- Spark SQL directory
- DataFrame
- DataSet
- RDD
- DataFrame, conversion between DataSet and RDD
- DataFrame, relationship between DataSet and RDD
- The commonness and difference between DataFrame, DataSet and RDD
1.Spark SQL
Spark SQL is a module used by spark to process structured data. It provides two programming abstractions: DataFrame and DataSet, and serves as a distributed SQL query engine.
2. Comparison between spark SQL and Hive SQL
Hive SQL is converted into MapReduce and submitted to the cluster for execution, which greatly simplifies the complexity of programming MapReduce. The execution efficiency of MapReduce is relatively slow.
Spark SQL is converted to RDD, and then submitted to the cluster for execution. The execution efficiency is very fast!
3.DataFrame
DataFrame is a distributed data container, in addition to data, it also records data structure information. DataFrame provides a view of the Schema for the data. We can treat it as a table in the database. DataFrame is lazy and its performance is higher than RDD.
4.DataSet
Dataset is a data set with strong type. You need to provide corresponding type information.
5.RDD
RDD (Resilient Distributed Dataset) is called distributed dataset, which is the most basic data abstraction in Spark. Code is an abstract class, which represents an immutable, divisible, parallel computing set of elements.
RDD will come out separately later.
6.DataFrame, conversion between DataSet and RDD
-
RDD to DataSet
SparkSQL can automatically convert RDD containing case class into DataFrame, case class defines the structure of table, and case class attribute becomes the column name of table through reflection.
// Sample class case class Person(name: String, age: BigInt) // Create configuration object val sparkConf: SparkConf = new SparkConf().setAppName("SparkSQL").setMaster("local[*]") // Create context object val sparkSession: SparkSession = SparkSession .builder() .config(sparkConf) .getOrCreate() // Add implicit conversion rule import sparkSession.implicits._ val rdd: RDD[(String, Int)] = sparkSession.sparkContext.makeRDD(Array(("zhaoliu", 20))) // RDD conversion DataSet val person: Dataset[Person] = rdd.map(x => Person(x._1, x._2)).toDS()
- DataSet to RDD
// Sample class case class Person(name: String, age: BigInt) // Create DataSet val dataSet: Dataset[Person] = Seq(Person("zhansan", 32)).toDS() // DataSet to RDD dataSet.rdd
- DataFrame to DataSet
// Sample class case class Person(name: String, age: BigInt) // Get data, convert data to DataFrame val dateFrame: DataFrame = sparkSession.read.json("input/user.json") // DataFrame to DataSet val dataSet: Dataset[Person] = dateFrame.as[Person]
- DataSet to DataFrame
// Sample class case class Person(name: String, age: BigInt) // Get data, convert data to DataFrame val dateFrame: DataFrame = sparkSession.read.json("input/user.json") // DataFrame to DataSet val dataSet: Dataset[Person] = dateFrame.as[Person] // DataSet to DataFrame val df: Dataset[Person] = dataSet.asDF
7. The relationship between dataframe, DataSet and RDD
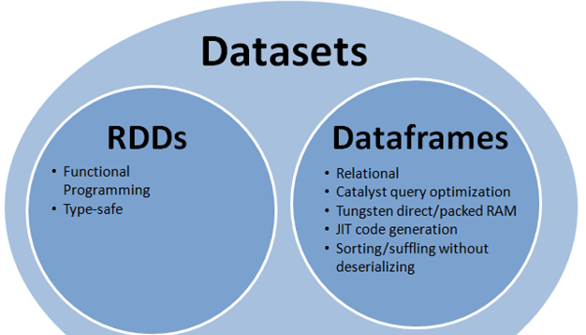
In SparkSQL, Spark provides us with two new abstractions: DataFrame and DataSet.
What's the difference between them and RDD? First of all, from the perspective of version generation:
RDD (Spark1.0) —> Dataframe(Spark1.3) —> Dataset(Spark1.6)
If the same data are given to these three data structures, they will give the same results after calculating separately. The difference is their execution efficiency and way.
In later Spark versions, DataSet will gradually replace RDD and DataFrame as the only API interface.
8. Commonness and difference between dataframe, DataSet and RDD
-
Generality
- RDD, DataFrame and Dataset are all distributed elastic data sets under spark platform, which provide convenience for processing super large data
- All three have an inert mechanism. When creating and transforming, such as map method, they will not be executed immediately. Only when they encounter Action, such as foreach, will they start to traverse.
- All three will automatically cache operations according to the memory condition of spark, so that even if the data volume is large, there is no need to worry about memory overflow.
- All three have the concept of partition
- There are many common functions among them, such as filter, sorting, etc
- This package is required for many operations on DataFrame and Dataset
import spark.implicits._ - Both DataFrame and Dataset can use pattern matching to get the value and type of each field
dataFrame.map{ case Row(col1:String,col2:Int)=> println(col1);println(col2) col1 case _=> "" } // Sample class, defining field name and type case class Coltest(col1:String,col2:Int)extends Serializable dataSet.map{ case Coltest(col1:String,col2:Int)=> println(col1);println(col2) col1 case _=> "" }
- Difference
-
RDD:
1) RDD is generally used together with spark mlib
2) Spark SQL operation is not supported by RDD -
DataFrame:
1) Unlike RDD and Dataset, the type of each Row of DataFrame is fixed to Row, and the value of each column cannot be accessed directly. Only through parsing can the value of each field be obtained, such as:
dataFrame.foreach{ line => val col1=line.getAs[String]("col1") val col2=line.getAs[String]("col2") }
2) DataFrame and Dataset are generally not used together with spark mlib
3) Both DataFrame and Dataset support the operation of sparksql, such as select, groupby, etc. they can also register temporary tables / windows for sql statement operations, such as:
// Create view dataFrame.createOrReplaceTempView("tmp") spark.sql("select ROW,DATE from tmp where DATE is not null order by DATE").show
4) DataFrame and Dataset support some convenient saving methods, such as saving as csv, which can be carried with header, so that the field name of each column is clear at a glance
// Preservation val saveOptions = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://hadoop102:9000/test") dataFrame.write.format("com.atguigu.spark.csv").mode(SaveMode.Overwrite).options(saveOptions).save() // read val options = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://hadoop102:9000/test") val dataFrame= spark.read.options(options).format("com.atguigu.spark.csv").load()
With this way of saving, it is convenient to get the corresponding field name and column, and the delimiter can be freely specified.
3. Dataset:
1) Dataset and DataFrame have exactly the same member functions, except that each row has a different data type.
2) DataFrame can also be called Dataset[Row], the type of each Row is Row, and it is not parsed. It is impossible to know which fields and what types of fields are in each Row. Only the getAS method mentioned above or the pattern matching mentioned in Article 7 of the commonness can be used to produce specific word segments. In Dataset, the type of each Row is not certain. After the case class is customized, you can get the information of each Row freely
// Example class: defining field names and types case class Coltest(col1:String,col2:Int)extends Serializable /** rdd ("a", 1) ("b", 1) ("a", 1) **/ val dataSet: Dataset[Coltest]=rdd.map{line=> Coltest(line._1,line._2) }.toDS dataSet.map{ line=> println(line.col1) println(line.col2) }
It can be seen that Dataset is very convenient to access a field in a column. However, if you want to write some functions with strong adaptability, if you use Dataset, the row type is uncertain, which may be a variety of case class es, unable to achieve adaptation. At this time, you can use DataFrame, that is, Dataset[Row], to better solve the problem

