1 SparkSQL Introduction
Spark SQL is a module Spark uses to process structured data. It provides a programming abstraction called DataFrame and serves as a distributed SQL query engine.
Hive has been learned. It converts Hive SQL into MapReduce and submits it to cluster for execution. It greatly simplifies the complexity of programming MapReduce, because MapReduce is a computational model with slow execution efficiency. All Spark SQL came into being. It converts Spark SQL into RDD and submits it to cluster for execution. The execution efficiency is very fast.
1.1 characteristics
-
Easy integration
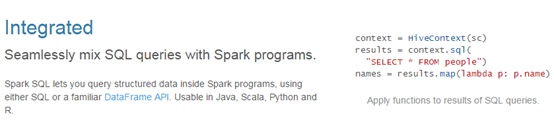
-
Unified Data Access Method

-
Compatible with Hive
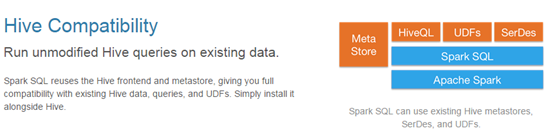
-
Standard data connection

2 DataFrames
2.1 Data Frames Introduction
Similar to RDD, DataFrame is also a distributed data container. However, DataFrame is more like two-dimensional tables in traditional databases. Besides data, it also records the structural information of data, namely schema. Similar to Hive, the DataFrame also supports nested data types (struct, array and map). From the perspective of API usability, the DataFrame API provides a set of high-level relational operations, which are more friendly and lower threshold than the functional RDD API. Similar to R and Pandas DataFrame, Spark DataFrame inherits the development experience of traditional stand-alone data analysis.
2.2 Create DataFrames
In Spark SQL, SQLContext is the entry to create DataFrames and execute SQL
2.2.1 Test data
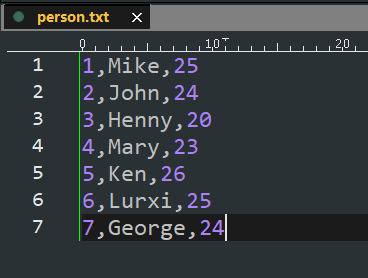
2.2.2 Data uploaded to HDFS
[hadoop@node1 ~]$ ll total 148296 drwxrwxr-x. 6 hadoop hadoop 95 Oct 16 10:18 apps -rw-rw-r--. 1 hadoop hadoop 707 Oct 23 10:19 derby.log drwxrwxr-x. 4 hadoop hadoop 28 Sep 14 19:02 hbase drwxrwxr-x. 4 hadoop hadoop 32 Sep 14 14:44 hdfsdir -rw-r--r--. 1 hadoop hadoop 93886005 Oct 16 23:35 hellospark-1.0-SNAPSHOT.jar -rw-r--r--. 1 hadoop hadoop 57953026 Oct 22 14:29 ipdata.txt drwxrwxr-x. 5 hadoop hadoop 133 Oct 23 10:19 metastore_db -rw-r--r--. 1 hadoop hadoop 78 Oct 23 10:22 person.txt -rw-r--r--. 1 hadoop hadoop 48 Oct 12 17:12 words1.txt drwxrwxr-x. 4 hadoop hadoop 29 Sep 16 22:58 zookeeper [hadoop@node1 ~]$ hadoop fs -put person.txt /
2.2.3
scala> val rdd = sc.textFile("hdfs://node1:9000/person.txt").map(_.split(","))
rdd: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[2] at map at <console>:27
scala> rdd.collect
res1: Array[Array[String]] = Array(Array(1, Mike, 25), Array(2, John, 24),
Array(3, Henny, 20), Array(4, Mary, 23), Array(5, Ken, 26),
Array(6, Lurxi, 25), Array(7, George, 24))
scala> case class Person(id : Long, name : String,age : Int)
defined class Person
scala> val personRDD = rdd.map(x => Person(x(0).toLong,x(1),x(2).toInt))
personRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[3] at map at <console>:31
scala> personRDD.toDF
res2: org.apache.spark.sql.DataFrame = [id: bigint, name: string, age: int]
scala> val df = personRDD.toDF
df: org.apache.spark.sql.DataFrame = [id: bigint, name: string, age: int]
scala> df.show()
+---+------+---+
| id| name|age|
+---+------+---+
| 1| Mike| 25|
| 2| John| 24|
| 3| Henny| 20|
| 4| Mary| 23|
| 5| Ken| 26|
| 6| Lurxi| 25|
| 7|George| 24|
+---+------+---+
2.3 Data Frame Common Operations
2.3.1 DSL Style Grammar
scala> df.select("id","name").show
+---+------+
| id| name|
+---+------+
| 1| Mike|
| 2| John|
| 3| Henny|
| 4| Mary|
| 5| Ken|
| 6| Lurxi|
| 7|George|
+---+------+
scala> df.filter(col("age") > 23).show
+---+------+---+
| id| name|age|
+---+------+---+
| 1| Mike| 25|
| 2| John| 24|
| 5| Ken| 26|
| 6| Lurxi| 25|
| 7|George| 24|
+---+------+---+
2.3.2 SQL Style Grammar
If you want to use SQL-style grammar, you need to register the DataFrame as a table
scala> df.registerTempTable("t_person")
scala> sqlContext.sql("select * from t_person order by age limit 2").show
+---+-----+---+
| id| name|age|
+---+-----+---+
| 3|Henny| 20|
| 4| Mary| 23|
+---+-----+---+
scala> sqlContext.sql("desc t_person").show
+--------+---------+-------+
|col_name|data_type|comment|
+--------+---------+-------+
| id| bigint| |
| name| string| |
| age| int| |
+--------+---------+-------+
2.3.3 The result is written as a json string
scala> case class Person(id:Long,name:String,age:Int)
scala> val rdd = sc.textFile("hdfs://node1:9000/person.txt").map(_.split(","))
rdd: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[2] at map at <console>:27
scala> val personRDD = rdd.map(x => Person(x(0).toLong,x(1),x(2).toInt))
personRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[3] at map at <console>:31
scala> val personDF = personRDD.toDF
personDF: org.apache.spark.sql.DataFrame = [id: bigint, name: string, age: int]
scala> personDF.select("id","name").show
+---+------+
| id| name|
+---+------+
| 1| Mike|
| 2| John|
| 3| Henny|
| 4| Mary|
| 5| Ken|
| 6| Lurxi|
| 7|George|
+---+------+
scala> personDF.select("id","name").write.json("hdfs://node1:9000/json")
[hadoop@node1 ~]$ hadoop fs -ls /json
Found 3 items
-rw-r--r-- 3 hadoop supergroup 0 2018-10-23 14:47 /json/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 93 2018-10-23 14:47 /json/part-r-00000-cfad9e06-9186-45ab-93b5-3bfce5738eb8
-rw-r--r-- 3 hadoop supergroup 71 2018-10-23 14:47 /json/part-r-00001-cfad9e06-9186-45ab-93b5-3bfce5738eb8
[hadoop@node1 ~]$ hadoop fs -cat /json/p*
{"id":1,"name":"Mike"}
{"id":2,"name":"John"}
{"id":3,"name":"Henny"}
{"id":4,"name":"Mary"}
{"id":5,"name":"Ken"}
{"id":6,"name":"Lurxi"}
{"id":7,"name":"George"}
[hadoop@node1 ~]$
2.4 Programming to Execute Spark SQL
2.4.1 pom file
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.tzb.com</groupId> <artifactId>hellospark</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.10.6</scala.version> <spark.version>1.6.3</spark.version> <hadoop.version>2.6.4</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.10</artifactId> <version>1.6.3</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-make:transitive</arg> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass></mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
2.4.2 Inference of Schema by Reflection
package mysparksql import org.apache.spark.sql.SQLContext import org.apache.spark.{SparkConf, SparkContext} object SQLDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("SQLDemo").setMaster("local[2]") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) System.setProperty("user.name", "hadoop") val personRdd = sc.textFile("hdfs://node1:9000/person.txt").map(line => { val fields = line.split(",") Person(fields(0).toLong, fields(1), fields(2).toInt) }) import sqlContext.implicits._ val personDF = personRdd.toDF personDF.registerTempTable("person") sqlContext.sql("select * from person where age>23 order by age desc limit 2").show() sc.stop() } } case class Person(id: Long, name: String, age: Int)
+---+-----+---+ | id| name|age| +---+-----+---+ | 5| Ken| 26| | 6|Lurxi| 25| +---+-----+---+ 18/10/23 11:59:41 INFO SparkUI: Stopped Spark web UI at http://10.210.22.170:4040 18/10/23 11:59:41 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 18/10/23 11:59:41 INFO MemoryStore: MemoryStore cleared 18/10/23 11:59:41 INFO BlockManager: BlockManager stopped 18/10/23 11:59:41 INFO BlockManagerMaster: BlockManagerMaster stopped 18/10/23 11:59:41 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 18/10/23 11:59:41 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon. 18/10/23 11:59:41 INFO SparkContext: Successfully stopped SparkContext 18/10/23 11:59:41 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. 18/10/23 11:59:41 INFO ShutdownHookManager: Shutdown hook called 18/10/23 11:59:41 INFO ShutdownHookManager: Deleting directory C:\Users\tzb\AppData\Local\Temp\spark-1085904e-37f4-4836-860c-e6b9f7f4e3fc 18/10/23 11:59:41 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
Pack jar
Modify source code
val conf = new SparkConf().setAppName("SQLDemo")
Modify pom
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>mysparksql.SQLDemo</mainClass>
</transformer>
Function
[hadoop@node1 ~]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/bin/spark-submit --class mysparksql.SQLDemo --master spark://node1:7077 /home/hadoop/sqldemo.jar
2.4.3 Specify Schema directly through StructType
import org.apache.spark.sql.{Row, SQLContext} import org.apache.spark.sql.types._ import org.apache.spark.{SparkContext, SparkConf} object SpecifyingSchema { def main(args: Array[String]) { //Establish SparkConf()And set up App Name val conf = new SparkConf().setAppName("SQL-2") //SQLContext To rely on SparkContext val sc = new SparkContext(conf) //Establish SQLContext val sqlContext = new SQLContext(sc) //Create from the specified address RDD val personRDD = sc.textFile(args(0)).map(_.split(" ")) //adopt StructType Specify each field directly schema val schema = StructType( List( StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) ) ) //take RDD Mapping to rowRDD val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt)) //take schema Information application rowRDD upper val personDataFrame = sqlContext.createDataFrame(rowRDD, schema) //registry personDataFrame.registerTempTable("t_person") //implement SQL val df = sqlContext.sql("select * from t_person order by age desc limit 4") //The results will be JSON How to store to a specified location df.write.json(args(1)) //Stop it Spark Context sc.stop() } }