new SparkContext(conf) val rdd1 = sc.parallelize( Array((10, "a"), (20, "b"), (30, "c"), (40, "d"), (50, "e"), (60, "f")), 3) val rdd2: RDD[(Int, String)] = rdd1.partitionBy(new MyPartitioner(4)) val rdd3: RDD[(Int, String)] = rdd2.mapPartitionsWithIndex((index, items) => items.map(x => (index, x._1 + " : " + x._2))) println(rdd3.collect.mkString(" ")) } } class MyPartitioner(numPars: Int) extends Partitioner{ override def numPartitions: Int = numPars override def getPartition(key: Any): Int = key match { case 10 => 1 case 20 => 2 case _ => 3 } } - View results
(1,10 : a) (2,20 : b) (3,30 : c) (3,40 : d) (3,50 : e) (3,60 : f)