1, Run command
bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --class org.apache.spark.examples.SparkPi \ examples/jars/spark-examples_2.11-2.3.1.3.0.1.0-187.jar
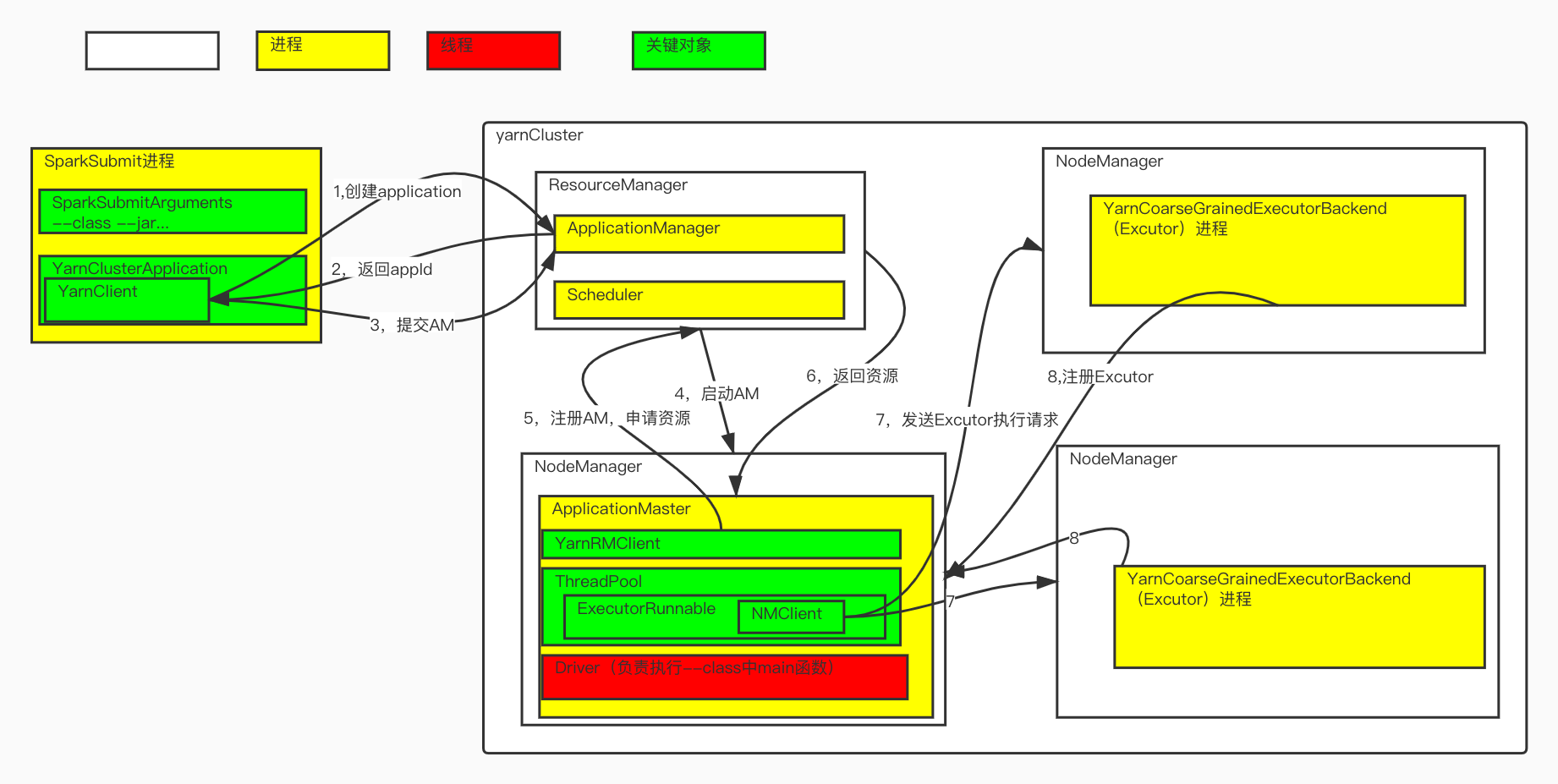
2, Task submission flowchart
3, Startup script
View the spark submit script file. The program entry is
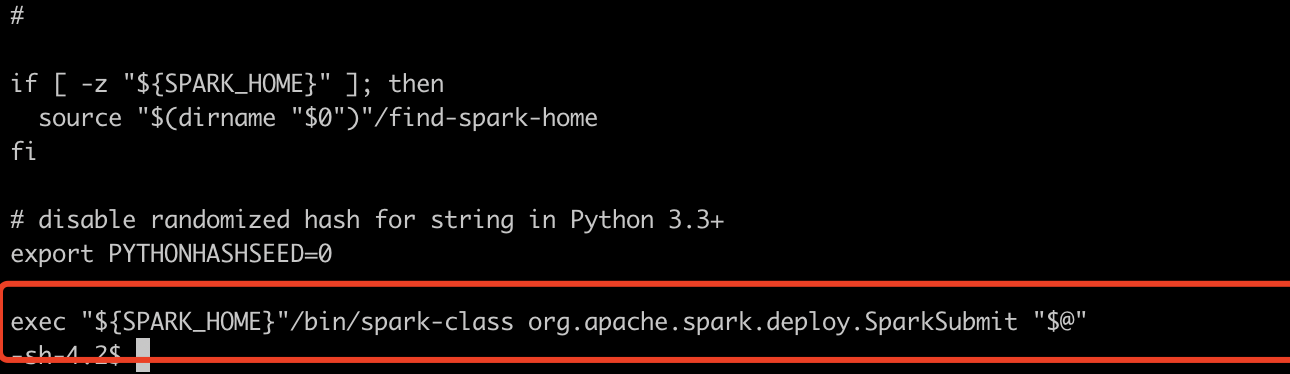
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
Check ${spark_home} "/ bin / spark class to see that the script executes the Java - CP main class Command and starts a java process named SparkSubmit. The main function is in the main class org.apache.spark.deploy.SparkSubmit.
The specific commands actually executed are:
/etc/alternatives/jre/bin/java -Dhdp.version=3.0.1.0-187 -cp /usr/hdp/3.0.1.0-187/spark2/conf/:/usr/hdp/3.0.1.0-187/spark2/jars/*:/usr/hdp/3.0.1.0-187/hadoop/conf/ -Xmx1g org.apache.spark.deploy.SparkSubmit --master yarn --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.3.1.3.0.1.0-187.jar
4, Program entry class org.apache.spark.deploy.SparkSubmit
This class has a companion object, including the main function, which creates a SparkSubmit object and executes doSubmit();
override def main(args: Array[String]): Unit = {
val submit = new SparkSubmit() {...}
submit.doSubmit(args)
}
doSubmit parses the args parameter, encapsulates it in the appArgs:SparkSubmitArguments object, and then executes submit(appArgs, uninitLog).
def doSubmit(args: Array[String]): Unit = {
// Initialize logging if it hasn't been done yet. Keep track of whether logging needs to
// be reset before the application starts.
val uninitLog = initializeLogIfNecessary(true, silent = true)
val appArgs = parseArguments(args)
if (appArgs.verbose) {
logInfo(appArgs.toString)
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
case SparkSubmitAction.PRINT_VERSION => printVersion()
}
}
submit(appArgs, uninitLog) calls runmain (args: sparksubmittarguments, uninitlog: Boolean)
private def runMain(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
.
.
.
try {
mainClass = Utils.classForName(childMainClass)
} catch {...}
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
new JavaMainApplication(mainClass)
}
.
.
.
try {
app.start(childArgs.toArray, sparkConf)
} catch {
case t: Throwable =>
throw findCause(t)
}
}
Here, mainClass is very important. First, judge whether mainClass is a subclass of SparkApplication. If so, call its constructor to create an object through reflection; if not, create a JavaMainApplication (a subclass of SparkApplication) object and override def start(args: Array[String], conf: SparkConf) Function, execute the main function in mainClass by reflection. After the SparkApplication is created, execute its start(childArgs.toArray, sparkConf) method.
/**
* Entry point for a Spark application. Implementations must provide a no-argument constructor.
*/
private[spark] trait SparkApplication {
def start(args: Array[String], conf: SparkConf): Unit
}
/**
* Implementation of SparkApplication that wraps a standard Java class with a "main" method.
*
* Configuration is propagated to the application via system properties, so running multiple
* of these in the same JVM may lead to undefined behavior due to configuration leaks.
*/
private[deploy] class JavaMainApplication(klass: Class[_]) extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
val mainMethod = klass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
val sysProps = conf.getAll.toMap
sysProps.foreach { case (k, v) =>
sys.props(k) = v
}
mainMethod.invoke(null, args)
}
}
If * * – deploy mode * * is the value of client mainClass, it is determined by the command line parameter – class, that is, org.apache.spark.examples.SparkPi. In this case, the client code will be executed in the current virtual machine. If other conditions are met, the situation will be more complex. Take the running command specified above as an example, where mainClass is org.apache.spark.deploy.yarn.YarnClusterApplication Class object.
private[deploy] val YARN_CLUSTER_SUBMIT_CLASS =
"org.apache.spark.deploy.yarn.YarnClusterApplication"
...
if (isYarnCluster) {
childMainClass = YARN_CLUSTER_SUBMIT_CLASS
if (args.isPython) {
childArgs += ("--primary-py-file", args.primaryResource)
childArgs += ("--class", "org.apache.spark.deploy.PythonRunner")
} else if (args.isR) {
val mainFile = new Path(args.primaryResource).getName
childArgs += ("--primary-r-file", mainFile)
childArgs += ("--class", "org.apache.spark.deploy.RRunner")
} else {
if (args.primaryResource != SparkLauncher.NO_RESOURCE) {
childArgs += ("--jar", args.primaryResource)
}
childArgs += ("--class", args.mainClass)
}
if (args.childArgs != null) {
args.childArgs.foreach { arg => childArgs += ("--arg", arg) }
}
}
5, org.apache.spark.deploy.yarn.YarnClusterApplication class
This class is in the spark yarn package.
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
Start executing its override def start(args: Array[String], conf: SparkConf) method.
private[spark] class YarnClusterApplication extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
// SparkSubmit would use yarn cache to distribute files & jars in yarn mode,
// so remove them from sparkConf here for yarn mode.
conf.remove(JARS)
conf.remove(FILES)
new Client(new ClientArguments(args), conf, null).run()
}
}
Create a Client client in the SparkSubmi process, which is a proxy class, including YarnClient, and execute the run() method. Submit the Application to the yarn cluster ResourceManager, and return appid after successful submission. If spark. Submit. Deploymode = cluster & & spark. Yarn. Submit. Waitapcompletion = true, the SparkSubmit process will periodically output appid logs until the task ends (monitorApplication(appId)), otherwise the log will be output once and exit.
def run(): Unit = {
this.appId = submitApplication()
if (!launcherBackend.isConnected() && fireAndForget) {
val report = getApplicationReport(appId)
val state = report.getYarnApplicationState
logInfo(s"Application report for $appId (state: $state)")
logInfo(formatReportDetails(report))
if (state == YarnApplicationState.FAILED || state == YarnApplicationState.KILLED) {
throw new SparkException(s"Application $appId finished with status: $state")
}
} else {
val YarnAppReport(appState, finalState, diags) = monitorApplication(appId)
if (appState == YarnApplicationState.FAILED || finalState == FinalApplicationStatus.FAILED) {
diags.foreach { err =>
logError(s"Application diagnostics message: $err")
}
throw new SparkException(s"Application $appId finished with failed status")
}
if (appState == YarnApplicationState.KILLED || finalState == FinalApplicationStatus.KILLED) {
throw new SparkException(s"Application $appId is killed")
}
if (finalState == FinalApplicationStatus.UNDEFINED) {
throw new SparkException(s"The final status of application $appId is undefined")
}
}
}
Continue tracking submitApplication()
def submitApplication(): ApplicationId = {
ResourceRequestHelper.validateResources(sparkConf)
var appId: ApplicationId = null
try {
launcherBackend.connect()
yarnClient.init(hadoopConf)
yarnClient.start()
logInfo("Requesting a new application from cluster with %d NodeManagers"
.format(yarnClient.getYarnClusterMetrics.getNumNodeManagers))
// Get a new application from our RM
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
appId = newAppResponse.getApplicationId()
// The app staging dir based on the STAGING_DIR configuration if configured
// otherwise based on the users home directory.
val appStagingBaseDir = sparkConf.get(STAGING_DIR)
.map { new Path(_, UserGroupInformation.getCurrentUser.getShortUserName) }
.getOrElse(FileSystem.get(hadoopConf).getHomeDirectory())
stagingDirPath = new Path(appStagingBaseDir, getAppStagingDir(appId))
new CallerContext("CLIENT", sparkConf.get(APP_CALLER_CONTEXT),
Option(appId.toString)).setCurrentContext()
// Verify whether the cluster has enough resources for our AM
verifyClusterResources(newAppResponse)
// Set up the appropriate contexts to launch our AM
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
// Finally, submit and monitor the application
logInfo(s"Submitting application $appId to ResourceManager")
yarnClient.submitApplication(appContext)
launcherBackend.setAppId(appId.toString)
reportLauncherState(SparkAppHandle.State.SUBMITTED)
appId
} catch {
case e: Throwable =>
if (stagingDirPath != null) {
cleanupStagingDir()
}
throw e
}
This method does the following work (corresponding to 1, 2 and 3 in the task submission flowchart):
1. Send a request to the ResourceManager to create an Application and obtain the globally unique
appId.
2. According to the configured cache directory information + appId information, create the cache directory stagingDirPath for running Application.
3. verifyClusterResources verifies whether there are enough resources available in the cluster. If not, an exception is thrown.
4. createContainerLaunchContext creates a Container, which encapsulates the start command of the Container process.
5. Submit appContext.
View the createContainerLaunchContext(newAppResponse) code.
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
...
// Command for the ApplicationMaster
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++ amArgs ++
Seq(
"1>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout",
"2>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr")
// TODO: it would be nicer to just make sure there are no null commands here
val printableCommands = commands.map(s => if (s == null) "null" else s).toList
amContainer.setCommands(printableCommands.asJava)
The startup code of the Container is approximately
bin/java -server org.apache.spark.deploy.yarn.ApplicationMaster --class ...
6, org.apache.spark.deploy.yarn.ApplicationMaster class.
A node manager of the yarn cluster receives a command from the resource manager and starts the ApplicationMaster process, corresponding to step 4 in the task submission flowchart
View the main method in the ApplicationMaster companion object.
def main(args: Array[String]): Unit = {
SignalUtils.registerLogger(log)
val amArgs = new ApplicationMasterArguments(args)
val sparkConf = new SparkConf()
if (amArgs.propertiesFile != null) {
Utils.getPropertiesFromFile(amArgs.propertiesFile).foreach { case (k, v) =>
sparkConf.set(k, v)
}
}
// Set system properties for each config entry. This covers two use cases:
// - The default configuration stored by the SparkHadoopUtil class
// - The user application creating a new SparkConf in cluster mode
//
// Both cases create a new SparkConf object which reads these configs from system properties.
sparkConf.getAll.foreach { case (k, v) =>
sys.props(k) = v
}
val yarnConf = new YarnConfiguration(SparkHadoopUtil.newConfiguration(sparkConf))
master = new ApplicationMaster(amArgs, sparkConf, yarnConf)
val ugi = sparkConf.get(PRINCIPAL) match {
// We only need to log in with the keytab in cluster mode. In client mode, the driver
// handles the user keytab.
case Some(principal) if master.isClusterMode =>
val originalCreds = UserGroupInformation.getCurrentUser().getCredentials()
SparkHadoopUtil.get.loginUserFromKeytab(principal, sparkConf.get(KEYTAB).orNull)
val newUGI = UserGroupInformation.getCurrentUser()
if (master.appAttemptId == null || master.appAttemptId.getAttemptId > 1) {
// Re-obtain delegation tokens if this is not a first attempt, as they might be outdated
// as of now. Add the fresh tokens on top of the original user's credentials (overwrite).
// Set the context class loader so that the token manager has access to jars
// distributed by the user.
Utils.withContextClassLoader(master.userClassLoader) {
val credentialManager = new HadoopDelegationTokenManager(sparkConf, yarnConf, null)
credentialManager.obtainDelegationTokens(originalCreds)
}
}
// Transfer the original user's tokens to the new user, since it may contain needed tokens
// (such as those user to connect to YARN).
newUGI.addCredentials(originalCreds)
newUGI
case _ =>
SparkHadoopUtil.get.createSparkUser()
}
ugi.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = System.exit(master.run())
})
}
The ApplicationMaster object is created and its run() method is executed.
final def run(): Int = {
try {
val attemptID = if (isClusterMode) {
// Set the web ui port to be ephemeral for yarn so we don't conflict with
// other spark processes running on the same box
System.setProperty(UI_PORT.key, "0")
// Set the master and deploy mode property to match the requested mode.
System.setProperty("spark.master", "yarn")
System.setProperty(SUBMIT_DEPLOY_MODE.key, "cluster")
// Set this internal configuration if it is running on cluster mode, this
// configuration will be checked in SparkContext to avoid misuse of yarn cluster mode.
System.setProperty("spark.yarn.app.id", appAttemptId.getApplicationId().toString())
Option(appAttemptId.getAttemptId.toString)
} else {
None
}
new CallerContext(
"APPMASTER", sparkConf.get(APP_CALLER_CONTEXT),
Option(appAttemptId.getApplicationId.toString), attemptID).setCurrentContext()
logInfo("ApplicationAttemptId: " + appAttemptId)
// This shutdown hook should run *after* the SparkContext is shut down.
val priority = ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY - 1
ShutdownHookManager.addShutdownHook(priority) { () =>
val maxAppAttempts = client.getMaxRegAttempts(sparkConf, yarnConf)
val isLastAttempt = appAttemptId.getAttemptId() >= maxAppAttempts
if (!finished) {
// The default state of ApplicationMaster is failed if it is invoked by shut down hook.
// This behavior is different compared to 1.x version.
// If user application is exited ahead of time by calling System.exit(N), here mark
// this application as failed with EXIT_EARLY. For a good shutdown, user shouldn't call
// System.exit(0) to terminate the application.
finish(finalStatus,
ApplicationMaster.EXIT_EARLY,
"Shutdown hook called before final status was reported.")
}
if (!unregistered) {
// we only want to unregister if we don't want the RM to retry
if (finalStatus == FinalApplicationStatus.SUCCEEDED || isLastAttempt) {
unregister(finalStatus, finalMsg)
cleanupStagingDir(new Path(System.getenv("SPARK_YARN_STAGING_DIR")))
}
}
}
if (isClusterMode) {
runDriver()
} else {
runExecutorLauncher()
}
} catch {
case e: Exception =>
// catch everything else if not specifically handled
logError("Uncaught exception: ", e)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_UNCAUGHT_EXCEPTION,
"Uncaught exception: " + StringUtils.stringifyException(e))
} finally {
try {
metricsSystem.foreach { ms =>
ms.report()
ms.stop()
}
} catch {
case e: Exception =>
logWarning("Exception during stopping of the metric system: ", e)
}
}
exitCode
}
Execute the runDriver() method.
userClassThread = startUserApplication() starts a thread named Driver. In this thread, the main * * function in the class specified by * * - class in the command line (org.apache.spark.examples.SparkPi) is executed by reflection to initialize the SparkContext. After the main thread wakes up, register the ApplicationMaster with the resource manager, step 5;
private def runDriver(): Unit = {
addAmIpFilter(None, System.getenv(ApplicationConstants.APPLICATION_WEB_PROXY_BASE_ENV))
userClassThread = startUserApplication()
// This a bit hacky, but we need to wait until the spark.driver.port property has
// been set by the Thread executing the user class.
logInfo("Waiting for spark context initialization...")
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
if (sc != null) {
val rpcEnv = sc.env.rpcEnv
val userConf = sc.getConf
val host = userConf.get(DRIVER_HOST_ADDRESS)
val port = userConf.get(DRIVER_PORT)
registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)
val driverRef = rpcEnv.setupEndpointRef(
RpcAddress(host, port),
YarnSchedulerBackend.ENDPOINT_NAME)
createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)
} else {
// Sanity check; should never happen in normal operation, since sc should only be null
// if the user app did not create a SparkContext.
throw new IllegalStateException("User did not initialize spark context!")
}
resumeDriver()
userClassThread.join()
} catch {
case e: SparkException if e.getCause().isInstanceOf[TimeoutException] =>
logError(
s"SparkContext did not initialize after waiting for $totalWaitTime ms. " +
"Please check earlier log output for errors. Failing the application.")
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_SC_NOT_INITED,
"Timed out waiting for SparkContext.")
} finally {
resumeDriver()
}
}
private def startUserApplication(): Thread = {
logInfo("Starting the user application in a separate Thread")
var userArgs = args.userArgs
if (args.primaryPyFile != null && args.primaryPyFile.endsWith(".py")) {
// When running pyspark, the app is run using PythonRunner. The second argument is the list
// of files to add to PYTHONPATH, which Client.scala already handles, so it's empty.
userArgs = Seq(args.primaryPyFile, "") ++ userArgs
}
if (args.primaryRFile != null &&
(args.primaryRFile.endsWith(".R") || args.primaryRFile.endsWith(".r"))) {
// TODO(davies): add R dependencies here
}
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]])
val userThread = new Thread {
override def run(): Unit = {
try {
if (!Modifier.isStatic(mainMethod.getModifiers)) {
logError(s"Could not find static main method in object ${args.userClass}")
finish(FinalApplicationStatus.FAILED, ApplicationMaster.EXIT_EXCEPTION_USER_CLASS)
} else {
mainMethod.invoke(null, userArgs.toArray)
finish(FinalApplicationStatus.SUCCEEDED, ApplicationMaster.EXIT_SUCCESS)
logDebug("Done running user class")
}
} catch {
case e: InvocationTargetException =>
e.getCause match {
case _: InterruptedException =>
// Reporter thread can interrupt to stop user class
case SparkUserAppException(exitCode) =>
val msg = s"User application exited with status $exitCode"
logError(msg)
finish(FinalApplicationStatus.FAILED, exitCode, msg)
case cause: Throwable =>
logError("User class threw exception: " + cause, cause)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_EXCEPTION_USER_CLASS,
"User class threw exception: " + StringUtils.stringifyException(cause))
}
sparkContextPromise.tryFailure(e.getCause())
} finally {
// Notify the thread waiting for the SparkContext, in case the application did not
// instantiate one. This will do nothing when the user code instantiates a SparkContext
// (with the correct master), or when the user code throws an exception (due to the
// tryFailure above).
sparkContextPromise.trySuccess(null)
}
}
}
userThread.setContextClassLoader(userClassLoader)
userThread.setName("Driver")
userThread.start()
userThread
}
After registration, the main thread processes the resource createlocator (driverref, userconf, rpcenv, appattemptid, distcacheconf) returned by yarn.
private def createAllocator(
driverRef: RpcEndpointRef,
_sparkConf: SparkConf,
rpcEnv: RpcEnv,
appAttemptId: ApplicationAttemptId,
distCacheConf: SparkConf): Unit = {
// In client mode, the AM may be restarting after delegation tokens have reached their TTL. So
// always contact the driver to get the current set of valid tokens, so that local resources can
// be initialized below.
if (!isClusterMode) {
val tokens = driverRef.askSync[Array[Byte]](RetrieveDelegationTokens)
if (tokens != null) {
SparkHadoopUtil.get.addDelegationTokens(tokens, _sparkConf)
}
}
val appId = appAttemptId.getApplicationId().toString()
val driverUrl = RpcEndpointAddress(driverRef.address.host, driverRef.address.port,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
val localResources = prepareLocalResources(distCacheConf)
// Before we initialize the allocator, let's log the information about how executors will
// be run up front, to avoid printing this out for every single executor being launched.
// Use placeholders for information that changes such as executor IDs.
logInfo {
val executorMemory = _sparkConf.get(EXECUTOR_MEMORY).toInt
val executorCores = _sparkConf.get(EXECUTOR_CORES)
val dummyRunner = new ExecutorRunnable(None, yarnConf, _sparkConf, driverUrl, "<executorId>",
"<hostname>", executorMemory, executorCores, appId, securityMgr, localResources,
ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
dummyRunner.launchContextDebugInfo()
}
allocator = client.createAllocator(
yarnConf,
_sparkConf,
appAttemptId,
driverUrl,
driverRef,
securityMgr,
localResources)
// Initialize the AM endpoint *after* the allocator has been initialized. This ensures
// that when the driver sends an initial executor request (e.g. after an AM restart),
// the allocator is ready to service requests.
rpcEnv.setupEndpoint("YarnAM", new AMEndpoint(rpcEnv, driverRef))
allocator.allocateResources()
val ms = MetricsSystem.createMetricsSystem(MetricsSystemInstances.APPLICATION_MASTER,
sparkConf, securityMgr)
val prefix = _sparkConf.get(YARN_METRICS_NAMESPACE).getOrElse(appId)
ms.registerSource(new ApplicationMasterSource(prefix, allocator))
// do not register static sources in this case as per SPARK-25277
ms.start(false)
metricsSystem = Some(ms)
reporterThread = launchReporterThread()
}
Just look at the key code allocator.allocateResources(), which handles the allocated resources.
def allocateResources(): Unit = synchronized {
updateResourceRequests()
val progressIndicator = 0.1f
// Poll the ResourceManager. This doubles as a heartbeat if there are no pending container
// requests.
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
allocatorBlacklistTracker.setNumClusterNodes(allocateResponse.getNumClusterNodes)
if (allocatedContainers.size > 0) {
logDebug(("Allocated containers: %d. Current executor count: %d. " +
"Launching executor count: %d. Cluster resources: %s.")
.format(
allocatedContainers.size,
runningExecutors.size,
numExecutorsStarting.get,
allocateResponse.getAvailableResources))
handleAllocatedContainers(allocatedContainers.asScala)
}
val completedContainers = allocateResponse.getCompletedContainersStatuses()
if (completedContainers.size > 0) {
logDebug("Completed %d containers".format(completedContainers.size))
processCompletedContainers(completedContainers.asScala)
logDebug("Finished processing %d completed containers. Current running executor count: %d."
.format(completedContainers.size, runningExecutors.size))
}
}
If the number of allocated containers is greater than 0, call * * handleAllocatedContainers(allocatedContainers.asScala)**
def handleAllocatedContainers(allocatedContainers: Seq[Container]): Unit = {
val containersToUse = new ArrayBuffer[Container](allocatedContainers.size)
// Match incoming requests by host
val remainingAfterHostMatches = new ArrayBuffer[Container]
for (allocatedContainer <- allocatedContainers) {
matchContainerToRequest(allocatedContainer, allocatedContainer.getNodeId.getHost,
containersToUse, remainingAfterHostMatches)
}
// Match remaining by rack. Because YARN's RackResolver swallows thread interrupts
// (see SPARK-27094), which can cause this code to miss interrupts from the AM, use
// a separate thread to perform the operation.
val remainingAfterRackMatches = new ArrayBuffer[Container]
if (remainingAfterHostMatches.nonEmpty) {
var exception: Option[Throwable] = None
val thread = new Thread("spark-rack-resolver") {
override def run(): Unit = {
try {
for (allocatedContainer <- remainingAfterHostMatches) {
val rack = resolver.resolve(allocatedContainer.getNodeId.getHost)
matchContainerToRequest(allocatedContainer, rack, containersToUse,
remainingAfterRackMatches)
}
} catch {
case e: Throwable =>
exception = Some(e)
}
}
}
thread.setDaemon(true)
thread.start()
try {
thread.join()
} catch {
case e: InterruptedException =>
thread.interrupt()
throw e
}
if (exception.isDefined) {
throw exception.get
}
}
// Assign remaining that are neither node-local nor rack-local
val remainingAfterOffRackMatches = new ArrayBuffer[Container]
for (allocatedContainer <- remainingAfterRackMatches) {
matchContainerToRequest(allocatedContainer, ANY_HOST, containersToUse,
remainingAfterOffRackMatches)
}
if (remainingAfterOffRackMatches.nonEmpty) {
logDebug(s"Releasing ${remainingAfterOffRackMatches.size} unneeded containers that were " +
s"allocated to us")
for (container <- remainingAfterOffRackMatches) {
internalReleaseContainer(container)
}
}
runAllocatedContainers(containersToUse)
logInfo("Received %d containers from YARN, launching executors on %d of them."
.format(allocatedContainers.size, containersToUse.size))
}
Here, the container will be allocated according to the host, rack and other information. After completion, start the container and runallocatedcontainers (containers touse).
private val launcherPool = ThreadUtils.newDaemonCachedThreadPool(
"ContainerLauncher", sparkConf.get(CONTAINER_LAUNCH_MAX_THREADS))
Create the thread pool launcherPool.
/**
* Launches executors in the allocated containers.
*/
private def runAllocatedContainers(containersToUse: ArrayBuffer[Container]): Unit = {
for (container <- containersToUse) {
executorIdCounter += 1
val executorHostname = container.getNodeId.getHost
val containerId = container.getId
val executorId = executorIdCounter.toString
assert(container.getResource.getMemory >= resource.getMemory)
logInfo(s"Launching container $containerId on host $executorHostname " +
s"for executor with ID $executorId")
def updateInternalState(): Unit = synchronized {
runningExecutors.add(executorId)
numExecutorsStarting.decrementAndGet()
executorIdToContainer(executorId) = container
containerIdToExecutorId(container.getId) = executorId
val containerSet = allocatedHostToContainersMap.getOrElseUpdate(executorHostname,
new HashSet[ContainerId])
containerSet += containerId
allocatedContainerToHostMap.put(containerId, executorHostname)
}
if (runningExecutors.size() < targetNumExecutors) {
numExecutorsStarting.incrementAndGet()
if (launchContainers) {
launcherPool.execute(() => {
try {
new ExecutorRunnable(
Some(container),
conf,
sparkConf,
driverUrl,
executorId,
executorHostname,
executorMemory,
executorCores,
appAttemptId.getApplicationId.toString,
securityMgr,
localResources,
ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID // use until fully supported
).run()
updateInternalState()
} catch {
case e: Throwable =>
numExecutorsStarting.decrementAndGet()
if (NonFatal(e)) {
logError(s"Failed to launch executor $executorId on container $containerId", e)
// Assigned container should be released immediately
// to avoid unnecessary resource occupation.
amClient.releaseAssignedContainer(containerId)
} else {
throw e
}
}
})
} else {
// For test only
updateInternalState()
}
} else {
logInfo(("Skip launching executorRunnable as running executors count: %d " +
"reached target executors count: %d.").format(
runningExecutors.size, targetNumExecutors))
}
}
}
Check the ExecutorRunnable class, where nmClient = NMClient.createNMClient(), NodeManager client, which is responsible for NodeManager interaction; its prepareCommand() method splices a process startup command, and the general format is:
bin/java -server org.apache.spark.executor.YarnCoarseGrainedExecutorBackend ...
The launcherPool thread pool in the ApplicationMaster process will start the thread ExecutorRunnable one by one according to the number of containers. The NMClient in the ExecutorRunnable will send the spliced jvm start command to the relevant NodeManager to start the Container process. The process name is yarncoarsegrainedexecutitorbackend.
ExecutorRunnable complete code:
private[yarn] class ExecutorRunnable(
container: Option[Container],
conf: YarnConfiguration,
sparkConf: SparkConf,
masterAddress: String,
executorId: String,
hostname: String,
executorMemory: Int,
executorCores: Int,
appId: String,
securityMgr: SecurityManager,
localResources: Map[String, LocalResource],
resourceProfileId: Int) extends Logging {
var rpc: YarnRPC = YarnRPC.create(conf)
var nmClient: NMClient = _
def run(): Unit = {
logDebug("Starting Executor Container")
nmClient = NMClient.createNMClient()
nmClient.init(conf)
nmClient.start()
startContainer()
}
def launchContextDebugInfo(): String = {
val commands = prepareCommand()
val env = prepareEnvironment()
s"""
|===============================================================================
|Default YARN executor launch context:
| env:
|${Utils.redact(sparkConf, env.toSeq).map { case (k, v) => s" $k -> $v\n" }.mkString}
| command:
| ${Utils.redactCommandLineArgs(sparkConf, commands).mkString(" \\ \n ")}
|
| resources:
|${localResources.map { case (k, v) => s" $k -> $v\n" }.mkString}
|===============================================================================""".stripMargin
}
def startContainer(): java.util.Map[String, ByteBuffer] = {
val ctx = Records.newRecord(classOf[ContainerLaunchContext])
.asInstanceOf[ContainerLaunchContext]
val env = prepareEnvironment().asJava
ctx.setLocalResources(localResources.asJava)
ctx.setEnvironment(env)
val credentials = UserGroupInformation.getCurrentUser().getCredentials()
val dob = new DataOutputBuffer()
credentials.writeTokenStorageToStream(dob)
ctx.setTokens(ByteBuffer.wrap(dob.getData()))
val commands = prepareCommand()
ctx.setCommands(commands.asJava)
ctx.setApplicationACLs(
YarnSparkHadoopUtil.getApplicationAclsForYarn(securityMgr).asJava)
// If external shuffle service is enabled, register with the Yarn shuffle service already
// started on the NodeManager and, if authentication is enabled, provide it with our secret
// key for fetching shuffle files later
if (sparkConf.get(SHUFFLE_SERVICE_ENABLED)) {
val secretString = securityMgr.getSecretKey()
val secretBytes =
if (secretString != null) {
// This conversion must match how the YarnShuffleService decodes our secret
JavaUtils.stringToBytes(secretString)
} else {
// Authentication is not enabled, so just provide dummy metadata
ByteBuffer.allocate(0)
}
ctx.setServiceData(Collections.singletonMap("spark_shuffle", secretBytes))
}
// Send the start request to the ContainerManager
try {
nmClient.startContainer(container.get, ctx)
} catch {
case ex: Exception =>
throw new SparkException(s"Exception while starting container ${container.get.getId}" +
s" on host $hostname", ex)
}
}
private def prepareCommand(): List[String] = {
// Extra options for the JVM
val javaOpts = ListBuffer[String]()
// Set the JVM memory
val executorMemoryString = executorMemory + "m"
javaOpts += "-Xmx" + executorMemoryString
// Set extra Java options for the executor, if defined
sparkConf.get(EXECUTOR_JAVA_OPTIONS).foreach { opts =>
val subsOpt = Utils.substituteAppNExecIds(opts, appId, executorId)
javaOpts ++= Utils.splitCommandString(subsOpt).map(YarnSparkHadoopUtil.escapeForShell)
}
// Set the library path through a command prefix to append to the existing value of the
// env variable.
val prefixEnv = sparkConf.get(EXECUTOR_LIBRARY_PATH).map { libPath =>
Client.createLibraryPathPrefix(libPath, sparkConf)
}
javaOpts += "-Djava.io.tmpdir=" +
new Path(Environment.PWD.$$(), YarnConfiguration.DEFAULT_CONTAINER_TEMP_DIR)
// Certain configs need to be passed here because they are needed before the Executor
// registers with the Scheduler and transfers the spark configs. Since the Executor backend
// uses RPC to connect to the scheduler, the RPC settings are needed as well as the
// authentication settings.
sparkConf.getAll
.filter { case (k, v) => SparkConf.isExecutorStartupConf(k) }
.foreach { case (k, v) => javaOpts += YarnSparkHadoopUtil.escapeForShell(s"-D$k=$v") }
// Commenting it out for now - so that people can refer to the properties if required. Remove
// it once cpuset version is pushed out.
// The context is, default gc for server class machines end up using all cores to do gc - hence
// if there are multiple containers in same node, spark gc effects all other containers
// performance (which can also be other spark containers)
// Instead of using this, rely on cpusets by YARN to enforce spark behaves 'properly' in
// multi-tenant environments. Not sure how default java gc behaves if it is limited to subset
// of cores on a node.
/*
else {
// If no java_opts specified, default to using -XX:+CMSIncrementalMode
// It might be possible that other modes/config is being done in
// spark.executor.extraJavaOptions, so we don't want to mess with it.
// In our expts, using (default) throughput collector has severe perf ramifications in
// multi-tenant machines
// The options are based on
// http://www.oracle.com/technetwork/java/gc-tuning-5-138395.html#0.0.0.%20When%20to%20Use
// %20the%20Concurrent%20Low%20Pause%20Collector|outline
javaOpts += "-XX:+UseConcMarkSweepGC"
javaOpts += "-XX:+CMSIncrementalMode"
javaOpts += "-XX:+CMSIncrementalPacing"
javaOpts += "-XX:CMSIncrementalDutyCycleMin=0"
javaOpts += "-XX:CMSIncrementalDutyCycle=10"
}
*/
// For log4j configuration to reference
javaOpts += ("-Dspark.yarn.app.container.log.dir=" + ApplicationConstants.LOG_DIR_EXPANSION_VAR)
val userClassPath = Client.getUserClasspath(sparkConf).flatMap { uri =>
val absPath =
if (new File(uri.getPath()).isAbsolute()) {
Client.getClusterPath(sparkConf, uri.getPath())
} else {
Client.buildPath(Environment.PWD.$(), uri.getPath())
}
Seq("--user-class-path", "file:" + absPath)
}.toSeq
YarnSparkHadoopUtil.addOutOfMemoryErrorArgument(javaOpts)
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++
Seq("org.apache.spark.executor.YarnCoarseGrainedExecutorBackend",
"--driver-url", masterAddress,
"--executor-id", executorId,
"--hostname", hostname,
"--cores", executorCores.toString,
"--app-id", appId,
"--resourceProfileId", resourceProfileId.toString) ++
userClassPath ++
Seq(
s"1>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stdout",
s"2>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stderr")
// TODO: it would be nicer to just make sure there are no null commands here
commands.map(s => if (s == null) "null" else s).toList
}
private def prepareEnvironment(): HashMap[String, String] = {
val env = new HashMap[String, String]()
Client.populateClasspath(null, conf, sparkConf, env, sparkConf.get(EXECUTOR_CLASS_PATH))
System.getenv().asScala.filterKeys(_.startsWith("SPARK"))
.foreach { case (k, v) => env(k) = v }
sparkConf.getExecutorEnv.foreach { case (key, value) =>
if (key == Environment.CLASSPATH.name()) {
// If the key of env variable is CLASSPATH, we assume it is a path and append it.
// This is kept for backward compatibility and consistency with hadoop
YarnSparkHadoopUtil.addPathToEnvironment(env, key, value)
} else {
// For other env variables, simply overwrite the value.
env(key) = value
}
}
env
}
}