The Spark Computing Framework encapsulates three data structures for high concurrency and high throughput data processing in different application scenarios.
- RDD: Elastic Distributed Dataset
- Accumulator: Distributed shared write-only variables
- Broadcast variables: distributed shared read-only variables
RDD
1. What is RDD
RDD (Resilient Distributed Dataset) is called an elastic distributed dataset and is the most basic data processing model in Spark. Code is an abstract class that represents an elastic, immutable, partitionable collection of elements that can be computed in parallel.
elastic
- Resilience of storage: automatic switching between memory and disk;
- Fault-tolerant resilience: data loss can be recovered automatically;
- Calculated elasticity: Calculate the error retry mechanism;
- Elasticity of slicing: can be re-sliced as needed.
Distributed
Data stored on different nodes in a large data cluster
data set
RDD encapsulates computing logic and does not save data
Data abstraction
RDD is an abstract class that requires a subclass implementation
Invariant
RDD encapsulates computing logic and cannot be changed. To change, only new RDDs can be generated, and computing logic can be encapsulated in new RDDs.
Partitionable, parallel computing
Relationship between RDD and IO streams
- RDD handles data like IO streams, but also in decorator design mode
- RDD data does not actually perform business logic operations until the collect method is called, and all previous encapsulations are extensions of functionality
- RDD does not save data, but IO can temporarily save part of the data
2. Core Attributes
- Partition List
A partition list exists in the RDD data structure for parallel computing while performing tasks, which is an important property of distributed computing. - Partition calculation function
Spark calculates each partition using a partition function - Dependency between RDD s
RDD is the encapsulation of computing models. When multiple computing models need to be combined in a requirement, multiple RDDs need to be established as dependencies - Partitioner (optional)
When the data is of KV type, you can customize the partition of the data by setting the partitioner - Preferred location (optional)
When calculating data, different node locations can be selected based on the state of the computing node.
3. Principle of execution
- From a computational point of view, computing resources (memory & CPU) and computing models (logic) are required in the data processing process. When executed, computing resources and computing models need to be coordinated and integrated.
- When the Spark framework executes, it first requests resources, then decomposes the application's data processing logic into one compute task by one. It then sends the tasks to the compute nodes that have allocated resources, and computes the data according to the specified calculation model. Finally, the compute results are obtained.
- RDD is the core model for data processing in the Spark framework. Next, let's look at how RDD works in the Yarn environment:
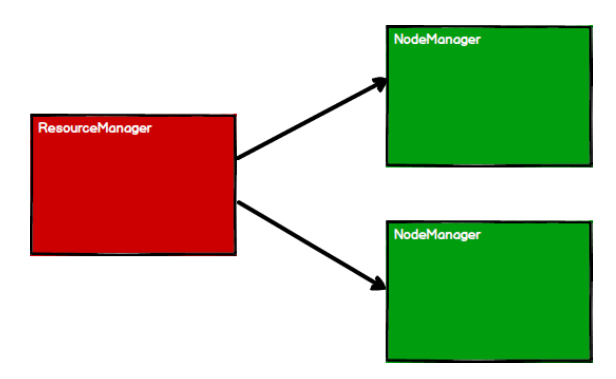
1) Start the Yarn cluster environment
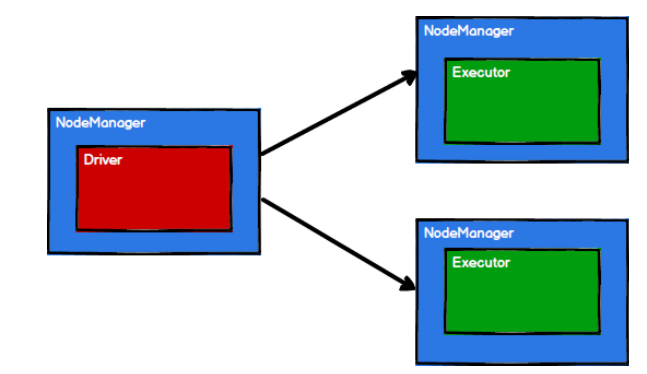
2) Spark creates scheduling and computing nodes by requesting resources
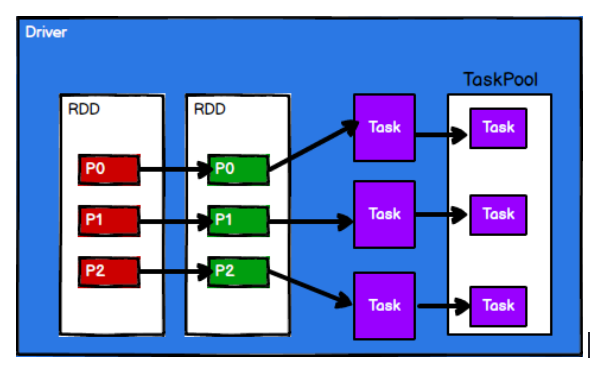
3) Spark Framework divides computing logic into tasks based on partition according to requirements
4) Scheduling nodes send tasks to the corresponding computing nodes based on their state for calculation
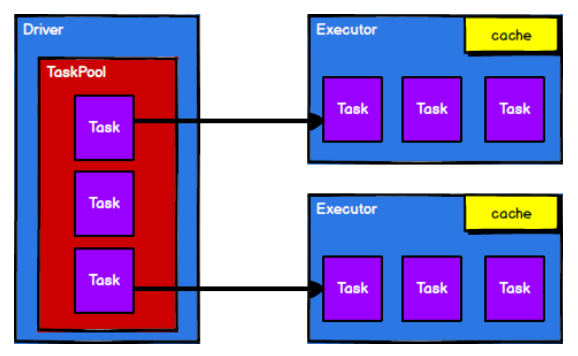
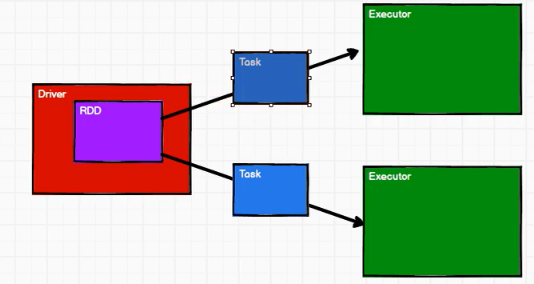
From the above process, it can be seen that RDD is mainly used to encapsulate logic throughout the process and generate Task s to send to Executor nodes to perform calculations
4. Basic Programming
4.1 RDD Creation
- Create an RDD from a collection (memory)
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
//TODO Prepare Environment
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(conf)
//TODO Create RDD
//Create an RDD from memory, using data from an in-memory collection as a data source for processing
val seq=Seq[Int](1,2,3,4)
//parallelize:Parallel
//val rdd: RDD[Int] = sc.parallelize(seq)
//The makeRDD method, when implemented at the bottom level, actually calls the parallelize method of the rdd object
val rdd: RDD[Int] = sc.makeRDD(seq)
rdd.collect().foreach(println)
//TODO Shutdown Environment
sc.stop()
}
}1 2 3 4
- Create RDD s from external storage (files)
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
//TODO Prepare Environment
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(conf)
//TODO Create RDD
//Create an RDD from a file that uses the data in the file as a data source for processing
//The path path path defaults to the root path of the current environment, either absolute or relative.
//The path path path can be either a specific path to a file or a directory name
//val rdd=sc.textFile("datas")
//path paths can also use wildcards
//val rdd=sc.textFile("datas/1*.txt")
//Path can also be the path to a distributed storage system: HDFS
//val rdd=sc.textFile("hdfs://linux1:8020/test.txt")
//textFile: Reads data in behavioral units, all read as strings
//wholeTextFiles: Read data in files
//val rdd = sc.wholeTextFiles("datas")
//The read result is represented as a tuple, with the first element representing the file path and the second element representing the file content
val rdd: RDD[String] = sc.textFile("file:///D:\\workspace\\leke-bigdata\\datas\\1.txt")
rdd.collect().foreach(println)
//TODO Shutdown Environment
sc.stop()
}
}Hello World Hello Spark hello scala hello Spark
- Create from other RDD s
- Create RDD directly
4.2 RDD Parallelism and Partitioning
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
//TODO Prepare Environment
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
//conf.set("spark.default.parallelism","5") can manually configure the number of cores
val sc = new SparkContext(conf)
//TODO Create RDD
//Parallelism & Partition of RDD
//The makeRDD method passes a second parameter that represents the number of partitions
//The second parameter can be passed away, then the makeRDD method will use the default value: defaultParallelism (default)
//Source scheduler.conf.getInt("spark.default.parallelism",totalCores)
//Spark gets the configuration parameters from the configuration object by default: spark.default.parallelism
//If not, use the totalCores property, which takes the maximum number of cores available for the current running environment
val rdd: RDD[Int] = sc.makeRDD(
List(1, 2, 3, 4), 2
)
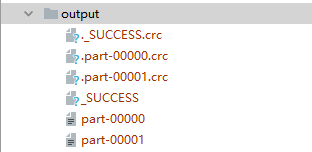
//Save processed data to a partition file
rdd.saveAsTextFile("file:///D:\\workspace\\leke-bigdata\\output")
//TODO Shutdown Environment
sc.stop()
}
}
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
//TODO Prepare Environment
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(conf)
//TODO Create RDD
//textFile can use a file as a data source for data processing, or it can set partitions by default. The default number of partitions is 2
//minPartition: Minimum number of partitions
//math.min(defaultParallelism,2)
//If you do not want to use the default number of partitions, you can specify the number of partitions by using the second parameter
//Spark reads files, but at the bottom, Hadoop reads them
//How the number of partitions is calculated:
// totalSize=7
// goalSize=7/2=3(byte)
// 7/3 = 2...1 (1.1) +1 = 3 (partition)
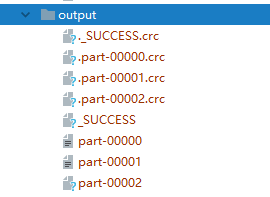
val rdd: RDD[String] = sc.textFile("file:///D:\\workspace\\leke-bigdata\\datas\\1.txt",3)
//Save processed data to a partition file
rdd.saveAsTextFile("file:///D:\\workspace\\leke-bigdata\\output")
//TODO Shutdown Environment
sc.stop()
}
}1.txt
1 2 3
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
//TODO Prepare Environment
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(conf)
//TODO Create RDD
//Allocation of TODO data partitions
//1. Data is read in behavioral units
// spark reads files in hadoop mode, so it reads one line at a time, regardless of the number of bytes
//2. Data is read in units of offset, which is not read repeatedly
/*Byte offset
* 1@@ => 012
* 2@@ => 345
* 3 => 6
*/
//3. Calculation of offset range for data partitions
/*Partition offset range
* 0 => [0,3] =>12
* 1 => [3,6] =>3
* 2 => [6,7] =>
*/
//If the data source is multiple files, then partition in file units when partitioning is calculated
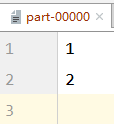
val rdd: RDD[String] = sc.textFile("file:///D:\\workspace\\leke-bigdata\\datas\\1.txt",2)
//Save processed data to a partition file
rdd.saveAsTextFile("file:///D:\\workspace\\leke-bigdata\\output")
//TODO Shutdown Environment
sc.stop()
}
}
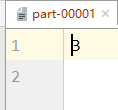
4.3 RDD Conversion Operator

1)map
The processed data is mapped one by one, where the conversion can be either a type conversion or a value conversion.
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-map
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//1,2,3,4
//2,4,6,8
//Conversion function
// def mapFunction(num:Int):Int={
// num*2
// }
// val mapRDD: RDD[Int] = rdd.map(mapFunction)
// Val map RDD: RDD[Int] = rdd.map((num:Int)=>{num*2})//anonymous function
val mapRDD: RDD[Int] = rdd.map(_*2)
mapRDD.collect().foreach(println)
sc.stop()
}
}2 4 6 8
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-map
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
//1,2 one partition 3,4 one partition
//1.rdd Calculates data within a partition as an execution logic
// The next data will not execute until all the logic of the previous data has been executed
// Execution of data within a partition is ordered
//2. The calculation of data in different partitions is out of order
val mapRDD1= rdd.map(
x => {
println("List:"+x)
x
}
)
val mapRDD2= mapRDD1.map(
x => {
println("After Conversion List: " + x)
x
})
mapRDD2.collect()
sc.stop()
}
}
List:1 List:3 After Conversion List: 1 After Conversion List: 3 List:2 List:4 After Conversion List: 2 After Conversion List: 4
2)mapPartitions
The data to be processed is sent in partitions to the computing nodes for processing, where processing means that any processing, even filtering data, can be done.
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-mapPartitions
//mapPartitions: Data conversion operations can be done in partitions
// However, data from the entire partition will be loaded into memory for reference
// If the processed data is not released, there is a reference to the object
// Memory overflow is prone to occur when memory is small and data is large
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val rdd1: RDD[Int] = rdd.mapPartitions(iter => {
println("One partition execution")
iter.map(_ * 2)
})
rdd1.collect().foreach(println)
sc.stop()
}
}One partition execution One partition execution 2 4 6 8
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-mapPartitions
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
//[1,2] [3,4]
//Maximum values within each partition can be derived
val rdd1 = rdd.mapPartitions(iter => {
List(iter.max).iterator
})
rdd1.collect().foreach(println)
sc.stop()
}
}2 4
Differences between map and mapPartitions
- Data processing angle
The Map operator is the execution of one data within a partition, similar to a serial operation, while the mapPartitions operator performs batch operations in units of partitions. - Functional Angle
The main purpose of the Map operator is to transform and change the data in the data source. However, it will not reduce or increase the data. The MapPartitions operator needs to pass an iterator and return an iterator. The number of elements that are not required remains the same, so it can increase or decrease the data. - Performance Angle
map operators have lower performance because they are similar to serial operations, but mapPartitions have higher performance because they are similar to batch processing. However, mapPartitions take up memory for a long time, which may result in insufficient memory and memory overflow errors. Therefore, mapPartitions are not recommended for use with limited memory.
3)mapPartitionsWithIndex
Send the data to be processed as partitions to the calculation node for processing, where processing means that any processing can be done, even if the data is filtered, while obtaining the current partition index.
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-mapPartitionsWithIndex
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
// [1,2] [3,4]
// [3,4]
val rdd1: RDD[Int] = rdd.mapPartitionsWithIndex((index, iter) => {
if (index == 1) {
iter
} else {
Nil.iterator //Nil returns an empty set
}
})
rdd1.collect().foreach(println)
sc.stop()
}
}3 4
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-mapPartitionsWithIndex
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 1,2,3,4
// (Section number, number)
val rdd1: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex((index, iter) => {
iter.map(x => (index, x))
})
rdd1.collect().foreach(println)
sc.stop()
}
}(2,1) (5,2) (8,3) (11,4)
4)flatMap
The data processed is flattened and then mapped, so the operator is also called a flattened map
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-flatMap
val rdd: RDD[List[Int]] = sc.makeRDD(List(
List(1, 2), List(3,4)))
val rdd1: RDD[Int] = rdd.flatMap(x=>x)
rdd.collect().foreach(println)
rdd1.collect().foreach(println)
sc.stop()
}
}List(1, 2) List(3, 4) 1 2 3 4
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-flatMap
val rdd: RDD[String] = sc.makeRDD(List(
"hello spark", "hello java"))
val rdd1: RDD[String] = rdd.flatMap(x => {
x.split(" ")
})
rdd1.collect().foreach(println)
sc.stop()
}
}hello spark hello java
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-flatMap
//Use pattern matching when data types are inconsistent
val rdd: RDD[Any] = sc.makeRDD(List(List(1,2),3,List(4,5)))
val rdd1: RDD[Any] = rdd.flatMap(x => {
x match {
case x: List[Int] => x
case x => List(x)
}
})
rdd1.collect().foreach(println)
sc.stop()
}
}1 2 3 4 5
5)glom
Converts data from the same partition directly to an array of memory of the same type for processing, leaving the partition unchanged
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-glom
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
//List => Int
//Int => Array
val glomRdd: RDD[Array[Int]] = rdd.glom()
glomRdd.collect().foreach(x=>println(x.mkString(",")))
sc.stop()
}
}1,2 3,4
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-glom
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
//[1,2], [3,4] Partition Maximum
//Sum of [2] [4] maximum
//[6]
val glomRDD: RDD[Array[Int]] = rdd.glom()
val maxRDD: RDD[Int] = glomRDD.map(
array => {
array.max
}
)
println(maxRDD.collect().sum)
sc.stop()
}
}6
6)groupBy
Grouping data according to specified rules will not change the partition by default, but the data will be shuffled and reassembled, which we call shuffle. In the extreme case, the data may be grouped in the same partition
A group's data is in a partition, but that doesn't mean there is only one group in a partition
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-groupBy
val rdd: RDD[String] = sc.makeRDD(List("hello","spark","hadoop","scala","java"),2)
val groupRDD: RDD[(Char, Iterable[String])] = rdd.groupBy(_.charAt(0))
groupRDD.collect().foreach(println)
sc.stop()
}
}
`
```scala
(h,CompactBuffer(hello, hadoop))
(j,CompactBuffer(java))
(s,CompactBuffer(spark, scala))1.txt
uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:02:05:03 +000 uu wr erw 17/05/2015:12:05:03 +000 uu wr erw 17/05/2015:03:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:03:05:03 +000 uu wr erw 17/05/2015:11:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:11:05:03 +000 uu wr erw 17/05/2015:11:05:03 +000 uu wr erw 17/05/2015:11:05:03 +000 uu wr erw 17/05/2015:02:05:03 +000 uu wr erw 17/05/2015:02:05:03 +000 uu wr erw 17/05/2015:12:05:03 +000 uu wr erw 17/05/2015:12:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("file:///D:\\workspace\\leke-bigdata\\datas\\1.txt")
val timeRDD: RDD[(String, Iterable[(String, Int)])] = rdd.map(line => {
val datas: Array[String] = line.split(" ")
val time: String = datas(3)
val sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss")
/*
* parse()Returns a Date-type data
* parse Method converts a String string to a date type in a specific format.
* Use parse with the same string length as the defined SimpleDateFormat object
*/
val date: Date = sdf.parse(time)
println(date)
println("----------------")
val sdf1 = new SimpleDateFormat("HH")
/*
* format The data returned is of type String
* format The method converts Date characters to String types in a specific format.
* If the Date type does not match the defined SimpleDateFormat length, 0 will be automatically added after
*/
val hour: String = sdf1.format(date)
println(hour)
(hour, 1)
// F2: String interception
// val str: String = datas(3).substring(11, 13)
//(str, 1)
}).groupBy(_._1)
timeRDD.map {
//pattern matching
case (hour, iter) => (hour, iter.size)
}.collect().foreach(println)
sc.stop()
}
}Sun May 17 11:05:03 CST 2015 Sun May 17 10:05:03 CST 2015 ---------------- ---------------- 11 10 Sun May 17 02:05:03 CST 2015 ---------------- Sun May 17 11:05:03 CST 2015 ---------------- 02 11 Sun May 17 11:05:03 CST 2015 ---------------- 11 Sun May 17 02:05:03 CST 2015 ---------------- 02 Sun May 17 02:05:03 CST 2015 ---------------- 02 Sun May 17 12:05:03 CST 2015 ---------------- 12 Sun May 17 12:05:03 CST 2015 ---------------- 12 Sun May 17 03:05:03 CST 2015 ---------------- 03 Sun May 17 10:05:03 CST 2015 ---------------- 10 Sun May 17 10:05:03 CST 2015 ---------------- 10 Sun May 17 12:05:03 CST 2015 ---------------- Sun May 17 10:05:03 CST 2015 ---------------- 12 10 Sun May 17 03:05:03 CST 2015 ---------------- Sun May 17 10:05:03 CST 2015 ---------------- 03 10 Sun May 17 11:05:03 CST 2015 ---------------- 11 Sun May 17 10:05:03 CST 2015 ---------------- 10 (02,3) (11,4) (03,2) (12,3) (10,6)
7)filter
Filters data according to specified rules, preserves data that conforms to rules, and discards data that does not conform to rules.
Partitions do not change when data is filtered, but the data within the partition may be uneven and data skewing may occur in production environments.
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-filter
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
rdd.filter(num=>(num%2!=0)).collect().foreach(println)
sc.stop()
}
}1 3
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-filter
val rdd: RDD[String] = sc.textFile("file:///D:\\workspace\\leke-bigdata\\datas\\1.txt")
//Filter 10-point data
rdd.filter(line=>{
line.split(" ")(3).startsWith("17/05/2015:10")
}).collect().foreach(println)
sc.stop()
}
}uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000 uu wr erw 17/05/2015:10:05:03 +000
8)sample
Extract data from a dataset according to specified rules
(Scenario: data skew)
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-sample
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6,7,8,9,10))
//The sample operator needs to pass three parameters
//1. The first parameter, withReplacement, indicates whether the data will be returned true (put back) or false (discarded) after it is extracted.
//2. The second parameter fraction indicates the probability of each data being extracted from the data source and the concept of the base value if the extraction is not replaced
// When to extract and put back: Indicates the possible number of separate extracts of each data in the data source
//3. The third parameter, seed, indicates the seed of the random algorithm when the data is extracted
// If the third parameter is not passed, then the current system time is used
println(rdd.sample(
false,
0.4,
1
).collect().mkString(","))
println("-------------------")
println(rdd.sample(
true,
2
).collect().mkString(","))
sc.stop()
}
}1,2,3,7,9 ------------------- 2,2,2,3,3,3,3,4,4,4,5,6,7,7,7,8,8,8,9,9,9,9,10,10,10,10,10,10,10
9)distinct
Removing duplicate data from a dataset
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-filter
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,2,3,2))
println(rdd.distinct().collect() mkString (","))
sc.stop()
}
}1,2,3,4
10)coalesce
Reduce partitions based on the amount of data used to filter large datasets and improve the efficiency of small datasets
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-coalesce
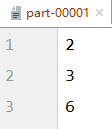
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),3)
val newRDD: RDD[Int] = rdd.coalesce(2)
newRDD.saveAsTextFile("file:///D:\\workspace\\leke-bigdata\\output")
sc.stop()
}
}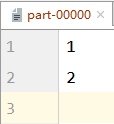

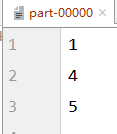
The coalesce method does not, by default, shuffle and reassemble partitioned data
Reduced partitioning in this case may result in uneven data and skewed data
If you want the data to be balanced, shuffle the data, and set the second parameter to true
coalesce operator can enlarge partitions, but it is meaningless and ineffective if shuffle operation is not performed
The shuffle operation is required if you want to achieve the effect of enlarging partitions
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-coalesce
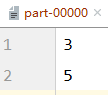
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),3)
val newRDD: RDD[Int] = rdd.coalesce(2,true)
newRDD.saveAsTextFile("file:///D:\\workspace\\leke-bigdata\\output")
sc.stop()
}
}
11)repartition
Inside the operation is actually a coalesce operation, with the coalesce function at the bottom and the default value of the parameter shuffle being true. Regardless of whether you convert an RDD with more partitions to an RDD with fewer partitions or an RDD with fewer partitions to an RDD with more partitions, the repartition operation can be completed, because it will go through the shuffle process in any case.
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-repartition
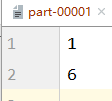
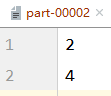
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),2)
val newRDD: RDD[Int] = rdd.repartition(3)
newRDD.saveAsTextFile("file:///D:\\workspace\\leke-bigdata\\output")
sc.stop()
}
}
12)sortBy
This operation is used to sort the data. Before sorting, the data can be processed through the f-function, and then sorted according to the result of the f-function, which is ascending by default. The number of partitions of the newly generated RDD after sorting is consistent with the number of partitions of the original RDD. There is a shuffle process in between
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-sortBy
//The sortBy method sorts the data in the data source according to the specified rules, and the default is ascending
//The second parameter can change the order, using false
//sortBy does not change partitions by default, but there is a shuffle operation in between
val rdd: RDD[Int] = sc.makeRDD(List(4,3,2,6,4,1))
println(rdd.sortBy(x => x,false).collect().mkString(","))
println("---------------")
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("1",1),("11",2),("2",3)))
println(rdd1.sortBy(x => x._1).collect().mkString(","))
println("---------------")
val rdd2: RDD[(String, Int)] = sc.makeRDD(List(("1",1),("11",2),("2",3)))
println(rdd2.sortBy(x => x._1.toInt).collect().mkString(","))
sc.stop()
}
}6,4,4,3,2,1 --------------- (1,1),(11,2),(2,3) --------------- (1,1),(2,3),(11,2)
13) Double Value Type {intersection, union, subtract, zip}
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-Double Value Type
//The intersection, union, and difference sets require the two data source data types to be consistent
//Zipper operation The types of the two data sources can be inconsistent
//When zipping, the two data sources require the same number of partitions and the same number of data in the partition
val rdd1: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val rdd2: RDD[Int] = sc.makeRDD(List(3,4,5,6))
//intersection
println(rdd1.intersection(rdd2).collect().mkString(","))
//Union
println(rdd1.union(rdd2).collect().mkString(","))
//Difference set
println(rdd1.subtract(rdd2).collect().mkString(","))
//zipper
println(rdd1.zip(rdd2).collect().mkString(","))
sc.stop()
}
}3,4 1,2,3,4,3,4,5,6 1,2 (1,3),(2,4),(3,5),(4,6)
14) Key-Value type {partitionBy, reduceByKey, groupByKey, aggregateByKey, foldByKey, combineByKey}
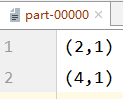
partitionBy
Partition the data again as specified by the Partitioner. The default partitioner for Spark is HashPartitioner
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5),2)
val mapRDD: RDD[(Int, Int)] = rdd.map((_,1))
//partitionBy partitions data according to specified partition rules
mapRDD.partitionBy(new HashPartitioner(2))
.saveAsTextFile("file:///D:\\workspace\\leke-bigdata\\output")
sc.stop()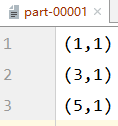
reduceByKey
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator - Key-Value Type
//ReducByKey: Data of the same key aggregates value data
//The rules for calculating reduceByKey within and between partitions are the same
//Generally, aggregation operations in Scala are two-to-two aggregation. spark was developed based on Scala, so its aggregation is also two-to-two aggregation.
//In reduceByKey, if the key has only one data, it will not participate in the operation
val rdd: RDD[(String, Int)] =sc.makeRDD(List(("a",1),("a",2),("a",3),("b",4)))
val rdd1: RDD[(String, Int)] = rdd.reduceByKey((x,y)=>{
println(s"x=${x},y=${y}")
x+y
})
rdd1.collect().foreach(println)
sc.stop()
}
}x=1,y=2 x=3,y=3 (a,6) (b,4)
groupByKey
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator - Key-Value Type
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("a",2),("a",3),("b",4)))
//groupByKey: Groups data from a data source into groups of the same key to form a dual tuple
// The first element in a tuple is the key
// The second element in the tuple is the value of the same key
val rdd1: RDD[(String, Iterable[Int])] = rdd.groupByKey()
rdd1.collect().foreach(println)
println("----------------------")
val rdd2: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1)
rdd2.collect().foreach(println)
sc.stop()
}
}(a,CompactBuffer(1, 2, 3)) (b,CompactBuffer(4)) ---------------------- (a,CompactBuffer((a,1), (a,2), (a,3))) (b,CompactBuffer((b,4)))
Differences between groupByKey and reduceByKey
- From the perspective of shuffle:
Both reduceByKey and groupByKey have shuffle operations, but reduceByKey can pre-aggregate data of the same key in a partition before shuffle, which reduces the amount of data that is dropped. GroupByKey is just grouping, there is no problem with data reduction. ReducByKey has a high performance. - From a functional point of view:
ReducByKey actually contains the functions of grouping and aggregation. groupByKey can only be grouped, not aggregated, so in the case of grouping aggregation, it is recommended to use ReducByKey, if it is only grouping and not aggregation. groupByKey is still the only option.
aggregateByKey
Intra-partition and interval calculations of data based on different rules
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator - Key-Value Type
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("a",2),("b",6),("b",4),("a",6),("b",2)),2)
//Take out the maximum value of the same key in each partition and add the partitions together
//aggregateByKey has a Curitized function with two parameter lists
//The first parameter list, which requires passing a parameter as an initial value
// Mainly used for in-partition calculations with value when the first key is encountered
//The second parameter list passes two parameters:
// The first parameter represents an in-partition calculation rule
// The second parameter represents the intersection calculation rule
val rdd1: RDD[(String, Int)] = rdd.aggregateByKey(5)(
(x, y) => math.max(x, y),
(x, y) => x + y
)
rdd1.collect().foreach(println)
sc.stop()
}
}(b,11) (a,11)
foldByKey
AggateByKey can be simplified to foldByKey when the intra-partition and intersection calculation rules are the same
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator - Key-Value Type
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("a",2),("b",4),("a",6),("b",2)),2)
val rdd1: RDD[(String, Int)] = rdd.foldByKey(0)(_+_)
rdd1.collect().foreach(println)
sc.stop()
}
}(b,6) (a,9)
combineByKey
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator - Key-Value Type
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("a",2),("b",4),("a",6),("b",2)),2)
//combineByKey: Method requires three parameters
//The first parameter implies that the first data of the same key is structurally transformed for operation
//The second parameter represents the calculation rules within a partition
//The third parameter represents the rules for computing between partitions
val rdd1: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
rdd1.collect().foreach(println)
println("---------------------")
val rdd2: RDD[(String, Int)] = rdd1.mapValues {
case (num, cnt) => {
num / cnt
}
}
rdd2.collect().foreach(println)
sc.stop()
}
}(b,(6,2)) (a,(9,3)) --------------------- (b,3) (a,3)
Differences between reduceByKey, foldByKey, aggregateByKey, combineByKey
- ReducByKey: The first data of the same key is not computed at all, and the rules for intra-partition and subinterval calculations are the same
- FoldByKey: The first data and initial values of the same key are calculated within a partition, with the same rules for Intrapartition and subpartition calculations
- AggregateByKey: The first data and initial values of the same key are calculated within a partition, and the rules for calculating within and between partitions can be different
- CombineByKey: Allow the first data conversion structure when the data structure is found to be unsatisfactory for calculations. The intra-partition and subinterval calculation rules are different.
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator - Key-Value Type
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("a",2),("b",4),("a",6),("b",2)),2)
//wordcount
println(rdd.reduceByKey(_ + _).collect().mkString(","))
println(rdd.aggregateByKey(0)(_+_,_+_).collect().mkString(","))
println(rdd.foldByKey(0)(_+_).collect().mkString(","))
println(rdd.combineByKey(v=>v,(x:Int,y)=>(x+y),(x:Int,y:Int)=>(x+y)).collect().mkString(","))
sc.stop()
}
}15)join
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-join
//join: Data from two different data sources, the same key's value is joined together to form a tuple
//If the key does not match between the two data sources, the data will not appear in the result
//If there are multiple key s in the two data sources that are identical, they will match in turn, Cartesian product may occur, the amount of data will increase geometrically, resulting in reduced performance
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("b",4),("c",2)))
val rdd1: RDD[(String, Any)] = sc.makeRDD(List(("a","g"),("b",5),("d",6),("a",2)))
val rdd2: RDD[(String, (Int, Any))] = rdd.join(rdd1)
rdd2.collect().foreach(println)
sc.stop()
}
}(a,(1,g)) (a,(1,2)) (b,(4,5))
16) leftOuterJoin and rightOuterJoin
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator-Left-Right Join
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("b",4),("c",2)))
val rdd1: RDD[(String, Any)] = sc.makeRDD(List(("a","g"),("b",5)))
val rdd2: RDD[(String, (Int, Option[Any]))] = rdd.leftOuterJoin(rdd1)
val rdd3: RDD[(String, (Option[Int], Any))] = rdd.rightOuterJoin(rdd1)
rdd2.collect().foreach(println)
println("---------------------")
rdd3.collect().foreach(println)
sc.stop()
}
}(a,(1,Some(g))) (b,(4,Some(5))) (c,(2,None)) --------------------- (a,(Some(1),g)) (b,(Some(4),5))
17)cogroup
object Spark_rdd_01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD").setMaster("local[*]")
val sc = new SparkContext(conf)
//TODO Operator - cogroup
//cogroup-connection+group
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("b",4),("c",2)))
val rdd1: RDD[(String, Any)] = sc.makeRDD(List(("a","g"),("b",5),("b","m")))
val rdd2: RDD[(String, (Iterable[Int], Iterable[Any]))] = rdd.cogroup(rdd1)
rdd2.collect().foreach(println)
sc.stop()
}
}(a,(CompactBuffer(1),CompactBuffer(g))) (b,(CompactBuffer(4),CompactBuffer(5, m))) (c,(CompactBuffer(2),CompactBuffer()))