As a framework of log real-time collection, flume can be connected with SparkStreaming real-time processing framework. Flume generates data in real-time and sparkStreaming does real-time processing.
Spark Streaming docks with FlumeNG in two ways: one is that FlumeNG pushes the message Push to Spark Streaming, the other is that Spark Streaming pulls data from Poll in flume.
6.1 Poll mode
(1) Installation of flume 1.6 or more
(2) Download dependency packages
spark-streaming-flume-sink_2.11-2.0.2.jar is placed in the lib directory of flume
(3) Modify scala dependency package version under flume/lib
Find the scala-library-2.11.8.jar package from the jars folder of the spark installation directory, and replace the scala-library-2.10.1.jar that comes with the lib directory of flume.
(4) Write the agent of flume. Note that since it is the pull mode, flume can produce data to its own machine.
(5) Write the flume-poll.conf configuration file
a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/data a1.sources.r1.fileHeader = true #channel a1.channels.c1.type =memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity=5000 #sinks a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink a1.sinks.k1.hostname=hdp-node-01 a1.sinks.k1.port = 8888 a1.sinks.k1.batchSize= 2000
Start script code
flume-ng agent -n a1 -c /opt/bigdata/flume/conf -f /opt/bigdata/flume/conf/flume-poll.conf -Dflume.root.logger=INFO,console
Prepare the data file data.txt in the / root/data directory on the server
(5) Start the spark-streaming application to pull data from the flume machine
(6) Code implementation
You need to add pom dependencies
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>2.0.2</version>
</dependency>
The code is as follows:
package cn.itcast.Flume
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
//Todo: spark Streaming integrates flume - using pull mode
object SparkStreamingPollFlume {
def main(args: Array[String]): Unit = {
//1. Create sparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingPollFlume").setMaster("local[2]")
//2. Create sparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//3. Create streaming Context
val ssc = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./flume")
//4. Call createPollingStream method through FlumeUtils to get data in flume
val pollingStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc,"192.168.200.100",8888)
//5. Get the body {"headers":xxxxxx,"body":xxxxx} of event in flume
val data: DStream[String] = pollingStream.map(x=>new String(x.event.getBody.array()))
//6. Divide each line, each word counts to 1
val wordAndOne: DStream[(String, Int)] = data.flatMap(_.split(" ")).map((_,1))
//7. The cumulative number of occurrences of the same words
val result: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc)
//8. Print Output
result.print()
//9. Open Flow Computation
ssc.start()
ssc.awaitTermination()
}
//CurrtValues: He represents all 1 (hadoop, 1) (hadoop, 1) of each word in the current batch.
//HisryValues: He represents the total number of times each word appeared in all previous batches (hadoop,100)
def updateFunc(currentValues:Seq[Int], historyValues:Option[Int]):Option[Int] = {
val newValue: Int = currentValues.sum+historyValues.getOrElse(0)
Some(newValue)
}
}
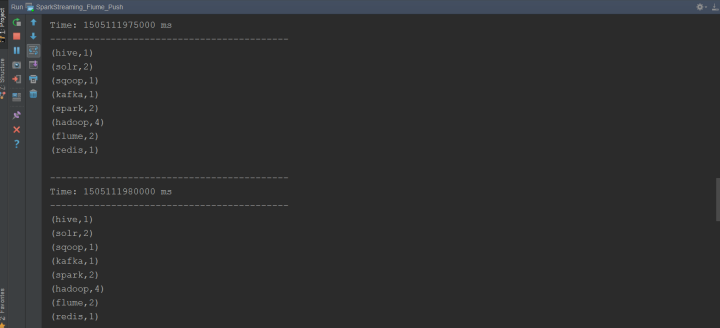
(7) Observe IDEA console output
1.2 Push mode
(1) Write flume-push.conf configuration file
#push mode a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/data a1.sources.r1.fileHeader = true #channel a1.channels.c1.type =memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity=5000 #sinks a1.sinks.k1.channel = c1 a1.sinks.k1.type = avro a1.sinks.k1.hostname=172.16.43.63 a1.sinks.k1.port = 8888 a1.sinks.k1.batchSize= 2000
Note that the hostname and port specified in the configuration file are the ip address and port of the server where the spark application is located.
flume-ng agent -n a1 -c /opt/bigdata/flume/conf -f /opt/bigdata/flume/conf/flume-push.conf -Dflume.root.logger=INFO,console
(2) The code is implemented as follows:
package cn.test.spark
import java.net.InetSocketAddress
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* sparkStreaming Integrating flume Push Mode
*/
object SparkStreaming_Flume_Push {
//New Values represent all 1 of the same words in the current batch summary (word,1)
//value summation of all the same key s in the history of runningCount
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount =runningCount.getOrElse(0)+newValues.sum
Some(newCount)
}
def main(args: Array[String]): Unit = {
//Configure sparkConf parameters
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreaming_Flume_Push").setMaster("local[2]")
//Building sparkContext objects
val sc: SparkContext = new SparkContext(sparkConf)
//Construct StreamingContext objects with intervals for each batch
val scc: StreamingContext = new StreamingContext(sc, Seconds(5))
//Setting log output level
sc.setLogLevel("WARN")
//Setting Checkpoint Directory
scc.checkpoint("./")
//flume pushes data over
// The server ip address of the current application deployment is consistent with the flume configuration file
val flumeStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createStream(scc,"172.16.43.63",8888,StorageLevel.MEMORY_AND_DISK)
//Get the data in flume, which is stored in event body and converted to String
val lineStream: DStream[String] = flumeStream.map(x=>new String(x.event.getBody.array()))
//Achieving single vocabulary aggregation
val result: DStream[(String, Int)] = lineStream.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunction)
result.print()
scc.start()
scc.awaitTermination()
}
}
}
(3) Start execution
a. Execute spark code first.
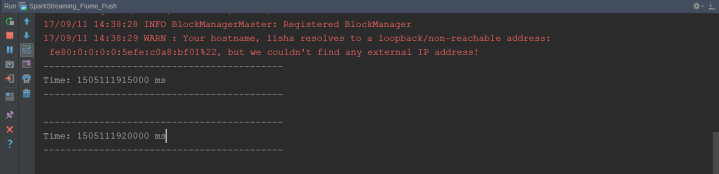
b. Then execute the flume configuration file.
First rename / root/data/ata.txt.COMPLETED to data.txt
(4) Observe IDEA console output