Basic summary
Spark is a fast, universal and scalable big data analysis engine. It is a big data parallel computing framework based on memory computing. Spark was born in the AMP laboratory at the University of California, Berkeley in 2009. It was open source in 2010 and became the top project of Apache in February 2014.
This article is the first in the Spark series of tutorials. It leads you to get started with Spark quickly through the "Hello World" – Word Count experiment in big data. Word Count, as its name implies, counts words. We will first count the words in the file, and then output the three words that appear the most times.
prerequisite
In this article, we will use the spark shell to demonstrate the execution of the Word Count example. Spark shell is one of many ways to submit spark jobs. It provides an interactive running environment (REPL, read evaluate print loop). You can get an immediate response after entering code on spark shell. When the spark shell runs, it depends on the Java and Scala language environments. Therefore, in order to ensure the successful startup of spark shell, Java and scala need to be pre installed locally.
Install Spark locally
Download and unzip the installation package
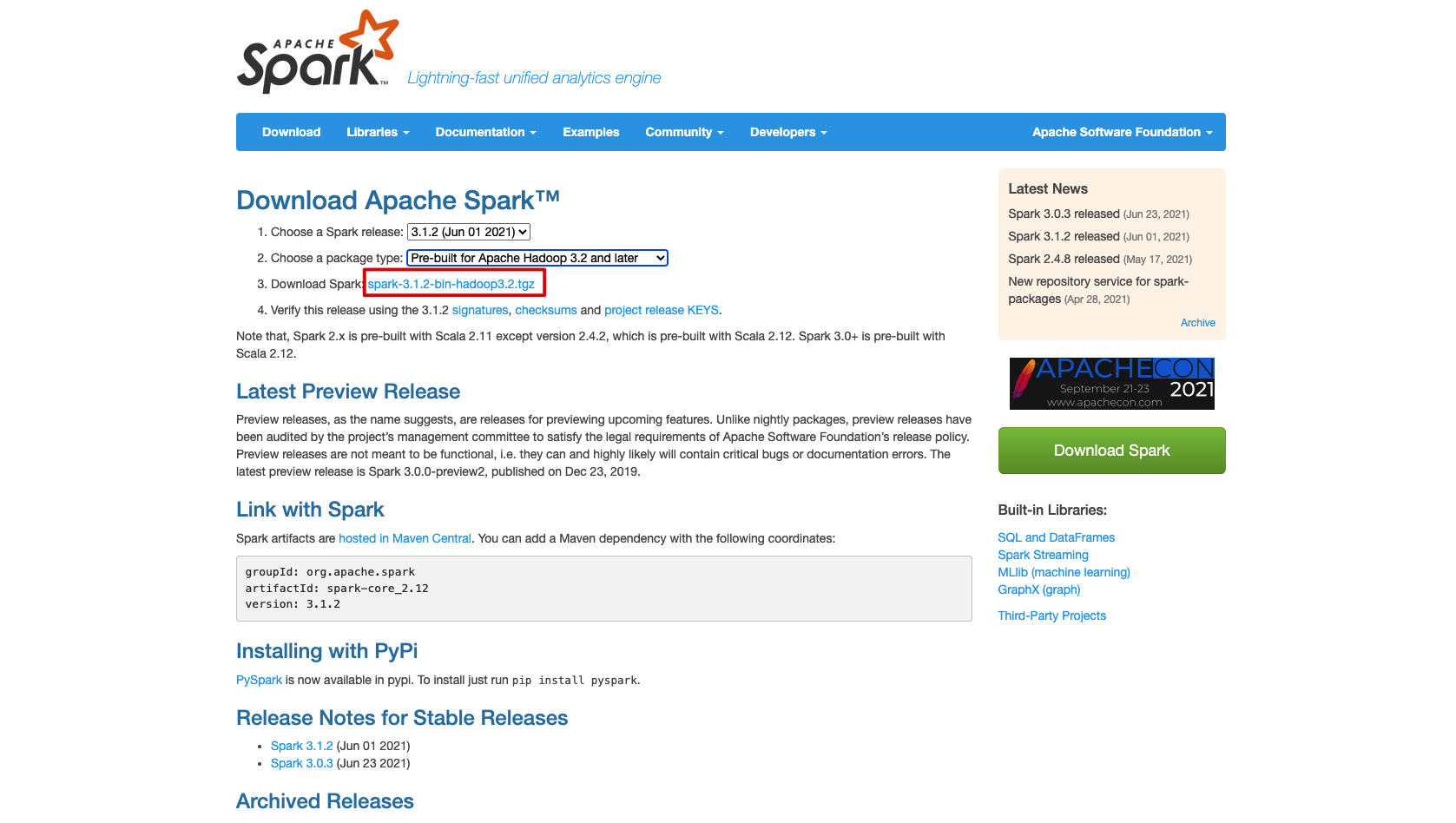
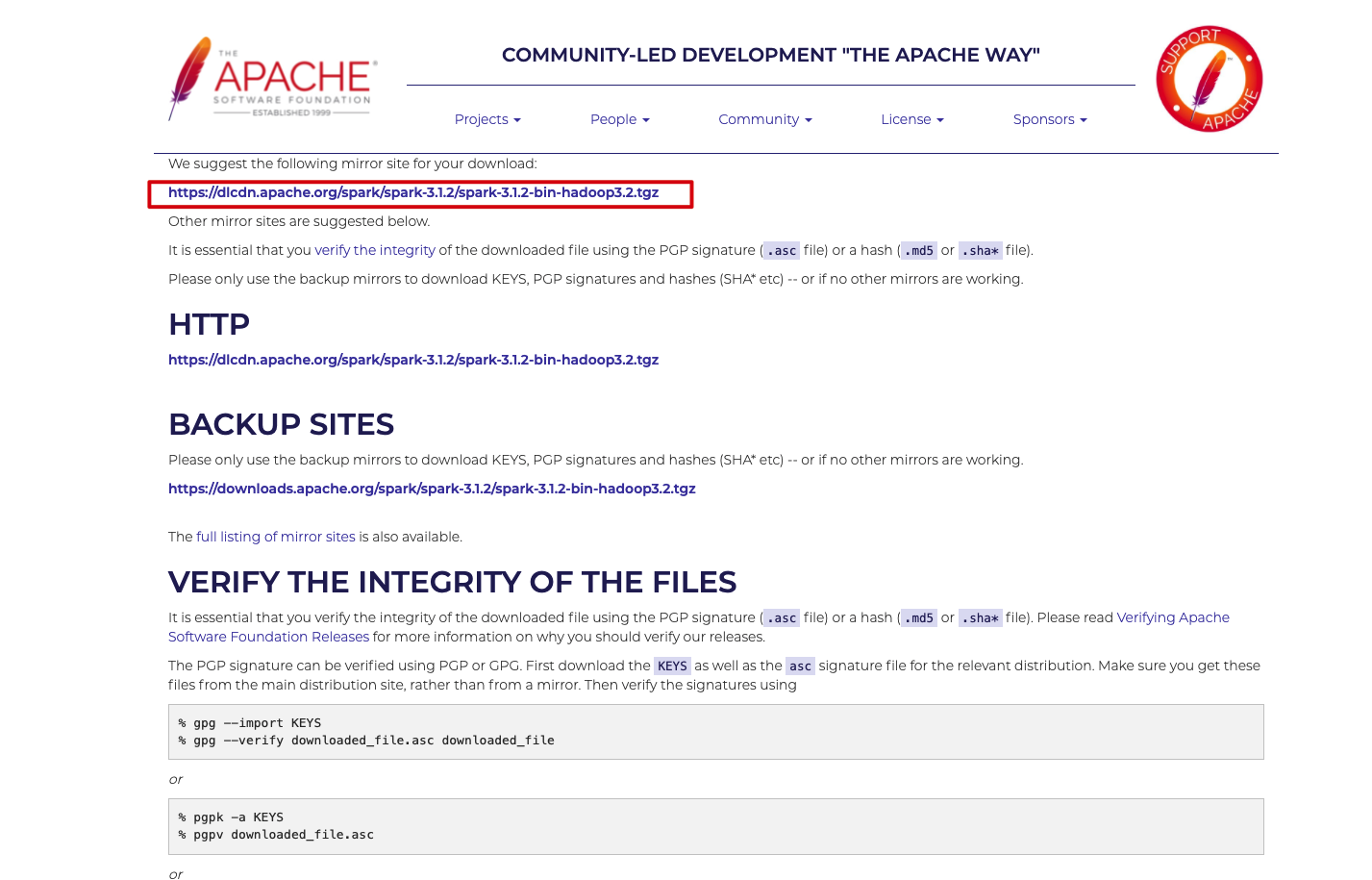
from Spark official website Download the installation package, select the latest precompiled version, and then unzip the installation package to any directory on the local computer.
Setting environment variables
In order to directly run Spark related commands in any directory of the local computer, we need to set the environment variable. My local Mac uses zsh as the terminal shell. Edit the ~ /. zshrc file to set the environment variables. If it is bash, you can edit the / etc/profile file.
export SPARK_HOME=/Users/chengzhiwei/software/spark/spark-3.1.2-bin-hadoop3.2 export PATH=$PATH:$SPARK_HOME/bin
Load environment variables:
source ~/.zshrc
Enter the Spark shell -- version command on the terminal. If the following contents are displayed, it means that we have successfully installed Spark locally.
❯ spark-shell --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10, OpenJDK 64-Bit Server VM, 1.8.0_302
Branch HEAD
Compiled by user centos on 2021-05-24T04:27:48Z
Revision de351e30a90dd988b133b3d00fa6218bfcaba8b8
Url https://github.com/apache/spark
Type --help for more information.
Basic concepts of Spark
Before starting the experiment, first introduce the concepts in three sparks, namely spark, sparkContext and RDD.
- spark and sparkContext are two different development entry instances:
- Spark is the development portal SparkSession Instance. Sparksessions are automatically created by the system in spark shell;
- SparkContext is an instance of the development portal SparkContext. During the evolution of Spark version, starting from version 2.0, SparkSession replaced SparkContext and became a unified development portal. This article uses SparkContext for development.
- The full name of RDD is Resilient Distributed Dataset, which means "elastic distributed dataset". RDD is Spark's unified abstraction of distributed data. It defines a series of basic attributes and processing methods of distributed data.
Implement Word Count
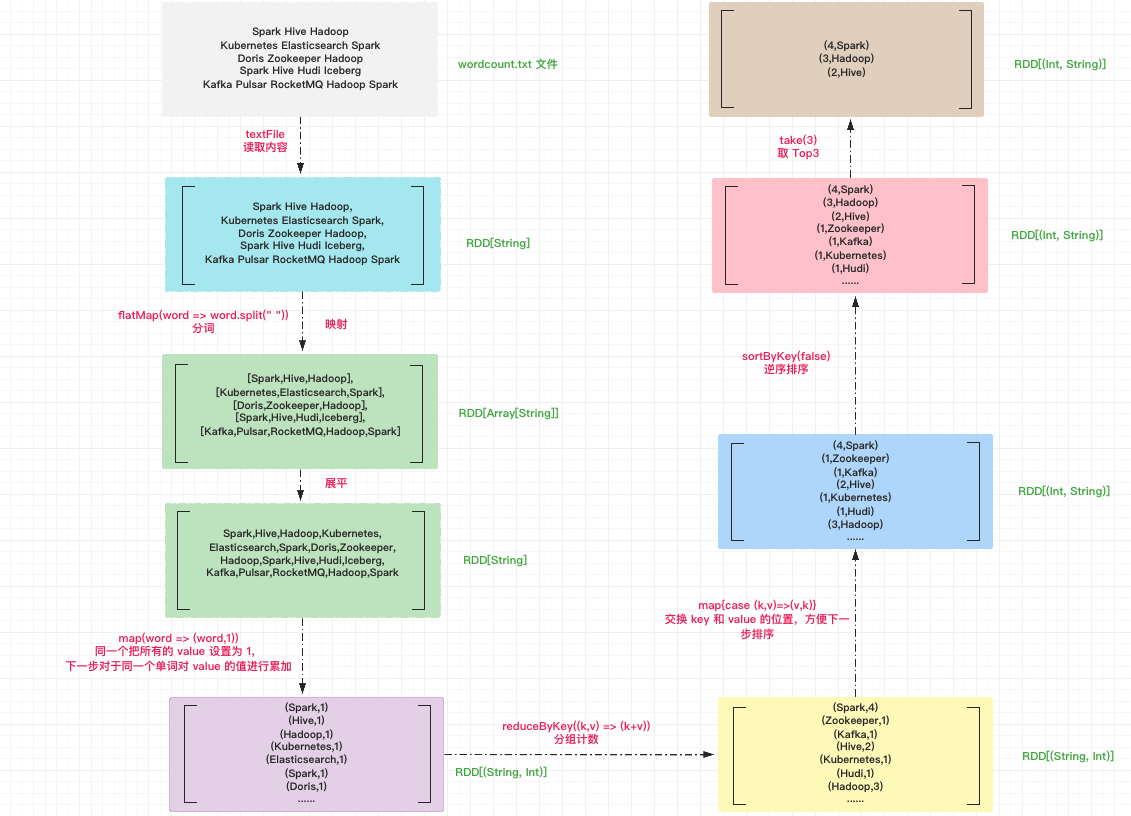
The overall execution process of Word Count is shown as follows. Next, the words in the file are processed according to the five steps of reading content, word segmentation, group counting, sorting and taking the words with the number of occurrences of top 3.
prepare documents
/Write the following in the Users/chengzhiwei/tmp/wordcount.txt file:
Spark Hive Hadoop Kubernetes Elasticsearch Spark Doris Zookeeper Hadoop Spark Hive Hudi Iceberg Kafka Pulsar RocketMQ Hadoop Spark
Step 1: read the file
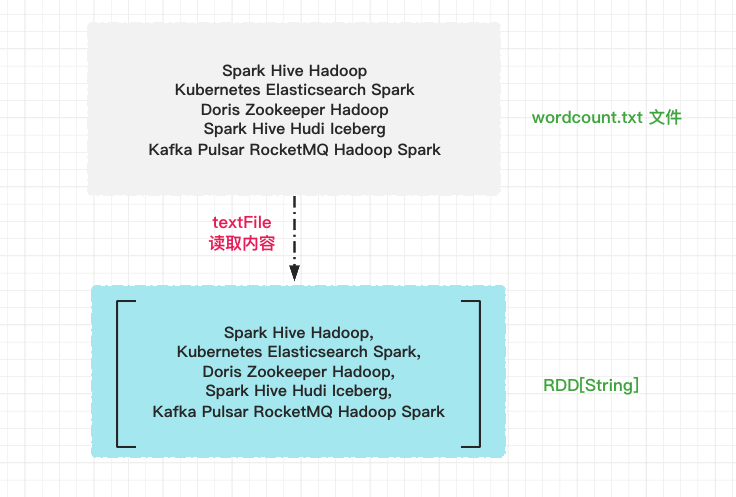
First, we call the textFile method of SparkContext to read the source file and generate an RDD of type RDD[String]. Each line in the file is an element in the array.
//Guide Package import org.apache.spark.rdd.RDD // File path val file: String = "/Users/chengzhiwei/tmp/wordcount.txt" // Read file contents val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
Step 2: word segmentation
"Word segmentation" is to break the line elements of "array" into words. To achieve this, we can call the flatMap method of RDD. The flatMap operation can be logically divided into two steps: mapping and flattening.
// Participle with behavioral unit
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
First, use the space as the separator to convert the line elements in lineRDD into words. After segmentation, each line element becomes a word array, and the element type changes from String to Array[String]. The operation of conversion in element units is uniformly called "mapping".
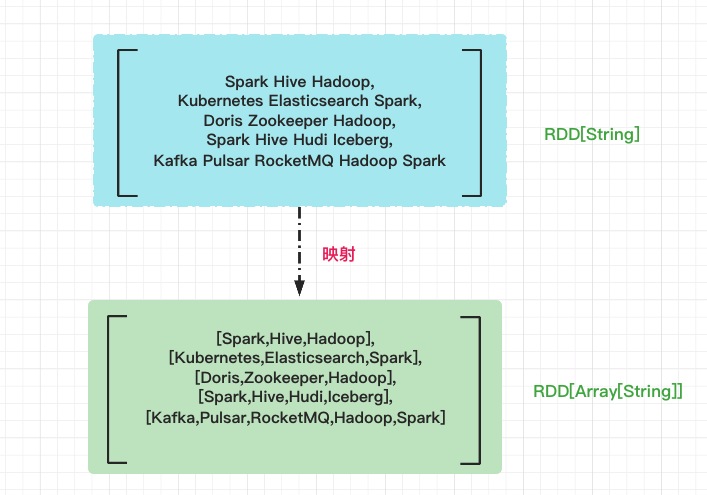
After mapping, the RDD type changes from the original RDD[String] to RDD[Array[String]]. If RDD[String] is regarded as an "array", then RDD[Array[String]] is a "two-dimensional array", and each element of it is a word. Next, we need to flatten the "two-dimensional array", that is, remove the inner nested structure and restore the "two-dimensional array" to "one-dimensional array".
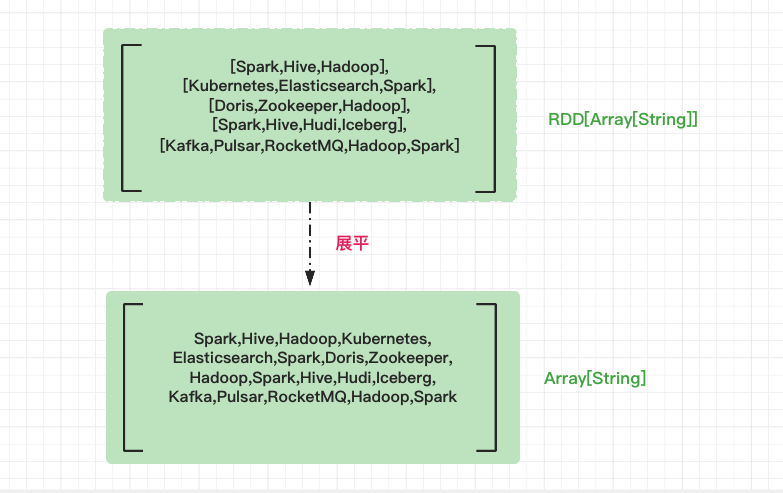
Step 3: group count
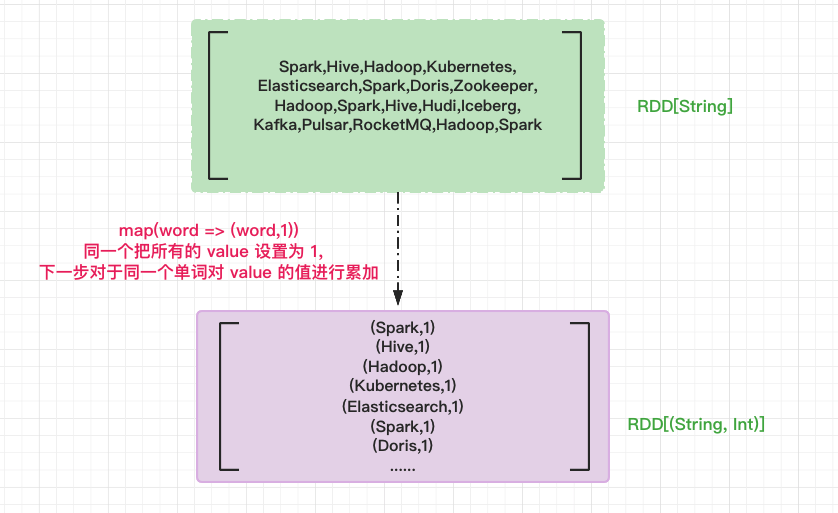
Under the development framework of RDD, aggregation operations, such as counting, summing and averaging, need to rely on data elements of key value pair type. Therefore, before calling the aggregation operator for grouping counting, we should first convert the RDD element into the form of (key, value), that is, map RDD[String] to RDD[(String, Int)].
Use the map method to map word into the form of (word,1). The values of all values are set to 1. For the same word, in the subsequent counting operation, we just need to accumulate the values.
// Convert RDD elements to the form of (Key, Value) val kvRDD: RDD[(String, Int)] = wordRDD.map(word => (word, 1))
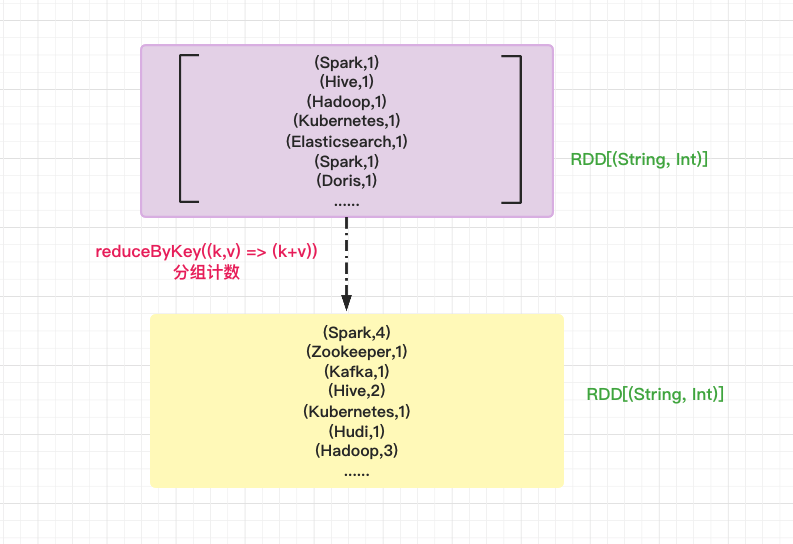
After the formal conversion is completed, we should officially do group counting. Grouping counting is actually two steps, that is, first "grouping" and then "counting". We use the aggregation operator reduceByKey to complete grouping and counting at the same time. For the key value pair "array" of kvRDD, the reduceByKey is first grouped according to the key (that is, words). After grouping, each word has a corresponding value list. Then, according to the aggregation function provided by the user, reduce all values of the same key. Here is to accumulate values.
// Count the words in groups val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
Step 4: sort
In the obtained wordCounts RDD, key is the word and value is the number of occurrences of the word. Finally, we want to take the words with the number of occurrences of the top 3. First, we should sort them in reverse order according to the number of occurrences of the words.
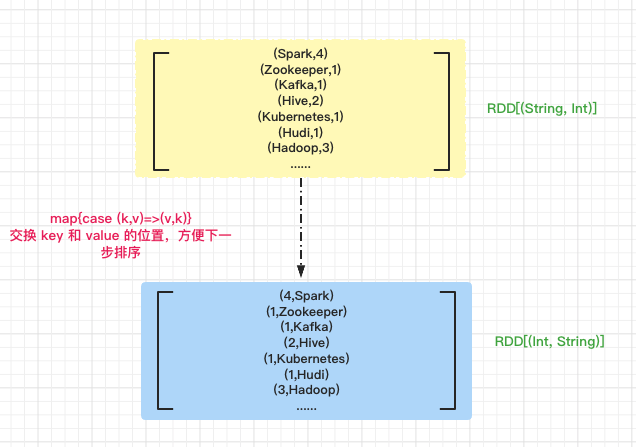
First exchange the positions of key and value in wordCounts RDD to facilitate sorting in the next step.
// Exchange key and value positions
val exchangeRDD: RDD[(Int, String)] = wordCounts.map{case (k,v)=>(v,k)}
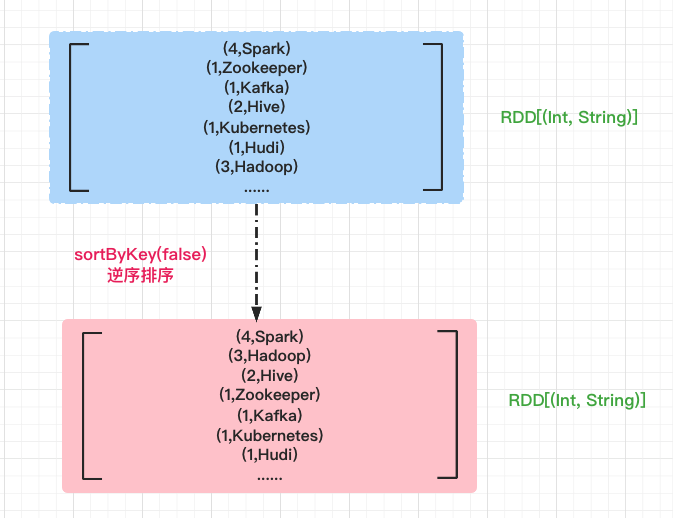
Sort the words in reverse order according to the number of occurrences. false indicates reverse order.
// Sort the words in reverse order according to the number of occurrences val sortRDD: RDD[(Int, String)] = exchangeRDD.sortByKey(false)
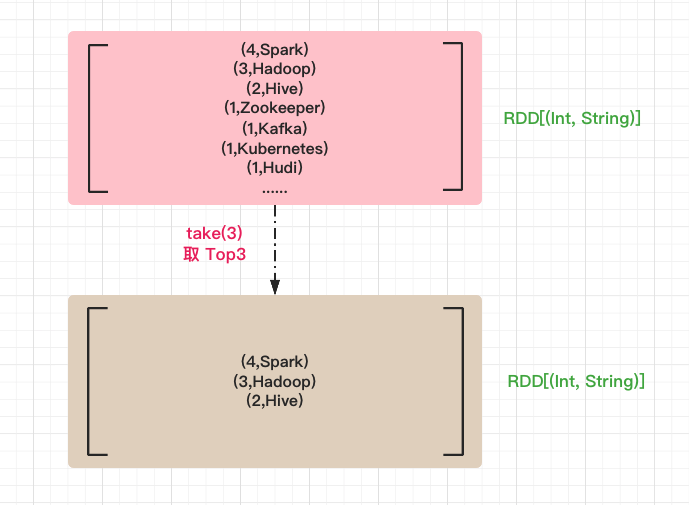
Step 5: take the word with the number of occurrences of Top3
Use the take method to get the first three elements in the sorted array.
// Take the word with the number of occurrences of Top3 sortRDD.take(3)
Complete code
Execute the following code in the spark shell:
//Guide Package
import org.apache.spark.rdd.RDD
//Step 1: read the file
// File path
val file: String = "/Users/chengzhiwei/tmp/wordcount.txt"
// Read file contents
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
//Step 2: word segmentation
// Participle with behavioral unit
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
// Step 3: group count
// Convert RDD elements to the form of (Key, Value)
val kvRDD: RDD[(String, Int)] = wordRDD.map(word => (word, 1))
// Count the words in groups
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
//Step 4: sort
// Exchange key and value positions
val exchangeRDD: RDD[(Int, String)] = wordCounts.map{case (k,v)=>(v,k)}
// Sort the words in reverse order according to the number of occurrences
val sortRDD: RDD[(Int, String)] = exchangeRDD.sortByKey(false)
// Step 5: take the word with the number of occurrences of Top3
sortRDD.take(3)
The output results are as follows. You can see that the words with the number of occurrences of top 3 are Spark, Hadoop and Hive respectively. So far, we have successfully implemented the function of Word Count.
Array[(Int, String)] = Array((4,Spark), (3,Hadoop), (2,Hive))
Simplified writing
The above code for implementing Word Count looks a little complex. We can use the writing method of chain call to simplify the above code into one line of code, call the methods in RDD through. And the return result is a new RDD. We can continue to call the methods in the new RDD with.
//read file
//sc represents the sparkContext instance
sc.textFile("/Users/chengzhiwei/tmp/wordcount.txt").
//Word segmentation according to spaces
flatMap(line => line.split(" ")).
//Group and uniformly set value to 1
map(word => (word,1)).
//Accumulate the value s of the same key
reduceByKey((k,v) => (k+v)).
//Swap (key, value) in order to sort by count, (spark, 4) = > (4, spark)
map{case (k,v)=>(v,k)}.
//Descending sort
sortByKey(false).
//Top 3
take(3)
In order to simplify the number of functions in Scala language, underscores can also be used_ Used as a placeholder to represent one or more parameters. The parameters we use to represent must only appear once in the function literal. Therefore, the above formulation can be further simplified to the following code:
//read file
sc.textFile("/Users/chengzhiwei/tmp/wordcount.txt").
//Word segmentation according to spaces
flatMap(_.split(" ")).
//Group and uniformly set value to 1
map((_,1)).
//Accumulate the value s of the same key
reduceByKey(_+_).
//Swap (key, value) in order to sort by count, (spark, 4) = > (4, spark)
map{case (k,v)=>(v,k)}.
//Descending sort
sortByKey(false).
//Top 3
take(3)
Welcome to pay attention
