Article directory
Transformation operator
All transformations in RDD are late loaded, that is, they do not directly evaluate the results. Instead, they just remember the transformation actions that apply to the underlying dataset, such as a file. These transformations actually work only when an action occurs that requires the result to be returned to the Driver. This design makes Spark run more efficiently.
| Transformation | Meaning |
|---|---|
| map(func) | Returns a new RDD, which is composed of each input element after func function conversion |
| filter(func) | Filtration. Returns a new RDD, which is composed of input elements with a return value of true after func function calculation |
| flatMap(func) | Flatten. Similar to map, but each input element can be mapped to 0 or more output elements (so func should return a sequence instead of a single element) |
| mapPartitions(func) | Similar to map, but running independently on each partition of RDD, so when running on RDD of type T, the function type of func must be iterator [t] = > iterator [u]. Operate on each partition in RDD |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but func takes an integer parameter to represent the index value of fragmentation, so when running on RDD of type T, the function type of func must be (int, interator [t]) = > iterator [u]. Operate on each partition in RDD, with subscript, and get partition number. |
| sample(withReplacement, fraction, seed) | Samples the data according to the scale specified by fraction. You can choose whether to replace it with random number. Seed is used to specify the seed of random number generator |
| union(otherDataset) | Set operation. Returns a new RDD after the union of the source RDD and the parameter RDD |
| intersection(otherDataset) | Set operation. Returns a new RDD after intersection of the source RDD and the parameter RDD |
| distinct([numTasks]) | Set operation. After the source RDD is de duplicated, a new RDD is returned |
| groupByKey([numTasks]) | Group operation. Called on an (K,V) RDD, returns an (K, Iterator[V]) RDD. Partial bottom |
| reduceByKey(func, [numTasks]) | Group operation. Call on a (K,V) RDD to return a (K,V) RDD. Use the specified reduce function to aggregate the values of the same key. Similar to groupByKey, the number of reduce tasks can be set by the second optional parameter. Call groupByKey. |
| aggregateByKey(zeroValue)(seqOp,combOp,[numTasks]) | Group operation. Call groupByKey, often used. |
| sortByKey([ascending], [numTasks]) | Sort. When called on an (K,V) RDD, K must implement the Ordered interface and return an (K,V) RDD sorted by key |
| sortBy(func,[ascending], [numTasks]) | Sort. Similar to sortByKey, but more flexible |
| join(otherDataset, [numTasks]) | Called on RDD of types (K,V) and (K,W), returns the RDD of (K,(V,W)) with all elements corresponding to the same key |
| cogroup(otherDataset, [numTasks]) | Called on RDD of types (K,V) and (K,W), returns an RDD of type (K,(Iterable,Iterable)) |
| cartesian(otherDataset) | Cartesian product |
| pipe(command, [envVars]) | |
| coalesce(numPartitions) | |
| repartition(numPartitions) | Re zoning |
| repartitionAndSortWithinPartitions(partitioner) | Re zoning |
Basic operator
1. map(func)
Returns a new RDD, which is composed of each input element after func function conversion
// Create an RDD numeric type scala> val rdd1 = sc.parallelize(List(5,6,7,8,9,1,2,3,100)) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:24 scala> rdd1.partitions.length res1: Int = 2 // Requirement: multiply each element by 2 scala> val rdd2 = rdd1.map(_*2) rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at map at <console>:26 scala> rdd2.collect res2: Array[Int] = Array(10, 12, 14, 16, 18, 2, 4, 6, 200)
2. filter(func)
Filtration. Returns a new RDD, which is composed of input elements with a return value of true after func function calculation
// Requirement: filter out elements greater than 20 scala> val rdd3 = rdd2.filter(_>20) rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[17] at filter at <console>:28 scala> rdd3.collect res5: Array[Int] = Array(200)
3. flatMap
Flatten. Similar to map, but each input element can be mapped to 0 or more output elements (so func should return a sequence instead of a single element)
// Create RDD with string (characters) scala> val rdd4 = sc.parallelize(Array("a b c","d e f","x y z")) rdd4: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[18] at parallelize at <console>:24 scala> val rdd5 = rdd4.flatMap(_.split(" ")) rdd5: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[19] at flatMap at <console>:26 scala> rdd5.collect res6: Array[String] = Array(a, b, c, d, e, f, x, y, z)
4. Set operation (union, intersection, distinct)
- union(otherDataset) - returns a new RDD after union of source RDD and parameter RDD
- intersection(otherDataset) - returns a new RDD after intersection of source RDD and parameter RDD
- distinct([numTasks]) - a new RDD is returned after the source RDD is de duplicated
// Set operation, de duplication (requires two RDD S) scala> val rdd6 = sc.parallelize(List(5,6,7,8,1,2,3,100)) rdd6: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[20] at parallelize at <console>:24 scala> val rdd7 = sc.parallelize(List(1,2,3,4)) rdd7: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[21] at parallelize at <console>:24 scala> val rdd8 = rdd6.union(rdd7) rdd8: org.apache.spark.rdd.RDD[Int] = UnionRDD[22] at union at <console>:28 scala> rdd8.collect res7: Array[Int] = Array(5, 6, 7, 8, 1, 2, 3, 100, 1, 2, 3, 4) scala> rdd8.distinct.collect res8: Array[Int] = Array(100, 4, 8, 1, 5, 6, 2, 7, 3) scala> val rdd9 = rdd6.intersection(rdd7) rdd9: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[31] at intersection at <console>:28 scala> rdd9.collect res9: Array[Int] = Array(2, 1, 3)
5. Grouping (groupByKey, reduceByKey, cogroup)
- groupByKey([numTasks]) - called on a (K,V) RDD and returns a (K, Iterator[V]) RDD. Partial bottom
- reduceByKey(func, [numTasks]) - call on a (K,V) RDD, return a (K,V) RDD, use the specified reduce function, aggregate the values of the same key together, similar to groupByKey, the number of reduce tasks can be set through the second optional parameter. Call groupByKey.
- Cogroup (other dataset, [numtasks]) - called on RDD of types (K,V) and (K,W), returns an RDD of type (K,(Iterable,Iterable))
// Grouping operation: reduceByKey groupByKey scala> val rdd1 = sc.parallelize(List(("Tom",1000),("Jerry",3000),("Mery",2000))) rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[32] at parallelize at <console>:24 scala> val rdd2 = sc.parallelize(List(("Jerry",1000),("Tom",3000),("Mike",2000))) rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[33] at parallelize at <console>:24 scala> val rdd3 = rdd1 union rdd2 rdd3: org.apache.spark.rdd.RDD[(String, Int)] = UnionRDD[34] at union at <console>:28 scala> rdd3.collect res10: Array[(String, Int)] = Array((Tom,1000), (Jerry,3000), (Mery,2000), (Jerry,1000), (Tom,3000), (Mike,2000)) scala> val rdd4 = rdd3.groupByKey rdd4: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[35] at groupByKey at <console>:30 scala> rdd4.collect res11: Array[(String, Iterable[Int])] = Array( (Tom,CompactBuffer(1000, 3000)), (Jerry,CompactBuffer(3000, 1000)), (Mike,CompactBuffer(2000)), (Mery,CompactBuffer(2000))) scala> rdd3.reduceByKey(_+_).collect res12: Array[(String, Int)] = Array((Tom,4000), (Jerry,4000), (Mike,2000), (Mery,2000)) // cogroup operation scala> val rdd1 = sc.parallelize(List(("Tom",1),("Tom",2),("Jerry",3),("Kitty",2))) rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[37] at parallelize at <console>:24 scala> val rdd2 = sc.parallelize(List(("Jerry",2),("Tom",1),("Andy",2))) rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[38] at parallelize at <console>:24 scala> val rdd3 = rdd1.cogroup(rdd2) rdd3: org.apache.spark.rdd.RDD[(String, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[40] at cogroup at <console>:28 scala> rdd3.collect res13: Array[(String, (Iterable[Int], Iterable[Int]))] = Array((Tom,(CompactBuffer(1, 2),CompactBuffer(1))), (Jerry,(CompactBuffer(3),CompactBuffer(2))), (Andy,(CompactBuffer(),CompactBuffer(2))), (Kitty,(CompactBuffer(2),CompactBuffer()))) // Differences between cogroup and groupByKey: // Example 1: groupByKey([numTasks]),In one(K,V)Of RDD Call on, return a(K, Iterator[V])Of RDD. cogroup(otherDataset, [numTasks]),The type is(K,V)and(K,W)Of RDD Call on, return a(K,(Iterable<V>,Iterable<W>))Type RDD scala> val rdd0 = sc.parallelize(Array((1,1), (1,2) , (1,3) , (2,1) , (2,2) , (2,3)), 3) rdd0: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> val rdd1 = rdd0.groupByKey() rdd1: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[1] at groupByKey at <console>:25 scala> rdd1.collect res0: Array[(Int, Iterable[Int])] = Array((1,CompactBuffer(1, 2, 3)), (2,CompactBuffer(1, 2, 3))) scala> val rdd2 = rdd0.cogroup(rdd0) rdd2: org.apache.spark.rdd.RDD[(Int, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[3] at cogroup at <console>:25 scala> rdd2.collect res1: Array[(Int, (Iterable[Int], Iterable[Int]))] = Array((1,(CompactBuffer(1, 2, 3),CompactBuffer(1, 2, 3))), (2,(CompactBuffer(1, 2, 3),CompactBuffer(1, 2, 3)))) // Example 2: scala> b.collect res3: Array[(Int, String)] = Array((1,b), (2,b), (1,b), (3,b)) scala> c.collect res4: Array[(Int, String)] = Array((1,c), (2,c), (1,c), (3,c)) scala> b.cogroup(c).collect res2: Array[(Int, (Iterable[String], Iterable[String]))] = Array((1,(CompactBuffer(b, b),CompactBuffer(c, c))), (3,(CompactBuffer(b),CompactBuffer(c))), (2,(CompactBuffer(b),CompactBuffer(c)))) scala> var rdd4=b union c rdd4: org.apache.spark.rdd.RDD[(Int, String)] = UnionRDD[9] at union at <console>:27 scala> rdd4.collect res6: Array[(Int, String)] = Array((1,b), (2,b), (1,b), (3,b), (1,c), (2,c), (1,c), (3,c)) scala> rdd4.groupByKey().collect res5: Array[(Int, Iterable[String])] = Array((2,CompactBuffer(b, c)), (1,CompactBuffer(b, b, c, c)), (3,CompactBuffer(b, c)))
6. Sorting (sortBy, sortByKey)
- sortBy(func,[ascending], [numTasks]) - similar to sortByKey, but more flexible
scala> val rdd2 = rdd1.map(_*2).sortBy(x=>x,true) rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[10] at sortBy at <console>:26 scala> rdd2.collect res3: Array[Int] = Array(2, 4, 6, 10, 12, 14, 16, 18, 200) scala> val rdd2 = rdd1.map(_*2).sortBy(x=>x,false) rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[16] at sortBy at <console>:26 scala> rdd2.collect res4: Array[Int] = Array(200, 18, 16, 14, 12, 10, 6, 4, 2)
- sortByKey([ascending], [numTasks]) - called on an (K,V) RDD. K must implement the Ordered interface and return an (K,V) RDD sorted by key
// 7. Requirement: sort by value. // Note: SortByKey is sorted by Key // Method: exchange the Key and Value positions // 1. Exchange Key Value and call SortByKey // 2. Switch back after calling scala> val rdd1 = sc.parallelize(List(("Tom",1),("Andy",2),("Jerry",4),("Mike",5))) rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[42] at parallelize at <console>:24 scala> val rdd2 = sc.parallelize(List(("Jerry",1),("Tom",2),("Mike",4),("Kitty",5))) rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[43] at parallelize at <console>:24 scala> val rdd3 = rdd1 union rdd2 rdd3: org.apache.spark.rdd.RDD[(String, Int)] = UnionRDD[44] at union at <console>:28 scala> rdd3.collect res14: Array[(String, Int)] = Array((Tom,1), (Andy,2), (Jerry,4), (Mike,5), (Jerry,1), (Tom,2), (Mike,4), (Kitty,5)) scala> val rdd4 = rdd3.reduceByKey(_+_) rdd4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[45] at reduceByKey at <console>:30 scala> rdd4.collect res15: Array[(String, Int)] = Array((Tom,3), (Jerry,5), (Andy,2), (Mike,9), (Kitty,5)) scala> val rdd5 = rdd4.map(t => (t._2,t._1)).sortByKey(false).map(t=>(t._2,t._1)) rdd5: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[50] at map at <console>:32 scala> rdd5.collect res16: Array[(String, Int)] = Array((Mike,9), (Jerry,5), (Kitty,5), (Tom,3), (Andy,2)) // Resolution execution process: // rdd4.map(t => (t._2,t._1)) --> (3,Tom), (5,Jerry), (2,Andy), (9,Mike), (5,Kitty) // .sortByKey(false) --> (9,Mike),(5,Jerry),(5,Kitty),(3,Tom),(2,Andy) // .map(t=>(t._2,t._1))--> (Mike,9), (Jerry,5), (Kitty,5), (Tom,3), (Andy,2)
Advanced operator
1. mapPartitionsWithIndex(func)
Similar to mapPartitions, but func takes an integer parameter to represent the index value of fragmentation, so when running on RDD of type T, the function type of func must be (int, interator [t]) = > iterator [u]. Operate on each partition in RDD, with subscript, and get partition number.
def mapPartitionsWithIndex[U](f: (Int, Iterator[T]) ⇒ Iterator[U])
- Operate on each partition (with subscript) in RDD, which is represented by index
- The partition number can be obtained by this operator
- Define a function to handle the partition
f receives two parameters. The first parameter represents the partition number. The second represents the elements in the partition. Iterator[U] results after processing
Give an example:
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9),3) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:24 scala> def fun1(index:Int,iter:Iterator[Int]) : Iterator[String] = { | iter.toList.map(x => "[PartId: " + index + " , value = " + x + " ]").iterator | } fun1: (index: Int, iter: Iterator[Int])Iterator[String] scala> rdd1.mapPartitionsWithIndex(fun1).collect res3: Array[String] = Array( [PartId: 0 , value = 1 ], [PartId: 0 , value = 2 ], [PartId: 0 , value = 3 ], [PartId: 1 , value = 4 ], [PartId: 1 , value = 5 ], [PartId: 1 , value = 6 ], [PartId: 2 , value = 7 ], [PartId: 2 , value = 8 ], [PartId: 2 , value = 9 ])
2. aggregate
Aggregate local data first, and then aggregate global data
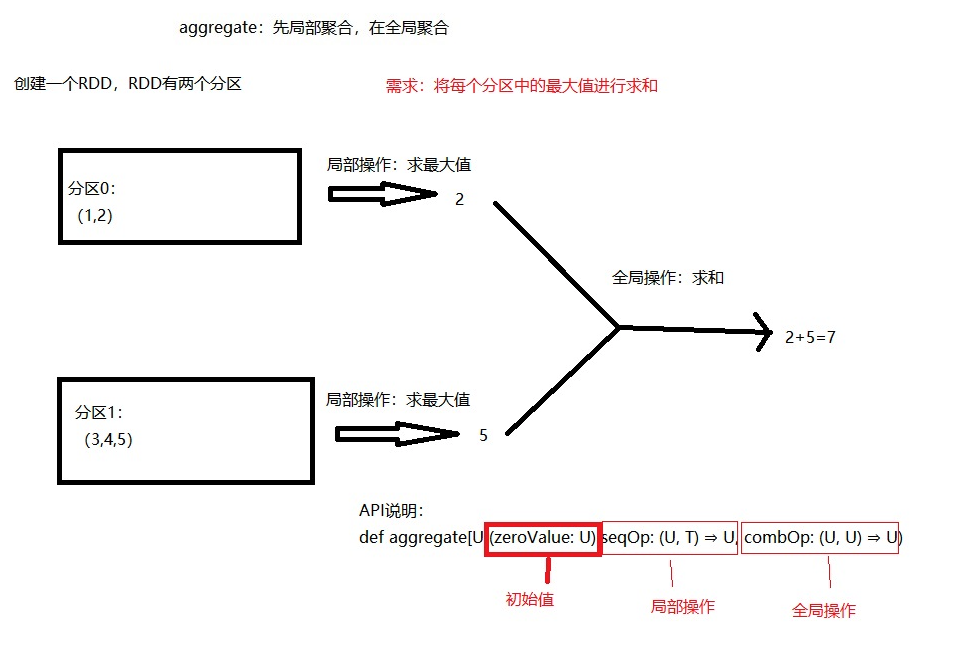
Give an example:
(1) Find the maximum value locally and then add it globally
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5),2) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> def fun1(index:Int,iter:Iterator[Int]) : Iterator[String] = { | iter.toList.map( x => "[PartId: " + index + " , value = " + x + "]").iterator | } fun1: (index: Int, iter: Iterator[Int])Iterator[String] scala> rdd1.mapPartitionsWithIndex(fun1).collect res0: Array[String] = Array([PartId: 0 , value = 1], [PartId: 0 , value = 2], [PartId: 1 , value = 3], [PartId: 1 , value = 4], [PartId: 1 , value = 5]) scala> import scala.math._ import scala.math._ // First, the local operation is maximized, and then the global operation is added 2 + 5 = 7 scala> rdd1.aggregate(0)(max(_,_),_+_) res2: Int = 7 // Modify the initial value to 10 10 + 10 + 10 = 30 scala> rdd1.aggregate(10)(max(_,_),_+_) res3: Int = 30 // Analysis results: // The initial value is 10, which means there is an additional 10 in each partition // Local operation, the maximum value of each partition is 10 // Global operation, 10 also takes effect in global operation, i.e. 10 + 10 + 10 = 30
(2) First add locally, then add globally
Sum the elements of RDD:
Mode 1: RDD.map
Mode 2: use aggregation operation
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5),2) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> def fun1(index:Int,iter:Iterator[Int]) : Iterator[String] = { | iter.toList.map( x => "[PartId: " + index + " , value = " + x + "]").iterator | } fun1: (index: Int, iter: Iterator[Int])Iterator[String] scala> rdd1.mapPartitionsWithIndex(fun1).collect res0: Array[String] = Array([PartId: 0 , value = 1], [PartId: 0 , value = 2], [PartId: 1 , value = 3], [PartId: 1 , value = 4], [PartId: 1 , value = 5]) // First add locally, then add globally 3 + 12 = 15 scala> rdd1.aggregate(0)(_+_,_+_) res5: Int = 15 // 10+(10+1+2)+(10+3+4+5) = 10+13+22 = 45 scala> rdd1.aggregate(10)(_+_,_+_) res6: Int = 45
(3) String addition
scala> val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2) rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[2] at parallelize at <console>:27 scala> def fun1(index:Int,iter:Iterator[String]) : Iterator[String] = { | iter.toList.map( x => "[PartId: " + index + " , value = " + x + "]").iterator | } fun1: (index: Int, iter: Iterator[String])Iterator[String] scala> rdd2.mapPartitionsWithIndex(fun1).collect res8: Array[String] = Array( [PartId: 0 , value = a], [PartId: 0 , value = b], [PartId: 0 , value = c], [PartId: 1 , value = d], [PartId: 1 , value = e], [PartId: 1 , value = f]) scala> rdd2.aggregate("")(_+_,_+_) res10: String = abcdef scala> rdd2.aggregate("")(_+_,_+_) res11: String = defabc // Note: who is faster and who is ahead scala> rdd2.aggregate("*")(_+_,_+_) res13: String = **def*abc scala> rdd2.aggregate("*")(_+_,_+_) res14: String = **abc*def
(4) Complex examples
scala> val rdd3 = sc.parallelize(List("12","23","345","4567"),2) rdd3: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[4] at parallelize at <console>:27 scala> rdd3.mapPartitionsWithIndex(fun1) res15: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at mapPartitionsWithIndex at <console>:32 scala> rdd3.mapPartitionsWithIndex(fun1).collect res16: Array[String] = Array( [PartId: 0 , value = 12], [PartId: 0 , value = 23], [PartId: 1 , value = 345], [PartId: 1 , value = 4567]) scala> rdd3.aggregate("")((x,y) => math.max(x.length,y.length).toString,(x,y)=>x+y) res20: String = 24 scala> rdd3.aggregate("")((x,y) => math.max(x.length,y.length).toString,(x,y)=>x+y) res21: String = 42
Analysis:
First partition:
"First comparison:" "to" "12" "for maximum len gt h: 2.". 2 —> “2”.
The second comparison: "2" and "23" ratio, find the maximum len gt h: 2. 2 —> “2”.
Second partition:
"First comparison:" "and" "345" "ratio, find the maximum len gt h: 3.". 3 —> “3”.
The second comparison: "3" and "4567" ratio, find the maximum len gt h: 4. 4 —> “4”.
scala> val rdd3 = sc.parallelize(List("12","23","345",""),2) rdd3: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[7] at parallelize at <console>:27 scala> rdd3.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>x+y) res22: String = 01 scala> rdd3.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>x+y) res23: String = 01 scala> rdd3.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>x+y) res24: String = 01 scala> rdd3.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>x+y) res25: String = 10
Analysis:
Note that there is an initial value "with a length of 0, and then 0.toString becomes the string" 0 "with a length of 1.
First partition:
"First comparison:" "to" "12" "for minimum len gt h: 0.". 0 —> “0”.
The second comparison: "0" and "23" ratio, the minimum len gt h: 1. 1 —> “1”.
Second partition:
"First comparison:" "and" "345" "ratio, minimum len gt h: 0.". 0 —> “0”.
The second comparison: "0" and "0", the minimum len gt h: 0. 0 —> “0”.
scala> val rdd3 = sc.parallelize(List("12","23","","345"),2) rdd3: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[8] at parallelize at <console>:27 scala> rdd3.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>x+y) res26: String = 11
Analysis:
First partition:
"First comparison:" "to" "12" "for minimum len gt h: 0.". 0 —> “0”.
The second comparison: "0" and "23" ratio, the minimum len gt h: 1. 1 —> “1”.
Second partition:
"First comparison:" "and" "for minimum len gt h: 0.". 0 —> “0”.
The second comparison: "0" and "345" ratio, find the minimum len gt h: 1. 1 —> “1”.
3. aggregateByKey(zeroValue)(seqOp,combOp,[numTasks])
Group operation. Call groupByKey, often used. Similar to aggregate, it operates on the data type of < key value >.
Give an example:
scala> val pairRDD = sc.parallelize(List(("cat",2),("cat",5),("mouse",4),("cat",12),("dog",12),("mouse",2)),2) pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[9] at parallelize at <console>:27 scala> def fun3(index:Int,iter:Iterator[(String,Int)]): Iterator[String] = { | iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator | } fun3: (index: Int, iter: Iterator[(String, Int)])Iterator[String] scala> pairRDD.mapPartitionsWithIndex(fun3).collect res27: Array[String] = Array( [partID:0, val: (cat,2)], [partID:0, val: (cat,5)], [partID:0, val: (mouse,4)], [partID:1, val: (cat,12)], [partID:1, val: (dog,12)], [partID:1, val: (mouse,2)]) // Sum the maximum number of animals in each zone scala> pairRDD.aggregateByKey(0)(math.max(_,_),_+_).collect res28: Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6)) // Program analysis: // 0: (cat,5)(mouse,4) // 1: (cat,12)(dog,12)(mouse,2) // (cat,17) (mouse,6) (dog,12) // Sum the number of each animal scala> pairRDD.aggregateByKey(0)(_+_, _+_).collect res71: Array[(String, Int)] = Array((dog,12), (cat,19), (mouse,6)) // This example can also be used: reduceByKey scala> pairRDD.reduceByKey(_+_).collect res73: Array[(String, Int)] = Array((dog,12), (cat,19), (mouse,6))
4. Repartition: coalesce(numPartitions) and repartition(numPartitions)
Both of these operators are related to partition, and both of them re partition RDD. The number of partitions that can be created when RDD is created.
Difference:
(1) coalesce: shuffle is not performed by default.
(2) Repartition: real shuffle of data (repartition on the network)
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9),2) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:27 scala> val rdd2 = rdd1.repartition(3) rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[16] at repartition at <console>:29 scala> rdd2.partitions.length res29: Int = 3 scala> val rdd3 = rdd1.coalesce(3) rdd3: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[17] at coalesce at <console>:29 scala> rdd3.partitions.length res30: Int = 2 scala> val rdd3 = rdd1.coalesce(3,true) rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[21] at coalesce at <console>:29 scala> rdd3.partitions.length res31: Int = 3 // The following two sentences are equivalent: val rdd2 = rdd1.repartition(3) val rdd3 = rdd1.coalesce(3,true) // -->If it is false, check that the len gt h of RDD is still 2. Default not to write is false.
5. Other advanced operators
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html

