Pay attention to the official account: big data technology, reply to "information" and receive 1000G information. This article started on my personal blog: Spark SQL knowledge points and actual combat Spark SQL overview
1. What is Spark SQL
Spark SQL is a spark module used by spark for structured data processing.
Unlike the basic Spark RDD API, the abstract data type of Spark SQL provides Spark with more information about data structures and calculations being performed.
Internally, Spark SQL uses this additional information for additional optimization. There are many ways to interact with Spark SQL, such as SQL and dataset API.
When calculating the results, the same execution engine is used, regardless of which API or language you are using. This unification also means that developers can easily switch between different APIs, which provide the most natural way to express a given transformation.
Hive converts Hive SQL into MapReduce and then submits it to the cluster for execution, which greatly simplifies the complexity of writing MapReduce programs. Due to the slow execution efficiency of MapReduce computing model. Therefore, Spark SQL came into being. It converts Spark SQL into RDD and then submits it to the cluster for execution. The execution efficiency is very fast!
Spark SQL provides two programming abstractions, similar to RDD in Spark Core
(1)DataFrame
(2)Dataset
2. Features of Spark SQL
1) Easy integration
Seamless integration of SQL query and Spark programming
2) Unified data access
Connect different data sources in the same way
3) Compatible with Hive
Run SQL or HiveQL directly on the existing warehouse
4) Standard data connection
Connect via JDBC or ODBC
3. DataFrame for what
In Spark, DataFrame is a distributed data set based on RDD, which is similar to two-dimensional tables in traditional databases. The main difference between DataFrame and RDD is that the former has schema meta information, that is, each column of the two-dimensional table dataset represented by DataFrame has a name and type. This enables Spark SQL to gain insight into more structural information, so as to optimize the data sources hidden behind the DataFrame and the transformations acting on the DataFrame, and finally achieve the goal of greatly improving runtime efficiency. In contrast to RDD, because there is no way to know the specific internal structure of the stored data elements, Spark Core can only carry out simple and general pipeline optimization at the stage level.
At the same time, like Hive, DataFrame also supports nested data types (struct, array and map). From the perspective of API ease of use, DataFrame API provides a set of high-level relational operations, which is more friendly and lower threshold than functional RDD API.
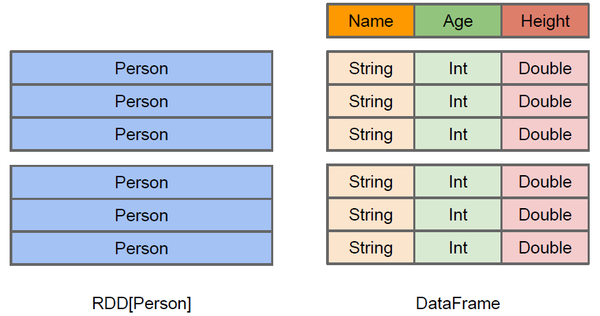
The figure above intuitively shows the difference between DataFrame and RDD.
Although the RDD[Person] on the left takes Person as the type parameter, the Spark framework itself does not understand the internal structure of the Person class. The DataFrame on the right provides detailed structure information, so that Spark SQL can clearly know which columns are included in the dataset, and what is the name and type of each column.
DataFrame is a view that provides a Schema for data. It can be treated as a table in the database. DataFrame is also lazy, but its performance is higher than RDD. The main reason is that the optimized execution plan, that is, the query plan is optimized through spark catalyst optimizer. For example, the following example:
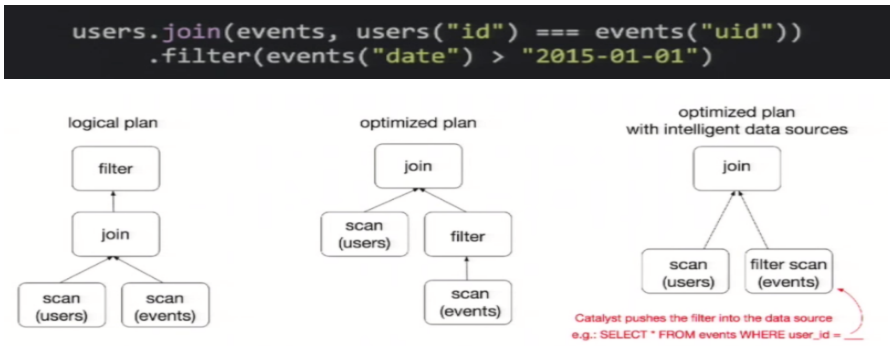
To illustrate query optimization, let's take a look at the example of population data analysis shown in the figure above. In the figure, two dataframes are constructed. After join ing them, a filter operation is performed.
If the implementation plan is implemented intact, the final implementation efficiency is not high. Because join is a costly operation, it may also produce a large data set. If we can push the filter down below the join, filter the DataFrame first, and then join the smaller result set after filtering, we can effectively shorten the execution time. The query optimizer of Spark SQL does exactly that. In short, logical query plan optimization is a process of replacing high-cost operations with low-cost operations by using equivalent transformation based on relational algebra.
4. What is a DataSet
DataSet is a distributed data set. DataSet is a new abstraction added in Spark 1.6 and an extension of DataFrame. It provides the advantages of RDD (strong typing, the ability to use powerful lambda functions) and Spark SQL optimized execution engine. DataSet can also use functional transformation (operation map, flatMap, filter, etc.).
1) It is an extension of DataFrame API and the latest data abstraction of SparkSQL;
2) User friendly API style, with both type safety check and query optimization characteristics of DataFrame;
3) The sample class is used to define the structure information of the data in the DataSet. The name of each attribute in the sample class is directly mapped to the field name in the DataSet;
4) DataSet is strongly typed. For example, there can be DataSet[Car], DataSet[Person].
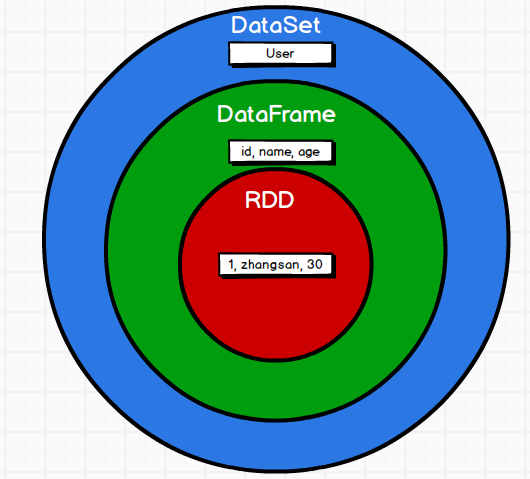
5) DataFrame is a special column of DataSet, DataFrame=DataSet[Row] , Therefore, you can convert the DataFrame into a DataSet through the as method. Row is a type. Like Car and Person, all table structure information is represented by row.
Spark SQL programming
1. Spark Session new starting point
In the old version, SparkSQL provides two SQL query starting points: one is SQLContext, which is used for SQL queries provided by Spark itself; One is called HiveContext, which is used to connect Hive queries.
SparkSession is the starting point of Spark's latest SQL query. It is essentially a combination of SQLContext and HiveContext. Therefore, the API s available on SQLContext and HiveContext can also be used on SparkSession. SparkSession encapsulates sparkcontext internally, so the calculation is actually completed by sparkcontext. When we use spark shell, spark will automatically create a SparkSession called spark, just as we can automatically obtain an sc to represent sparkcontext before
2,DataFrame
The DataFrame API of Spark SQL allows us to use DataFrame without having to register temporary tables or generate SQL expressions. The DataFrame API has both transformation and action operations. In essence, the transformation of DataFrame is more relational, while the DataSet API provides a more functional API.
2.1 create DataFrame
In Spark SQL, SparkSession is the entrance to create DataFrame and execute SQL. There are three ways to create DataFrame: through Spark data source; Convert from an existing RDD; You can also query and return from Hive Table.
2.2 SQL style syntax
SQL syntax style means that we use SQL statements to query data. This style of query must be assisted by temporary view or global view
1) Create a DataFrame
scala> val df = spark.read.json("/opt/module/spark-local/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) Create a temporary table for the DataFrame
scala> df.createOrReplaceTempView("people")
3) Query the whole table through SQL statement
scala> val sqlDF = spark.sql("SELECT * FROM people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
4) Result display
scala> sqlDF.show +---+--------+ |age| name| +---+--------+ | 18|qiaofeng| | 19| duanyu| | 20| xuzhu| +---+--------+
note: the general temporary table is within the Session range. If you want to be effective within the application range, you can use the global temporary table. Full path access is required when using global temporary tables, such as global_temp.people
5) Create a global table for the DataFrame
scala> df.createGlobalTempView("people")
6) Query the whole table through SQL statement
scala> spark.sql("SELECT * FROM global_temp.people").show()
+---+--------+
|age| name|
+---+--------+
| 18|qiaofeng|
| 19| duanyu|
| 20| xuzhu|
+---+--------+
scala> spark.newSession().sql("SELECT * FROM global_temp.people").show()
+---+--------+
|age| name|
+---+--------+
| 18|qiaofeng|
| 19| duanyu|
| 20| xuzhu|
+---+--------+
2.3 DSL style syntax
DataFrame provides a domain specific language (DSL) to manage structured data. DSL can be used in Scala, Java, Python and R. using DSL syntax style, there is no need to create temporary views.
1) Create a DataFrame
scala> val df = spark.read.json("/opt/module/spark-local /people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) View Schema information of DataFrame
scala> df.printSchema root |-- age: Long (nullable = true) |-- name: string (nullable = true)
3) View only the "name" column data
scala> df.select("name").show()
+--------+
| name|
+--------+
|qiaofeng|
| duanyu|
| xuzhu|
+--------+
4) View all columns
scala> df.select("*").show
+--------+---------+
| name |age|
+--------+---------+
|qiaofeng| 18|
| duanyu| 19|
| xuzhu| 20|
+--------+---------+
5) View "name" column data and "age+1" data
Note: when operations are involved, each column must be used$
scala> df.select($"name",$"age" + 1).show +--------+---------+ | name|(age + 1)| +--------+---------+ |qiaofeng| 19| | duanyu| 20| | xuzhu| 21| +--------+---------+
6) View data with age greater than 19
scala> df.filter($"age">19).show +---+-----+ |age| name| +---+-----+ | 20|xuzhu| +---+-----+
7) Group by "age" to view the number of data pieces
scala> df.groupBy("age").count.show
+---+-----+
|age|count|
+---+-----+
| 19| 1|
| 18| 1|
| 20| 1|
+---+-----+
2.4 converting RDD to DataFrame
When developing programs in IDEA, if you need to operate between RDD and DF or DS, you need to introduce import spark. Implications.
The spark here is not the package name in Scala, but the variable name of the created SparkSession object, so you must create a SparkSession object before importing. The spark object here cannot be declared with var, because Scala only supports the introduction of val decorated objects.
No import is required in spark shell, and this operation is completed automatically.
scala> val idRDD = sc.textFile("data/id.txt") scala> idRDD.toDF("id").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+
In actual development, RDD is generally transformed into DataFrame through sample classes.
scala> case class User(name:String, age:Int) defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF.show
+--------+---+
| name|age|
+--------+---+
2.5 conversion of dataframe to RDD
DataFrame is actually the encapsulation of RDD, so you can directly obtain the internal RDD
scala> val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val rdd = df.rdd
rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[46] at rdd at <console>:25
scala> val array = rdd.collect
array: Array[org.apache.spark.sql.Row] = Array([zhangsan,30], [lisi,40])
Note: the RDD storage type obtained at this time is Row
scala> array(0)
res28: org.apache.spark.sql.Row = [zhangsan,30] scala> array(0)(0)
res29: Any = zhangsan
scala> array(0).getAs[String]("name") res30: String = zhangsan
3,DataSet
DataSet is a strongly typed data set, and the corresponding type information needs to be provided.
3.1 create DataSet
1) Create DataSet using sample class sequence
scala> case class Person(name: String, age: Long)
defined class Person
scala> val caseClassDS = Seq(Person("wangyuyan",2)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: Long]
scala> caseClassDS.show
+---------+---+
| name|age|
+---------+---+
|wangyuyan| 2|
+---------+---+
2) Create a DataSet using a sequence of basic types
scala> val ds = Seq(1,2,3,4,5,6).toDS ds: org.apache.spark.sql.Dataset[Int] = [value: int] scala> ds.show +-----+ |value| +-----+ | 1| | 2| | 3| | 4| | 5| | 6| +-----+
Note: in actual use, it is rarely used to convert a sequence into a DataSet, and it is more used to obtain a DataSet through RDD.
3.2 converting RDD to DataSet
SparkSQL can automatically convert the RDD containing the sample class into a DataSet. The sample class defines the structure of the table, and the attribute of the sample class is changed into the column name of the table through reflection. The sample class can contain complex structures such as Seq or Array.
1) Create an RDD
scala> val peopleRDD = sc.textFile("/opt/module/spark-local/people.txt")
peopleRDD: org.apache.spark.rdd.RDD[String] = /opt/module/spark-local/people.txt MapPartitionsRDD[19] at textFile at <console>:24
2) Create a sample class
scala> case class Person(name:String,age:Int)
defined class Person
3)take RDD Convert to DataSet
scala> peopleRDD.map(line => {val fields = line.split(",");Person(fields(0),fields(1). toInt)}).toDS
res0: org.apache.spark.sql.Dataset[Person] = [name: string, age: Long]
3.3 conversion of dataset to RDD
Just call the rdd method.
1) Create a DataSet
scala> val DS = Seq(Person("zhangcuishan", 32)).toDS()
DS: org.apache.spark.sql.Dataset[Person] = [name: string, age: Long]
2) Convert DataSet to RDD
scala> DS.rdd res1: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[6] at rdd at <console>:28
4. Interoperability between DataFrame and DataSet
4.1 conversion of dataframe to DataSet
1) Create a DateFrame
scala> val df = spark.read.json("/opt/module/spark-local/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) Create a sample class
scala> case class Person(name: String,age: Long) defined class Person
3) Convert DataFrame to DataSet
scala> df.as[Person] res5: org.apache.spark.sql.Dataset[Person] = [age: bigint, name: string]
This method is to use the as method to convert to Dataset after giving the type of each column, which is very convenient when the data type is DataFrame and needs to be processed for each field. When using some special operations, be sure to add import spark.implicits._ Otherwise, toDF and toDS cannot be used.
4.2 converting dataset to DataFrame
1) Create a sample class
scala> case class Person(name: String,age: Long) defined class Person
2) Create DataSet
scala> val ds = Seq(Person("zhangwuji",32)).toDS()
ds: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
3) Convert DataSet to DataFrame
scala> var df = ds.toDF df: org.apache.spark.sql.DataFrame = [name: string, age: bigint]
4) Display
scala> df.show +---------+---+ | name|age| +---------+---+ |zhangwuji| 32| +---------+---+
5. IDEA practice
1) Maven project add dependency
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.1.1</version> </dependency>
2) Code implementation
object SparkSQL01_Demo {
def main(args: Array[String]): Unit = {
//Create context configuration object
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
//Create a SparkSession object
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//RDD = > dataframe = > dataset conversion requires the introduction of implicit conversion rules, otherwise it cannot be converted
//spark is not a package name, but a context object name
import spark.implicits._
//Read json file and create dataframe {"username": "Lisi", "age": 18}
val df: DataFrame = spark.read.json("D:\\dev\\workspace\\spark-bak\\spark-bak-00\\input\\test.json")
//df.show()
//SQL style syntax
df.createOrReplaceTempView("user")
//spark.sql("select avg(age) from user").show
//DSL style syntax
//df.select("username","age").show()
//*****RDD=>DataFrame=>DataSet*****
//RDD
val rdd1: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List((1,"qiaofeng",30),(2,"xuzhu",28),(3,"duanyu",20)))
//DataFrame
val df1: DataFrame = rdd1.toDF("id","name","age")
//df1.show()
//DateSet
val ds1: Dataset[User] = df1.as[User]
//ds1.show()
//*****DataSet=>DataFrame=>RDD*****
//DataFrame
val df2: DataFrame = ds1.toDF()
//The RDD type returned by RDD is Row. The getXXX method provided in it can obtain the field value, which is similar to jdbc processing result set, but the index starts from 0
val rdd2: RDD[Row] = df2.rdd
//rdd2.foreach(a=>println(a.getString(1)))
//*****RDD=>DataSe*****
rdd1.map{
case (id,name,age)=>User(id,name,age)
}.toDS()
//*****DataSet=>=>RDD*****
ds1.rdd
//Release resources
spark.stop()
}
}
case class User(id:Int,name:String,age:Int)
Loading and saving Spark SQL data
1. General loading and saving methods
1) spark.read.load is a general method of loading data
2) df.write.save is a common way to save data
1.1 data loading
1)read loads data directly
scala> spark.read. csv format jdbc json load option options orc parquet schema table text textFile
Note: the parameters related to loading data need to be written into the above methods. For example, textFile needs to pass in the path of loading data, and JDBC needs to pass in the parameters related to JDBC.
For example: directly load Json data
scala> spark.read.json("/opt/module/spark-local/people.json").show
+---+--------+
|age| name|
+---+--------+
| 18|qiaofeng|
| 19| duanyu|
| 20| xuzhu|
2)format specifies the type of data to load
scala> spark.read.format("...")[.option("...")].load("...")
Detailed usage:
(1) format("..."): Specifies the type of data to load, including "csv", "jdbc", "json", "orc", "parquet" and "textFile"
(2) load("..."): the path to load data in "csv", "jdbc", "json", "orc", "parquet" and "textFile" formats
(3) option("..."): in the "JDBC" format, you need to pass in the corresponding JDBC parameters, url, user, password and dbtable
For example, use format to specify loading Json type data
scala> spark.read.format("json").load ("/opt/module/spark-local/people.json").show
+---+--------+
|age| name|
+---+--------+
| 18|qiaofeng|
| 19| duanyu|
| 20| xuzhu|
3) Run SQL directly on file
The previous is to use the read API to load the file into the DataFrame and then query. You can also query directly on the file.
scala> spark.sql("select * from json.`/opt/module/spark-local/people.json`").show
+---+--------+
|age| name|
+---+--------+
| 18|qiaofeng|
| 19| duanyu|
| 20| xuzhu|
+---+--------+|
Note: json indicates the format of the file. The specific path of the following file needs to be enclosed in backquotes.
1.2 saving data
1)write save data directly
scala> df.write. csv jdbc json orc parquet textFile... ...
Note: the parameters related to saving data need to be written into the above method. For example, textFile needs to pass in the path of loading data, and JDBC needs to pass in JDBC related parameters.
For example: directly save the data in df to the specified directory
//The default save format is parquet
scala> df.write.save("/opt/module/spark-local/output")
//You can specify the save format and save directly without calling save
scala> df.write.json("/opt/module/spark-local/output")
2)format specifies the type of data to save
scala> df.write.format("...")[.option("...")].save("...")
Detailed usage:
(1) format("..."): Specifies the type of data to be saved, including "csv", "jdbc", "json", "orc", "parquet" and "textFile".
(2) Save ("..."): the path to save data needs to be passed in the formats of "csv", "orc", "parquet" and "textFile".
(3) option("..."): in the "JDBC" format, you need to pass in the corresponding JDBC parameters, url, user, password and dbtable
3) File save options
The save operation can use SaveMode to indicate how to process data, and set it using the mode() method. One thing is important: these savemodes are unlocked and are not atomic operations.
SaveMode is an enumeration class, where constants include:
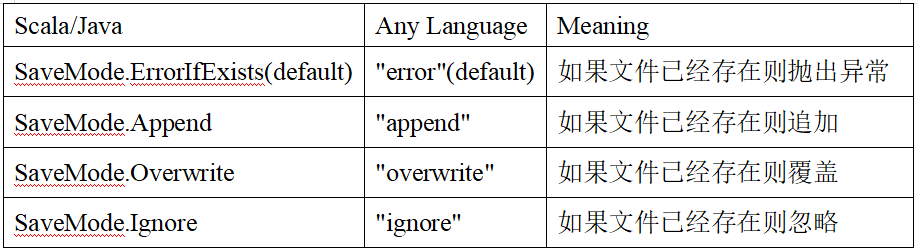
For example: use the specified format to specify the save type for saving
df.write.mode("append").json("/opt/module/spark-local/output")
1.3 default data source
The default data source of Spark SQL is Parquet format. When the data source is a Parquet file, Spark SQL can easily perform all operations without using format. Modify the configuration item spark.sql.sources.default to modify the default data source format.
1) Load data
val df = spark.read.load("/opt/module/spark-local/examples/src/main/resources/users.parquet").show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
df: Unit = ()
2) Save data
scala> var df = spark.read.json("/opt/module/spark-local/people.json")
//Save in parquet format
scala> df.write.mode("append").save("/opt/module/spark-local/output")
2. JSON file
Spark SQL can automatically infer the structure of JSON dataset and load it as a Dataset[Row]. You can load JSON files through SparkSession.read.json().
Note: This JSON file is not a traditional JSON file. Each line must be a JSON string. The format is as follows:
{"name":"Michael"}
{"name":"Andy","age":30}
{"name":"Justin","age":19}
1) Import implicit conversion
import spark.implicits._
2) Load JSON file
val path = "/opt/module/spark-local/people.json" val peopleDF = spark.read.json(path)
3) Create temporary table
peopleDF.createOrReplaceTempView("people")
4) Data query
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
+------+
| name|
+------+
|Justin|
+------+
3,MySQL
Spark SQL can create a DataFrame by reading data from the relational database through JDBC. After a series of calculations on the DataFrame, you can write the data back to the relational database.
**If you use the spark shell operation, you can specify the relevant database driver path when starting the shell or put the relevant database driver under the class path of spark**
bin/spark-shell --jars mysql-connector-java-5.1.27-bin.jar
Here is a demonstration of Mysql operation through JDBC in Idea
3.1 import dependency
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
3.2 reading data from JDBC
object SparkSQL02_Datasource {
def main(args: Array[String]): Unit = {
//Create context configuration object
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
//Create a SparkSession object
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
//Mode 1: general load method reading
spark.read.format("jdbc")
.option("url", "jdbc:mysql://hadoop202:3306/test")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "user")
.load().show
//Mode 2: another form of reading parameters by the general load method
spark.read.format("jdbc")
.options(Map("url"->"jdbc:mysql://hadoop202:3306/test?user=root&password=123456",
"dbtable"->"user","driver"->"com.mysql.jdbc.Driver")).load().show
//Method 3: use jdbc method to read
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123456")
val df: DataFrame = spark.read.jdbc("jdbc:mysql://hadoop202:3306/test", "user", props)
df.show
//Release resources
spark.stop()
}
}
3.3 writing data to JDBC
object SparkSQL03_Datasource {
def main(args: Array[String]): Unit = {
//Create context configuration object
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
//Create a SparkSession object
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val rdd: RDD[User2] = spark.sparkContext.makeRDD(List(User2("lisi", 20), User2("zs", 30)))
val ds: Dataset[User2] = rdd.toDS
//Method 1: specify the write out type in the general format
ds.write
.format("jdbc")
.option("url", "jdbc:mysql://hadoop202:3306/test")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "user")
.mode(SaveMode.Append)
.save()
//Method 2: through jdbc method
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123456")
ds.write.mode(SaveMode.Append).jdbc("jdbc:mysql://hadoop202:3306/test", "user", props)
//Release resources
spark.stop()
}
}
case class User2(name: String, age: Long)
4,Hive
Apache Hive is an SQL Engine on Hadoop. Spark SQL can be compiled with or without Hive support.
Spark SQL with Hive support can support Hive table access, UDF (user-defined function) and Hive query language (HiveQL/HQL). It should be emphasized that if Hive libraries are to be included in spark SQL, Hive does not need to be installed in advance. Generally speaking, it is better to introduce Hive support when compiling spark SQL, so that these features can be used. If you download a binary version of spark, it should have added Hive support at compile time.
To connect spark SQL to a deployed Hive, you must copy hive-site.xml to spark's configuration file directory ($SPARK_HOME/conf). Spark SQL can run even if Hive is not deployed. It should be noted that if Hive is not deployed, spark SQL will create its own Hive metadata warehouse called Metastore in the current working directory_ db. In addition, for using the deployed Hive, if you try to use the CREATE TABLE (not CREATE EXTERNAL TABLE) statement in HiveQL to create tables, these tables will be placed in the / user/hive/warehouse directory in your default file system (if you have a configured hdfs-site.xml in your classpath, the default file system is HDFS, otherwise it is the local file system).
Spark shell is Hive supported by default; It is not supported by default in the code and needs to be specified manually (add a parameter).
4.1 use embedded Hive
If you use Hive embedded in Spark, you don't have to do anything. You can use it directly.
Hive's metadata is stored in derby, and the warehouse address is $SPARK_HOME/spark-warehouse.
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
+--------+---------+-----------+
scala> spark.sql("create table aa(id int)")
19/02/09 18:36:10 WARN HiveMetaStore: Location: file:/opt/module/spark-local/spark-warehouse/aa specified for non-external table:aa
res2: org.apache.spark.sql.DataFrame = []
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| default| aa| false|
+--------+---------+-----------+
Loading local data into a table
scala> spark.sql("load data local inpath './ids.txt' into table aa")
res8: org.apache.spark.sql.DataFrame = []
scala> spark.sql("select * from aa").show
+---+
| id|
+---+
|100|
|101|
|102|
|103|
|104|
|105|
|106|
+---+
In practical use, almost no one will use the built-in Hive.
4.2 external Hive applications
If Spark wants to take over Hive deployed outside Hive, it needs to go through the following steps.
(1) Make sure the original Hive is working properly
(2) You need to copy hive-site.xml to the conf / directory of spark
(3) If Tez related information has been configured in the previous hive-site.xml file, comment it out
(4) copy the Mysql driver to the jars / directory of Spark
(5) You need to start the hive service in advance. hive/bin/hiveservices.sh start
(6) If HDFS cannot be accessed, copy core-site.xml and hdfs-site.xml to the conf / directory
Start spark shell
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| default| emp| false|
+--------+---------+-----------+
scala> spark.sql("select * from emp").show
19/02/09 19:40:28 WARN LazyStruct: Extra bytes detected at the end of the row! Ignoring similar problems.
+-----+-------+---------+----+----------+------+------+------+
|empno| ename| job| mgr| hiredate| sal| comm|deptno|
+-----+-------+---------+----+----------+------+------+------+
| 7369| SMITH| CLERK|7902|1980-12-17| 800.0| null| 20|
| 7499| ALLEN| SALESMAN|7698| 1981-2-20|1600.0| 300.0| 30|
| 7521| WARD| SALESMAN|7698| 1981-2-22|1250.0| 500.0| 30|
| 7566| JONES| MANAGER|7839| 1981-4-2|2975.0| null| 20|
| 7654| MARTIN| SALESMAN|7698| 1981-9-28|1250.0|1400.0| 30|
| 7698| BLAKE| MANAGER|7839| 1981-5-1|2850.0| null| 30|
| 7782| CLARK| MANAGER|7839| 1981-6-9|2450.0| null| 10|
| 7788| SCOTT| ANALYST|7566| 1987-4-19|3000.0| null| 20|
| 7839| KING|PRESIDENT|null|1981-11-17|5000.0| null| 10|
| 7844| TURNER| SALESMAN|7698| 1981-9-8|1500.0| 0.0| 30|
| 7876| ADAMS| CLERK|7788| 1987-5-23|1100.0| null| 20|
| 7900| JAMES| CLERK|7698| 1981-12-3| 950.0| null| 30|
| 7902| FORD| ANALYST|7566| 1981-12-3|3000.0| null| 20|
| 7934| MILLER| CLERK|7782| 1982-1-23|1300.0| null| 10|
| 7944|zhiling| CLERK|7782| 1982-1-23|1300.0| null| 50|
+-----+-------+---------+----+----------+------+------+------+
4.3 running Spark SQL CLI
Spark SQLCLI can easily run Hive metadata service locally and perform query tasks from the command line. Execute the following command in the spark directory to start Spark SQ LCLI and directly execute SQL statements, similar to the Hive window.
bin/spark-sql
4.4 operation Hive in code
1) Add dependency
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
2) Copy hive-site.xml to the resources directory
3) Code implementation
object SparkSQL08_Hive{
def main(args: Array[String]): Unit = {
//Create context configuration object
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
val spark: SparkSession = SparkSession
.builder()
.enableHiveSupport()
.master("local[*]")
.appName("SQLTest")
.getOrCreate()
spark.sql("show tables").show()
//Release resources
spark.stop()
}
}
Spark SQL practice
1. Data preparation
All data of spark SQL operation comes from Hive. First, create a table in Hive and import data. There are 3 tables in total: 1 user behavior table, 1 city table and 1 product table.
CREATE TABLE `user_visit_action`( `date` string, `user_id` bigint, `session_id` string, `page_id` bigint, `action_time` string, `search_keyword` string, `click_category_id` bigint, `click_product_id` bigint, `order_category_ids` string, `order_product_ids` string, `pay_category_ids` string, `pay_product_ids` string, `city_id` bigint) row format delimited fields terminated by '\t'; load data local inpath '/opt/module/data/user_visit_action.txt' into table sparkpractice.user_visit_action; CREATE TABLE `product_info`( `product_id` bigint, `product_name` string, `extend_info` string) row format delimited fields terminated by '\t'; load data local inpath '/opt/module/data/product_info.txt' into table sparkpractice.product_info; CREATE TABLE `city_info`( `city_id` bigint, `city_name` string, `area` string) row format delimited fields terminated by '\t'; load data local inpath '/opt/module/data/city_info.txt' into table sparkpractice.city_info;
2. Demand
2.1 requirements introduction
From the perspective of hits, the top three popular commodities in each region are calculated, and the distribution proportion of each commodity in major cities is noted. More than two cities are displayed by others.
For example:
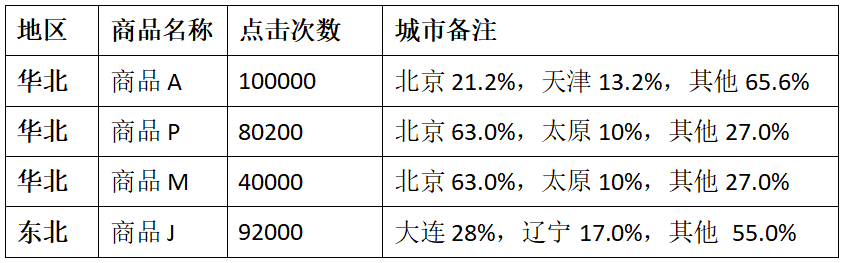
2.2 train of thought analysis
1) Use sql to complete. If you encounter complex requirements, you can use udf or udaf
2) Query out all click records and compare them with city_ Connect the info table to get the region of each city and product_ The product name is obtained by connecting the info table
3) Group by region and commodity name, and count the total hits of each commodity in each region
4) The number of hits in each region is in descending order
5) Take only the top three and save the results in the database
6) UDAF function needs to be customized for city notes
2.3 code implementation
1) UDAF function definition
class AreaClickUDAF extends UserDefinedAggregateFunction {
// Type of input data: String
override def inputSchema: StructType = {
StructType(StructField("city_name", StringType) :: Nil)
// StructType(Array(StructField("city_name", StringType)))
}
// Types of cached data: Beijing - > 1000, Tianjin - > 5000 map, total hits 1000 /?
override def bufferSchema: StructType = {
// MapType(StringType, LongType) also needs to mark the type of key and value of map
StructType(StructField("city_count", MapType(StringType, LongType)) :: StructField("total_count", LongType) :: Nil)
}
// The output data type is "Beijing 21.2%, Tianjin 13.2%, others 65.6%" string
override def dataType: DataType = StringType
// Whether the same input application has the same output
override def deterministic: Boolean = true
// Initialize stored data
override def initialize(buffer: MutableAggregationBuffer): Unit = {
//Initialize map cache
buffer(0) = Map[String, Long]()
// Initialize total hits
buffer(1) = 0L
}
// Merge Map within the zone [city name, hits]
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
// First, get the city name, and then use the city name as a key to check whether it exists in the map. If it exists, add the corresponding value + 1. If it does not exist, directly add 0 + 1
val cityName = input.getString(0)
// val map: collection.Map[String, Long] = buffer.getMap[String, Long](0)
val map: Map[String, Long] = buffer.getAs[Map[String, Long]](0)
buffer(0) = map + (cityName -> (map.getOrElse(cityName, 0L) + 1L))
// If you encounter a city, the total number of hits should be + 1
buffer(1) = buffer.getLong(1) + 1L
}
// Merging between partitions
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
val map1 = buffer1.getAs[Map[String, Long]](0)
val map2 = buffer2.getAs[Map[String, Long]](0)
// The key value pair of map1 and the accumulation in map2 are finally assigned to buffer1
buffer1(0) = map1.foldLeft(map2) {
case (map, (k, v)) =>
map + (k -> (map.getOrElse(k, 0L) + v))
}
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// Final output. "Beijing 21.2%, Tianjin 13.2%, others 65.6%"
override def evaluate(buffer: Row): Any = {
val cityCountMap = buffer.getAs[Map[String, Long]](0)
val totalCount = buffer.getLong(1)
var citysRatio: List[CityRemark] = cityCountMap.toList.sortBy(-_._2).take(2).map {
case (cityName, count) => {
CityRemark(cityName, count.toDouble / totalCount)
}
}
// If the number of cities exceeds 2, other cities will be displayed
if (cityCountMap.size > 2) {
citysRatio = citysRatio :+ CityRemark("other", citysRatio.foldLeft(1D)(_ - _.cityRatio))
}
citysRatio.mkString(", ")
}
}
case class CityRemark(cityName: String, cityRatio: Double) {
val formatter = new DecimalFormat("0.00%")
override def toString: String = s"$cityName:${formatter.format(cityRatio)}"
}
2) Concrete implementation
object SparkSQL04_TopN {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[2]")
.appName("AreaClickApp")
.enableHiveSupport()
.getOrCreate()
spark.sql("use sparkpractice")
// 0 register custom aggregate function
spark.udf.register("city_remark", new AreaClickUDAF)
// 1. Query all click records and make internal connection with city table and product table
spark.sql(
"""
|select
| c.*,
| v.click_product_id,
| p.product_name
|from user_visit_action v join city_info c join product_info p on v.city_id=c.city_id and v.click_product_id=p.product_id
|where click_product_id>-1
""".stripMargin).createOrReplaceTempView("t1")
// 2. Calculate the hits of each area and each product
spark.sql(
"""
|select
| t1.area,
| t1.product_name,
| count(*) click_count,
| city_remark(t1.city_name)
|from t1
|group by t1.area, t1.product_name
""".stripMargin).createOrReplaceTempView("t2")
// 3. Arrange the hits of products in each area in reverse order
spark.sql(
"""
|select
| *,
| rank() over(partition by t2.area order by t2.click_count desc) rank
|from t2
""".stripMargin).createOrReplaceTempView("t3")
// 4. Top 3 for each area
spark.sql(
"""
|select
| *
|from t3
|where rank<=3
""".stripMargin).show
//Release resources
spark.stop()
}
}
Knowledge planet
Welcome to my knowledge planet to provide technical Q & A, data sharing, simulated interview and other services. 
Guess you like < br > Hive calculates the maximum number of consecutive login days<br> Detailed explanation of Hadoop data migration usage<br> Hbase repair tool Hbck<br> Hierarchical theory of warehouse modeling<br> Understand Hive's data storage and compression<br> Big data components focus on these aspects